3个不同的API可供评估模型预测质量:
-
评估器评分方法:评估器有一个score方法,它给计划解决的问题提供一个初始评估标准。这部分内容不在这里讨论,但会出现在每一个评估器的文件中。
-
评分参数:使用交叉验证(cross-validation)的模型评估方法(例如:model_selection.cross_val_score和model_selection.GridSearchCV基于一个内部评分策略。这部分内容将会在评分参数:定义模型评估规则部分详细介绍。
-
指标函数:metrics模块执行的功能是评估特定目的的误差。这些指标在分类指标, 多标签排序指标, 回归指标和聚类指标部分会详细介绍。
最后,Dummy评估器(Dummy评估器)可用于获取随机预测的这些指标基准值。
还可参见:对于“成对”指标,样本之间而不是评估器或者预测值之间,详见成对度量、亲和力和核函数部分。
一、评分参数:定义模型评估准则
1.1 常见场景:预定义值
在最常见的例子中,可以给scoring参数指定评分对象;下面的表格列出所有可能取值。所有记分对象遵从的惯例是:高返回值好于低返回值。因此,如metrics.mean_squared_error,衡量模型与数据间差距的指标可用neg_mean_squared_error,它返回一个负值。
| 评分 | 函数 | 评论 |
|---|---|---|
| 分类 | ||
| “accuracy”(准确率) | metrics.accuracy_score | |
| “balanced_accuracy”(平衡准确率) | metrics.balanced_accuracy_score | |
| “average_precision”(平均精确率) | metrics.average_precision_score | |
| “neg_brier_score”(负布里尔评分) | metrics.brier_score_loss | |
| “f1” | metrics.f1_score | 二分类 |
| “f1_micro” | metrics.f1_score | 微平均 |
| “f1_macro” | metrics.f1_score | 宏平均 |
| “f1_weighted” | metrics.f1_score | 加权平均 |
| “f1_samples” | metrics.f1_score | 多标签样本 |
| “neg_log_loss” | metrics.log_loss | 要求predict_proba支持 |
| "precision"等 | metrics.precision_score | 后缀适用于“f1” |
示例:
>>> from sklearn import svm, datasets
>>> from sklearn.model_selection import cross_val_score
>>> X,y = datasets.load_iris(return_X_y=True)
>>> clf=svm.SVC(random_state=0)
>>>cross_val_score(c1f,x,y,cv=5,scoring='reca11_macro')
array([0.96..., 0.96..., 0.96..., 0.93..., 1. ]
>>> model = svm.SVC()
>>>cross_val score(model,X,y,cv=5,scoring='wrong_choice')
Traceback (most recent call last):
ValueError: 'wrong_choice' is not a valid scoring value. Use sorted (sklearn.metrics.SCORERS.keys()) to get va
注意:ValueError列出的异常值对应于以下各节中说明的测量预测准确性函数。这些函数中的评分对象以字典形式存储在 sklearn.metrics.SCORES中。
1.2 根据metric函数定义评分策略
sklearn.metrics模块公开一组简单函数,该函数可应用于测量给定真实值和预测值的预测误差:
- 以_score为结尾的函数,返回一个最大值,该值越大越好。
- 以_error或_loss为结尾的函数,返回一个最小值,该值越小越好。当使用make_scorer把它转变为评分对象时,设置greater_is_better参数为False(初始值是True;详见下面的函数描述)。
各类机器学习任务的可用指标会在下文详细介绍。
许多指标没有给定名称就作为scoring的参数值,有时是因为它们需要额外的参数,例如fbeta_score。使用make_scorer是生成可调用对象进行评分的最简单方法,该函数将指标转换为可用于模型评估的可调用对象。
一个典型的例子是从库中包含一个非默认参数值中,包装现有指标函数,例如fbeta_score函数用来定义beta参数:
>>> from sklearn.metrics import fbeta_score, make_scorer
>>> ftwo_scorer = make_scorer(fbeta_score, beta=2)
>>> from sklearn.model_selection import GridSearchCV
>>> from sklearn.svm import LinearSVC
>>> grid = GridSearchCV(LinearSVC(), param_grid={'C': [1, 10]},
... scoring=ftwo_scorer, cv=5)
第二个例子是在简单python函数中使用make_scorer,以构建完全自定义评分对象,它可以接受几个参数:
-
可以使用的python函数(下例中使用my_custom_loss_func)
-
是否python函数返回一个分数(初始值为greater_is_better=True)或者一个损失(分数)(greater_is_better=False)。如果一个损失函数,python函数的返回值是负值的评分对象,符合交叉验证的传统,评分越高,模型越好。
-
仅对于分类的指标:是否python函数要求提供连续决定确定性(needs_threshold=True)。初始值是False。
-
任何其它参数,如f1_score中的beta或labels。
如下示例展示构建传统评分器,使用greater_is_better参数:
>>> import numpy as np
>>> def my_custom_loss_func(y_true, y_pred):
... diff = np.abs(y_true - y_pred).max()
... return np.log1p(diff)
...
>>> # score will negate the return value of my_custom_loss_func,
>>> # which will be np.log(2), 0.693, given the values for X
>>> # and y defined below.
