目录
一、前言
二、Kafka 介绍
2.1 什么是 Apache Kafka
2.2 Kafka 核心概念与架构
2.3 Kafka 为什么如此强大
2.4 Kafka 在微服务领域的应用场景
三、Docker 部署Kakfa服务
3.1 环境准备
3.2 Docker部署Kafka操作过程
3.2.1 创建docker网络
3.2.2 启动zookeeper容器
3.2.3 启动kafka容器
3.3 kafka使用效果验证
四、SpringBoot整合Kafka完整过程
4.1 前置准备
4.1.1 环境依赖
4.1.2 导入核心依赖
4.1.3 添加配置文件
4.2 代码整合过程
4.2.1 增加消息传递对象类
4.2.2 创建发送消息的工具类
4.2.3 创建消费者
4.2.4 增加一个操作topic的工具类
4.2.5 创建测试接口
4.2.6 效果验证
五、写在文末
一、前言
kafka在众多的领域中都有着广泛的使用。作为一款久经考验性能强劲的消息中间件,在大数据、微服务、电商、金融等众多领域的IT系统中承担着重要的角色。利用kafka的高吞吐、高性能等特点,应用程序很容易进行适合高并发的架构拓展设计,为架构优化、系统性能提升、应用程序解耦等场景提供了有力的支撑。在微服务领域,kafka的应用,可以让微服务的设计能够应对更多复杂的业务场景,本文以SpringBoot为例,详细介绍如何在SpringBoot的微服务项目中集成和使用kafka。
二、Kafka 介绍
2.1 什么是 Apache Kafka
Apache Kafka 最初由 LinkedIn 开发,并于 2011 年开源,现已发展成为一款开源的分布式事件流平台。它的核心设计目标是能够高效地处理实时数据流,具备高吞吐量、可扩展性、持久性和容错性。官网:Apache Kafka
你可以把它理解为一个高度耐用、永不丢失的“消息队列”,但它的能力远不止于此。它更像是一个中央神经系统,用于连接不同应用程序、系统和数据源,让数据能够以流的形式在其中可靠地流动。
2.2 Kafka 核心概念与架构
要理解 Kafka,首先需要了解几个核心概念:
-
Topic(主题):数据的类别或Feed名称。消息总是被发布到特定的 Topic,好比数据库中的表。
-
Producer(生产者):向 Topic 发布消息的客户端应用程序。
-
Consumer(消费者):订阅 Topic 并处理发布的消息的客户端应用程序。
-
Broker(代理):一个 Kafka 服务器就是一个 Broker。一个 Kafka 集群由多个 Broker 组成,以实现高可用和负载均衡。
-
Partition(分区):每个 Topic 可以被分成多个 Partition。分区是 Kafka 实现水平扩展和并行处理的基础。消息在分区内是有序的(但跨分区不保证顺序)。
-
Consumer Group(消费者组):由多个消费者实例组成,共同消费一个 Topic。同一个分区只会被分配给同一个消费者组内的一个消费者,从而实现“负载均衡”和“Scale-Out”(横向扩展)的消费模式。
-
Offset(偏移量):消息在分区中的唯一标识。消费者通过管理 Offset 来追踪自己消费到了哪里,即使重启也不会丢失位置。
2.3 Kafka 为什么如此强大
-
高吞吐量:即使使用普通的硬件,也能支持每秒数十万甚至百万级的消息处理。
-
可扩展性:通过简单地增加 Broker 和分区,可以轻松扩展集群,处理更大的数据量。
-
持久性与可靠性:消息被持久化到磁盘,并且通过副本机制(Replication)在多台服务器上进行备份,防止数据丢失。
-
实时性:消息产生后立刻可供消费,延迟极低,是真正的实时流处理平台。
2.4 Kafka 在微服务领域的应用场景
在微服务架构中,服务被拆分为多个小型、独立的单元。这些服务之间需要通信和协作,而 Kafka 正是实现这种松耦合、异步通信的理想选择。具体来说,Kafka 可以在下面的场景中使用。
1)服务间异步通信(解耦)
-
场景:订单服务创建订单后,需要通知库存服务扣减库存、通知用户服务发送短信、通知分析服务更新统计数据。
-
传统问题:如果使用同步 HTTP 调用(如 REST),订单服务需要等待所有调用成功后才能返回,导致响应慢,且任何一个下游服务故障都会导致整个操作失败(紧耦合)。
-
Kafka 方案:订单服务只需将一条
OrderCreated事件发送到 Kafka 的ordersTopic,然后就可以立即返回响应。库存、用户、分析等服务作为消费者,各自独立地从该 Topic 拉取消息并进行处理。实现了服务的彻底解耦:订单服务不关心谁消费、何时消费、消费是否成功。
2)事件溯源(Event Sourcing)与 CQRS
-
事件溯源:不存储对象的当前状态,而是存储所有改变状态的事件序列。Kafka 的持久化日志特性使其成为存储这些事件的完美“事件存储”。
-
CQRS(命令查询职责分离):写模型(命令端)在处理完命令后,将领域事件发布到 Kafka。读模型(查询端)订阅这些事件,并更新自己的物化视图(如 Elasticsearch、Redis 中的查询专用数据)。这极大地提高了系统的查询性能和灵活性。
3)流处理与实时数据管道
使用 Kafka Streams 或 ksqlDB 这样的流处理库,可以直接在微服务中构建复杂的实时数据处理逻辑。
场景:实时监控用户点击流、实时计算仪表盘、实时风控、实时推荐。
4)日志聚合(Log Aggregation)
将多个微服务的日志集中收集到 Kafka 中,然后再导入到 ELK(Elasticsearch, Logstash, Kibana)或 Splunk 等中央日志系统中进行分析和查询。Kafka 作为缓冲层,可以应对日志量的突发高峰,防止冲垮后端的日志存储系统。
5)小结:
在 Java 微服务架构中,Apache Kafka 远不止一个消息队列。它还具备下面多种角色:
-
服务的粘合剂:以事件驱动的方式连接孤立的微服务,实现高度解耦和弹性。
-
实时数据流的中心枢纽:所有重要的业务事件都流经此处,为构建实时应用提供数据基础。
-
流处理平台:允许开发者直接在微服务中编写实时数据处理逻辑。
其与 Spring Boot 等主流 Java 框架的无缝集成,使得它成为构建现代、可扩展、高响应的 Java 微服务系统时不可或缺的基础设施。选择 Kafka,意味着为你的微服务系统选择了面向未来的架构模式。
三、Docker 部署Kakfa服务
为了后面在工程中对接与使用Kafka,需要提前准备一个Kafka的服务,下面使用docker快速部署一个Kakfa,参考下面的过程完成基于Docker环境部署kafka的操作流程。
3.1 环境准备
服务器推荐:2核4G(至少),提前在服务器安装好docker环境
