ARM汇编一般无法在PC上直接运行,因为ARM和x86架构是不一样的。但是很多时候用ARM开发板是很不方便的,所以能不能直接在PC上仿真运行ARM汇编来练习呢?当然可以,那就是:使用QEMU来仿真。
这篇文章我们就来演示下如何在Ubuntu上安装QEMU并仿真ARM汇编程序(其实windows下也可以,只是比较麻烦,需要的话自行百度即可,这里就不记录了)
QEMU是啥
QEMU 是一款开源的硬件虚拟化工具,全称为 "Quick Emulator",它能模拟多种硬件架构的处理器、内存、外设等,让你在一种硬件平台上运行为另一种硬件平台编译的操作系统或程序。
简单来说,QEMU 的核心功能是模拟不同的计算机硬件环境,主要用途包括:
跨架构运行程序 比如在 x86 架构的 PC 上,通过 QEMU 模拟 ARM、MIPS 等架构的处理器,直接运行为这些架构编译的程序(如前面提到的在 x86 Ubuntu 上运行 ARM 汇编程序)。
完整系统仿真 模拟整个计算机系统(包括 CPU、内存、硬盘、网卡等),可以在其中安装和运行不同的操作系统。例如:
在 Windows 上通过 QEMU 运行 Linux 系统
在 x86 Linux 上模拟 ARM 架构的 Ubuntu 服务器
调试与开发 开发者常用 QEMU 调试底层代码(如内核、驱动、汇编程序),因为它可以模拟各种硬件场景,且支持调试接口(如 GDB 远程调试),无需依赖真实硬件。
虚拟化加速 配合 KVM(Linux 内核虚拟化技术)等模块时,QEMU 可以实现接近原生性能的虚拟化(此时更像传统虚拟机,而非纯软件模拟)。
QEMU 支持的架构非常广泛,包括 x86、ARM、RISC-V、PowerPC 等,是嵌入式开发、操作系统研究、跨平台测试的常用工具。它本身是命令行工具,但可以通过图形界面前端(如 Virt-Manager)简化操作。
QEMU是不是就是虚拟机?
QEMU 不完全等同于传统意义上的 “虚拟机”,但它包含虚拟机的功能,且功能范围更广泛。可以说,虚拟机是 QEMU 的一种使用场景,但 QEMU 不止是虚拟机。
具体区别和联系如下:
QEMU 的两种核心模式
QEMU 有两种主要工作模式,其中一种是虚拟机模式,另一种则超越了传统虚拟机的范畴:
全系统仿真(System Emulation) 这是最接近 “虚拟机” 的模式:QEMU 会模拟一整套硬件系统(CPU、内存、硬盘、网卡、显卡等),你可以在其中安装完整的操作系统(如 Linux、Windows),就像使用 VMware、VirtualBox 等虚拟机软件一样。 例如,在 x86 电脑上用 QEMU 模拟一台 ARM 架构的 “虚拟电脑”,并在里面运行 ARM 版的 Ubuntu。
用户模式仿真(User Mode Emulation) 这种模式不模拟完整系统,只模拟目标架构的 CPU 指令集,让单个程序在当前系统中直接运行(无需安装完整 OS)。 例如,在 x86 架构的 Ubuntu 上,通过
qemu-arm命令直接运行一个 ARM 架构的二进制程序(就像前面运行 ARM 汇编程序的例子)。 这是 QEMU 独有的轻量功能,传统虚拟机(如 VMware)无法做到。与传统虚拟机的核心差异
对比维度 QEMU(全系统仿真) 传统虚拟机(如 VMware、VirtualBox) 核心依赖 纯软件模拟(可配合 KVM 加速) 依赖硬件虚拟化技术(如 Intel VT、AMD-V) 性能 纯模拟时性能较低;配合 KVM 后接近原生 接近原生性能 支持架构 极其广泛(x86、ARM、RISC-V、MIPS 等) 主要支持 x86/x86_64,部分支持 ARM 适用场景 跨架构开发、底层调试、小众系统 日常多系统运行、服务器虚拟化 总结
QEMU 包含虚拟机功能:在 “全系统仿真” 模式下,它就是一款虚拟机工具,能模拟完整的计算机系统。