>>> score = make_scorer(my_custom_loss_func, greater_is_better=False)
>>> X = [[1], [1]]
>>> y = [0, 1]
>>> from sklearn.dummy import DummyClassifier
>>> clf = DummyClassifier(strategy='most_frequent', random_state=0)
>>> clf = clf.fit(X, y)
>>> my_custom_loss_func(clf.predict(X), y)
0.69...
>>> score(clf, X, y)
-0.69...
1.3 执行自定义评分对象
无需使用make_scorer“制造厂”,就可以通过从头构建自定义评分对象,生成更加灵活的模型评分器。对于一个可调用的评分器,需要满足如下两个规定协议:
- 可以调用参数(estimator, X, y),estimator是需要被评估的模型,X是验证数据,y是X标签(应用于有监督的案例中)的真实值或者None(应用于非监督的案例中)。
- 它返回一个浮点型数值,该数值量化estimator对X关于y的预测质量。再强调一遍,越高的得分模型越好,所以如果得分是损失函数的返回值,那么该值应为负。
注意:当n_jobs>1时,函数中对传统评分器的使用
虽然在调用函数的旁边定义自定义评分函数应使用默认joblib backend(loky),但从另一个模块中导入时将会是更健壮的方法,并且独立于joblib backend(loky)。
例如,下例中将n_jobs设置为大于1,custom_scoring_function保存在user_created模块(custom_scorer_module.py)中并导入:
>>> from custom_scorer_module import custom_scoring_function
>>> cross_val_score(model,
... X_train,
... y_train,
... scoring=make_scorer(custom_scoring_function, greater_is_better=False),
... cv=5,
... n_jobs=-1)
1.4 使用多指标评估
Scikit-learn也允许在GridSearchCV,RandomizedSearchCV和cross_validate中评估多指标。
有两种方式可以指定scoring参数的多评分指标:
- 可迭代字符串指标:
>>> scoring = ['accuracy', 'precision']
以字典形式将评分器名称映射给评分函数:
深色版本
>>> from sklearn.metrics import accuracy_score
>>> from sklearn.metrics import make_scorer
>>> scoring = {'accuracy': make_scorer(accuracy_score),
... 'prec': 'precision'}
需要注意的是:字典的值或者是评分器函数,或者是预定义指标字符串的一个。
目前,只有返回单值的评分函数才能使用字典传递。评分函数返回多个值是不被允许的,并且要求封装从而返回单个指标值。
>>> from sklearn.model_selection import cross_validate
>>> from sklearn.metrics import confusion_matrix
>>> # A sample toy binary classification dataset
>>> X, y = datasets.make_classification(n_classes=2, random_state=0)
>>> svm = LinearSVC(random_state=0)
>>> def tn(y_true, y_pred): return confusion_matrix(y_true, y_pred)[0, 0]
>>> def fp(y_true, y_pred): return confusion_matrix(y_true, y_pred)[0, 1]
>>> def fn(y_true, y_pred): return confusion_matrix(y_true, y_pred)[1, 0]
>>> def tp(y_true, y_pred): return confusion_matrix(y_true, y_pred)[1, 1]
>>> scoring = {'tp': make_scorer(tp), 'tn': make_scorer(tn),
... 'fp': make_scorer(fp), 'fn': make_scorer(fn)}
