在了解了各种协议的使用以及简单的socket接口后,学会了“怎么传”的问题,现在来了解一下“传什么”的问题。
1. 序列化与反序列化
在前面的TCP、UDP的socket api 的接口, 在读写数据时, 都是按 "字符串" 的方式来发送接收的. 如果我们要传输一些 "结构化的数据" 怎么办呢?在最初的对网络的整体结构的学习中,我们了解了网络分层的概念,也知道了消息在传输的时候是会被分段的——用于描述信息的叫报头,实际传输的内容叫报文,但是我们前面的demo代码都是直接把消息当作一个个直接的string当作信息传来传去,没有所谓报头或者序列化的概念,这是很不严谨的。
协议不仅仅是TCP或UDP等传输协议,传输的内容也是可以被定义的
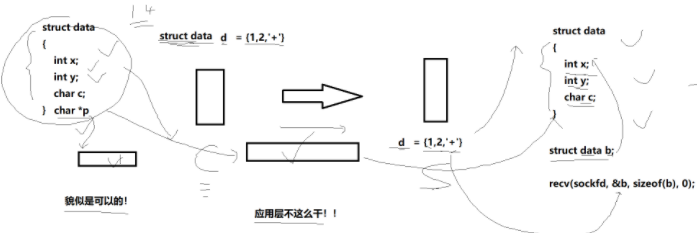
在同一台机器内,结构体的“打包”与“解包”由同一套编译器和运行时完成,直接按字节传递即可(比如在本地电脑的文件读写,就是直接二进制入再二进制出);一旦跨过网络,就可能遇到不同操作系统、不同 CPU 体系结构带来的字节序、对齐方式等差异,贸然按原样发送结构体极易出错,因此网络通信中不宜直接传递裸结构体(也就是避免直接传二进制)。
譬如:结构体对齐方法可能不一样,客户端可能是安卓平台等等
既想保留结构化信息的便利,又要回避兼容性问题,业界给出的答案是序列化:把结构体按既定规则转成一段无歧义的字符串(字节流)。接收方再通过反序列化,把这串字节重新还原成结构体。序列化与反序列化互为逆过程,屏蔽了底层差异。
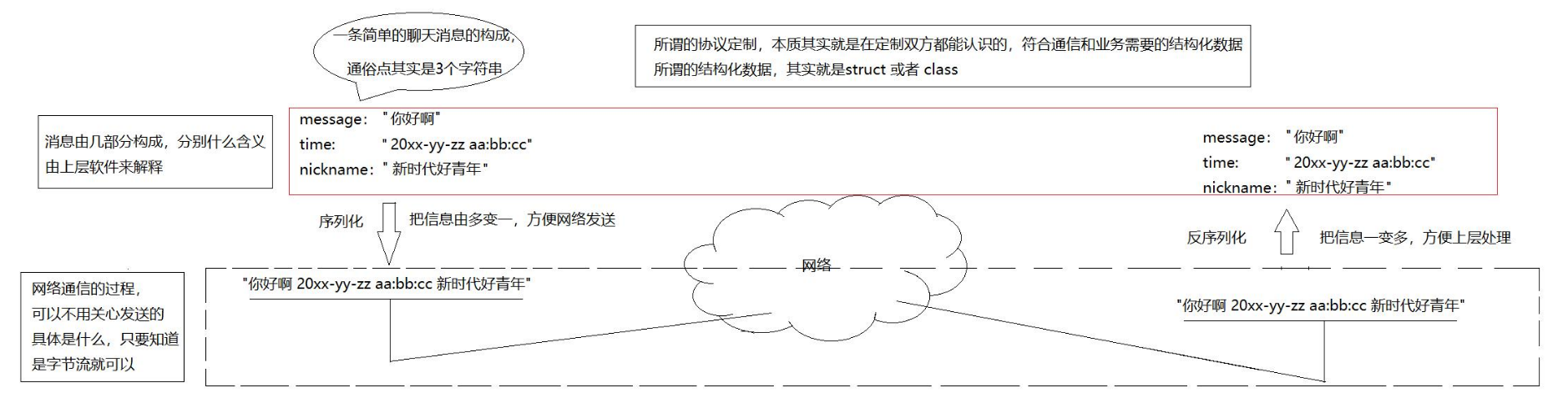
为了让两端都能准确还原数据,双方必须持有同一份“数据蓝图”——即完全一致的类型定义(也就是双方要有一样的协议)。这份共享的结构体定义就是应用层协议本身:它既描述了报文的字段顺序、类型与含义,又隐含了编码/解码规则;因其随应用程序一起部署,故属于应用层协议范畴。
比如要传以上的data,可以先写成{1,2,'+'},应用层传输这个字符串,在服务器接受到这个字符串之后按照相同的规则进行反序列化
2. 如何理解socketfd全双工
前面都提到UDP和TCP是全双工的,如何理解一个fd支持同时读写呢?
