一、技术背景
随着大型语言模型(LLM)广泛应用于搜索、内容生成、AI助手等领域,对模型推理服务的并发能力、响应延迟和资源利用效率提出了前所未有的高要求。与模型训练相比,推理是一个持续进行、资源消耗巨大的任务,尤其在实际业务中,推理服务需要同时支持大量用户请求,保证实时性和稳定性。
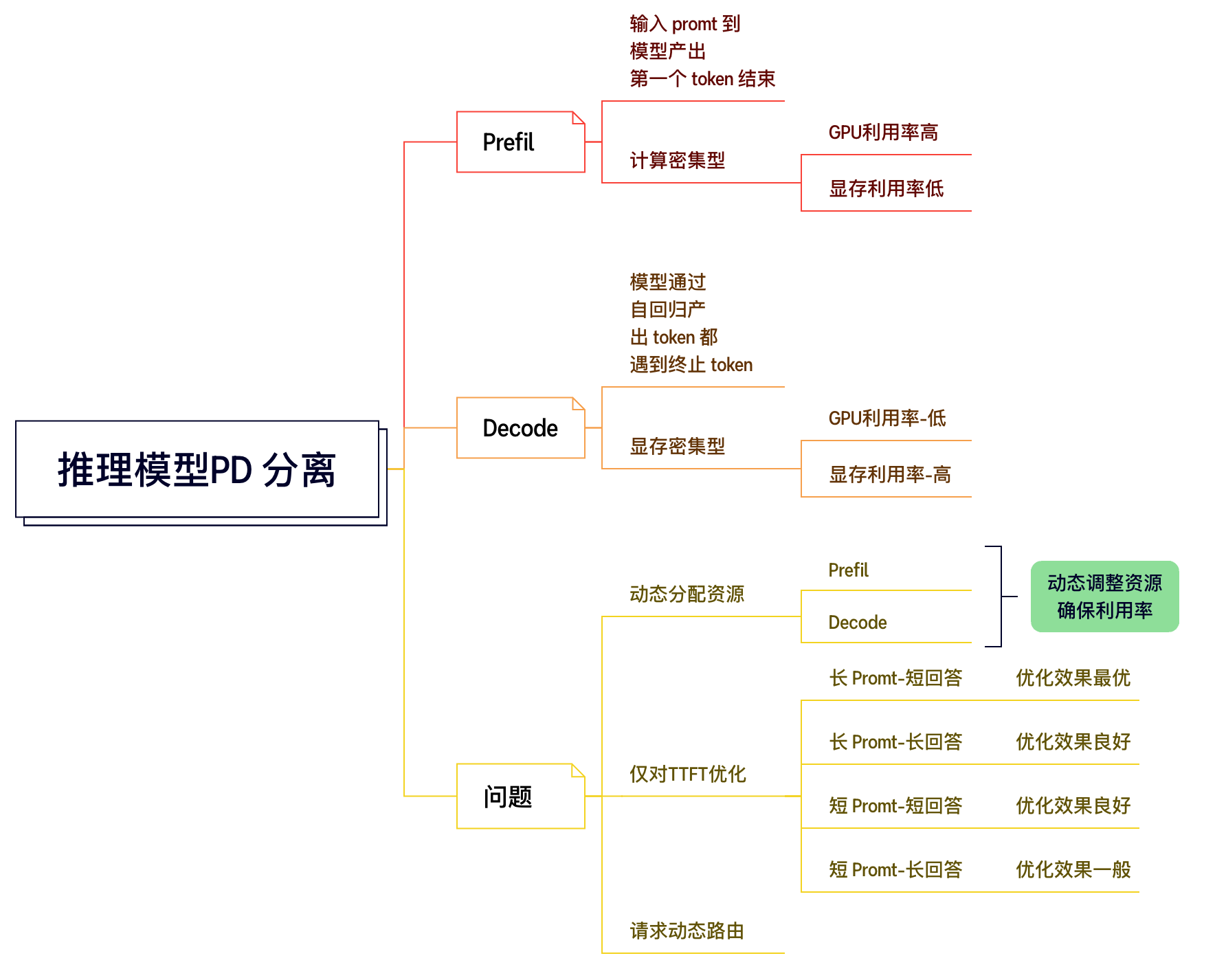
在传统架构中,LLM 的输入处理(Prefill)和输出生成(Decode)阶段往往混合部署在同一批 GPU 上。这种“统一架构”虽然实现简单,但很快暴露出严重的性能瓶颈和资源调度困境:Prefill 阶段计算密集、耗时长,容易阻塞 Decode 阶段对低延迟的需求,导致整体吞吐和响应速度下降;而 Decode 阶段则受制于 KV Cache 带宽和访问延迟,难以并发扩展
二、PD 分离介绍讨论
2.1 Prefill阶段:特征与计算需求
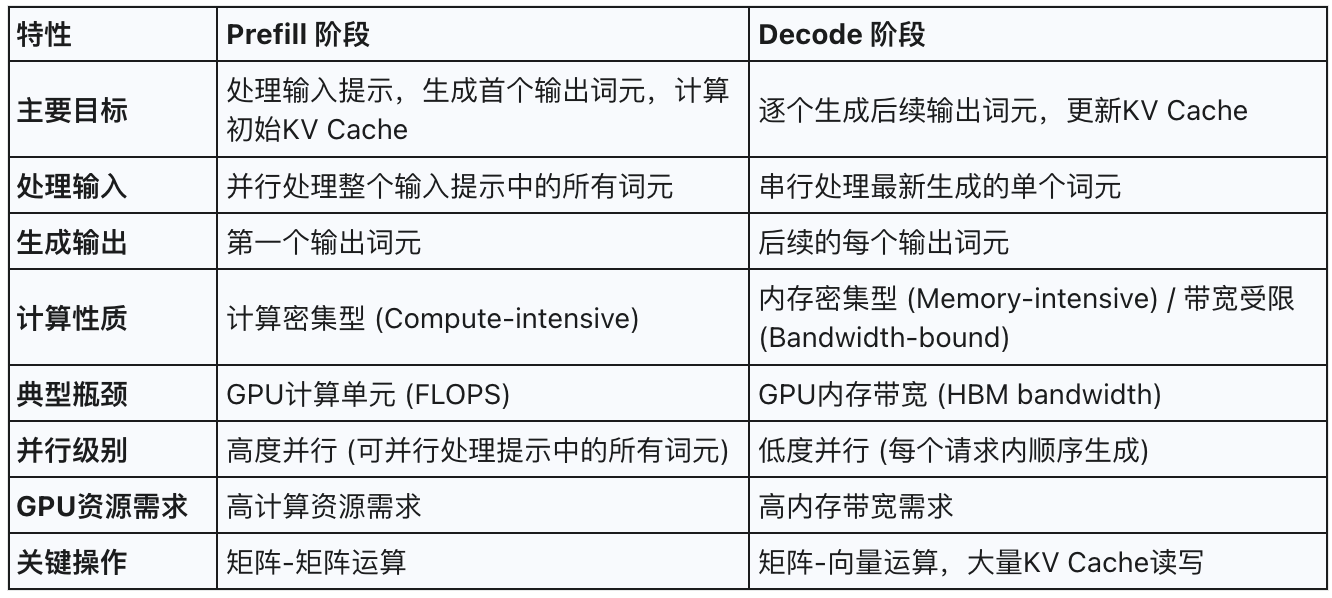
Prefill阶段负责并行处理输入提示中的所有词元,生成第一个输出词元,并计算初始的键值缓存 (Key-Value Cache, KV Cache) 。其主要特征是计算密集型 (computationally intensive),通常受限于计算资源 (compute-bound),尤其是在处理较长提示时。在此阶段,模型对输入序列中的每个词元进行并行计算,通常涉及大规模的矩阵-矩阵运算,能够充分利用GPU的并行计算能力,甚至使其达到饱和状态。