>>> cv_results = cross_validate(svm.fit(X, y), X, y, cv=5, scoring=scoring)
>>> # Getting the test set true positive scores
>>> print(cv_results['test_tp'])
[10 9 8 7 8]
>>> # Getting the test set false negative scores
>>> print(cv_results['test_fn'])
[0 1 2 3 2]
二、分类指标
sklearn.metrics模块执行各种损失函数,评分,及调用函数测量分类模型的表现。一些指标可能要求正类别的可能性(probability)估计,置信度值,或者二分类决策值。大多数执行允许计算每一个样本对评分的权重贡献,通过sample_weight参数实现。
其中一些只适用于二分类的案例中:
| 参数 | 说明 |
|---|---|
precision_recall_curve(y_true, probs_pred, *) | 根据不同的可能性阈值计算精确率-召回率 |
roc_curve(y_true, y_score, *[pos_label, ...]) | 计算Receiver operating characteristic(ROC) |
其它也可用于多分类的参数例子:
| 参数 | 说明 |
|---|---|
balanced_accuracy_score(y_true, y_pred, *) | 计算balanced准确率 |
cohen_kappa_score(y1, y2, *[labels, ...]) | Cohen’s kappa: 衡量注一致程度的统计 |
confusion_matrix(y_true, y_pred, *[...]) | 计算混淆矩阵来评估分类模型的准确率 |
hinge_loss(y_true, pred_decision, *[...]) | 平均hinge损失(非正规 non-regularized) |
matthews_corrcoef(y_true, y_pred, *[...]) | 计算曼哈顿相关系数(MCC) |
roc_auc_score(y_true, y_score, *[...]) | 从预测分数中,计算ROC曲线的面积(ROC AUC) |
一些也可以用于多分类例子中的参数:
| 参数 | 说明 |
|---|---|
accuracy_score(y_true, y_pred, *[...]) | 分类模型的准确率得分 |
classification_report(y_true, y_pred, *[...]) | 主要分类模型指标的文本报告 |
f1_score(y_true, y_pred, *[labels, ...]) | 计算F1评分,也被称为balanced F-score或者F-measure |
fbeta_score(y_true, y_pred, *, beta[, ...]) | 计算F-beta评分 |
hamming_loss(y_true, y_pred, *[sample_weight]) | 计算平均Hamming损失 |
jaccard_score(y_true, y_pred, *[labels, ...]) | Jaccard相似性系数得分 |
log_loss(y_true, y_pred, *[eps, ...]) | 对数损失,aka logistic损失或者交叉熵损失 |
multilabel_confusion_matrix(y_true, y_pred, *) | 为每一个类或样本计算混淆矩阵 |
precision_recall_fscore_support(y_true, ...) | 计算精确率,召回率,F-measure并且支持每一个类 |
precision_score(y_true, y_pred, *[...]) | 计算精确率 |
recall_score(y_true, y_pred, *[labels, ...]) | 计算召回率 |
roc_auc_score(y_true, y_score, *[...]) | 从预测分数中计算ROC曲线的面积 |
zero_one_loss(y_true, y_pred, *[...]) | 0-1分类损失 |
可以处理二分类和多标签(不是多分类)的问题:
| 参数 | 说明 |
|---|---|
average_precision_score(y_true, y_score, *) | 从预测评分中计算平均精确率(AP) |
在随后的各子部分中,将会描述每一个上述函数,使用常用的API和指数定义。
2.1 从二分类到多分类和多标签
一些指标本质上是定义给二分类模型的(例如:f1_score)。在这些例子中,模型的默认值是只有正标签会被评估,假设正样本类的标签为1是初始值(尽管标签可以通过pos_label参数进行修改)。
