孪生扩散模型,生成息肉图像用于提升分割性能!
论文:Noise-Consistent Siamese-Diffusion for Medical Image Synthesis and Segmentation
代码:https://github.com/Qiukunpeng/Siamese-Diffusion
0、摘要
深度学习已彻底革新医学影像分割,但其潜力仍受限于标注数据极度匮乏。尽管扩散模型被视为生成合成图像-掩膜对以扩充数据的有前景手段,它们却陷入“用少量数据解决数据稀缺”的悖论。(这个悖论有点意思哈哈)
传统仅生成掩膜的模型因难以刻画精细解剖结构,常导致图像保真度低,进而削弱分割模型的稳健性与可靠性。(当前不足)
为此,本文提出 Siamese-Diffusion:一种由 Mask-Diffusion 和 Image-Diffusion 组成的双组件框架。
训练阶段,两组件间通过噪声一致性损失约束参数空间,显著提升 Mask-Diffusion 的形态保真度;采样阶段仅调用 Mask-Diffusion,兼顾多样性与可扩展性。
大量实验表明,Siamese-Diffusion 在 Polyps 数据集上将 SANet 的 mDice 和 mIoU 分别提升 3.6% 与 4.4%,在 ISIC2018 数据集上使 UNet 的 mDice 和 mIoU 分别提升 1.52% 与 1.64%。
1、引言
1.1、研究意义与当前挑战
(1)虽然生成模型旨在缓解分割模型的数据稀缺问题,但它们自身却面临着同样的挑战;(生成模型也没有足够的数据,ԾㅂԾ,)
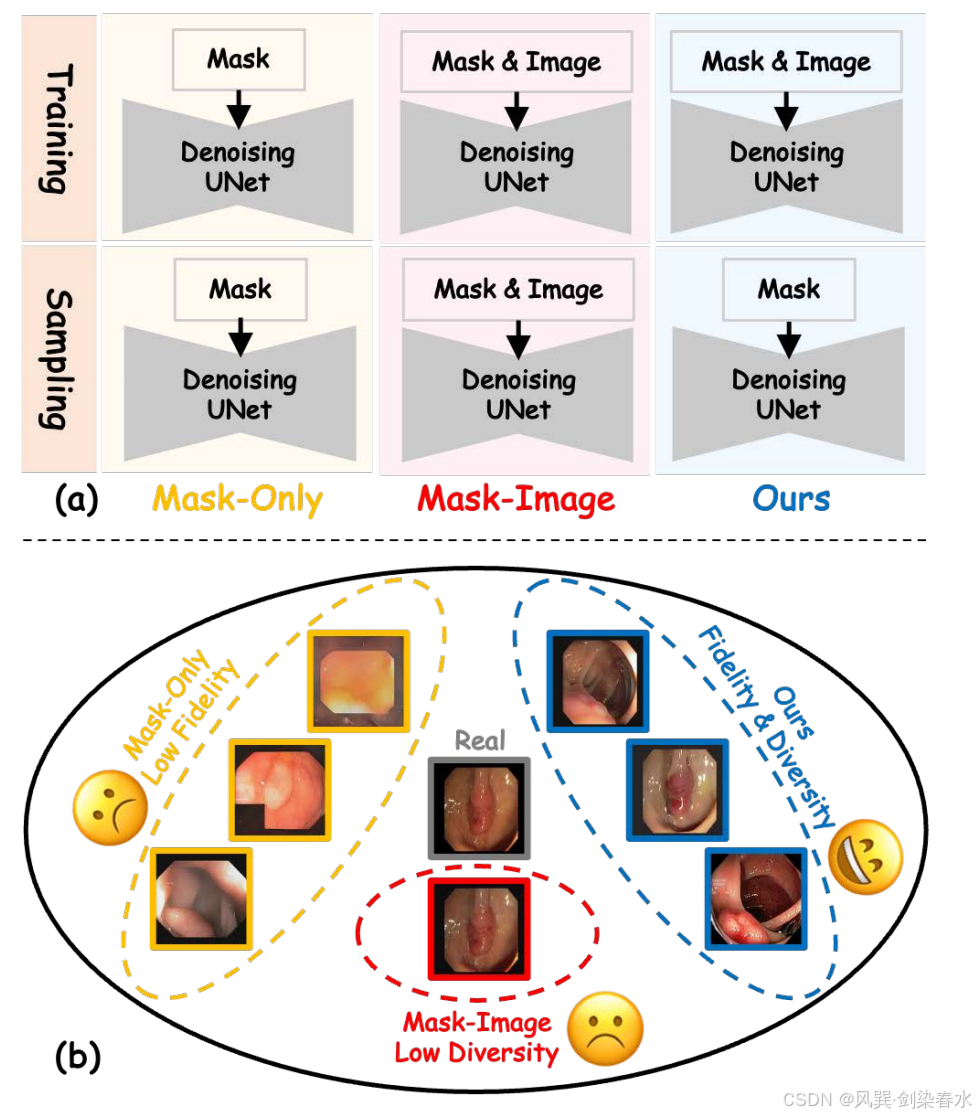
(2)如 图 1(a) 所示,仅生成掩膜的模型主要关注病灶形状与掩膜的对齐,容易陷入局部极小值,导致形态保真度偏低;
(3)如 图 1(b) 黄色方框所示,合成医学影像常缺失关键形态特征(如表面纹理),此类缺失使得分割模型难以学习具有辨识力的病灶特征,造成模型可解释性不足且表现难以捉摸,显著削弱了增强分割模型的可靠性;