2.3 Decode阶段:特征与计算需求
Decode阶段以自回归的方式逐个生成后续的输出词元。在Decode的每一步中,模型仅处理最新生成的那个词元,并结合先前存储在KV Cache中的上下文信息来预测下一个词元。与Prefill阶段不同,Decode阶段每个词元的计算量相对较小,但其主要瓶颈在于内存带宽 (memory-bandwidth-bound) 。这是因为每个解码步骤都需要频繁访问和读取不断增长的KV Cache,涉及的操作主要是矩阵-向量运算。尽管只处理一个新词元,但其对模型权重和KV Cache的I/O需求与Prefill阶段相似。Decode阶段可以看作是“逐字逐句地续写回应”的过程
2.4. KV Cache 机制
KV Cache 是 LLM 高效推理的核心技术。它将每个词元在 Transformer 计算中生成的 Key 和 Value 向量缓存到 GPU 显存,避免重复计算,大幅提升生成效率。
-
Prefill 阶段:为所有输入词元批量生成 KV Cache,计算密集型、强并行。
-
Decode 阶段:每生成一个新词元,都会增量更新 KV Cache,并频繁读取全部缓存内容,这使得 Decode 主要受内存带宽限制。
KV Cache 的容量会随着输入和生成序列的长度线性增长,是 GPU 显存消耗的主要来源。自回归生成的顺序性决定了 Decode 难以高并发,访问 KV Cache 的效率成为系统瓶颈。高效的 KV Cache 管理和分阶段调优是优化大模型推理的关键。