由二分类指标延伸到多类或者多标签问题,数据被当作是二分类问题的集合,每个类都有一个。有一系列的方法可用于计算类集合的平均二分类指标,每个二分类指标可以应用于某些领域中。如果需要,可以使用average参数进行定义。
- “weighted”(权重)处理类的不均衡问题。按其在真实数据中的加权计算每个类的分数,并计算各二分类指标的平均值。
- “micro”(微)对于所有二分类指标(除非已分配样本权重)指定给每个样本类匹配相等的贡献。除了汇总每个类的指标,还要汇总除数和被除数,将每个类的各指标汇总成一个整体商(总被除数/总除数得出评估模型整体水平的商)。微-平均方法更适合多标签分类中,包括多类别分类问题,但多数类会被忽略。
- “samples”(样本)仅应用于多标签问题。它不对子类进行计算,而是计算评估数据中每个样本真实类别和预测类别的指标。最后返回它们的(sample_weight - weighted)均值。
- 设置参数
average = None会返回每个类得分的数组。
当多分类数据作为类标签数组提供给指标时,如二分类标签,多标签数据就会被指定为一个指标矩阵。如元素(一个列表形式)[i, j],如果样本i被标记为j,则其值为1,否则为0。
2.2 准确率评分
accuracy_score函数计算accuracy(准确率),或者是个分数(初始值)或者是正确预测个数的计数(normalize=False)。
在多标签分类中,函数返回各子集的准确率。如果整个集合中每一个样本的预测标签严格匹配集合中的标签真实值,子集的准确率是1.0;否则是0.0。
如果y^i\hat{y}_iy^i是第i个样本的预测值与真实值yiy_iyi相一致,对nsamplesn_{samples}nsamples
个样本正确预测的分数值是:
accuracy(y,y^)=1nsamples∑i=0nsamples−11(y^i=yi)\text{accuracy}(y, \hat{y}) = \frac{1}{n_{\text{samples}}} \sum_{i=0}^{n_{\text{samples}}-1} 1(\hat{y}_i = y_i) accuracy(y,y^)=nsamples1i=0∑nsamples−11(y^i=yi)
其中*1(x)*是指标函数(indicator function)。
>>> import numpy as np
>>> from sklearn.metrics import accuracy_score
>>> y_pred = [0, 2, 1, 3]
>>> y_true = [0, 1, 2, 3]
>>> accuracy_score(y_true, y_pred)
0.5
>>> accuracy_score(y_true, y_pred, normalize=False)
2
在带有二分类标签指标的多标签例子中:
>>> accuracy_score(np.array([[0, 1], [1, 1]]), np.ones((2, 2)))
0.5
2.3 平衡的准确率评分(Balanced accuracy score)
balanced_accuracy_score函数计算balanced accuracy,避免了对不平衡数据集进行夸大的性能估计。每个类别召回率的宏平均,或者等同于每个样本根据真实类别的比率(inverse prevalence)的权重,而计算的原始准确率。因此,对于平衡样本,平衡的准确率评分(Balanced accuracy score)与准确率相同。
在二分类的例子中,平衡的准确率与灵敏度(sensitivity)相同(真正率)和特异性(specificity)(真负率),或者ROC曲线的面积(二分类预测值而不是分数):
balanced-accuracy=12(TPTP+FN+TNTN+FP)\text{balanced-accuracy} = \frac{1}{2}\left(\frac{TP}{TP + FN} + \frac{TN}{TN + FP}\right) balanced-accuracy=21(TP+FNTP+TN+FPTN)
如果分类器在每个类的表现都很好,则该函数会退化为传统的准确率(例如:正确预测的个数除以总预测样本数)。
与之相对比,如果传统的准确率高于样本比例,仅因为分类器利用的是不均衡测试集,而对于平衡的准确率,会下降为
1nclasses\frac{1}{n_{\text{classes}}} nclasses1
分数范围为0-1,或者当参数adjusted=True时,范围变为
11−nclasses\frac{1}{1 - n_{\text{classes}}} 1−nclasses1
到1,包括边界的,随机得分表现为0。
如果yiy_iyi是第i个样本的真实值,wiw_iwi是对应的样本权重,从而调整的样本权重为:
w^i=wi∑j1(yj=yi)wj\hat{w}_i = \frac{w_i}{\sum_j 1(y_j = y_i) w_j} w^i=∑j1(yj=yi)wjwi