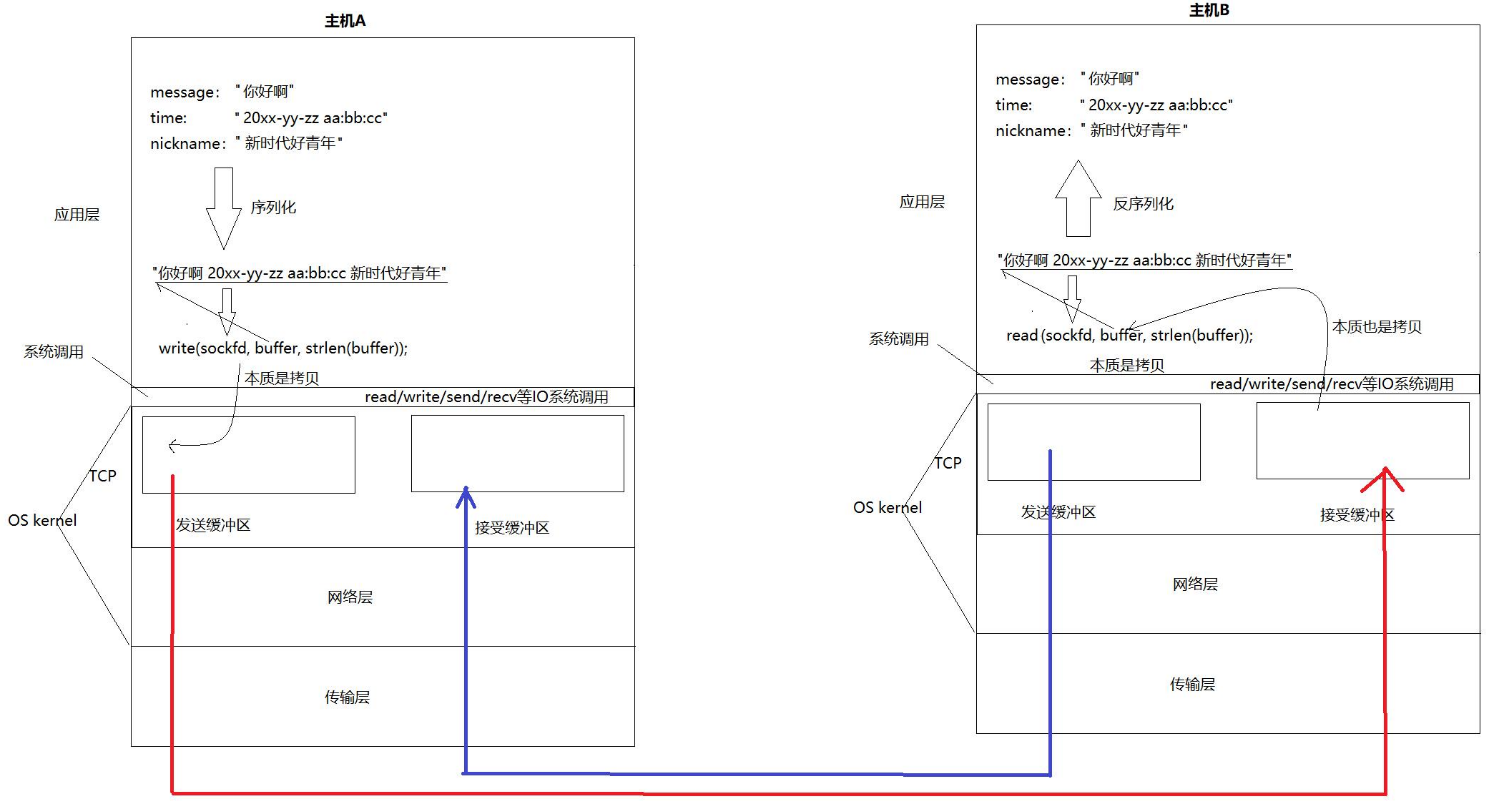
本质是因为TCP的底层有两个缓冲区,一个是发送缓冲区,一个是接受缓冲区。
就像OS传输文件给磁盘一样,read/write/send/recv等系统调用只负责把内容发送到缓冲区,至于缓冲区多久刷新、如何刷新,都是由TCP或UDP的Kernel代码自动进行的。
而发送和接受的本质就是拷贝,所以其实就是应用层对于内核的拷贝
所以,所谓的全双工本质就是利用两个缓冲区,客户端的发送缓冲区对应服务端的接收缓冲区,服务端的发送缓冲区对应客户端的接收缓冲区
不管是客户端还是服务器,OS内部都可能积累大量的报文,操作系统需要对这些报文进行管理,管理就必须先组织。
所以内部一定有对应的结果体在描述这些报文。
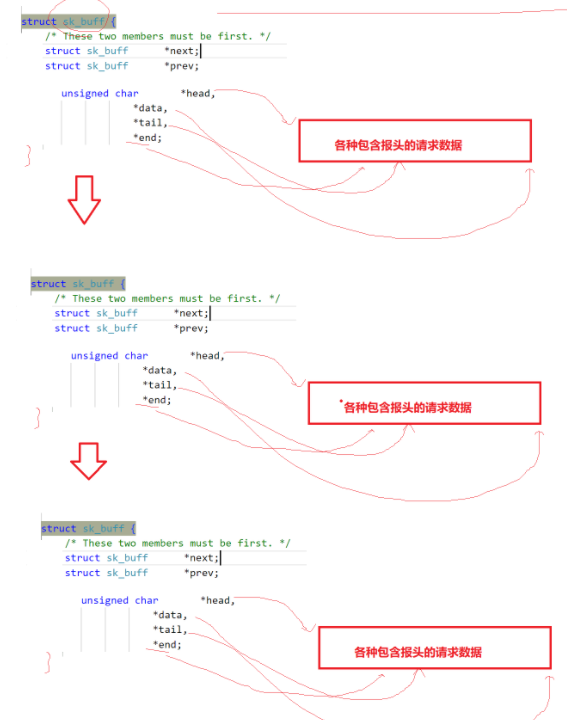
观察、了解报文是如何被管理的
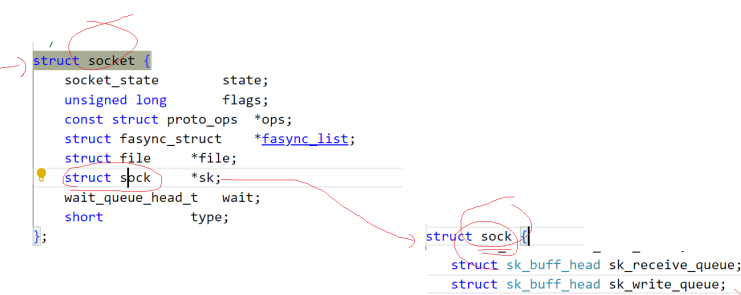
每个fd指向的struct file中都有一个隐藏的private_data指针,作为VFS的描述普通文件的struct file时,private_data没有明确的指向。
private_data指向具体文件系统或驱动的私有数据
但是当file作为一个套接字的描述结构体时,private_data指向的就是一个socket结构体,而socket结构体中也有一个struct file指回 file。
然后这个socket还包括了一个sock结构体,sock结构体里包含了两个队列,这两个队列里装的都是sk_buff
sk_buff就是管理报文的。
各个报文以链表形式被组织管理起来。而这些链表就由sock中的接受队列和写队列分别管理。
由此,TCP\UDP等就能进行全双工了。

现在将视角集中到客户端向服务端发送的一条信息之上,因为TCP是面向字节流的,所以在客户端给服务端发送数据时可能存在发送的数据只有待发送数据的一半甚至更少,那这样服务端接收到数据就属于不完整的数据,在上面应用层转换时也就可能转换失败。
基于这个原因,所以说TCP的读写,不论是使用文件流的read和write,还是网络中的recv和send都是不完善的,因为这些接口不会检测数据是否是上层需要的有效数据,而且这些接口也无法做到判断数据是否是上层需要的有效数据,所以这就需要应用层自己判断收到的数据是否是可以被正确转换的,如果不是就应该继续接收直到至少有一条有效数据。
TCP更像自来水,自来水公司只负责把水放到你家的水箱里,你自己可能一桶一桶接,可能一杯一杯接。TCP按照真实情况,控制着一点一点发,所以需要由应用层来控制报文的完整性。因此,TCP中必须要有序列化和反序列化的操作。
但是对于UDP来说就不存在上面TCP这个问题,因为UDP是面向数据包的,所谓数据包就是将数据整个打包,在发送时要么就发整个数据包,要么就一点也不发,这样不论是哪一个接口,拿到的都是完整的数
而UDP就是发快递。永远都是完整的一个包裹,快递员不被允许送半个包裹给你。
JSONCPP
所以,要把这个结构体给控制成什么样子才作为标准呢?我们可以自己制定,也有一些被规定好并且比较有名的方案:
一句话理解:• XML:「文档+元数据」时代的老大哥,现在只做配置/协议兼容。