3.2 Docker部署Kafka操作过程
3.2.1 创建docker网络
搭配zookeeper进行使用,这个是部署kafka比较经典的方式,为了更好的让kafka与zookeeper交互,提前创建一个docker网络
docker network create kafka-net
3.2.2 启动zookeeper容器
使用下面的命令启动zookeeper容器
docker run -d \--name zookeeper_01 \--network kafka-net \-p 12179:2181 \-e ZOO_TICK_TIME=2000 \zookeeper:latest
参数解释:
-
-d: 后台运行容器。 -
--name: 为容器指定一个名称。 -
--network: 加入创建的kafka-net网络。 -
-p 12179:2181: 将容器的12179端口映射到宿主机的 2181 端口。 -
-e ZOO_TICK_TIME=2000: 设置 ZooKeeper 的基本时间单位(毫秒)。
3.2.3 启动kafka容器
使用下面的命令启动kafka容器
docker run -d \
--name kafka_01 \
-p 19091:9092 \
-e KAFKA_BROKER_ID=0 \
-e KAFKA_ZOOKEEPER_CONNECT=服务器公网IP:12179 \
-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://服务器公网IP:19091 \
-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \
wurstmeister/kafka:latest
docker 参数说明:
-
KAFKA_ADVERTISED_LISTENERS: 非常重要。Broker 发布给客户端(生产者、消费者)的连接地址。如果客户端在宿主机外,需替换localhost为宿主机 IP。 -
KAFKA_LISTENERS: Broker 实际监听的地址和协议,0.0.0.0表示监听所有网络接口。 -
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 设置内部偏移量主题的副本因子,单机设为 1 即可。
3.3 kafka使用效果验证
kafka的服务搭建完成之后,接下来验证下是否可以先通过客户端操作命令正常使用topic进行收发消息。
1)进入 Kafka 容器:
docker exec -it kafka_01 /bin/bash2)创建一个topic
kafka-topics.sh --create --zookeeper 公网IP:12179 --replication-factor 1 --partitions 1 --topic test-topic3)启动生产者窗口
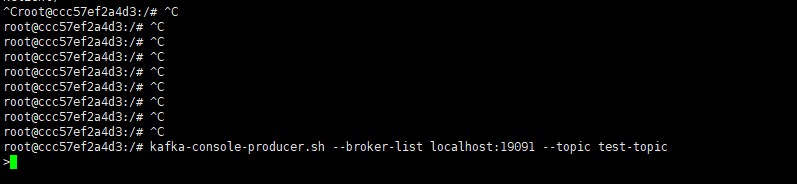
开启一个生产者窗口,尝试往上面的topic中发送消息
kafka-console-producer.sh --broker-list 公网IP:19091 --topic test-topic看到下面的效果说明生产端连接上了
4)启动消费者窗口
开启一个新的消费者窗口,尝试从上面的topic中接收消息
kafka-console-consumer.sh --bootstrap-server 公网IP:19091 --topic test-topic --from-beginning看到下面的效果说明消费端接收消息就绪了

5)发送消息
接下来从生产者窗口发送一条消息,可以看到消息能够正常的发送出去,同时消费端也能接收到消息

四、SpringBoot整合Kafka完整过程
接下来通过案例操作详细介绍下如何在springboot项目中整合与使用kafka。
4.1 前置准备
4.1.1 环境依赖
首先确保你的开发环境满足以下要求:
-
Java 17+ (Spring Boot 3 需要 Java 17 或更高版本)
-
Apache Kafka (本地安装或使用 Docker 容器)
-
Maven 或 Gradle 构建工具
4.1.2 导入核心依赖
提前创建一个springboot工程,并导入如下核心依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>mcp-client</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>17</maven.compiler.source><maven.compiler.target>17</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.3.3</version><relativePath/></parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- Mysql Connector --><dependency><groupId>com.mysql</groupId><artifactId>mysql-connector-j</artifactId></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>3.0.3</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.5</version><exclusions><exclusion><groupId>org.mybatis</groupId><artifactId>mybatis-spring</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><dependency><groupId>com.github.ulisesbocchio</groupId><artifactId>jasypt-spring-boot-starter</artifactId><version>3.0.5</version> <!-- 建议使用最新版本 --></dependency><dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId></dependency></dependencies><build><finalName>${project.artifactId}</finalName><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>4.1.3 添加配置文件