其中,l(x)l(x)l(x)是指标函数。根据样本i的预测值y^i\hat{y}_iy^i,平衡的准确率被定义如下:
balanced-accuracy(y,y^,w)=1∑w^i∑i1(y^i=yi)w^i\text{balanced-accuracy}(y, \hat{y}, w) = \frac{1}{\sum \hat{w}_i} \sum_i 1(\hat{y}_i = y_i) \hat{w}_i balanced-accuracy(y,y^,w)=∑w^i1i∑1(y^i=yi)w^i
设置adjusted=True,平衡的准确率报告的是比w^i=wi∑j1(yj=yi)wj\hat{w}_i = \frac{w_i}{\sum_j 1(y_j = y_i) w_j}w^i=∑j1(yj=yi)wjwi相对高的值。在二分类的例子中,也被称为Youden’s J statistic或者informedness。
**注意:**多分类的定义看起来是用于二分类指标的合理延伸,尽管在文献中未达成共识。
- 我们的定义:[Mosley2013],[Kelleher2015]和[Guyon2015],其中[Guyon2015]适合调整的版本,以确保随机预测值为0,好的预测值为1。
- 类的均衡准确率在[Mosley2013]中描述:每个类别中精确率和召回率的最小值会被计算。将计算出的这些值进行平均,从而得到均衡的准确率。
- 均衡的准确率在[Urbanowicz2015]中被描述:每一个类别的灵敏度和特异性的均值会被计算,随后计算总的均值。
2.4 Cohen’s kappa
cohen_kappa_score函数计算Cohen’s kappa统计值。此度量旨在比较不同标注的标签,而分类器和真实数据的比较。
Kappa score(参见文档字符串)是一个数值,介于-1和1之间。分数大于0.8会被认为是好的协议;小于0说明没有协议(等同于随机标签)。
Kappa score可被用于计算二分类或者多分类的问题,但不适用于多标签的问题(除手动计算每一个标签分数)和多于两个以上注释器的问题。
>>> from sklearn.metrics import cohen_kappa_score
>>> y_true = [2, 0, 2, 2, 0, 1]
>>> y_pred = [0, 0, 2, 2, 0, 2]
>>> cohen_kappa_score(y_true, y_pred)
0.4285714285714286
2.5 混淆矩阵
confusion_matrix函数评估分类模型准确率,通过计算每一行相对应真实类别(维基百科或者其它资料可能使用不同的轴向)的混淆矩阵(confusion matrix)。
根据定义,混淆矩阵中的条目ij是实际为i,但是预测为j的观测个数。
如下示例:
>>> from sklearn.metrics import confusion_matrix
>>> y_true = [2, 0, 2, 2, 0, 1]
>>> y_pred = [0, 0, 2, 2, 0, 2]
>>> confusion_matrix(y_true, y_pred)
array([[2, 0, 0],[0, 0, 1],[1, 0, 2]])
plot_confusion_matrix可被用于展示混淆矩阵的可视化,在混淆矩阵的例子中,如下图所示:
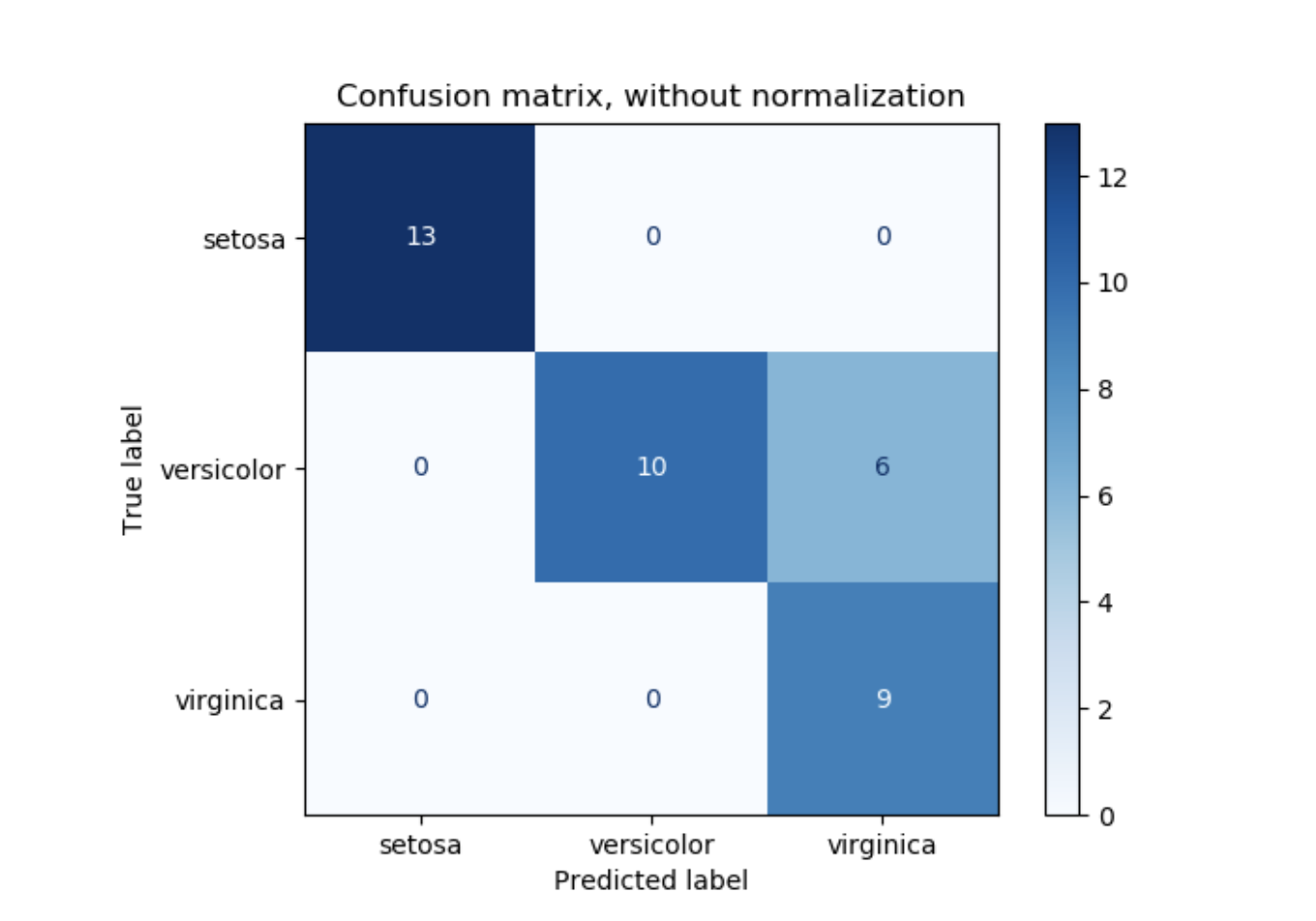
参数normalize允许报告比例而不仅是计数。混淆矩阵可以通过3种方式被规范化:“pred”, “true”, 和"all",这些参数将计算方式区分为按列求和,按行求和,或者整个矩阵求和。
>>> y_true = [0, 0, 0, 1, 1, 1, 1, 1]
>>> y_pred = [0, 1, 0, 1, 0, 1, 0, 1]
>>> confusion_matrix(y_true, y_pred, normalize='all')
array([[0.25 , 0.125],[0.25 , 0.375]])
对于二分类问题,可以得到真负值计数,假正值计数,假负值计数和真正值计数,详见如下代码:
>>> y_true = [0, 0, 0, 1, 1, 1, 1, 1]
>>> y_pred = [0, 1, 0, 1, 0, 1, 0, 1]
>>> tn, fp, fn, tp = confusion_matrix(y_true, y_pred).ravel()
>>> tn, fp, fn, tp
(2, 1, 2, 3)
2.6 分类模型报告
classification_report函数输出一个文本报告,显示主要分类模型的评估指标。如下是一个自定义target_names和推断标签的例子:
>>> from sklearn.metrics import classification_report
>>> y_true = [0, 1, 2, 2, 0]