Figure 1 | :(a)本文的方法与现有方法在训练和采样阶段的工作流程对比;(b)各方法合成图像的差异;仅使用掩膜的方法(黄色)缺乏形态特征(如表面纹理),导致保真度较低;掩膜-图像方法(红色)生成高保真图像,但其依赖额外的图像先验控制导致多样性不足且扩展性差;本文的方法(蓝色)在保持多样性的同时提升了形态特征的保真度;
1.2、本文贡献
(1)本文发现,当前的生成模型和医学图像分割模型都面临着相同的数据稀缺问题,导致形态学保真度较低;本文认为,只有包含必要形态特征的合成医学图像,才能确保增强型分割模型的可靠性;
(2)提出了一种名为“孪生扩散模型”的方法,该模型通过噪声一致性损失和图像扩散技术,引导掩模扩散算法在保持高形态保真度的前提下找到局部最优解;在采样过程中,仅使用掩模扩散算法来合成具有真实形态特征的医学图像;
(3)大量实验表明,本文方法在图像质量与分割性能方面均优于现有方法。SANet 在息肉数据集上使 mDice 和 mIoU 分别提升 3.6% 和 4.4%,而 UNet 在 ISIC2018 数据集上实现 1.52% 和 1.64% 的性能提升,充分彰显了本方法的优越性;
2、方法
2.1、基础
原文略,可参考 【Diffusion综述】医学图像分析中的扩散模型(一) 中的 2.2 节
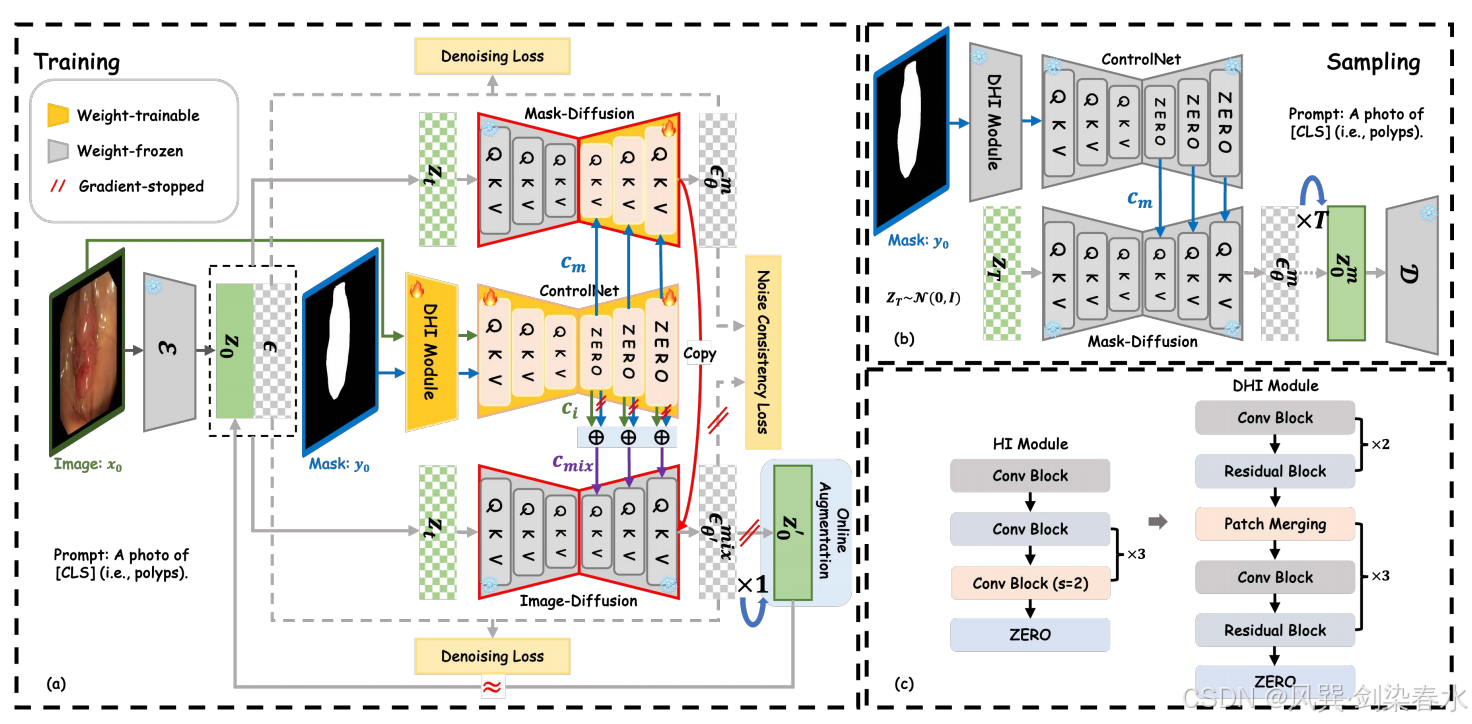
2.2、孪生扩散模型结构
ControlNet 和预训练的 Stable Diffusion 构成了本文方法的基础框架。Stable Diffusion 框架中的 VQ-VAE 模块和去噪 U-Net 编码器模块均被冻结。
在训练阶段,如 图 2(a) 所示,图像 x0x_0x0 通过 VQ-VAE 编码器 E\mathcal EE 被压缩到潜在空间 z0z_0z0 中。本文提出的密集提示输入(DHI)与控制网络(ControlNet)串联组合形成特征提取网络。该网络将输入图像 x0x_0x0 及其对应掩码 y0y_0y0 编码为 cic_ici 和 cmc_mcm。随后,不同的先验控制参数 cmc_mcm 和 cmixc_{mix}cmix 被注入同一扩散模型的去噪 U-Net 解码器(即图2(a)中的“复制”模块),用于分别预测噪声 ϵθmϵ^m_θϵθm 和混合噪声 ϵθ′mixϵ^{mix}_{θ′}ϵθ′mix,此处,cmixc_{mix}cmix 是 cic_ici 和 cmc_mcm 的混合特征:
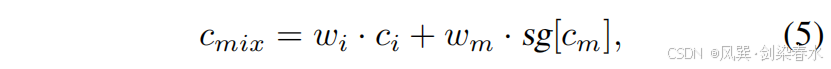
其中,wi=k/Niterw_i = k/N_{iter}wi=k/Niter 与 wmw_mwm 分别表示对图像先验与掩膜先验的控制权重;NiterN_{iter}Niter 为训练总迭代次数,kkk 为当前迭代步数。为简洁起见,仅利用掩膜(记为 cmc_mcm)以及同时利用掩膜与图像(记为 cmixc_{mix}cmix)的两种过程分别称为 Mask-Diffusion 与 Image-Diffusion。式 (5) 中的 cmc_mcm 与 Mask-Diffusion 所用项相同,并采用截断梯度。
该孪生架构与知识蒸馏模型不同,后者需同时训练教师和学生网络,计算开销较大。最终,用于训练 Siamese-Diffusion 的损失函数定义为:
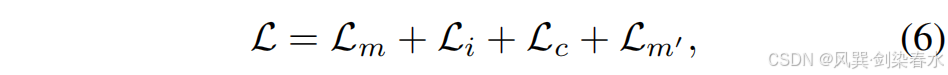
其中,Lc\mathcal L_cLc 是本文提出的噪声一致性损失函数,Lm′\mathcal L_{m′}Lm′ 源自在线增强技术,这两个部分将在后续内容中详细阐述。Lm\mathcal L_mLm 和 Li\mathcal L_iLi 分别是针对 Mask-Diffusion 和 Image-Diffusion 的去噪损失函数:
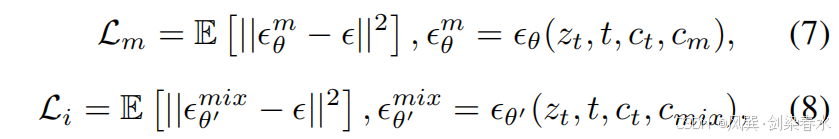
其中 θθθ 是 Mask-Diffusion 的参数,而 θ′θ′θ′ 是 θθθ 的复制。公式(7)和(8)共享相同的 ϵ∼N(0,I)ϵ∼\mathcal N(0,I)ϵ∼N(0,I)。
在采样阶段,如 图 2(b) 所示,仅使用 Mask-Diffusion 和任意掩模先验控制来合成医学图像进行分割。
Figure 2 | :(a)本文方法在训练阶段的示意图;(b)在采样阶段,仅使用 Mask-Diffusion 技术生成高保真度且多样化的合成图像;(c)通过将提示输入(HI)模块替换为提出的密集提示输入(DHI)模块,可有效增强图像中先验引导信息的提取效果;