• JSON:「前后端通用语」,无 schema,想改就改,调试最爽。
• Protobuf:「高性能 RPC 专用二进制」,IDL 一把梭,版本演进最省心。

作为后端开发者,我们重点学习jsoncpp插件的使用 :
JsoncppJsoncpp 是一个用于处理 JSON 数据的 C++ 库。它提供了将 JSON 数据序列化为字符串以及从字符串反序列化为 C++ 数据结构的功能。Jsoncpp 是开源的,广泛用于各种需要处理 JSON 数据的 C++ 项目中
1.简单易用:Jsoncpp 提供了直观的 API,使得处理 JSON 数据变得简单。2.高性能:Jsoncpp 的性能经过优化,能够高效地处理大量 JSON 数据。3.全面支持:支持 JSON 标准中的所有数据类型,包括对象、数组、字符串、数字、布尔值和 null。4.错误处理:在解析 JSON 数据时,Jsoncpp 提供了详细的错误信息和位置,方便开发者调试。当使用 Jsoncpp 库进行 JSON 的序列化和反序列化时,确实存在不同的做法和工具类可供选择。
以下是三种常见用法(JSON组件只要会用就行,不需要掌握很多,忘记了就AI)
使用 Json::Value 的 toStyledString 方法:○优点:将 Json::Value 对象直接转换为格式化的 JSON 字符串。○实例如下:
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>
int main()
{Json::Value root;root["name"] = "joe";root["sex"] = "男";std::string s = root.toStyledString();std::cout << s << std::endl;return 0;
}$ ./test.exe
{
"name" : "joe",
"sex" : "男"
}//第一种,使用toStyledString。直接把一个JSON::VALUE对象转换成string:使用 Json::StreamWriter:○优点:提供了更多的定制选项,如缩进、换行符等。#include <iostream> #include <string> #include <sstream> #include <memory> #include <jsoncpp/json/json.h> int main() {Json::Value root;root["name"] = "joe";root["sex"] = "男";Json::StreamWriterBuilder wbuilder; // StreamWriter 的工厂std::unique_ptr<Json::StreamWriter> writer(wbuilder.newStreamWriter());std::stringstream ss;writer->write(root, &ss);std::cout << ss.str() << std::endl;return 0; }$ ./test.exe { "name" : "joe", "sex" : "男" }这次的代码示例中我们没有展示如何定制,不过AI之后就可以了解到:


反序列化:
反序列化指的是将序列化后的数据重新转换为原来的数据结构或对象。Jsoncpp 提供了以下方法进行反序列化:1.使用 Json::Reader:○优点:提供详细的错误信息和位置,方便调试。#include <iostream> #include <string> #include <jsoncpp/json/json.h> int main() { // JSON 字符串 std::string json_string = "{\"name\":\"张三\", \"age\":30, \"city\":\"北京\"}"; // 解析 JSON 字符串 Json::Reader reader; Json::Value root; // 从字符串中读取 JSON 数据 bool parsingSuccessful = reader.parse(json_string, root); if (!parsingSuccessful) { // 解析失败,输出错误信息 std::cout << "Failed to parse JSON: " << reader.getFormattedErrorMessages() << std::endl; return 1; } // 访问 JSON 数据 std::string name = root["name"].asString(); int age = root["age"].asInt(); std::string city = root["city"].asString(); // 输出结果 std::cout << "Name: " << name << std::endl; std::cout << "Age: " << age << std::endl; std::cout << "City: " << city << std::endl; return 0; } $ ./test.exe Name: 张三 Age: 30 City: 北京
在今天的demo代码中,我们采取部分自定义+JSON
可以避免1+22+3的歧义,不知道是1+2 2+3还是1+22+3
3. 网络计算器
网络计算器:
上面已经基本介绍了一些概念,下面基于TCP实现一个网络计算器,通过这个计算器更深刻得去理解上面的概念网络计算器的基本功能就是客户端发送计算表达式(本次只实现五种运算,分别是:+、-、*、/和%),服务端接收到计算表达式后通过相关接口对这个表达式进行处理并将结果返回给客户端
现在就来构思这个网络计算器,如何通过协议模块以及之前的TCP框架进行传输。
今天的demo都是基于【LINUX网络】使用TCP简易通信-CSDN博客中实现的TCP框架进行的
socket code of TCP demo · 78028f9 · lsnmjp/code of cpp Linux 算法 - Gitee.com
使用JSON进行序列化
很明显,客户端传过去的是诸如“1+2”,服务器要传回去的是“3,正确计算”或者“0xfffff,非正常计算”等字段。
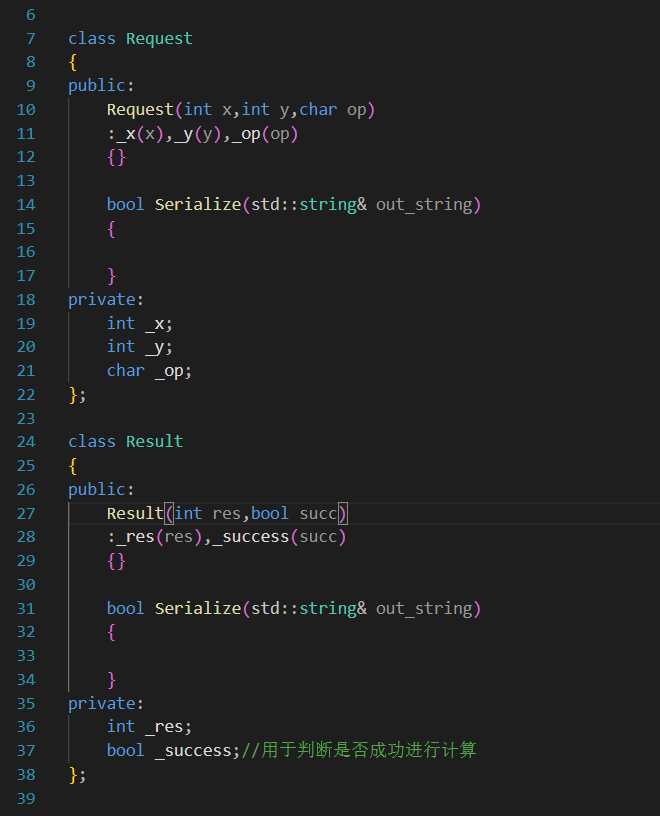