QEMU 不止是虚拟机:它的 “用户模式仿真” 可以轻量地跨架构运行单个程序,且支持更多小众硬件架构,是开发者调试底层代码的重要工具。
简单说,传统虚拟机更像 “一台虚拟电脑”,而 QEMU 更像 “一个万能的硬件模拟器”,虚拟机功能只是它的一部分。
Ubuntu下安装QEMU
我们直接使用apt来安装,步骤如下:
首先更新系统软件包列表,打开终端输入命令:
sudo apt update。若只需要安装 QEMU 基本功能,可执行命令:
sudo apt install qemu-system。若希望获得更完整的虚拟化体验,例如使用图形界面管理虚拟机等,则执行命令:
sudo apt install qemu qemu-kvm libvirt-daemon libvirt-clients bridge-utils virt-manager。安装完成后,可通过运行
qemu-system-x86_64 --version来验证 QEMU 是否正确安装,并查看其版本信息。
模拟ARM架构执行ARM汇编
在 Ubuntu 下使用 QEMU 用户模式模拟 32 位 ARM 架构执行 ARM 汇编代码,是一种轻量高效的方案,无需配置完整的系统镜像。以下是详细步骤:
一、安装工具链
首先安装 32 位 ARM 交叉编译工具和 QEMU 用户模式模拟器:
# 安装32位ARM交叉编译工具链(支持ARMv7及以下架构) sudo apt install gcc-arm-linux-gnueabihf binutils-arm-linux-gnueabihf# 安装QEMU用户模式模拟器(用于运行32位ARM程序) sudo apt install qemu-user二、编写 32 位 ARM 汇编代码
创建一个示例程序(
arm32_demo.s),使用 ARMv7 指令集和 Linux 系统调用:.datamsg: .asciz "Hello, 32-bit ARM Assembly (QEMU User Mode)!\n"len = . - msg @字符串长度.text.global _start _start:@系统调用:write(1, msg, len)mov r0, #1 @r0 = 标准输出文件描述符(stdout)ldr r1, =msg @r1 = 字符串地址ldr r2, =len @r2 = 字符串长度mov r7, #4 @r7 = write系统调用号(32位ARM Linux约定)swi #0 @触发软中断执行系统调用@系统调用:exit(0)mov r0, #0 @r0 = 退出状态码(0表示成功)mov r7, #1 @r7 = exit系统调用号swi #0 @退出程序三、编译为 32 位 ARM 可执行文件
使用交叉工具链将汇编代码编译为 32 位 ARM 二进制程序:
# 汇编:将.s文件转为目标文件(指定ARM架构为armv7) arm-linux-gnueabihf-as -mcpu=armv7-a -o arm32_demo.o arm32_demo.s# 链接:生成可执行文件 arm-linux-gnueabihf-ld -o arm32_demo arm32_demo.oarm-linux-gnueabihf-as -mcpu=armv7-a -o arm32_demo.o arm32_demo.s
这一步遇到问题:

Assembler messages:
Error: unknown cpu `armv7-a'
Error: unrecognized option -mcpu=armv7-a
查看下汇编器的版本:
arm-linux-gnueabihf-as --version

查看
