Rust 学习笔记:处理任意数量的 future
- Rust 学习笔记:处理任意数量的 future
- 竞争的 future
- 将控制权交给运行时
- 构建我们自己的异步抽象
Rust 学习笔记:处理任意数量的 future
当两个 future 切换到三个 future 时,我们也必须从使用 join 切换到使用 join3。每次我们改变想要加入的 future 的数量时,都必须调用不同的函数,这是很烦人的。
幸运的是,我们有一个宏形式的 join,可以向其传递任意数量的参数,它还处理等待 future 本身。
trpl::join!(tx1_fut, tx_fut, rx_fut);
将 future 推入集合,然后等待它们的部分或全部 future 完成是一种常见的模式。要检查某个集合中的所有 future,我们需要遍历并连接所有这些 future。trpl::join_all 函数接受任何实现了 Iterator trait 的类型。
let futures = vec![tx1_fut, rx_fut, tx_fut];
trpl::join_all(futures).await;
然而,上述代码不能通过编译。因为编译器会为每个异步块创建一个唯一的枚举,不能在数组中放入两个不同的手写结构体,同样的规则也适用于编译器生成的不同枚举。
你可能会想到使用 Enum 来表示 vector 中可能出现的每种类型,但我们在这里做不到。我们没有办法命名不同的类型,因为它们是匿名的。
真正的解决办法是使用 trait 对象,这可以让我们将这些类型产生的每个匿名 Future 视为相同的类型,因为它们都实现了 Future trait。
let futures =vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)];
trpl::join_all(futures).await;
不幸的是,这段代码仍然无法编译。事实上,对于第二个和第三个 Box::new 调用,我们得到了与之前相同的基本错误,以及引用 Unpin trait 的新错误。
首先,让我们通过显式注释 futures 变量的类型来修复 Box::new 调用上的类型错误。
let futures: Vec<Box<dyn Future<Output = ()>>> =vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)];
这个类型声明有点复杂,所以让我们从头开始:
- 最内在的类型是 futrue 本身。通过写 Future<Output = ()>,我们显式地注意到未来的输出是单位类型 ()。
- 然后我们用 dyn 注释这个特性,把它标记为动态的。
- 整个 trait 引用被包装在一个 Box 中。
- 最后,我们明确指出,futrue 是包含这些项目的 Vec。
use std::pin::Pin;// -- snip --let futures: Vec<Pin<Box<dyn Future<Output = ()>>>> =vec![Box::pin(tx1_fut), Box::pin(rx_fut), Box::pin(tx_fut)];
现在修复第二个错误。错误信息提示第一个异步块不实现 Unpin trait,建议使用 pin! 或 Box::pin 来解决它。
我们可以按照编译器的建议来解决问题。我们首先从 std::pin 导入 Pin。接下来,我们更新 future 的类型注释,用一个 Pin 包装每个 Box。最后,我们使用 Box::pin 来固定 future 本身。
现在,程序可以正常运行了。
使用 Pin<Box<T>> 会增加少量的开销,因为使用 Box 将这些 future 放在堆上——我们这样做只是为了使类型对齐。我们实际上并不需要堆分配,毕竟这些 future 是这个特定函数的局部。如前所述,Pin 本身是一种包装器类型,因此我们可以获得在 Vec 中使用单一类型的好处——这是我们使用 Box 的最初原因——而无需进行堆分配。我们可以使用 std::pin::pin 宏直接对每个 future 使用 Pin。
然而,我们仍然必须明确固定引用的类型;否则,Rust 仍然不知道将它们解释为动态 trait 对象,这是我们在 Vec 中需要的。因此,我们将 pin 添加到 std::pin 的导入列表中。然后,我们可以在定义每个 future 时使用 pin! 将其固定,并将 future 定义为包含对动态 future 类型的固定可变引用的 Vec。
use std::pin::{Pin, pin};// -- snip --let tx1_fut = pin!(async move {// --snip--});let rx_fut = pin!(async {// --snip--});let tx_fut = pin!(async move {// --snip--});let futures: Vec<Pin<&mut dyn Future<Output = ()>>> =vec![tx1_fut, rx_fut, tx_fut];我们忽略了我们可能有不同的输出类型这一事实。例如:
let a = async { 1u32 };let b = async { "Hello!" };let c = async { true };let (a_result, b_result, c_result) = trpl::join!(a, b, c);println!("{a_result}, {b_result}, {c_result}");
其中,a 的匿名 future 实现 Future<Output = u32>, b 的匿名 future 实现 Future<Output = &str>, c 的匿名 future 实现 Future<Output =bool>。
我们可以使用 trpl::join! 等待它们,因为它允许我们传入多个 future类型并生成这些类型的元组。我们不能使用 trpl::join_all,因为它要求传入的所有 future 都具有相同的类型。
这是一个基本的权衡:我们可以使用 join_all 处理动态数量的 future,只要它们都具有相同的类型,或者我们可以使用 join 函数或 join! 宏来处理固定数量的 future,即使它们有不同的类型。