所以,需要把这两种数据都进行结构化,一个是class Request,另一个是class Resluat
客户端生成Req,经过序列化之后传到服务器,服务器经过反序列化获得Req,丢给运算逻辑函数,运算逻辑函数会返回Res需要的数据,再生成一个Res之后经过序列化传给客户端。
并且,两个类还需要搭配相应的序列化函数和反序列化函数。
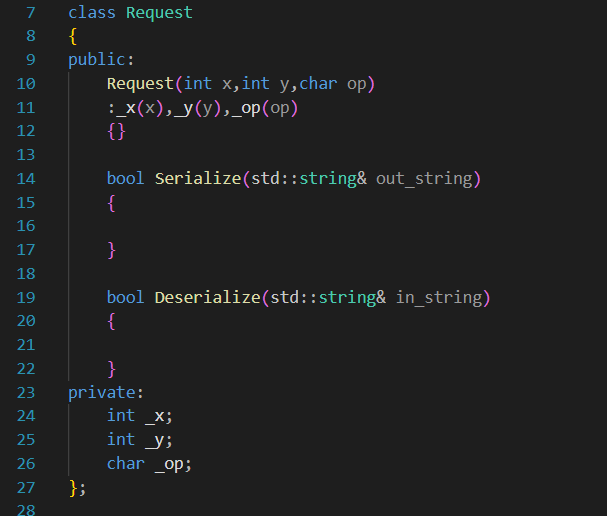
前面我们提到了,应用层需要我们自行进行检查,得到的报文是不是完整的(read或者recv得到的不一定是完整的一个Res或者Req),所以其实在设计应用层时,到时候还需要设计类似的检测“报头”的函数
编码来看看细节:
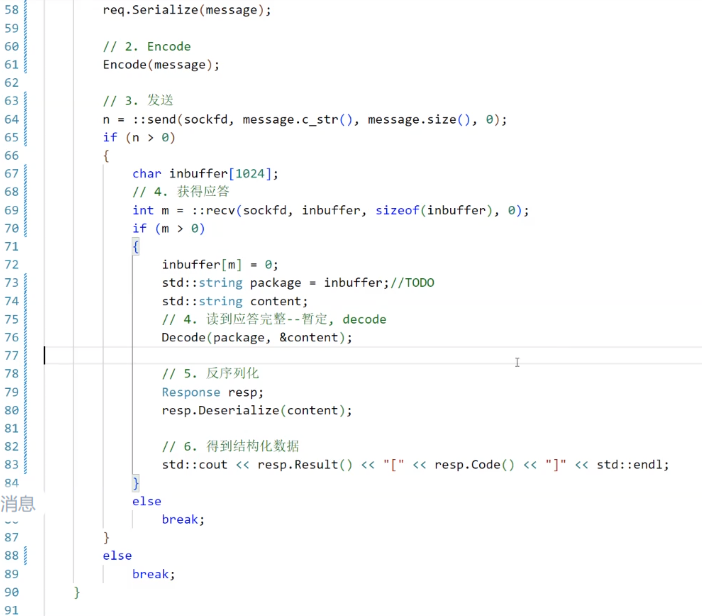
所以到时候在main函数里大概是:
Request req(10,20,"+"); string str; req.Serialize(str); 相当于str是一个输出型参数
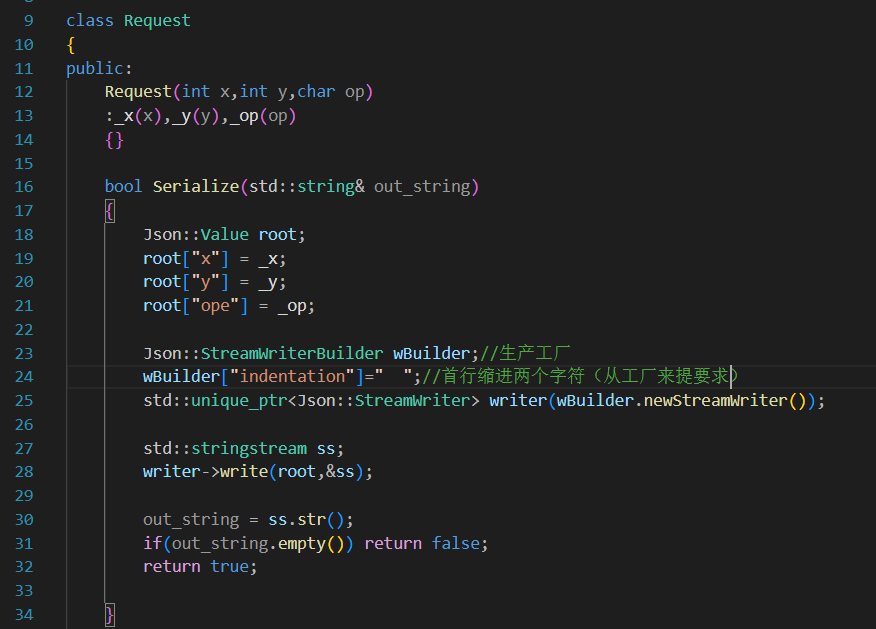
写进去的时候自动判断是什么类型的,拿出来的时候需要手动指定是什么类型的
bool Deserialize(std::string& in_string){//反序列化Json::Value root;Json::Reader reader;bool ParseSuccess = reader.parse(in_string,root);if(!ParseSuccess){LOG(LogLevel::ERROR)<<"Parse Failed";return false;}//使用Json数据_res = root["res"].asInt();_success = root["y"].asBool();return true;}简单一个测试
#include "Protocol.hpp" #include <iostream> #include <string>int main() {Request req(10,20,'+');std::string out;req.Serialize(&out);std::cout<<out<<std::endl;req.Deserialize(out);req.Print();return 0; }
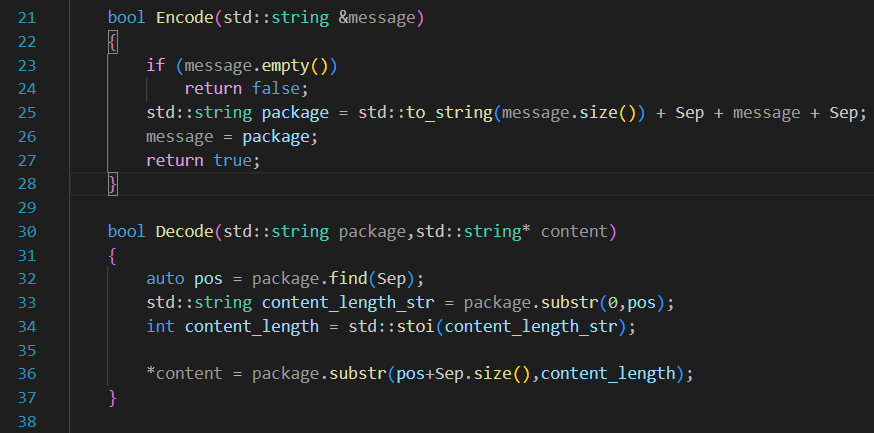
序列化得到了报文,现在为了在应用层区分每一条消息(一次完整的x和y的计算),我们使用一个Encode函数和Decode函数来添加、取消报头,希望我们的每一次完整格式都是:
12\r\n{JSON}\r\n 、 34\r\n{JSON}\r\n 其中,前面的数表示后面JSON串的长度
应用层添加报头
Encode可以给每一个配置好的JSON串添加报头:
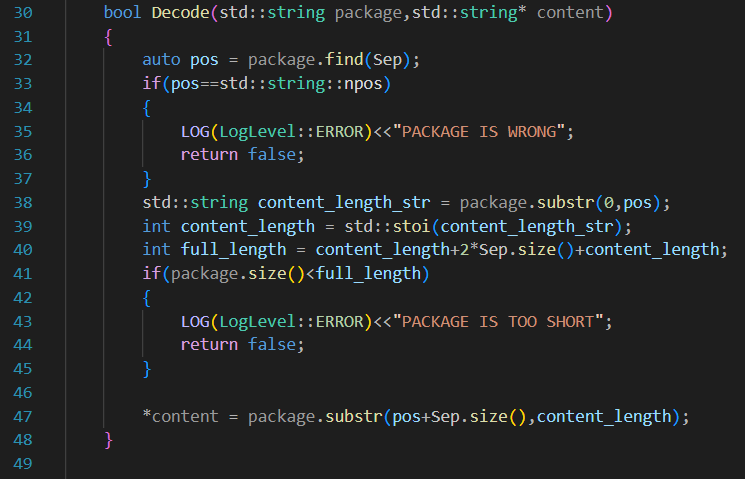
为了增加代码的健壮性,大概处理下Decode中可能出现的各种问题:
1.避免可能整个包不完整的情况
通过计算一个full_length来避免一条报文过于短
2.避免压根没找到Sep
通过判断pos来决定。