arm-linux-gnueabihf-as汇编器支持的架构,可以使用它的帮助选项来列出所有支持的 CPU 和架构:arm-linux-gnueabihf-as --target-help
在输出结果中,你会看到类似以下的内容(不同版本可能略有差异):
... -mcpu=name select CPU variant (arm1020e, arm1020t, arm1022e, ..., armv7-a, armv7-m, armv7-r, ...) ...其中列出的所有以
armv开头的选项(如armv7-a、armv8-a等)都是该汇编器支持的 ARM 架构版本。但是我执行后没有列出来
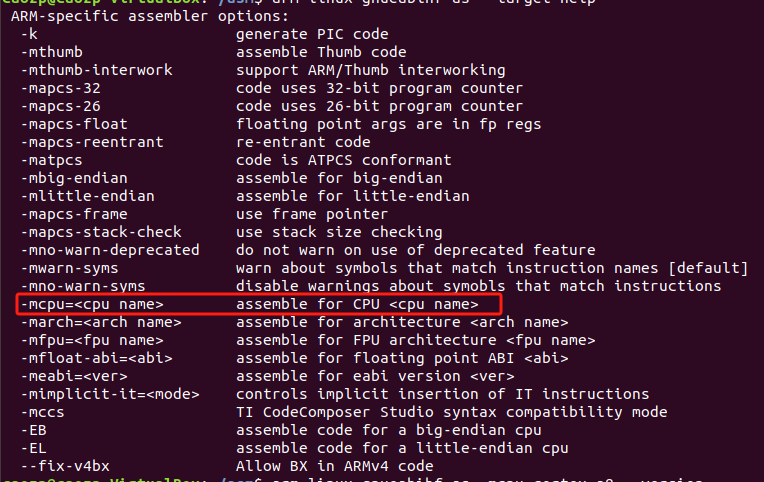
下面有个-march选项,这个才是架构吧,-mcpu需要指定的是CPU型号?
然后试着改下,用-march来指定armv7-a架构
arm-linux-gnueabihf-as -march=armv7-a -o arm32_demo.o arm32_demo.s或者用-mcpu来指定具体的CPU型号比如cortex-a8
arm-linux-gnueabihf-as -mcpu=cortex-a8 -o arm32_demo.o arm32_demo.s在执行之前,我们先测试下看看
arm-linux-gnueabihf-as -march=armv7-a --versionarm-linux-gnueabihf-as -mcpu=cortex-a8 --version如果不报错的话应该就是对的
在 ARM 工具链中,
-mcpu和-march是两个相关但含义不同的选项,它们的使用场景有明确区别:
-march=<architecture>:指定目标处理器架构(如armv7-a),仅关注指令集架构版本,不涉及具体 CPU 实现细节(如缓存大小、流水线等)。 例如:-march=armv7-a明确指定使用 ARMv7-A 架构的指令集。
-mcpu=<cpu-name>:指定具体的 CPU 型号(如cortex-a9),不仅包含该 CPU 所属的架构版本,还会启用该型号特有的硬件特性优化。 例如:-mcpu=cortex-a9会自动隐含-march=armv7-a,同时针对 Cortex-A9 的硬件特性进行优化。关键点:
ARM 工具链中,
-march确实是指定架构(如armv7-a)的更直接方式,而-mcpu更多用于指定具体 CPU 型号。当使用
-mcpu指定某个属于armv7-a架构的 CPU 时(如cortex-a8、cortex-a9),工具链会自动推断出对应的-march=armv7-a,无需重复指定。如果你只需要确保代码兼容
armv7-a架构(不针对特定 CPU 优化),直接使用-march=armv7-a更合适:arm-linux-gnueabihf-as -march=armv7-a -o arm32_demo.o arm32_demo.s如果之前用
-mcpu=armv7-a报错,可能是因为工具链对-mcpu的参数要求更严格(必须是具体 CPU 型号),而-march=armv7-a是更标准的架构指定方式,通常能解决这类识别问题。
四、用 QEMU 用户模式运行
直接通过
qemu-arm模拟 32 位 ARM 环境并执行程序:qemu-arm ./arm32_demo执行后会输出:
Hello, 32-bit ARM Assembly (QEMU User Mode)!五、扩展:调试 32 位 ARM 程序
若需调试汇编代码,可结合