2.4 统一架构的局限性(PD Fusion)
实现相对简单,无需复杂的跨节点通信,Prefill (计算密集) 和 Decode (内存密集) 两个阶段的资源需求和计算特性差异大,在同一组GPU上运行时容易相互干扰,导致GPU资源利用率不均衡。例如,Prefill 可能会抢占 Decode 的计算资源,导致 Decode 延迟增加;或者为了 Decode 的低延迟,Prefill 的批处理大小受限。
2.5 PD 分离式系统 (PD Disaggregation)
优点:
-
消除干扰: Prefill 和 Decode 在独立的硬件资源池中运行,避免了相互的性能干扰。
-
资源优化: 可以为 Prefill 阶段配置计算密集型硬件,为 Decode 阶段配置内存密集型硬件,从而更有效地利用资源。
-
独立扩展: 可以根据 Prefill 和 Decode 各自的负载情况独立扩展资源。
-
提升吞吐量和效率: 通过上述优化,通常能实现更高的系统总吞吐量。
缺点:
-
KV Cache 传输: 在 Prefill 阶段计算完成的 KV Cache 需要传输到 Decode 节点,这个过程会引入额外的延迟和网络开销,是 PD 分离架构需要重点优化的环节。
-
调度复杂性: 需要一个全局调度器来协调 Prefill 和 Decode 任务的分发和管理。