3. 有可能送了好几条完整的报文,需要能剔除前面的完整的、已经被获取的报文
诸如:12\r\n{JSON}\r\n
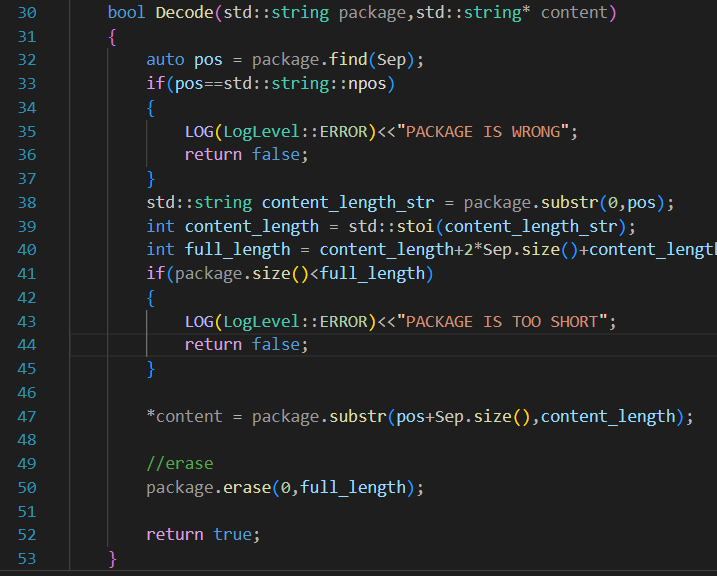
回归Server.hpp。对于recv函数,由于tcp通信的特性,放到inbuffer里的可能是半个Request(序列化后的JSON串),可能是一个,也可能是多个。同样,下面的send也是不完善的
那么,我们是不是需要一个package用来存每一轮接受到inbuffer里的内容,再对这个package进行解析,拿走完整的JSON,让留在package里面的半个json等待下一轮的inbuffer传进来。
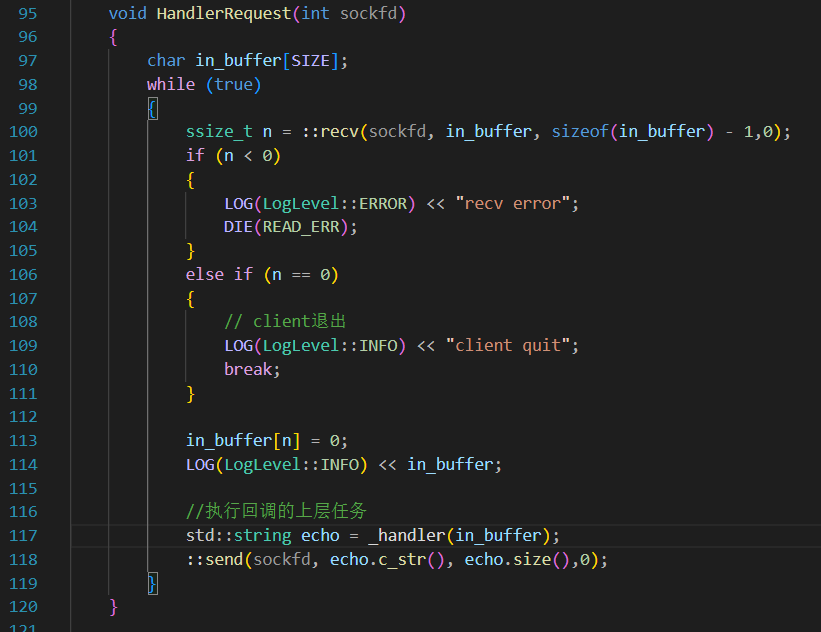
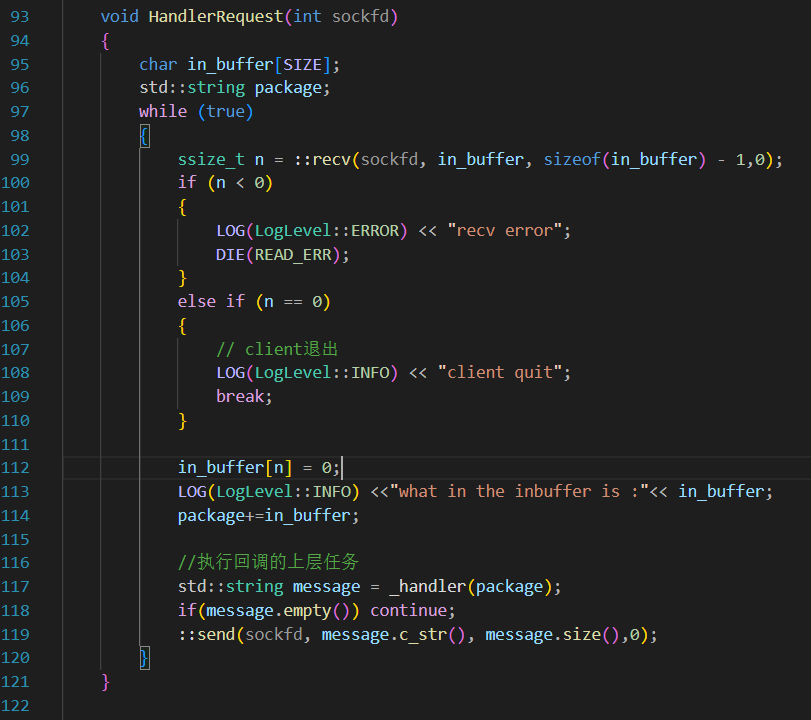
当然,HandleRequest作为“网络计算器”这个程序的在网络通信层中处理任务的模块,肯定不该被用于处理类似于“package是不是不完善”的问题,只管把这个package丢给中间层就可以了
只需要知道,_handler返回的也一定是一个被序列化的Response结构体,所以这个_handler不应该直接传给计算器层,应该传给一个用于解析的中间层。不过,如果是调用别人的库的话,这种中间层都是应该直接被写好的,只不过我们今天是纯手搓,所以必须实现这一层Decode和Desiralize
实现一下计算器
计算器的逻辑就不过多赘述了。
这个Calculator的参数和返回值就很能说明序列化的必要性,只针对两个结构进行运算
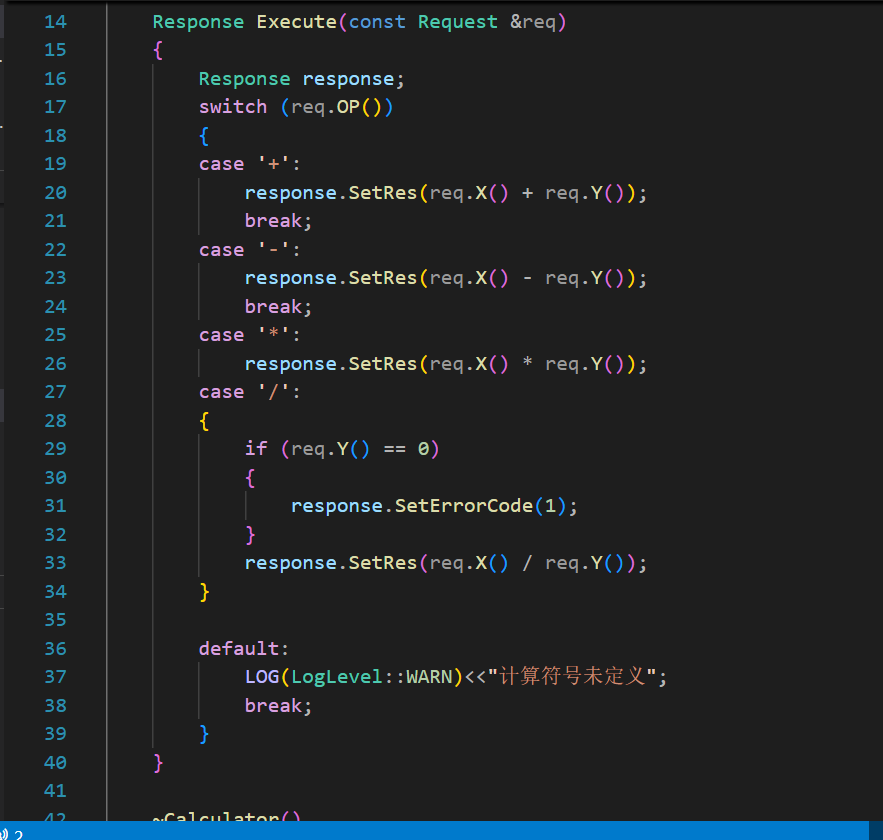
此处的计算器本身的业务逻辑应该就不需要多说了:
将计算功能注册进入服务中
注册进入之后,保证整个TCP层就只需要负责IO了。
using Cal_t = std::function<Response(Request)>;class Parse
{
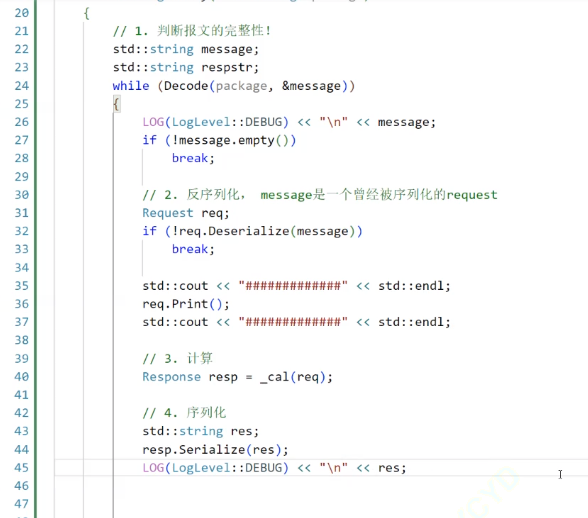
public:Parse(Cal_t cal): _cal(cal){}std::string Parse2Entry(std::string &package){std::string message; // package解包之后的信息// 1.解包bool ret = Decode(package, &message);if (!ret || message.empty()){// 如果Decode失败,返回空串,这样在Server.hpp中就可以去重新recvreturn std::string();}// 2.反序列化Request req;if (!req.Deserialize(message)){LOG(LogLevel::ERROR) << "反序列化失败";return std::string();}// 3.计算Response ans;ans = _cal(req);// 4.序列化std::string message_back;if (!ans.Serialize(&message_back)){LOG(LogLevel::ERROR) << "序列化失败";}// 5.添加报头if (!Encode(message_back)){LOG(LogLevel::ERROR) << "Encode failed";}}private:Cal_t _cal;
