今天带来EMO2(全称End-Effector Guided Audio-Driven Avatar Video Generation)是阿里巴巴智能计算研究院研发的创新型音频驱动视频生成技术。该技术通过结合音频输入和静态人像照片,生成高度逼真且富有表现力的动态视频内容,值得一提的是目前阿里并没有开源这个项目,所以今天内容仅供学习(阿里的EMO一代到目前都还没有开源,所以等项目开源那是遥遥无期)欢迎大家再评论区讨论
- 项目官网: https://humanaigc.github.io/emote-portrait-alive-2/carxiv
- 技术论文: https://arxiv.org/pdf/2501.10687
1. 动机与问题
1.1 问题1:如何实现富有表现力的音画同步人体视频生成
- 研究背景:音频驱动人体视频生成技术旨在创建音画同步的面部表情与肢体动作,尽管在音频驱动面部表情生成和以人物为中心的视频合成方面已取得显著成果,但在实现富有表现力的音画同步人体视频生成,尤其是伴随语音的视频生成方面仍存在挑战
- 现状与挑战:现有方法主要聚焦于面部区域,忽略了上半身尤其是手部动作的建模,现有方法难以生成 富有表现力,语义一致的全身动作
1.2 问题2:存在肢体动作丰富度不足或泛化能力有限等缺陷
- 分析原因:
- 人体是一个具有高自由度的复杂多关节系统,其运动具有高度的时间依赖性与多样性。
- 在像素空间或显式坐标空间中从音频直接预测全身动作,而音频与不同身体关节之间的相关性存在显著差异,所以容易出现动作僵硬、同步性不足等问题
解决方案: - 借鉴机器人控制系统的“末端执行器”和机器人逆向运动学降低自由度,改进逆向运动学,提出“像素先于逆运动学”,这种方法能够重建完整人物角色,实现音频与嘴唇运动的同步,同时保持人体结构的合理性,从而生成连贯、自然的共语视频。
- 不再直接从音频预测全身动作,专注于将音频映射到手部姿态,充分利用音频与手部动作的强相关性。
2. 创新点
- 受到机械臂和人形机器人等控制系统常通过仿生设计来模拟人类行为的启发,将手部动作看作日常生活的"末端执行器"简化人体自由度
- 提出音频特征与全身动作之间的对应关系比较弱是当前方法的关键限制,验证了音频信号与手部动作的强相关性(所以这篇文章是由音频输入先生成手部姿态,再将手部姿态看作“末端执行器”来生成全身动作)
- 提出一种简化的两段音频驱动手势生成框架
- 引入基于扩散模型的生成方法,能够从生成的手部姿态合成逼真的面部表情与身体动作
3. 方法
EMO2 提出了一个创新的音频驱动视频生成框架,结合末端执行器引导机制,在音画同步的基础上,显著提升了生成动作的自然性、协调性和表现力。该方法的整体架构由音频解码器、末端执行器预测网络、视频合成模块、运动控制模块四个主要模块组成
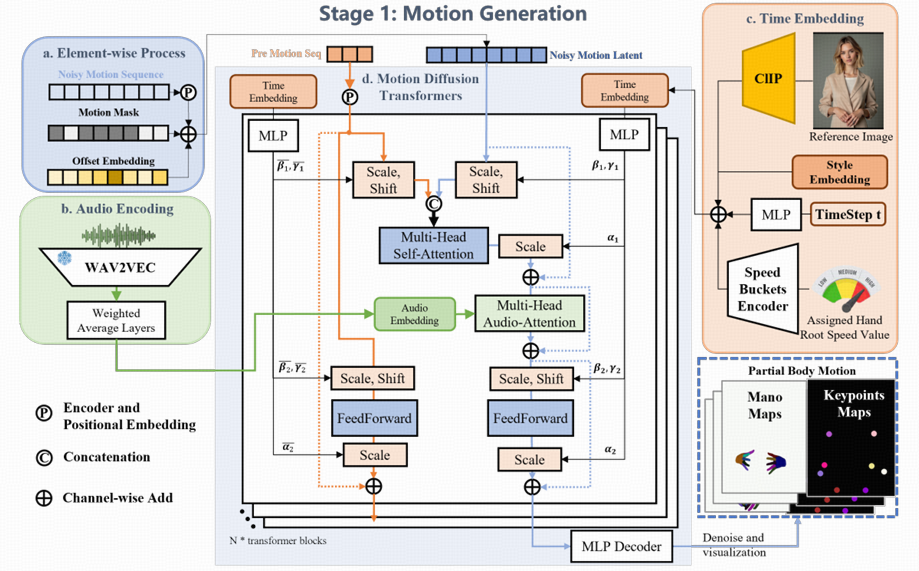
3.1 音频编码器
音频编码器接收时序音频信号作为输入,提取其局部语义信息和全局情绪特征。EMO2利用 wav2vec2.0 预训练模型来提取高维语音表示,捕捉音频中的语音节奏、语调、强度等潜在驱动因素。
输出包括:
- 逐帧语音特征(Frame-level audio embedding)
- 韵律与情感信息(Global prosody vector)
3.2 末端执行器预测网络(手部动作生成)
EMO2 的核心创新点在于引入末端执行器引导机制,该机制首次应用于音频驱动的人体生成任务中。将手部动作作为末端执行器,利用上半身的预定义关键点,作为视频生成的弱监督信号,采用的是 Diffusion Transformer(DiT ) 作为主干网络,利用交叉注意力机制联结音频特征和噪声运动潜变量,并嵌入时间步。
基于音频特征,通过注意力机制,生成与语音节奏一致的MANO手部系数, 从而获得符合语音语调和节奏的手势。为了保证连续片段之间的平滑过渡,前一片段的运动序列的最后几帧被拼接到当前运动序列中,确保动作的流畅性和连贯性。
3.3 视频生成模块(Video Renderer / Image Synthesizer )
视频生成模块基于EMO,骨干网络接收多帧噪声潜在输入,并在每个时间步中尝试去噪,生成连续的视频帧。该框架可以分为四个部分:
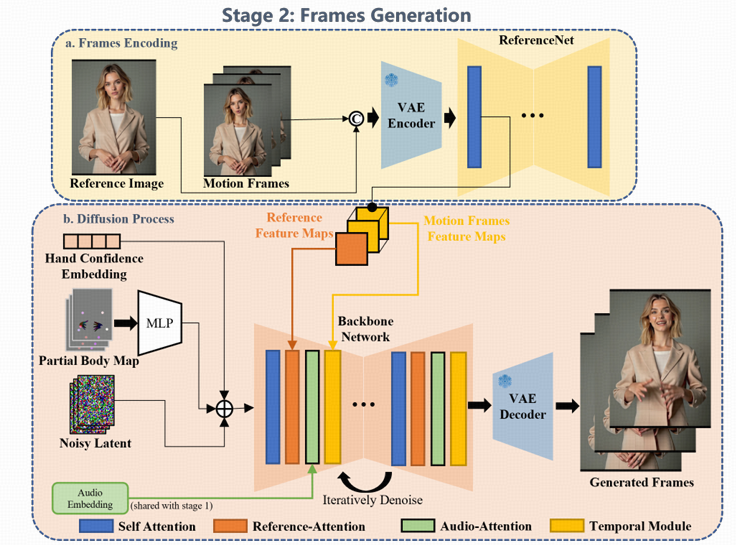