三、kv 缓存分析
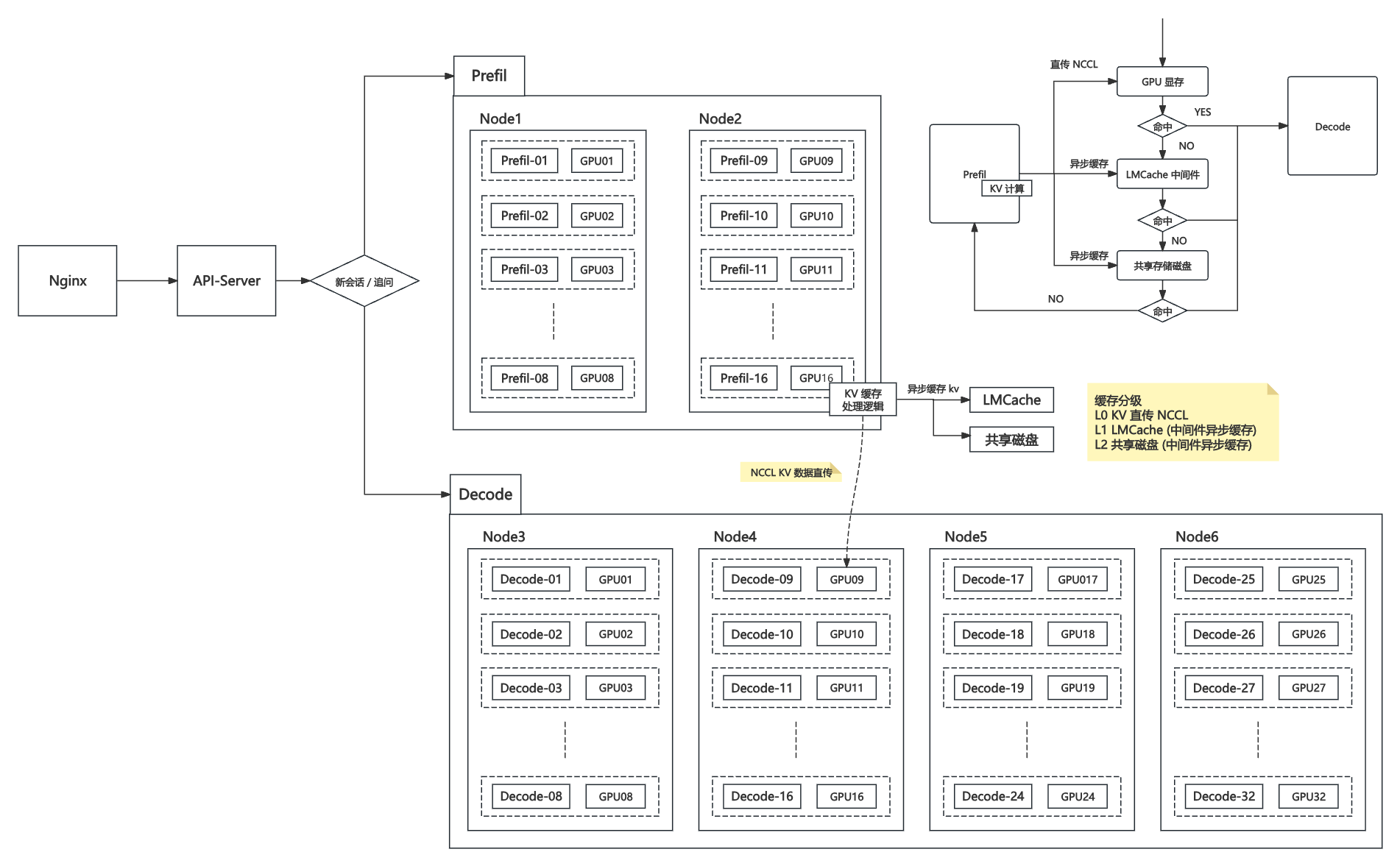
3.1 直传 KV 缓存
通过高速互联(如 NVIDIA NCCL、NVLink、Infiniband 等)在多 GPU 之间直接传递 KV 缓存,无需落盘或经过主机内存。
-
优点:延迟极低、带宽极高,非常适合同机或高速互联环境下多 GPU 间的数据交互。
-
典型场景:Prefill 生成 KV 后,直接推送到 Decode GPU,适合高性能集群内部。
3.2 LMCache
利用独立的 KV 缓存服务(如 LMCache),在集群节点间通过高性能网络或主机内存中转和管理 KV 数据。
-
优点:跨主机节点灵活,缓存可设定有效期,支持异步读写,适合中大型分布式环境。
-
典型场景:Prefill 结果写入 LMCache,Decode 阶段可在任意节点拉取所需 KV 缓存,实现解耦与弹性扩缩容。
3.3 共享缓存磁盘
将 KV 缓存写入分布式文件系统或本地共享存储(如 NFS、Ceph、HDFS),供多节点共享访问。
-
优点:实现跨节点持久化、可恢复,可用于极大规模或需要历史缓存复用的场景。
-
缺点:读写延迟和带宽通常劣于显存直传和内存缓存,仅适合低频访问或大规模冷数据。
-
典型场景:大规模集群、节点动态加入/重启恢复等需持久化的情况。
3.4 多级缓存