竞争的 future
当我们使用名字带 join 的函数和宏时,我们需要在继续之前完成所有的 future。
trpl::race 则不同,传入的 future 将彼此竞争。
let slow = async {println!("'slow' started.");trpl::sleep(Duration::from_millis(100)).await;println!("'slow' finished.");};let fast = async {println!("'fast' started.");trpl::sleep(Duration::from_millis(50)).await;println!("'fast' finished.");};trpl::race(slow, fast).await;
每个 future 在开始运行时打印一条消息,通过调用和等待 sleep 暂停一段时间,然后在结束时打印另一条消息。然后我们通过创建 slow 和 fast,等待其中一个 future 完成“比赛”。这里忽略了 trpl::race 返回的 Either 实例,因为我们不在乎。
注意,如果将 trpl::race 的参数变换顺序,则“started”消息的顺序将发生变化,尽管 fast future 总是先完成。这是因为这个特殊的 race 函数的实现是不公平的,它总是按照传入的顺序运行作为参数的 future。其他实现是公平的,将随机选择先轮询哪个 future。
在每个等待(await)点,如果等待的未来还没有准备好,Rust 会给运行时(runtime)一个暂停任务并切换到另一个任务的机会。反之亦然:Rust 只暂停异步块,并在等待点将控制权交还给运行时。等待点之间的一切都是同步的。
这意味着,如果你在一个异步块中做了一堆工作,而没有等待点,那么这个 future 将阻止任何其他 future 取得进展。
这被称为一个 future "饿死"其他 future。
在某些情况下,这可能不是什么大事。但是,如果正在进行某种昂贵的设置或长时间运行的工作,或者如果将来要无限期地执行某些特定的任务,则需要考虑何时何地将控制权交还给运行时。
同样的道理,如果你有长时间运行的阻塞操作,异步可以是一个有用的工具,为程序的不同部分提供相互关联的方法。
但是在这些情况下,如何将控制权交还给运行时呢?
将控制权交给运行时
让我们模拟一个长时间运行的操作。
fn slow(name: &str, ms: u64) {thread::sleep(Duration::from_millis(ms));println!("'{name}' ran for {ms}ms");
}
这段代码使用 std::thread::sleep 而不是 trpl::sleep,这样调用 slow 会阻塞当前线程。
使用 slow 来模拟在一对 future 中执行 CPU 密集型工作。
let a = async {println!("'a' started.");slow("a", 30);slow("a", 10);slow("a", 20);trpl::sleep(Duration::from_millis(50)).await;println!("'a' finished.");};let b = async {println!("'b' started.");slow("b", 75);slow("b", 10);slow("b", 15);slow("b", 350);trpl::sleep(Duration::from_millis(50)).await;println!("'b' finished.");};trpl::race(a, b).await;
每个 future 只在执行了一堆缓慢的操作后才将控制权交还给运行时。如果你运行这段代码,你会看到这样的输出:
'a' started.
'a' ran for 30ms
'a' ran for 10ms
'a' ran for 20ms
'b' started.
'b' ran for 75ms
'b' ran for 10ms
'b' ran for 15ms
'b' ran for 350ms
'a' finished.
与前面的示例一样,a 和 b 的竞争仍然在 a 完成后立即结束。不过,这两个 future 之间并没有交集。a future 在等待 trpl::sleep 调用之前完成所有的工作,然后 b future 在等待自己的 trpl::sleep 调用之前完成所有的工作,最后 a future 完成。
假如们在 a future 的末尾删除 trpl::sleep,它将在 b future 完全不运行的情况下完成。
为了允许两个 future 在它们缓慢的任务之间取得进展,我们需要等待点,这样我们就可以将控制权交还给运行时。这意味着我们需要一些可以等待的东西!
修改代码:
let one_ms = Duration::from_millis(1);let a = async {println!("'a' started.");slow("a", 30);trpl::sleep(one_ms).await;slow("a", 10);trpl::sleep(one_ms).await;slow("a", 20);trpl::sleep(one_ms).await;println!("'a' finished.");};let b = async {println!("'b' started.");slow("b", 75);trpl::sleep(one_ms).await;slow("b", 10);trpl::sleep(one_ms).await;slow("b", 15);trpl::sleep(one_ms).await;slow("b", 350);trpl::sleep(one_ms).await;println!("'b' finished.");};
我们在每次调用之间添加带有等待点的 trpl::sleep 调用。现在,这两个 future 的工作交织在一起。每次其中一个 future 到达等待点时,另一个 future 就开始执行。
'a' started.
'a' ran for 30ms
'b' started.