- 去噪:骨干网络是一个去噪的2D-UNet,并集成了来自AnimateDiff 间模块。这个网络负责在每个时间步中逐步去除噪声,并生成连续的视频帧。
- 帧参考:为了保持角色的身份,我们将ReferenceNet与骨干网络并行部署,输入参考图像和运动帧,以获取2D图像特征。这些特征通过跨注意力机制分别注入骨干网络的空间和时间维度。
- 音频驱动:为了通过音频驱动角色,第一阶段共享的音频特征通过跨注意力机制与骨干网络的潜在特征相结合,从而实现音频与角色动作的同步。
- 运动引导:第一阶段生成的MANO映射和关键点映射被按通道拼接,并与潜在特征一起集成,以调节身体运动,从而实现更加自然且精准的动作生成。
3.4 运动控制模块
- 运动控制模块利用末端执行器预测网络生成的MANO映射引导角色的运动。这些映射明确描述了生成帧中的手部运动,涵盖形状、大小和姿势等方面。 并使用MANO手部检测的置信度分数。这些分数在遇到显著遮挡或运动模糊的情况下可能会降低,作为条件输入来增强生成的手部质量。
- 初步实现使用了仅手部控制信号,使得其他身体部位可以与音频信号和手部运动同步。然而,MANO手部信号的大幅度运动通常与静止的躯干不兼容,导致视频中的表现显得不自然(所以说文章提出的改进逆向运动学其实效果也不怎么好?)。为了解决这一问题,EMO2引入了关节关键点来补充运动驱动方法,这些关键点映射表示了手臂和腿部关节的二维位置。
4. 实验
4.1 数据集
MOSEI 简介:
数据类型:
- 视频(包含人脸、语音和文本信息)
- 对象为网络中真实人物的访谈、演讲等短视频片段
标注:
- 情感极性评分([-3, 3],例如:-3为非常负面,3为非常正面)
- 情绪标签(7类:快乐、愤怒、惊讶、厌恶、悲伤、恐惧、中性)
AVSpeech 简介:
数据类型:
- 来自 YouTube 的讲话者视频(“in-the-wild”)
- 每个片段包含:清晰人脸视频 + 对应的干净语音
数据特点:
- 仅包含一个人说话的片段,背景干扰较少
- 没有转录文本,仅提供音频和视频模态
EMTD简介:
- 用于音频驱动的人体上半身表达生成任务的多模态数据集。它的目标是推动真实感强、表达丰富的音频驱动人体动画技术的发展,特别关注于面部表情、手势动作与语音内容的自然匹配与同步。
数据类型: 视频、音频、3D人体关键点、文本转录、情感标签和动作标签
标注:面部动作、手部动作、上半身姿势动作都有具体标注
4.2 评价指标
手部动作生成评价指标
- DIV(Diversity,多样性):
计算多个生成样本之间的欧式距离或分布距离,较高的 DIV 表示模型具有更强的表达能力,能生成更多样、 生动且不重复的动作;较低的 DIV 可能说明模型模式崩溃或生成内容单一。 - BA(Beat Alignment,节拍对齐):
计算节拍位置与“运动峰值”的对齐度,较高的 BA 表示生成的手势、身体动作等能更好地跟随语音节奏,增强自然性和表现力。 - PCK(Percentage of Correct Keypoints):
较高的 PCK 说明生成动作在空间上更接近真实数据,通常用于检测动作是否合理、逼真。 - FGD(Fréchet Gesture Distance):
较低的 FGD 表明生成动作的风格、动态特征更接近真实分布,是衡量“自然性”的重要指标。
视频生成评价指标
- FID
FID度量生成图像与真实图像之间的距离 , 基于Fréchet距离,衡量生成样本的特征分布与真实样本的特征分布的差异。数值越低,表示生成图像的质量越接近真实图像。 - 结构相似性指数(SSIM)
SSIM度量图像的结构相似性,考虑了亮度、对比度和结构信息的影响。其计算方式是将图像分成小块,分别计算每个块的SSIM值,然后综合得出图像的整体SSIM值,值越高说明生成的图像与参考图像在结构上越相似。 - 峰值信噪比(PSNR)
PSNR用于评估图像重建的误差,它通过计算图像的最大像素值与均方误差(MSE)之间的关系来衡量质量。PSNR的值越高,表示图像的质量越好。 - Fréchet Video Distance(FVD)
FVD是通过计算生成视频和真实视频的Fréchet距离来度量它们之间的差异,值越高说明生成视频与真实视频之间的差异越大,即生成视频的质量越差。
4.3 实验结论
手部动作生成对比实验结果