多级缓存是为最大化缓存命中率、降低延迟、平衡成本和容量而设计的一套分层缓存体系,广泛应用于高性能分布式大模型推理服务中。其核心思想是:优先在最快速的存储介质中查找和存取 KV 数据,逐层回退至更慢但容量更大的存储层。
四、SGlang PD 分离实战
4.1 基础环境准备
1) GPU 服务器
这里直接选择单卡双卡/H800配置测试
2) NCCL 通信网卡
# 查看可用于nccl通信的网卡 在SGlang地方需要指定网卡
ibdev2netdev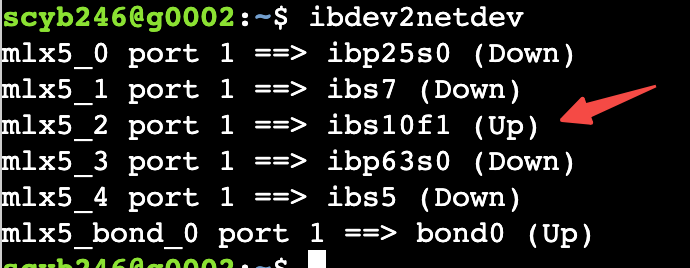
3) 推理模型环境
这里为了测试方便我直接采用sglang[all]全部下载。如果有需要可以按需下载各个组件
pip install sglang[all]
pip install mooncake-transfer-engine4) 基础模型准备
4.2 推理模型部署
1) prefil 服务启动
CUDA_VISIBLE_DEVICES=0 python -m sglang.launch_server \--model-path /data/public/model/qwen2.5/qwen2.5-7b-instruct \--port 7000 \--host 0.0.0.0 \--tensor-parallel-size 1 \--disaggregation-mode prefill \--disaggregation-bootstrap-port 8998 \--disaggregation-transfer-backend