gdb-multiarch进行单步调试:# 1. 启动QEMU并等待GDB连接(监听1234端口) qemu-arm -g 1234 ./arm32_demo &# 2. 另开终端,启动多架构GDB gdb-multiarch ./arm32_demo# 3. 在GDB中连接调试端口 (gdb) target remote localhost:1234# 4. 设置断点(如在_start处) (gdb) b _start# 5. 运行程序 (gdb) c# 6. 单步执行(汇编级) (gdb) si # 执行下一条汇编指令关键说明
用户模式的特点:
QEMU 用户模式(qemu-arm)仅模拟 32 位 ARM 指令集和系统调用转换,直接复用宿主 Ubuntu 的文件系统、标准输入输出等资源,无需配置内核或根文件系统,启动速度极快。系统调用兼容性:
32 位 ARM Linux 的系统调用通过r7寄存器传递调用号(如write=4、exit=1),QEMU 会自动将这些调用转换为 x86 Ubuntu 的系统调用,因此程序可直接与宿主系统交互。指令集兼容性:
若需模拟更低版本的 ARM 架构(如 ARMv5),可在编译时指定-mcpu=arm926ej-s,QEMU 会自动适配对应的指令集模拟。通过以上步骤,可在 x86 架构的 Ubuntu 中快速验证 32 位 ARM 汇编代码,适合学习 ARMv7 指令集或开发调试简单程序。
补充:汇编转成可执行文件
在上面我们看到,汇编程序转成可执行程序,用了两步,即汇编和链接,我们知道,C语言可以直接用GCC来一步生成可执行程序,为啥汇编要分成两步?
汇编程序需要先汇编再链接,而 C 语言可以通过
gcc一步生成可执行文件,这是由两种语言的特性、编译流程和工具链设计决定的,核心原因在于语言抽象层次不同和工具链的自动化封装:汇编语言:直接映射机器码,与硬件强绑定
汇编指令是机器码的 “人类可读形式”,一条汇编指令通常对应一条机器码(或少数几条),直接操作寄存器、内存地址和硬件接口。
- 汇编器(如
as)的工作是将汇编指令翻译成机器码(生成目标文件.o),但不处理跨文件符号引用(如调用其他文件的函数)、内存地址分配等复杂逻辑。- 例如,汇编中调用外部函数
func时,只能生成一个 “待填充” 的跳转地址,具体地址需要链接器在整合所有目标文件后确定。C 语言:高级抽象,依赖复杂的编译流程
C 语言通过变量、函数、控制结构等抽象屏蔽了硬件细节,编译器需要完成:
这些步骤被
gcc等工具链自动化封装,用户只需执行gcc main.c -o main,工具链会自动完成上述所有流程。
- 预处理(展开宏、头文件)
- 编译(将 C 代码翻译成汇编代码)
- 汇编(将汇编代码翻译成机器码,生成目标文件)
- 链接(整合所有目标文件和库,处理符号引用,分配最终内存地址)
gcc等 C 语言编译器并非 “直接编译” 生成可执行文件,而是自动串联了预处理、编译、汇编、链接四个步骤。例如:gcc main.c -o main实际执行的流程是:
cpp main.c > main.i(预处理,生成.i 文件)cc1 main.i -o main.s(编译,生成汇编代码.s 文件)as main.s -o main.o(汇编,生成目标文件.o)ld main.o -lc -o main(链接,整合目标文件和 C 标准库,生成可执行文件)用户看不到中间步骤,是因为工具链将其封装为 “一步命令”,而汇编程序通常需要手动执行 “汇编→链接” 以更灵活地控制过程(如指定链接脚本、库路径等)。
简言之,汇编语言更贴近硬件,流程拆分更细以保留灵活性;C 语言通过工具链自动化隐藏了复杂步骤,降低了使用门槛,但本质上仍遵循 “编译→汇编→链接” 的底层逻辑。

)




机器学习(2)-day29)



 配置指南)







![[spring6: @EnableWebSocket]-源码解析](http://pic.xiahunao.cn/[spring6: @EnableWebSocket]-源码解析)