在工程的yml配置文件中增加下面有关kafka的信息
server:port: 8082spring:kafka:bootstrap-servers: IP:9092#生产者配置producer:retries: 3batch-size: 16384 # 批量处理大小buffer-memory: 33554432 # 生产者缓冲内存大小acks: all # 消息确认机制key-serializer: org.apache.kafka.common.serialization.StringSerializer#value-serializer: org.springframework.kafka.support.serializer.JsonSerializer # JSON类型的序列化value-serializer: org.apache.kafka.common.serialization.StringSerializer # 字符串类型的序列化#消费者配置consumer:group-id: consumer-group # 消费者组IDauto-offset-reset: earliest # 当无初始offset或offset失效时的处理方式enable-auto-commit: false # 关闭自动提交偏移量key-deserializer: org.apache.kafka.common.serialization.StringDeserializer#value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer # JSON类型的反序列化value-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 字符串类型的序列化#需要搭配对象类型的序列化一起使用#properties:#spring.json.trusted.packages: "*"listener:ack-mode: MANUAL_IMMEDIATE # 手动立即提交偏移量:cite[4]mybatis-plus:# 不支持多包, 如有需要可在注解配置 或 提升扫包等级# 例如 com.**.**.mappermapperPackage: com.congge.mapper# 对应的 XML 文件位置mapperLocations: classpath*:mapper/**/*Mapper.xml# 实体扫描,多个package用逗号或者分号分隔typeAliasesPackage: com.congge.entityglobal-config:dbConfig:# 主键类型# AUTO 自增 NONE 空 INPUT 用户输入 ASSIGN_ID 雪花 ASSIGN_UUID 唯一 UUID# 如需改为自增 需要将数据库表全部设置为自增idType: ASSIGN_ID# 逻辑已删除值(默认为 1)logic-delete-value: 1# 逻辑未删除值(默认为 0)logic-not-delete-value: 04.2 代码整合过程
参考下面的操作过程完成代码的整合。
4.2.1 增加消息传递对象类
自定义一个消息对象,用于承载某些复杂场景下对传递消息的要求
package com.congge.kafka;import java.time.LocalDateTime;public class MessageData {private Long id;private String content;private LocalDateTime timestamp;// 构造方法public MessageData() {}public MessageData(Long id, String content, LocalDateTime timestamp) {this.id = id;this.content = content;this.timestamp = timestamp;}// Getter和Setter方法public Long getId() {return id;}public void setId(Long id) {this.id = id;}public String getContent() {return content;}public void setContent(String content) {this.content = content;}public LocalDateTime getTimestamp() {return timestamp;}public void setTimestamp(LocalDateTime timestamp) {this.timestamp = timestamp;}@Overridepublic String toString() {return "MessageData{" +"id=" + id +", content='" + content + '\'' +", timestamp=" + timestamp +'}';}}4.2.2 创建发送消息的工具类
创建一个工具类用于发送消息,为了后续使用方便,该类作为spring bean配置到IOC容器中,其他类需要使用的时候直接注入即可。
-
该类中定义了多个发送消息的方法,可用于发送不同类型的消息,比如比较常用的字符串消息,对象消息等,可以根据实际的业务场景选型使用;
package com.congge.utils;import com.congge.kafka.MessageData;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Service;import java.time.LocalDateTime;
import java.util.concurrent.CompletableFuture;@Service