mooncake \--disaggregation-ib-device mlx5_2 \--max-total-tokens 4096 \--dtype float16 \--trust-remote-code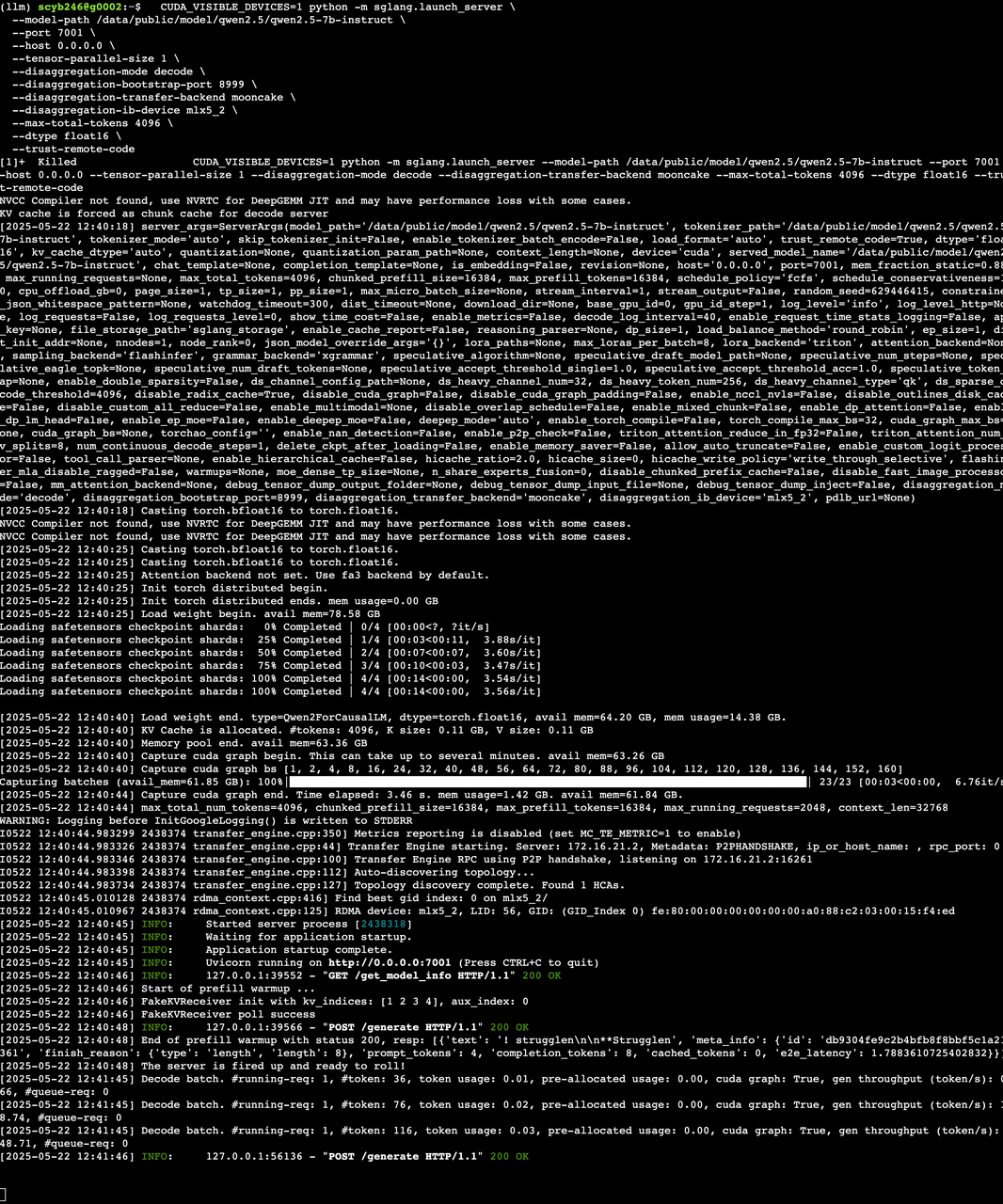
2) decode 服务启动
CUDA_VISIBLE_DEVICES=1 python -m sglang.launch_server \--model-path /data/public/model/qwen2.5/qwen2.5-7b-instruct \--port 7001 \--host 0.0.0.0 \--tensor-parallel-size 1 \--disaggregation-mode decode \--disaggregation-bootstrap-port 8999 \--disaggregation-transfer-backend mooncake \--disaggregation-ib-device mlx5_2 \--max-total-tokens 4096 \--dtype float16 \--trust-remote-code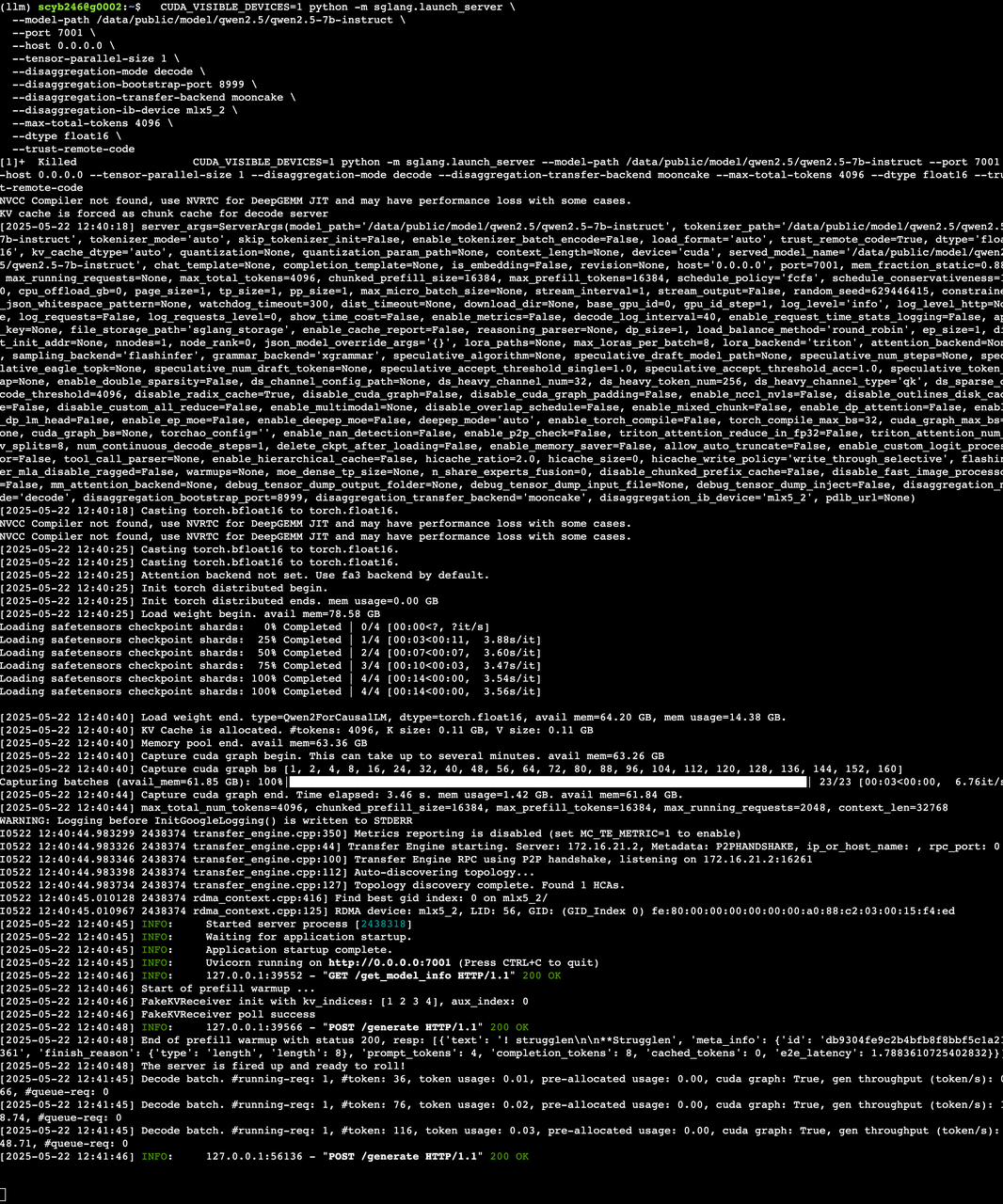
4.3 简易版路由 mini_lb