在对比实验中,EMO2基于 MANO 模型,相较于其他基于 SMPL 的方法,在多个指标上展现了显著优势:
- DIV(多样性):文章的MANO 方法在 DIV 指标上遥遥领先,显示了更高的手部动作生动性和表现力。其他基于 SMPL 的方法往往生成单调、重复的动作,即使起始手势不同,手部动作也倾向于维持在胸前或停留在初始位置,缺乏多样性。
- BA(节拍对齐):在 BA 指标上,文章的 MANO 方法同样表现优越,能够更好地与音频节奏同步。这两个指标(DIV 和 BA)在生成生动且富有表现力的共语驱动信号方面至关重要,有助于提升下一阶段视频生成的质量。
- PCK 和 FGD:尽管在 PCK(接近真实动作的比例)和 FGD(生成动作分布与真实动作分布之间的距离)上,文章的方法得分较低可以预见(文章没有给出这两个指标结果)。其他基于 SMPL 的方法通过正向运动学计算手部动作,容易生成与真实动作更为接近的结果,而我们的 MANO 方法则具有更大的自由度,可以生成与真实动作有所不同的手部运动,导致这些指标的得分较低。
视频生成对比试验结果

- 图像质量:从 FID、SSIM 和 PSNR 指标的提升可以看出,此文章的方法在生成单帧图像质量方面优于其他方法。特别是在使用原始姿态作为驱动(“w/o motion gen”)的实验设置中,由于与真实标签更加一致,进一步提升了生成图像和视频的质量。
- 动作多样性:尽管“w/o motion gen”设定下图像质量提升明显,但相对较低的 HKV 值表明动作缺乏变化。相比之下,文章的完整方法具备更高的 HKV 值,显示出在保持合理性的前提下能够生成更丰富、更具表现力的动作序列。
- 身份一致性与面部表现力:文章的方法能够更好地保持人物身份一致性,这从更高的 CSIM 值中得到验证。同时,更低的 EFID 值也证明了EMO2能生成更生动、自然的面部表情。
![[Redis] Redis:高性能内存数据库与分布式架构设计](http://pic.xiahunao.cn/[Redis] Redis:高性能内存数据库与分布式架构设计)






 Naflex模型的动态分辨率原理)






)



)