};如上述代码,解码、解析等工作主要就是靠这个Decode
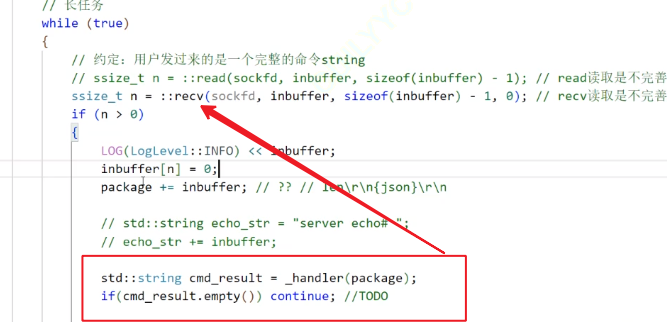
之前写的Decode就有这个功能:1、探测报文完整性。2、报文完整就提取出来
保证返回为true,并且content不为空。
解码成功的时候:
如果Decode失败,或者message是空,那么我们就返回一个空串。
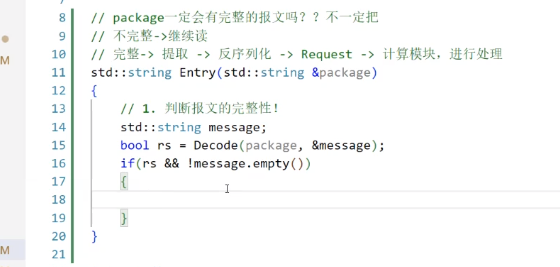
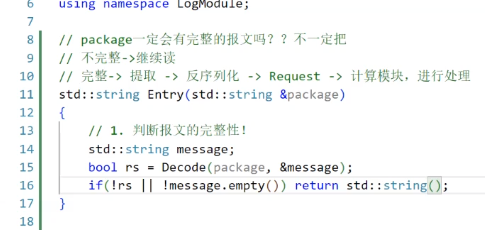
而一旦返回一个空串(对于服务器)
就会执行continue,从而继续recv
这也体现了package+=的意义,如果在_handler中package没有被处理,那么我们就可以通过+=
从而拿到完整的报文
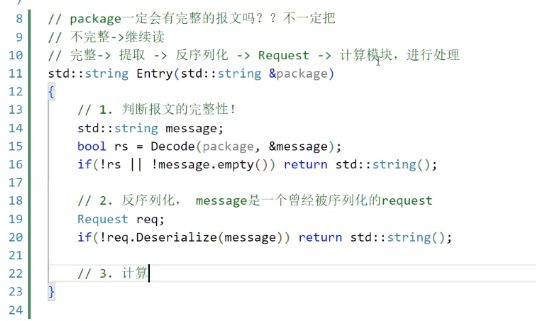
一旦拿到这个message,此时的message就是一个曾经被序列化的request
为了健壮性,如果反序列化失败,还是要返回一个空串
走到最后一步,就是计算(也可以像演示中的代码那样,直接using一个新的函数类别,这样能形成类之间的解耦合)
现在要返回的是一个Response的结果,应以被序列化过的状态去返回
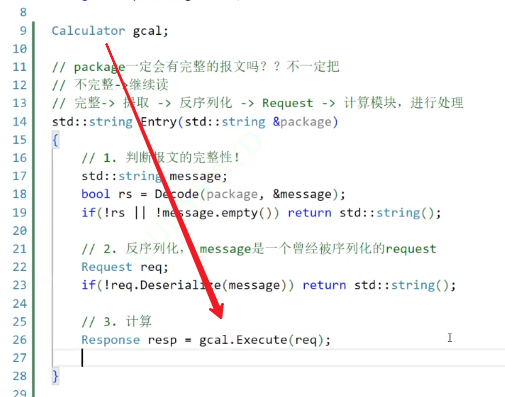

所以现在的整个代码就形成了三层:计算器、分析、服务器
package处理多个完整JSON
如果 一个package里有多个完整的请求该怎么办呢?还需要简单修改一下刚刚的parse逻辑。
package有点像生产消费队列中的生产者
只要package不为空,就可以一直去decode package,不过也因此package必须要传引用
std::string Parse2Entry(std::string &package){std::string message; // package解包之后的信息std::string return_response_str;// 1.解包while (!Decode(package, &message)){if (message.empty()){// 如果Decode失败,返回空串,这样在Server.hpp中就可以去重新recvreturn std::string();}// 2.反序列化Request req;if (!req.Deserialize(message)){LOG(LogLevel::ERROR) << "反序列化失败";return std::string();}// 3.计算Response ans;ans = _cal(req);// 4.序列化std::string message_back;if (!ans.Serialize(&message_back)){LOG(LogLevel::ERROR) << "序列化失败";}// 5.添加报头if (!Encode(message_back)){LOG(LogLevel::ERROR) << "Encode failed";}return_response_str+=message_back;}//可能是多个JSON拼接的return_response_strreturn return_response_str;}