python -m sglang.srt.disaggregation.mini_lb \--prefill http://127.0.0.1:7000 \--prefill-bootstrap-ports 8998 \--decode http://127.0.0.1:7001 \--host 0.0.0.0 \--port 8000 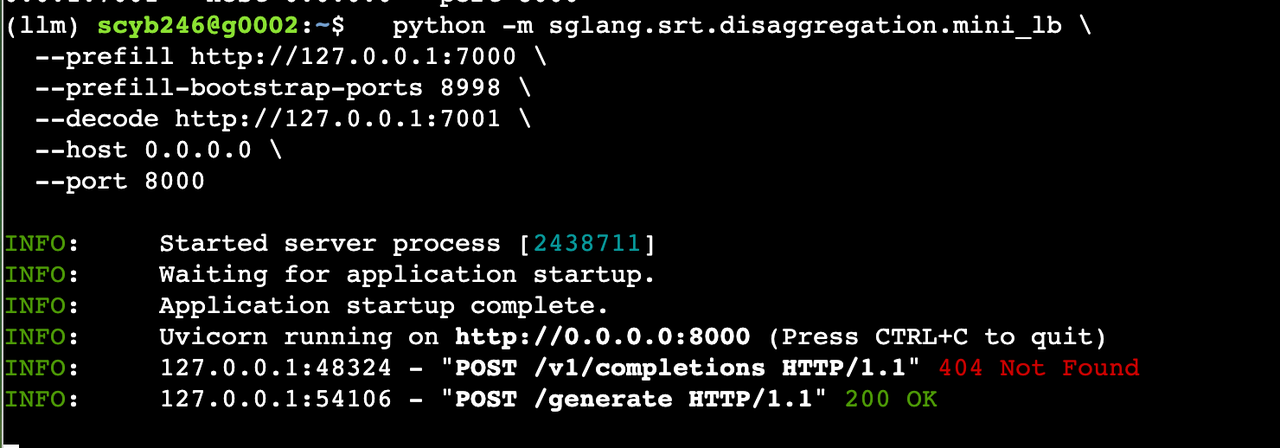
4.4 测试
curl -X POST http://localhost:8000/generate -H "Content-Type: application/json" -d '{"text": "请介绍一下你自己","max_new_tokens": 32,"temperature": 0.7}'
五、小结
kv 缓存概念理解起来就很痛苦。经过各种查资料问大模型才理解整个过程。相当不容易。现在的示例只是提供了 SGLang 的 Mooncake 框架的直传也属于 NCCL 的方式。还没有体现出分布式多级缓存。如果是生产环境则需要将并行策略和多级缓存融合后再实施。
之 yolov5分类模型 训练自己的数据集)





在Qt中的应用)








)

![函数[x]和{x}在数论中的应用](http://pic.xiahunao.cn/函数[x]和{x}在数论中的应用)
Python爬虫高阶:动态页面处理与Scrapy+Selenium+BeautifulSoup分布式架构深度解析实战)