>>> y_pred = [0, 0, 2, 1, 0]
>>> target_names = ['class 0', 'class 1', 'class 2']
>>> print(classification_report(y_true, y_pred, target_names=target_names))precision recall f1-score supportclass 0 0.67 1.00 0.80 2class 1 0.00 0.00 0.00 1class 2 1.00 0.50 0.67 2accuracy 0.60 5macro avg 0.56 0.50 0.49 5
weighted avg 0.67 0.60 0.59 5
2.7 Hamming损失函数
Hamming_loss 计算平均的 Hamming loss 或者 Hamming distance 在两个样本的集合中。
如果 y^j\hat{y}_jy^j 是某个样本第 jjj 个标签的预测值,yjy_jyj 是其对应的真实值,
nlabels\text{nlabels}nlabels
是类别或者标签个数,Hamming 损失函数 LHammingL_{\text{Hamming}}LHamming 介于两个样本之间:
LHamming(y,y^)=1nlabels∑j=0nlabels−11(y^j≠yj)L_{\text{Hamming}}(y, \hat{y}) = \frac{1}{n_{\text{labels}}} \sum_{j=0}^{n_{\text{labels}}-1} 1(\hat{y}_j \neq y_j) LHamming(y,y^)=nlabels1j=0∑nlabels−11(y^j=yj)
其中,l(x) 是指标函数(indicator function)。
>>> from sklearn.metrics import hamming_loss
>>> y_pred = [1, 2, 3, 4]
>>> y_true = [2, 2, 3, 4]
>>> hamming_loss(y_true, y_pred)
0.25
在二分类标签指标的多分类标签中:
>>> hamming_loss(np.array([[0, 1], [1, 1]]), np.zeros((2, 2)))
0.75
注意: 在多分类的分类模型中,y_true 和 y_pred 的 Hamming 损失函数与 Hamming 距离相一致。Hamming 损失函数与零一损失函数(Zero one loss)相类似。但是零一损失函数惩罚预测集合,预测集不与真实值集直接匹配;Hamming 损失函数惩罚单个标签。因此,Hamming 损失函数的上限是零一损失函数,它介于零和一之间,包括边界;预测真实标签合适的子集或者超子集会使 Hamming 损失函数界于零和一之间,不包括边界。
2.8 精确率,召回率和F-measures
直观地说,精确率(precision)是模型区分的能力,而不是将样本为负的标签标记为正,而召回率(recall)是找到正样本的能力。
F-measure(FβF\betaFβ 和 F1F1F1 测量)可被解释为精确率和召回率的权重调和平均数。FβF\betaFβ 测量值最高为 1,最差为 0。当 β=1\beta = 1β=1 时,FβF\betaFβ 和 F1F1F1 是相等的,并且召回率和精确率是同等重要的。
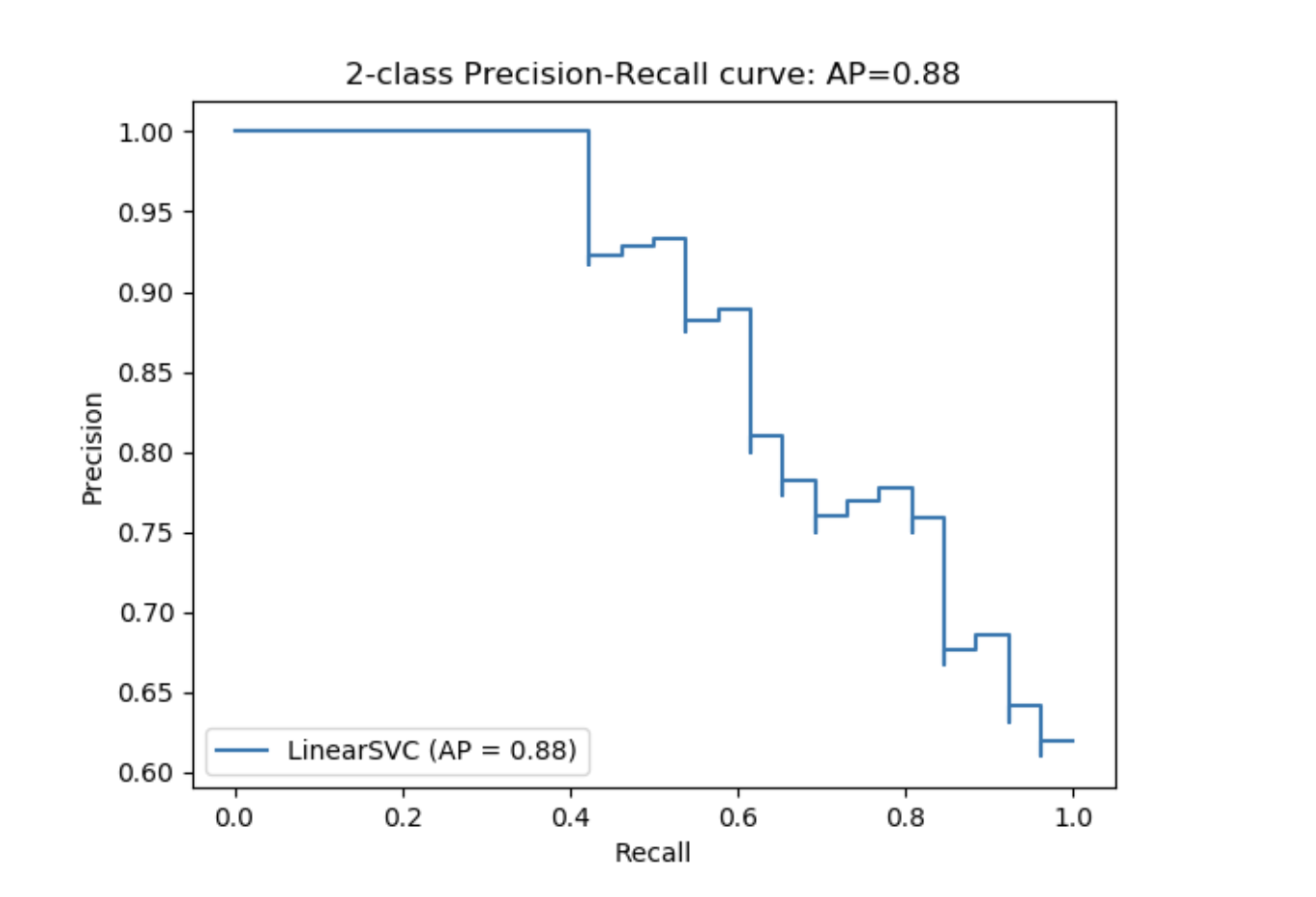
precision_recall_curve 从真实标签和评分(不同阈值设定下,分类器的评分)计算一个精确率-召回率曲线。
average_precision_score 函数从预测分数中计算平均精确率(average precision (AP))。该值介于 0 和 1 之间,且越高越好。AP 的定义如下:
AP=∑n(Rn−Rn−1)Pn\text{AP} = \sum_{n}(R_n - R_{n-1})P_n AP=n∑(Rn−Rn−1)Pn
其中,PnP_nPn 和 RnR_nRn 是在第 nnn 个阈值下的精确率和召回率,AP 是正样本的分数。
参考 [Manning2008] 和 [Everingham2010] 展现 AP 的替代变体,它差值计算精确率-召回率曲线。目前,average_precision_score 并不能执行各种差值的变体。参考 [Davis2006] 和 [Flach2015] 描述了为何精确率-召回率曲线上点的线性插值产生的结果是过于乐观的分类器表现测量。线性插值被用于计算带有梯形法则的 ROC 曲线面积,即 auc。
以下函数提供对精确率、召回率和F-measure评分的解释:
| 参数 | 解释 |
|---|---|
average_precision_score(y_true, y_score, *) | 从预测评分中计算平均精确率 |