2.3、噪声一致性损失
如前所述,在数据稀缺场景下,Mask-Diffusion 容易陷入低保真度的局部极小值,生成的医学图像会缺失表面纹理等关键形态特征。相比之下,Image-Diffusion 借助额外的图像先验控制项 x0x_0x0,能更轻松地收敛到高保真度的局部最优解。
然而,在采样阶段,来自图像 x0x_0x0 的强先验控制导致合成图像与真实图像非常相似(如 图 1(b) 所示),这限制了形态特征的多样性,并由于配对样本的稀缺性而限制了可扩展性。
为了帮助 Mask-Diffusion 从低保真度的局部极小值中逃逸,并向参数空间中更高保真度的区域移动,引入了噪声一致性损失:
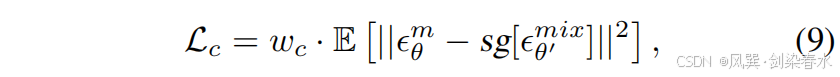
其中,Image-Diffusion 预测的噪声值 ϵθ′mixϵ^{mix}_{θ′}ϵθ′mix 比 Mask-Diffusion 预测的噪声值 ϵθmϵ^m_θϵθm 更准确,这得益于图像先验控制的额外优势。通过停止梯度操作 sgsgsg,更精确的 ϵθ′mixϵ^{mix}_{θ′}ϵθ′mix 可作为锚点,引导 Mask-Diffusion 的收敛轨迹向参数空间中更高保真的局部极小值方向发展。
图 2(a) 中的“复制”操作和等式(5)中的相同 cmc_mcm 共同确保了附加图像提供的强先验控制成功传播到 Mask-Diffusion。同时,wiw_iwi 逐渐增加,去噪损失在早期阶段起主导作用以确保稳定收敛。wcw_cwc 控制转向强度。
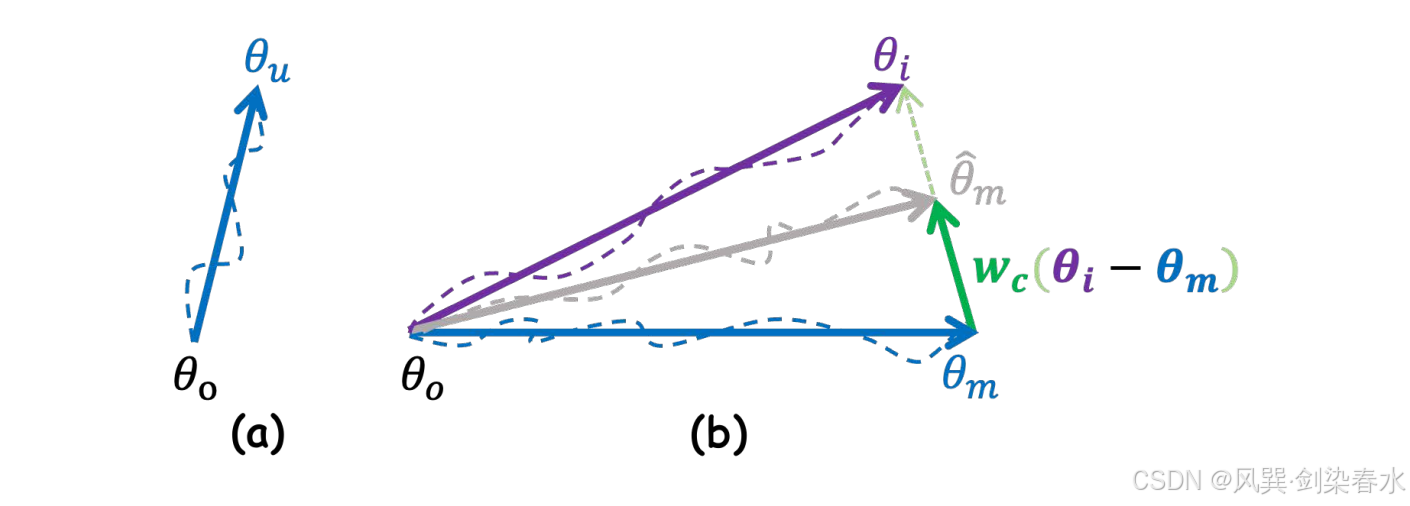
图 3 直观展示了上述操作在参数空间中的表现。通过算术运算,参数的更新方向可以通过原始模型参数 θoθ_oθo 与更新后模型参数 θuθ_uθu 之间的差异来表示。因此,Mask-Diffusion 参数的最终更新方向可近似表示为:
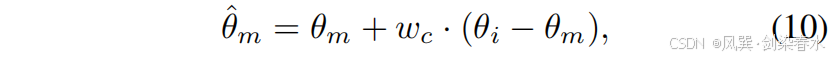