'b' ran for 75ms
'a' ran for 10ms
'b' ran for 10ms
'a' ran for 20ms
'b' ran for 15ms
'a' finished.
每次想要切换 future 时就调用 trpl::sleep(one_ms).await 还是不够好,我们只需要把控制权交还给运行时。使用 yield_now 函数直接做到这一点。我们用 yield_now 替换了所有这些 trpl::sleep 调用。
let a = async {println!("'a' started.");slow("a", 30);trpl::yield_now().await;slow("a", 10);trpl::yield_now().await;slow("a", 20);trpl::yield_now().await;println!("'a' finished.");};let b = async {println!("'b' started.");slow("b", 75);trpl::yield_now().await;slow("b", 10);trpl::yield_now().await;slow("b", 15);trpl::yield_now().await;slow("b", 350);trpl::yield_now().await;println!("'b' finished.");};
这段代码不仅更清楚地表明了实际意图,而且因为没有了 sleep,代码执行更快了。但要记住,yield_now 并不是免费的,仍存在细微的开销。
性能对比程序:
use std::time::{Duration, Instant};fn main() {trpl::run(async {let one_ns = Duration::from_nanos(1);let start = Instant::now();async {for _ in 1..1000 {trpl::sleep(one_ns).await;}}.await;let time = Instant::now() - start;println!("'sleep' version finished after {} seconds.",time.as_secs_f32());let start = Instant::now();async {for _ in 1..1000 {trpl::yield_now().await;}}.await;let time = Instant::now() - start;println!("'yield' version finished after {} seconds.",time.as_secs_f32());});
}
输出:
'sleep' version finished after 1.3959756 seconds.
'yield' version finished after 0.0003042 seconds.
可以看出 yield_now 的开销相比于 sleep 可以说是微乎其微。
通过调用 yield_now,每个 future 都有能力通过等待点决定何时移交控制权。因此,每个 future 也有责任避免阻塞太久。
构建我们自己的异步抽象
我们也可以共同构建未来,创造新的模式。例如,我们可以用已有的异步构建块构建超时函数。当我们完成后,结果将是另一个构建块,我们可以使用它来创建更多的异步抽象。
先介绍一下 timeout API:
async fn timeout<F: Future>(future_to_try: F,max_time: Duration,
) -> Result<F::Output, Duration> {match trpl::race(future_to_try, trpl::sleep(max_time)).await {Either::Left(output) => Ok(output),Either::Right(_) => Err(max_time),}
}
timeout 本身需要是一个 async 函数,这样我们才能等待它。它的第一个参数是要运行的任意类型的 future。它的第二个参数是最长等待时间。它返回一个 Result。如果 future 成功完成,结果就是 future 返回的值。如果超时,Result 将为 Err,并显示超时等待的持续时间。
我们想让 future_to_try 这个 future 与给定的时间 max_time 赛跑。trpl::race 是不公平的,按传递的顺序轮询参数。因此,我们首先将 future_to_try 传递给 race,这样即使 max_time 的持续时间非常短,它也有机会完成比赛。如果 future_to_try 先完成,race 将返回 Left,其中有 future_to_try 的输出。如果计时器先完成,race 将返回 Right,计时器的输出为 ()。如果 future_to_try 成功并且得到 Left(output),则返回 Ok(output)。如果睡眠计时器先结束,我们得到一个 Right(()),我们忽略其中的 () 并返回 Err(max_time)。
use std::time::Duration;
use trpl::Either;async fn timeout<F: Future>(future_to_try: F,max_time: Duration,
) -> Result<F::Output, Duration> {// skip
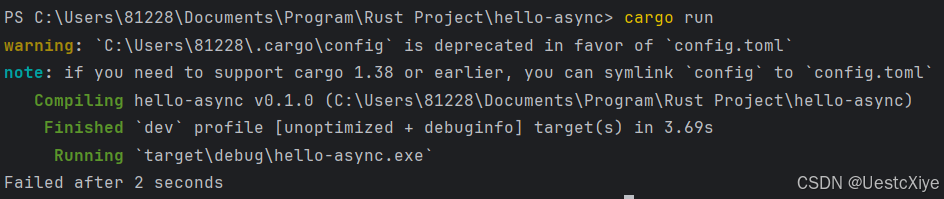
}fn main() {trpl::run(async {let slow = async {trpl::sleep(Duration::from_secs(5)).await;"Finally finished"};match timeout(slow, Duration::from_secs(2)).await {Ok(message) => println!("Succeeded with '{message}'"),Err(duration) => {println!("Failed after {} seconds", duration.as_secs())}}});
}
这样,我们就有了一个由另外两个异步帮助程序构建的工作超时。如果我们运行代码,它将在超时后打印失败模式:

)


)

)









)