f1_score(y_true, y_pred, *[labels, ...]) | 计算F1评分,也被称为均衡的F-score或F-measure |
fbeta_score(y_true, y_pred, *, beta[, ...]) | 计算F-beta评分 |
precision_recall_curve(y_true, probas_pred, *) | 计算在不同的阈值下精确率-召回率组合 |
precision_recall_fscore_support(y_true, ...) | 计算精确率、召回率、F-measure,且支持对每一类的计算 |
precision_score(y_true, y_pred, *[, ...]) | 计算精确率 |
recall_score(y_true, y_pred, *[, labels, ...]) | 计算召回率 |
需要注意的是:precision_recall_curve 函数只能用于二分类的例子中。average_precision_score 函数可以用于二分类的分类模型和多标签形式。plot_precision_recall_curve 函数画出精确率召回率关系图,如下所示。
2.8.1 二分类分类模型
在二分类分类模型中,分类预测中的“正”和“负”,“真”和“假”指的是预测值是否与外部评判(也作“观测值”)相一致。基于这些定义,可以总结一下表格:
| 预测类别(期望) | 实际类别(观测值) | 实际类别(观测值) |
|---|---|---|
| tp(真正)正确的结果 | fp(假正)意料外的结果 | |
| fn(假负)错误的结果 | tn(真负)正确未出现的结果 |
基于上文,可以定义精确率、召回率和F-measure的概念:
precision=tptp+fprecall=tptp+fnFβ=(1+β2)precision×recallβ2⋅precision+recall\begin{align*} \text{precision} &= \frac{tp}{tp + fp} \\ \text{recall} &= \frac{tp}{tp + fn} \\ F_\beta &= (1 + \beta^2) \frac{\text{precision} \times \text{recall}}{\beta^2 \cdot \text{precision} + \text{recall}} \end{align*} precisionrecallFβ=tp+fptp=tp+fntp=(1+β2)β2⋅precision+recallprecision×recall
如下是二分类分类模型代码示例:
>>> from sklearn import metrics
>>> y_pred = [0, 1, 0, 0]
>>> y_true = [0, 1, 0, 1]
>>> metrics.precision_score(y_true, y_pred)
1.0
>>> metrics.recall_score(y_true, y_pred)
0.5
>>> metrics.f1_score(y_true, y_pred)
0.66...
>>> metrics.fbeta_score(y_true, y_pred, beta=0.5)
0.83...
>>> metrics.fbeta_score(y_true, y_pred, beta=1)
0.66...
>>> metrics.fbeta_score(y_true, y_pred, beta=2)
0.55...
>>> metrics.precision_recall_fscore_support(y_true, y_pred, beta=0.5)
(array([0.66..., 1. ]), array([1. , 0.5]), array([0.71..., 0.83...]), array([2, 2]))>>> import numpy as np
>>> from sklearn.metrics import precision_recall_curve
>>> from sklearn.metrics import average_precision_score
>>> y_true = np.array([0, 0, 1, 1])
>>> y_scores = np.array([0.1, 0.4, 0.35, 0.8])
>>> precision, recall, threshold = precision_recall_curve(y_true, y_scores)
>>> precision
array([0.66..., 0.5 , 1. , 1. ])
>>> recall
array([1. , 0.5, 0.5, 0. ])
>>> threshold
array([0.35, 0.4 , 0.8 ])
>>> average_precision_score(y_true, y_scores)
0.83...