其中 θmθ_mθm 和 θiθ_iθi 是 Mask-Diffusion 与 Image-Diffusion 的参数,而 θ^m\hat θ_mθ^m 则是优化后的 Mask-Diffusion 参数。在整个过程中,特征提取网络与扩散模型的协同更新确保了掩码特征 cmc_mcm 与含噪图像特征 ztz_tzt 在潜在空间中的对齐关系,从而保证融合后的潜在特征位于合适的流形内。因此,Mask-Diffusion 在采样阶段能够独立运行。
Figure 3 | :(a) 参数更新方向;(b) Mask-Diffusion 参数更新方向,按噪声一致性损失进行缩放;
如 图 1(b) 所示,通过改进的 Mask-Diffusion 技术增强了合成图像的形态特征,使得这些图像与 Image-Diffusion 合成的图像具有竞争力。
通过这些图像增强的分割模型能确保结果的可解释性和可靠性。与通过调整样本空间中引导强度来提升保真度的无分类器引导(CFG)不同,本文提出的孪生扩散(Siamese Diffusion)方法在参数空间内增强了形态学保真度。这种创新设计有效解决了采样过程中依赖配对对照数据所带来的局限性。
2.4、密集提示输入模块
现有方法通常使用低密度语义图像作为先验控制,例如分割掩膜、深度图和草图,这类图像的特征可通过稀疏提示输入(HI)模块轻松提取。然而,对于高密度的医学图像,原始稀疏 HI 模块难以捕捉纹理、颜色等细节信息。为此,本文引入密集提示输入(DHI)模块。如 图 2(c) 所示,DHI 在主干网络中堆叠了通道数分别为 16、32、64、128 和 256 的密集残差块,并集成更先进的 patch 合并单元,从而能够同时兼容图像先验和掩膜先验。
2.5、在线增强
基于孪生扩散训练范式的优点,引入了在线增强技术来扩展掩模扩散训练集(如 图 2 (a) 所示)。通过引入额外的图像先验控制项 x0x_0x0,有效提升了图像扩散对噪声预测的准确性,从而实现单步采样在线生成 z0′z_0^{′}z0′。
在第一步中,z0′z_0^{′}z0′ 通过加噪的逆过程获得,其中 xtx_txt 被替换为 ztz_tzt,具体如下:
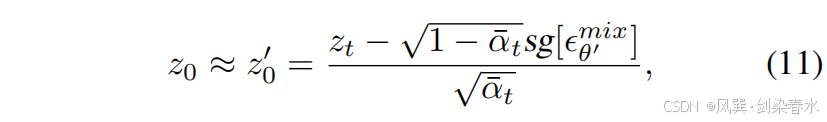
其中,sg[ϵθ′mix]sg[ϵ^{mix}_{θ′}]sg[ϵθ′mix] 表示通过带有截断梯度的 Image-Diffusion 预测的噪声。在第二步中,z0′z_0^{′}z0′ 用于近似 z0z_0z0,并与 cmc_mcm 结合以训练 Mask-Diffusion:
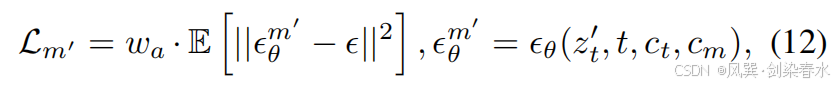
其中 ϵϵϵ 与公式等式(7)中的相同,waw_awa 控制 z0′z_0^{′}z0′ 与 cmc_mcm 之间的对齐关系:
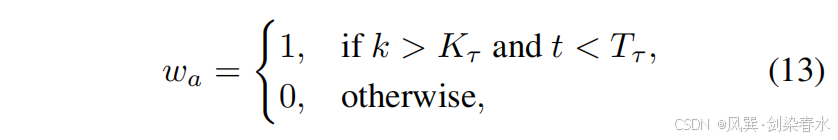
其中 kkk 表示当前迭代次数,KτK_τKτ 是迭代阈值,ttt 是时间步长,TτT_τTτ 是时间步长阈值。
3、实验与结果
3.1、数据集与评价指标
在三个公共医疗数据集——Polyps、ISIC2016 和 ISIC2018——以及两个内部数据集,Stain 和 Faeces 上进行了实验;
(1)生成模型训练集:息肉数据集共 1450 例,其中 900 例来自 Kvasir,550 例来自 CVC-ClinicDB。ISIC2016 含 900 例,ISIC2018 含 2 594 例。Stain 数据集共 500 例,Faeces 数据集共 458 例,二者均按 3∶1∶1 划分为训练、验证与测试集,对应训练集分别为 300 例与 275 例。
(2)分割模型训练集:医学数据集使用由其原训练集掩膜生成的合成图像,与原始图像合并后构成新的训练集。Stain 与 Faeces 数据集的原掩膜经过缩放等变换扩充至 1 000 例,用于训练。
(3)评估指标:图像质量采用 FID、KID、CLIP-I、LPIPS、CMMD 及平均主观评分(MOS,由 3 位资深临床医师评定,详见附录)。分割性能以 mDice 和 mIoU 度量,使用 CNN 与 Transformer 基线模型的默认设置。
3.2、实施细节
Siamese-Diffusion 以预训练的 Stable Diffusion V1.5 为骨干,在五个数据集上统一采用 AdamW 优化器继续微调:学习率 1×10−51×10⁻⁵1×10−5,权重衰减 1×10−21×10⁻²1×10−2。Polyps、ISIC2016 与 ISIC2018 的最大迭代次数设为 3000;Stain 和 Faeces 设为 1500。