主程序
现在的主程序就非常清晰了,只需要一层一层的使用lambda绑定进去就可以了
注意,给tcp_server绑定的时候package也必须传引用,否则还是存在不能解决多个JSON串的问题。
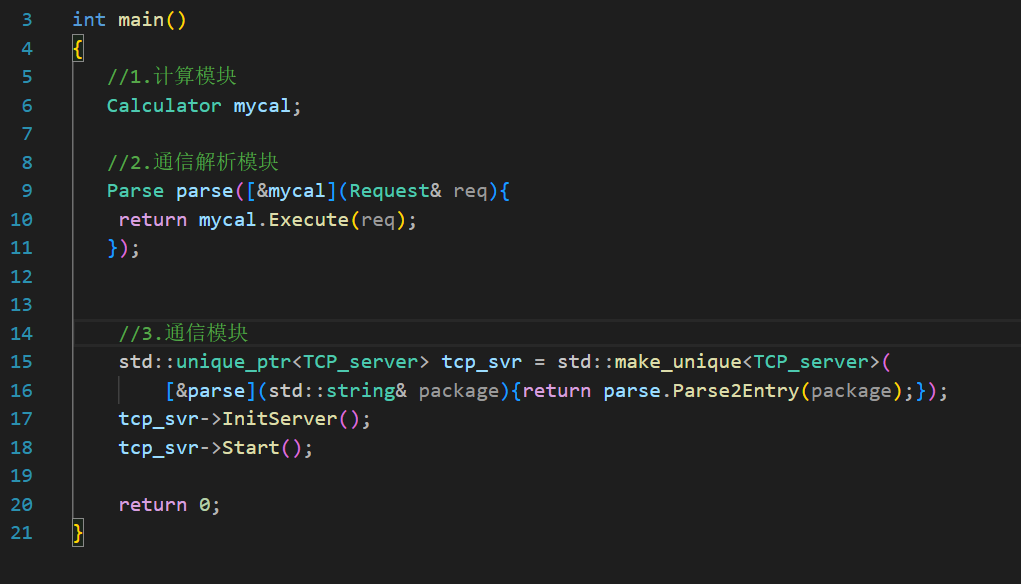
客户端(简化)
客户端就可以直接按照序列化、Decode的顺序来做:
注意,第四步的位置应该是要加循环的,必须保证recv到了一个完整的、可以被Decode的字符串才行
简单测试一下:
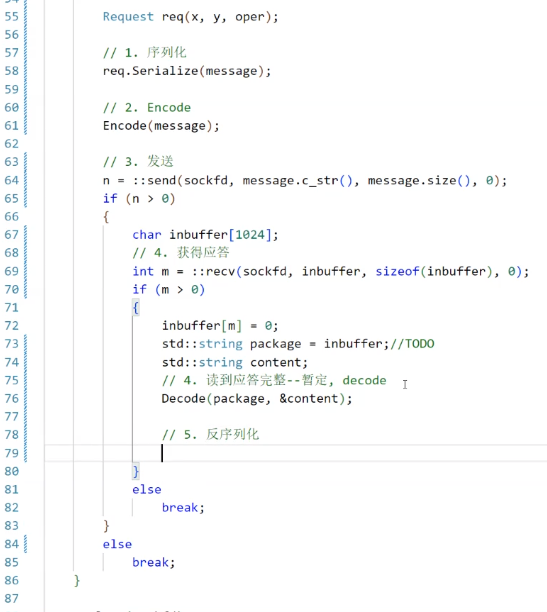
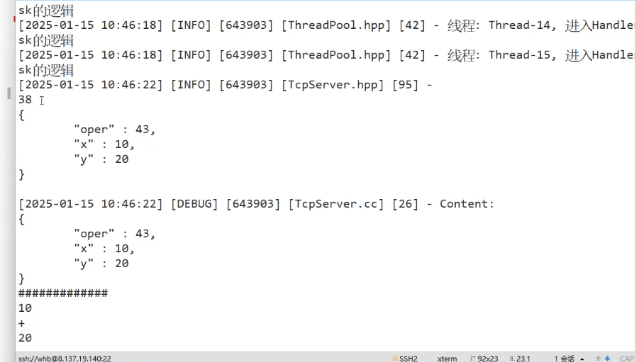
-------------------------------------------------------code end--------------------------------------------------------------
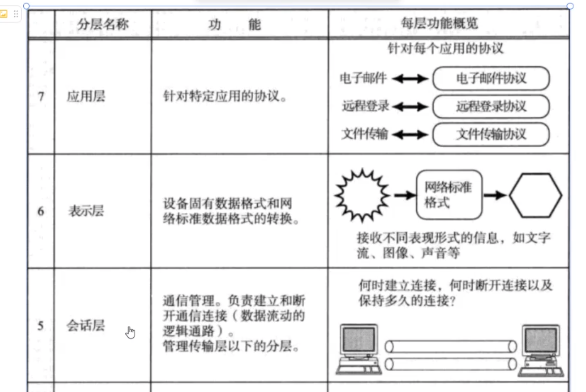
4. 再看OSI七层模型与TCP/IP四层协议
在比较 OSI 七层模型和 TCP/IP 模型时,我们可以观察到两者在低四层上是相同的。这种一致性的本质原因在于,这四层的功能是可以通过操作系统实现的。为了确保网络通信的顺畅进行,这四层的实现必须是统一的。
然而,当我们将目光转向 OSI 七层模型的上三层时,情况就有所不同了:
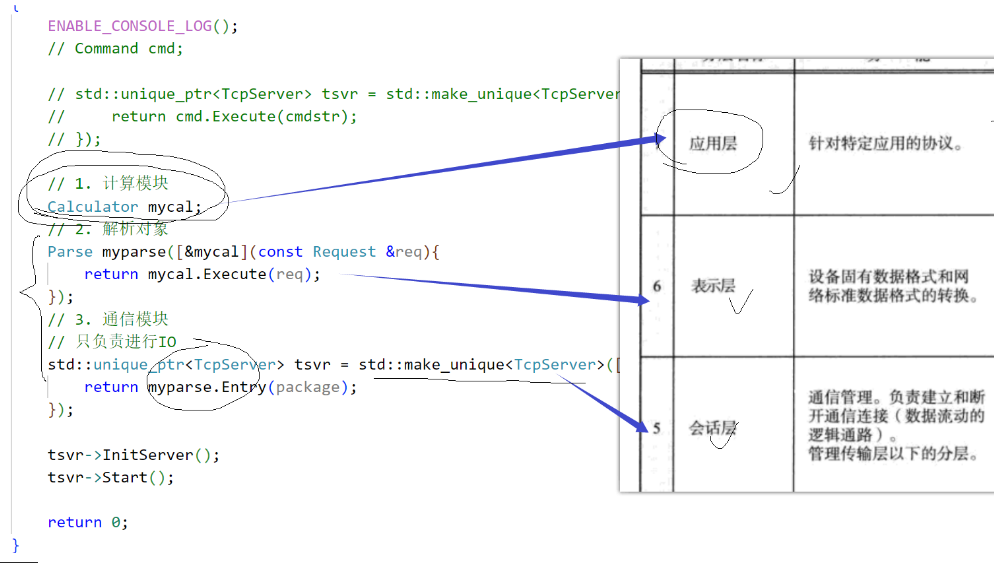
会话层(Session Layer):这一层主要负责通信管理,定义了客户端和服务器之间如何进行通信。这一功能的实现依赖于操作系统底层的接口,因此,会话层实际上是对下四层通信的管理和协调。在网络计算器的设计中,这一层对应于客户端和服务端的通信设计。再直白一点,这一层就是使用TCP这些接口的代码
表示层(Presentation Layer):一旦客户端和服务端能够正常通信,接下来的关键问题就是确定通信的具体内容。表示层负责设定传输内容的格式,确保双方能够识别并正确解析彼此的数据。在网络计算器的实现中,这一层对应于序列化和反序列化的过程,以及编码和解码的操作。这一层就是parse层次
应用层(Application Layer):最后,我们需要定义传输的内容,即结构化数据的设置。在网络计算器中,这一层对应于请求类和响应类的字段定义。这一层就是计算器
这三层紧密相连,缺少任何一层都会导致通信无法正确进行。TCP/IP 协议将 OSI 模型的这三层合并为一层的原因在于,这些功能无法由操作系统具体实现,它们属于操作系统之上的应用层面。这种合并简化了模型,同时保持了网络通信的核心功能。
)










--计数排序,排序算法复杂度对比和稳定性分析)
)
)


:绘图)