2.8.2 多分类和多标签分类模型
在多分类和多标签分类任务中,精确率,召回率,和F-measures的定义可以应用于每一个独立的标签。有很多方法可以将各标签的结果进行组合,可用average参数分别在average_precision_score(仅用于多标签),f1_score,fbeta_score,precision_recall_support,precision_score和recall_score函数中传递,已在以上描述(above)。需要注意的是:如果所有的标签啊都包括在内,那么"micro"-averaging(“微”-平均)在多分类中的设置将产生精确率,召回率和F与准确率的结果相等。也要注意"权重"平均可能产生不介于精确率和召回率之间的F-score。
为了更清晰的了解,请考虑如下概念:
- yyy 是预测值(样本, 标签)组合的集合
- y^\hat{y}y^ 是真实值(样本, 标签)组合的集合
- LLL 是标签的集合
- SSS 是样本的集合
- ysysys 是 yyy 的样本 sss 的子集,例如: ys:={(s′,l)∈y∣s′=s}ys := \{(s', l) \in y | s' = s\}ys:={(s′,l)∈y∣s′=s}
- ylylyl 是 yyy 的标签 lll 的子集
- 同样地,ys^\hat{ys}ys^ 和 yl^\hat{yl}yl^ 均是 y^\hat{y}y^ 的子集
- P(A,B):=∣A∩B∣∣A∣P(A, B) := \frac{|A \cap B|}{|A|}P(A,B):=∣A∣∣A∩B∣
- R(A,B):=∣A∩B∣∣B∣R(A, B) := \frac{|A \cap B|}{|B|}R(A,B):=∣B∣∣A∩B∣ (在处理 B=∅B=\emptysetB=∅ 时,公约有所不同;这个执行使用 R(A,B):=0R(A, B):=0R(A,B):=0,并且与 PPP 类似)
- Fβ(A,B):=(1+β2)P(A,B)×R(A,B)β2P(A,B)+R(A,B)F_\beta(A, B) := (1 + \beta^2) \frac{P(A, B) \times R(A, B)}{\beta^2 P(A, B) + R(A, B)}Fβ(A,B):=(1+β2)β2P(A,B)+R(A,B)P(A,B)×R(A,B)
各指标定义如下:
| average | Precision | Recall | F_beta |
|---|---|---|---|
| “micro” | P(y,y^)P(y, \hat{y})P(y,y^) | R(y,y^)R(y, \hat{y})R(y,y^) | Fβ(y,y^)F_\beta(y, \hat{y})Fβ(y,y^) |
| “samples” | 1∣S∣∑s∈SP(ys,ys^)\frac{1}{|S|} \sum_{s \in S} P(ys, \hat{ys})∣S∣1∑s∈SP(ys,ys^) | 1∣S∣∑s∈SR(ys,ys^)\frac{1}{|S|} \sum_{s \in S} R(ys, \hat{ys})∣S∣1∑s∈SR(ys,ys^) | 1∣S∣∑s∈SF(ys,ys^)\frac{1}{|S|} \sum_{s \in S} F(ys, \hat{ys})∣S∣1∑s∈SF(ys,ys^) |
| “macro” | 1∣L∣∑l∈LP(yl,yl^)\frac{1}{|L|} \sum_{l \in L} P(yl, \hat{yl})∣L∣1∑l∈LP(yl,yl^) | 1∣L∣∑l∈LR(yl,yl^)\frac{1}{|L|} \sum_{l \in L} R(yl, \hat{yl})∣L∣1∑l∈LR(yl,yl^) | 1∣L∣∑l∈LF(yl,yl^)\frac{1}{|L|} \sum_{l \in L} F(yl, \hat{yl})∣L∣1∑l∈LF(yl,yl^) |
| “weighted” | 1∑l∈L∣yl^∣∑l∈L∣yl^∣P(yl,yl^)\frac{1}{\sum_{l \in L} |\hat{yl}|} \sum_{l \in L} |\hat{yl}| P(yl, \hat{yl})∑l∈L∣yl^∣1∑l∈L∣yl^∣P(yl,yl^) | 1∑l∈L∣yl^∣∑l∈L∣yl^∣R(yl,yl^)\frac{1}{\sum_{l \in L} |\hat{yl}|} \sum_{l \in L} |\hat{yl}| R(yl, \hat{yl})∑l∈L∣yl^∣1∑l∈L∣yl^∣R(yl,yl^) | 1∑l∈L∣yl^∣∑l∈L∣yl^∣F(yl,yl^)\frac{1}{\sum_{l \in L} |\hat{yl}|} \sum_{l \in L} |\hat{yl}| F(yl, \hat{yl})∑l∈L∣yl^∣1∑l∈L∣yl^∣F(yl,yl^) |
| None | $\langle P(yl, \hat{yl}) | l \in L \rangle$ | $\langle R(yl, \hat{yl}) |
>>> from sklearn import metrics >>> y_true = [0, 1, 2, 0, 1, 2] >>> y_pred = [0, 2, 1, 0, 0, 1] >>> metrics.precision_score(y_true, y_pred, average='macro') 0.22... >>> metrics.recall_score(y_true, y_pred, average='micro') 0.33... >>> metrics.f1_score(y_true, y_pred, average='weighted') 0.26... >>> metrics.fbeta_score(y_true, y_pred, average='macro', beta=0.5) 0.23... >>> metrics.precision_recall_fscore_support(y_true, y_pred, beta=0.5, average=None) (array([0.66..., 0. , 0. ]), array([1., 0., 0.]), array([0.71..., 0. , 0. ]), array([2, 2, 2]...))对于带有“负类”的多分类类别,可以除去一些标签:
>>> metrics.recall_score(y_true, y_pred, labels=[1, 2], average='micro')
... # excluding 0, no labels were correctly recalled
0.0
同样地,一些未在样本中出现的标签,可以考虑使用宏-平均(macro-averaging)。
>>> metrics.precision_score(y_true, y_pred, labels=[0, 1, 2, 3], average='macro')
0.166...
未完待续、、、、


Ubuntu环境配置)

:xml.dom.minidom模块高阶使用方法)


)
)


的核心板)






深度解析)