式 (5) 中掩膜损失权重 wmw_mwm 取 1.0。式 (13) 的迭代阈值 KτK_τKτ 经验性地设为 Niter/3N_{iter}/3Niter/3,时间步阈值 TτT_τTτ 设为 200(遵循公开实现)。经实验验证,wcw_cwc 的最佳值为 1.0。所有图像统一缩放至 384×384,并在训练中以 5% 的概率使用空提示。训练在 8 张 NVIDIA RTX 4090 上进行,单卡批次大小 6,全局批次大小 48。采样阶段采用 DDIM(η=0η=0η=0),共 50 步,指导尺度 λ=9λ=9λ=9,与已有设置一致。
4、评估与结果
4.1、图像质量评价
Table 1 | 仅使用掩膜生成息肉合成图像的质量比较,采用 FID、KID、CLIP-I、LPIPS、CMMD 及 MOS 指标进行评估:
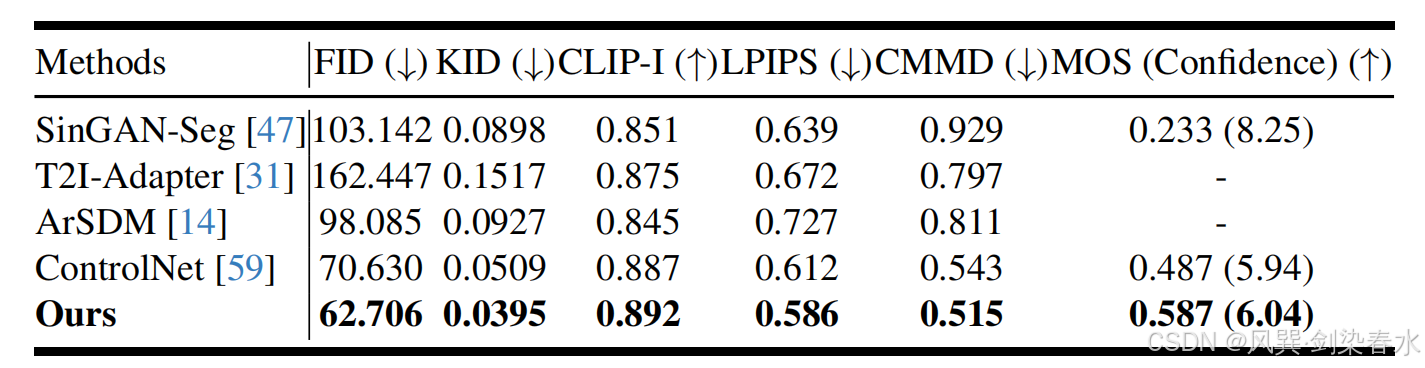
Figure 4 | 数据分布的 t-SNE 可视化: (a)-(e) 展示了真实息肉图像与各掩模方法合成图像的分布差异,本文方法生成的息肉图像分布几乎与真实数据完全重合,充分展现了其生成高度逼真息肉图像的卓越能力;
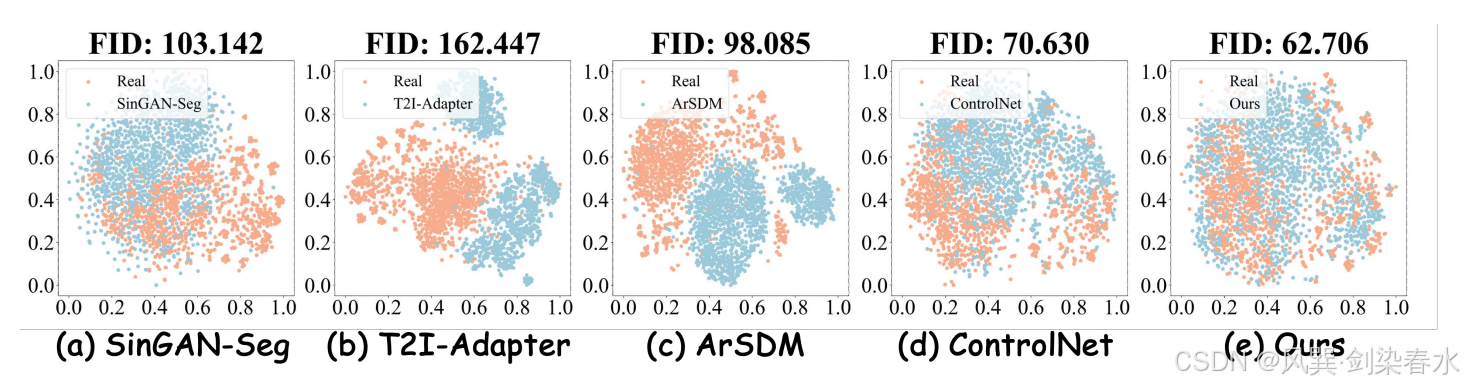
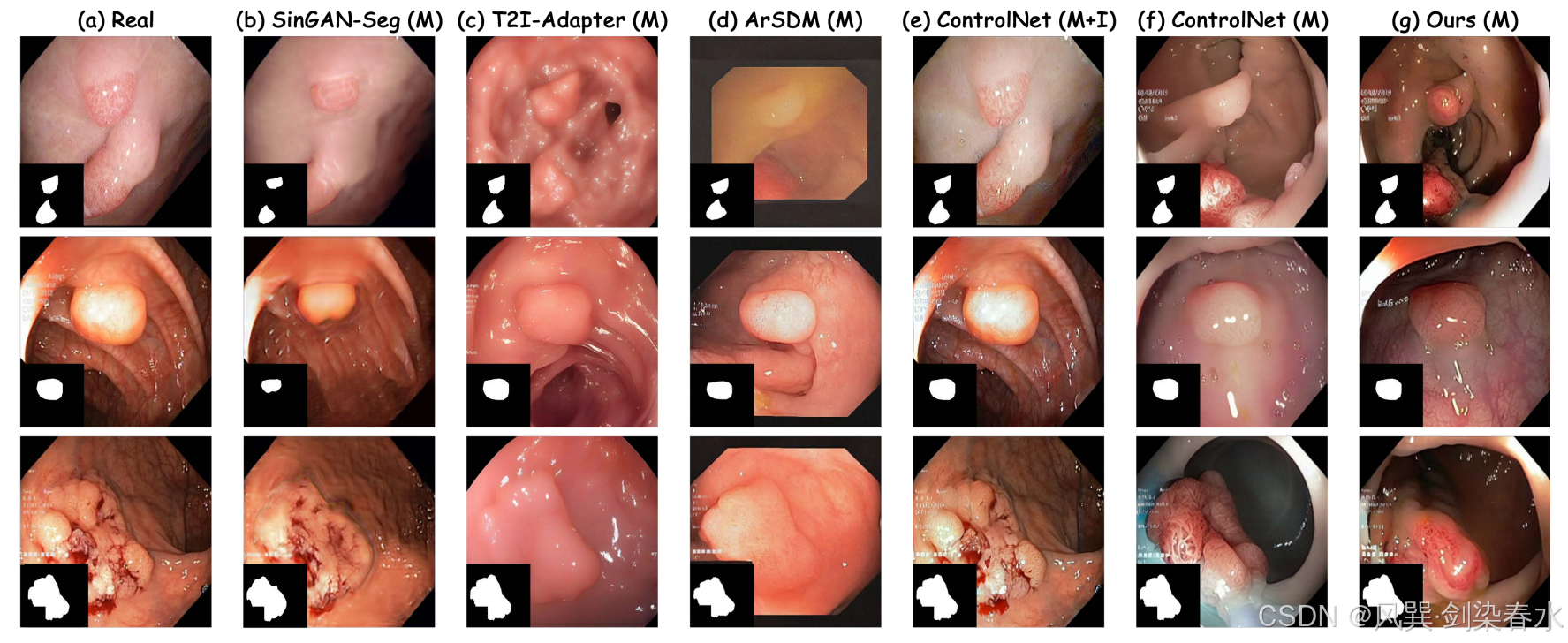
Figure 5 | 数据分布的 t-SNE 可视化:(a)实际息肉图像示例;(b)-(g)各方法生成的合成息肉图像对比;其中 “M” 表示仅使用掩膜先验控制,“M+I” 则采用掩膜-图像联合先验控制,本方法生成的合成息肉图像不仅保持了良好的形态学保真度,还展现出丰富的形态多样性;
4.2、分割性能比较
Table 2 | 以 mDice(%) 与 mIoU(%) 为指标,比较 SANet、Polyp-PVT 与 CTNet 的性能:“+” 表示训练集同时包含真实息肉图像及各方法生成的合成息肉图像;“M” 指仅用掩膜先验控制,“M+I” 指掩膜-图像联合先验控制;
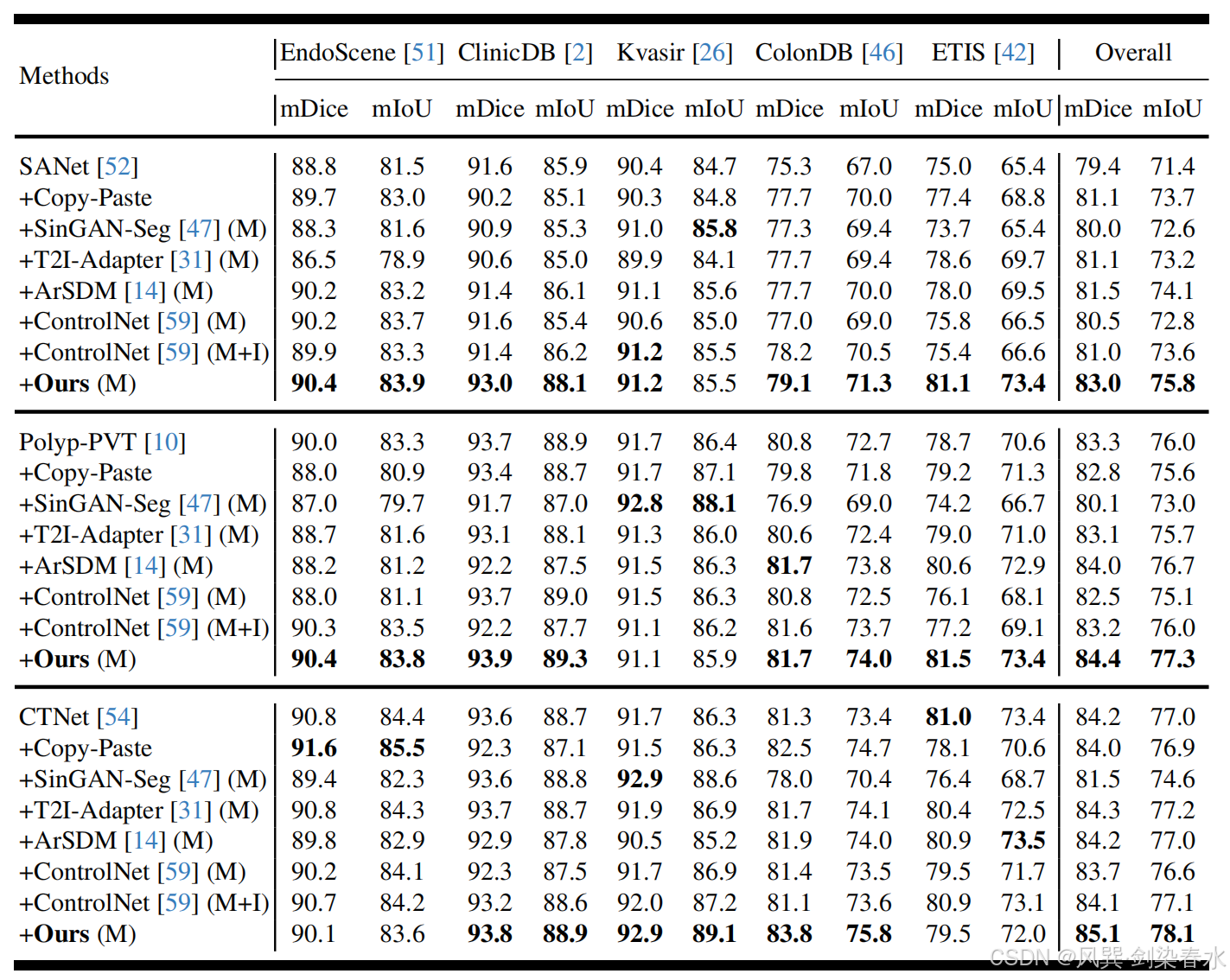
Table 3 | 以 mDice(%) 与 mIoU(%) 为指标,比较 UNet 与 SegFormer 的性能:“+” 表示训练集同时包含真实皮肤病变图像及各掩膜驱动方法生成的合成图像;“Real” 指掩膜来自真实数据,“Random” 指对真实掩膜进行变换(如缩放)后所得;
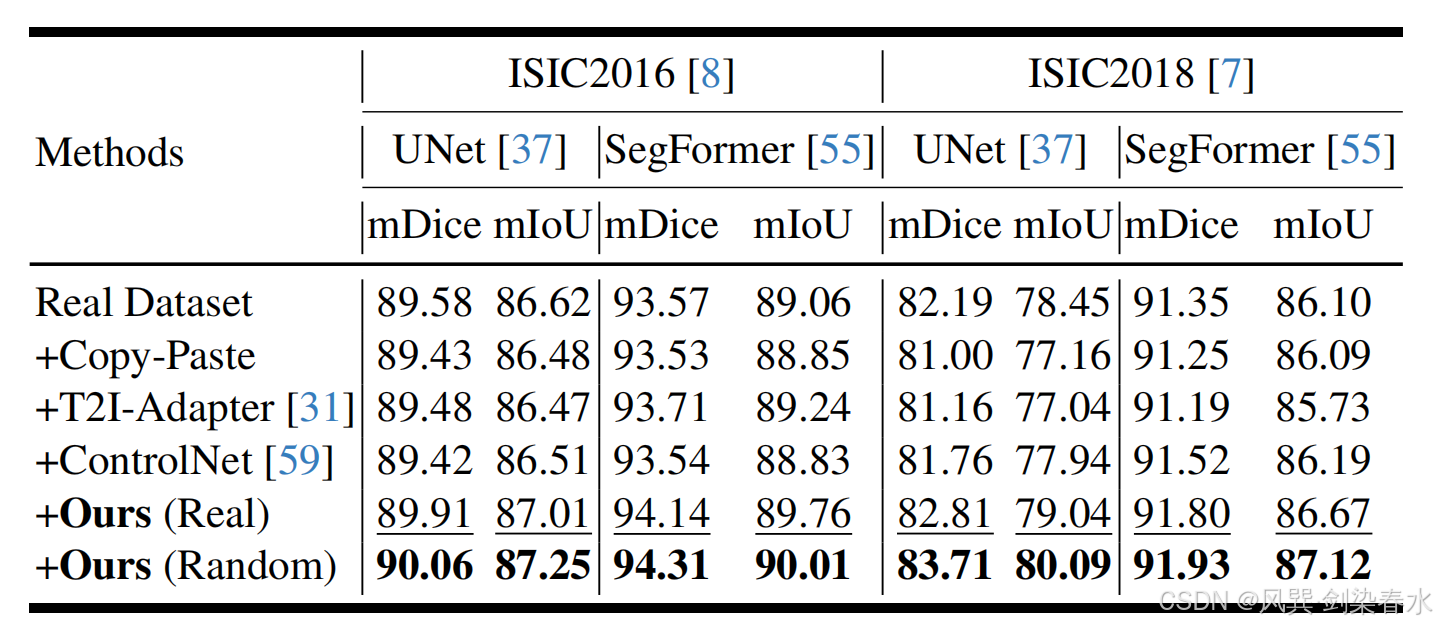
Table 4 | 以 mDice(%) 与 mIoU(%) 为指标,评估 SegFormer 的性能:训练集包含各掩膜驱动方法生成的 1000 张 Stain/Faeces 合成图像;
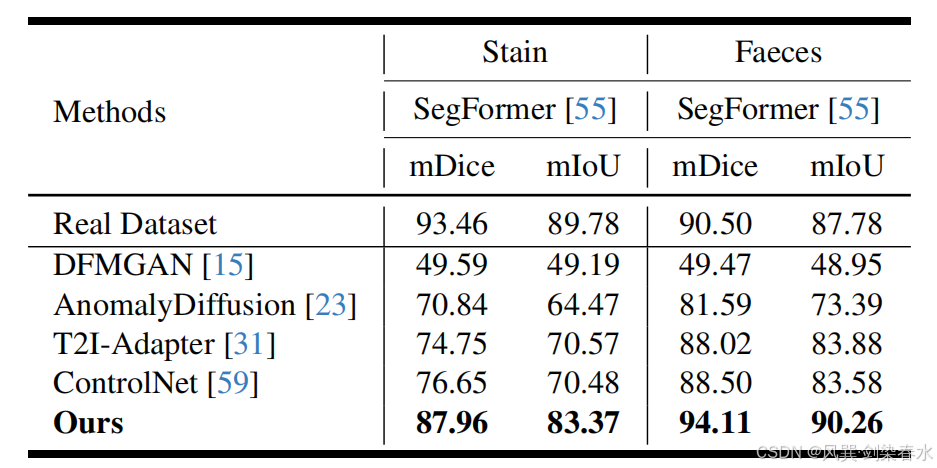
4.3、消融实验
Table 5 | 不同模块对息肉图像质量及分割性能的影响比较:图像质量以 FID、KID 和 LPIPS 评估;分割性能以加权 mDice(%) 与 mIoU(%) 在五个公共测试集上衡量;训练集由真实息肉图像与本方法在对应设置下生成的合成图像共同构成;
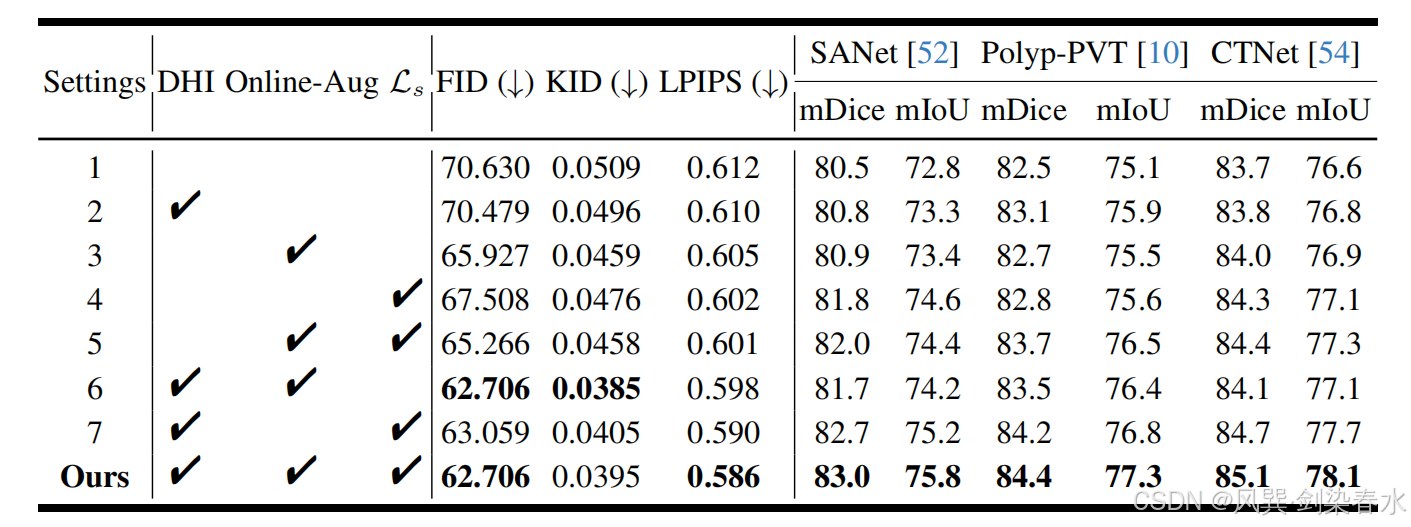
Figure 6 | 可视化不同组件对息肉图像合成的影响:
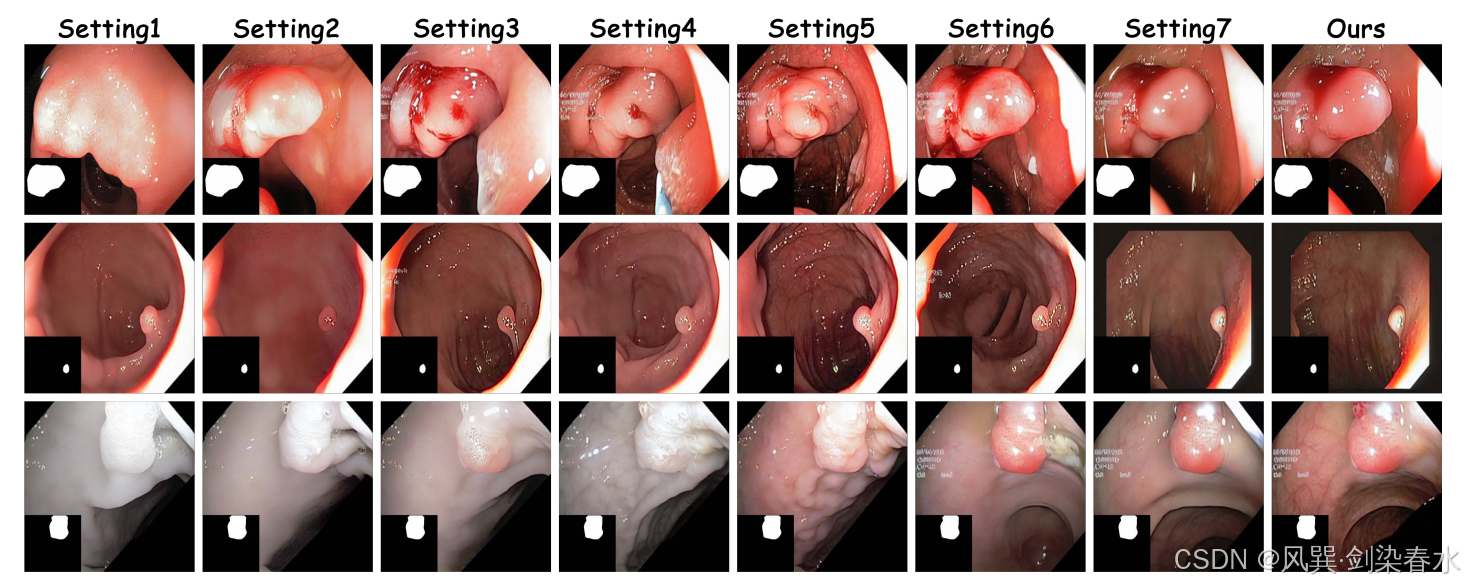
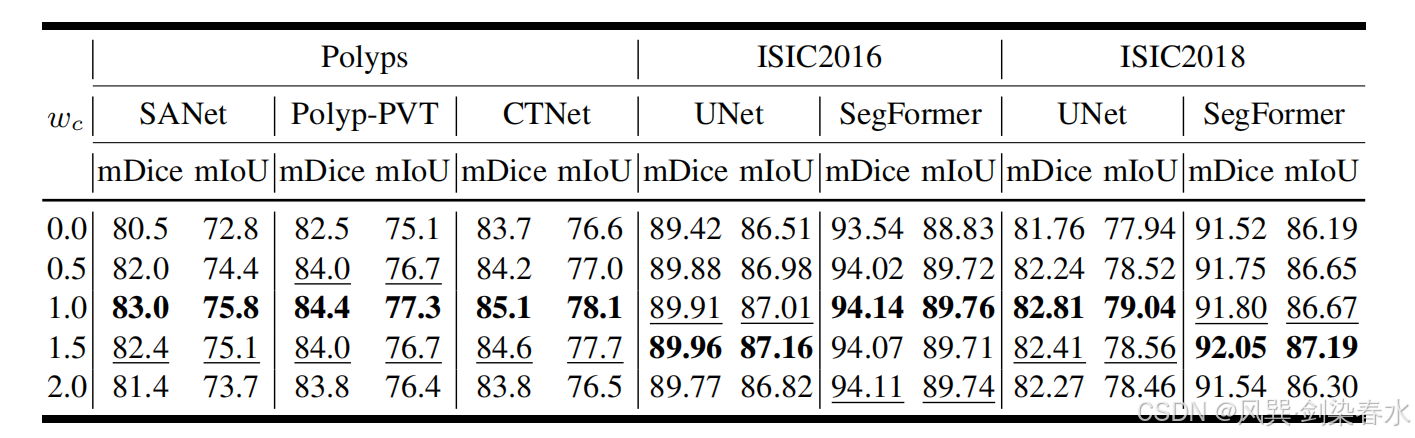
Table 6 | 以加权 mDice(%) 和 mIoU(%) 为指标,在三个数据集上比较不同 wcw_cwc 取值对医学图像分割性能的影响:训练集由真实图像与本方法在相应 wcw_cwc 下生成的合成图像共同构成;
4.4、讨论
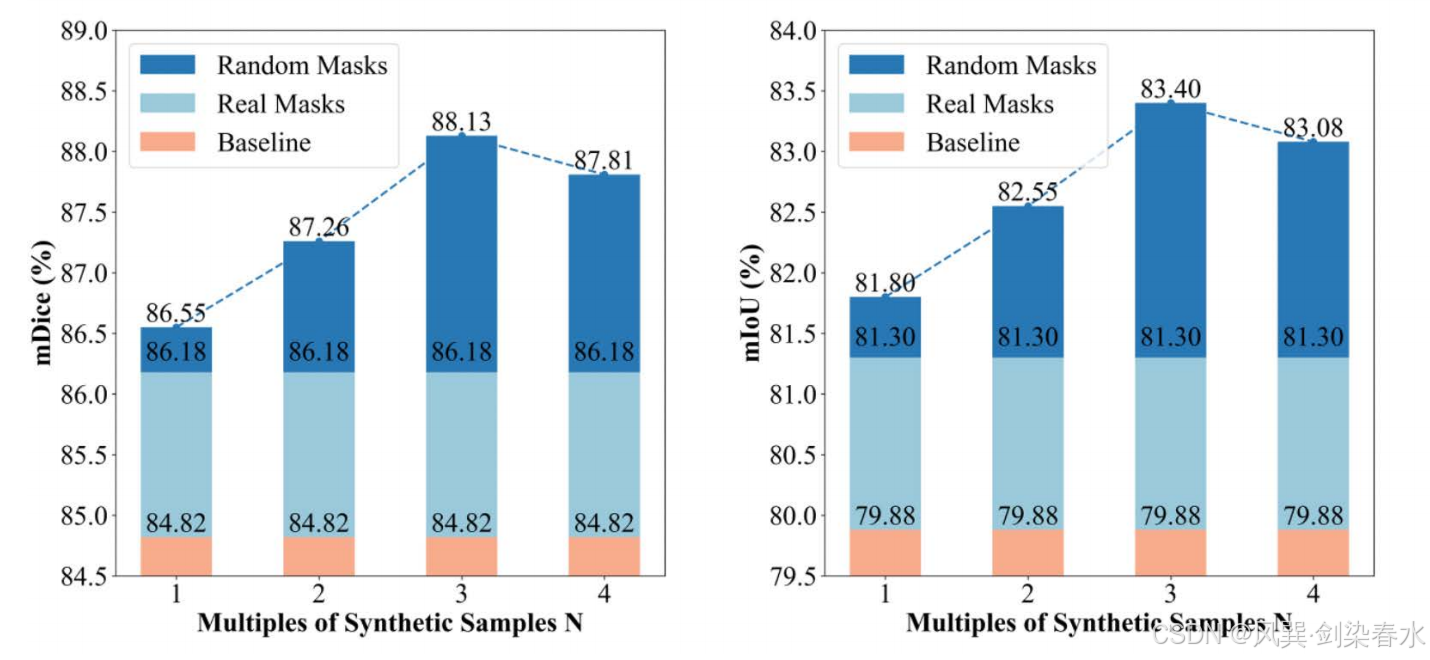
可扩展性和形态多样性是分割任务的关键因素。然而当增强数据量增至四倍时,性能提升效果出现下降。这一有趣现象可能源于息肉训练集和测试集中复杂分布所引发的独特“长尾效应”。
Figure 7 | 可视化 SegFormer 的 mDice(%) 与 mIoU(%) 变化趋势:训练集由真实息肉图像与本方法按不同倍数生成的合成息肉图像共同构成;
核心问题还是如何生成更优质的数据(●’◡’●)





)









)

)