public class KafkaProducerService {private static final Logger logger = LoggerFactory.getLogger(KafkaProducerService.class);private static final String TOPIC_NAME = "test-topic";private final KafkaTemplate<String, Object> kafkaTemplate;public KafkaProducerService(KafkaTemplate<String, Object> kafkaTemplate) {this.kafkaTemplate = kafkaTemplate;}/*** 发送字符串消息*/public void sendStringMessage(String message) {CompletableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC_NAME, message);future.whenComplete((result, ex) -> {if (ex == null) {logger.info("Sent message=[{}] with offset=[{}]", message, result.getRecordMetadata().offset());} else {logger.error("Unable to send message=[{}] due to: {}", message, ex.getMessage());}});}/*** 发送对象消息(JSON格式)*/public void sendObjectMessage(Long id, String content) {MessageData messageData = new MessageData(id, content, LocalDateTime.now());CompletableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC_NAME, messageData);future.whenComplete((result, ex) -> {if (ex == null) {logger.info("Sent message=[{}] with offset=[{}]", messageData, result.getRecordMetadata().offset());} else {logger.error("Unable to send message=[{}] due to: {}", messageData, ex.getMessage());}});}/*** 发送带键的消息*/public void sendMessageWithKey(String key, String message) {CompletableFuture<SendResult<String, Object>> future = kafkaTemplate.send(TOPIC_NAME, key, message);future.whenComplete((result, ex) -> {if (ex == null) {logger.info("Sent message=[{}] with key=[{}] and offset=[{}]",message, key, result.getRecordMetadata().offset());} else {logger.error("Unable to send message=[{}] with key=[{}] due to: {}",message, key, ex.getMessage());}});}
}4.2.3 创建消费者
创建一个服务类,专门用于消费 Kafka 主题中的消息
-
在实际开发中,建议不同的业务使用各自的监听器的类,避免业务重度耦合
package com.congge.utils;import com.congge.kafka.MessageData;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.Acknowledgment;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Service;@Service
public class KafkaConsumerService {private static final Logger logger = LoggerFactory.getLogger(KafkaConsumerService.class);/*** 消费字符串消息*/@KafkaListener(topics = "test-topic", groupId = "consumer-group")public void consumeStringMessage(String message,Acknowledgment acknowledgment,@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,@Header(KafkaHeaders.RECEIVED_PARTITION) int partition,@Header(KafkaHeaders.OFFSET) long offset) {try {logger.info("Received string message: [{}] from topic: {}, partition: {}, offset: {}",message, topic, partition, offset);// 业务处理逻辑processMessage(message);// 手动提交偏移量acknowledgment.acknowledge();logger.info("Acknowledged message from topic: {}, partition: {}, offset: {}",topic, partition, offset);} catch (Exception e) {logger.error("Error processing message: {}", message, e);// 可根据业务需求决定是否重试或将消息发送到DLT(死信主题)}}/*** 消费对象消息(JSON格式)*/@KafkaListener(topics = "example-topic", groupId = "object-consumer-group")public void consumeObjectMessage(MessageData messageData,Acknowledgment acknowledgment,@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,@Header(KafkaHeaders.RECEIVED_PARTITION) int partition,@Header(KafkaHeaders.OFFSET) long offset) {try {logger.info("Received object message: [{}] from topic: {}, partition: {}, offset: {}",messageData, topic, partition, offset);// 业务处理逻辑processObjectMessage(messageData);// 手动提交偏移量acknowledgment.acknowledge();logger.info("Acknowledged message from topic: {}, partition: {}, offset: {}",topic, partition, offset);} catch (Exception e) {logger.error("Error processing message: {}", messageData, e);}}/*** 消费带键的消息*/@KafkaListener(topics = "example-topic", groupId = "key-consumer-group")public void consumeMessageWithKey(ConsumerRecord<String, String> record,Acknowledgment acknowledgment) {try {logger.info("Received message with key: [{}], value: [{}] from topic: {}, partition: {}, offset: {}",record.key(), record.value(), record.topic(), record.partition(), record.offset());// 业务处理逻辑processMessageWithKey(record.key(), record.value());// 手动提交偏移量acknowledgment.acknowledge();logger.info("Acknowledged message with key: [{}] from topic: {}, partition: {}, offset: {}",record.key(), record.topic(), record.partition(), record.offset());} catch (Exception e) {logger.error("Error processing message with key: {}", record.key(), e);}}private void processMessage(String message) {// 实现你的业务逻辑logger.info("Processing message: {}", message);}private void processObjectMessage(MessageData messageData) {// 实现你的业务逻辑logger.info("Processing object message: {}", messageData);}private void processMessageWithKey(String key, String value) {// 根据键处理消息的逻辑logger.info("Processing message with key: {} and value: {}", key, value);}
}4.2.4 增加一个操作topic的工具类
增加一个操作topic的类,用于手动创建topic
package com.congge.kafka;import org.apache.kafka.clients.admin.*;
import org.springframework.kafka.core.KafkaAdmin;
import org.springframework.stereotype.Service;import java.util.Collections;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.ExecutionException;@Service
public class KafkaTopicService {private final AdminClient adminClient;public KafkaTopicService(KafkaAdmin kafkaAdmin) {this.adminClient = AdminClient.create(kafkaAdmin.getConfigurationProperties());}/*** 创建单个Topic*/public void createTopic(String topicName, int partitions, short replicationFactor) {NewTopic newTopic = new NewTopic(topicName, partitions, replicationFactor);createTopic(newTopic);}/*** 创建Topic(使用NewTopic对象)*/public void createTopic(NewTopic newTopic) {CreateTopicsResult result = adminClient.createTopics(Collections.singleton(newTopic));try {result.all().get(); // 等待创建完成} catch (InterruptedException | ExecutionException e) {Thread.currentThread().interrupt();throw new RuntimeException("Failed to create topic: " + newTopic.name(), e);}}/*** 检查Topic是否存在*/public boolean topicExists(String topicName) {try {ListTopicsResult topics = adminClient.listTopics();Set<String> topicNames = topics.names().get();return topicNames.contains(topicName);} catch (InterruptedException | ExecutionException e) {Thread.currentThread().interrupt();throw new RuntimeException("Failed to check topic existence: " + topicName, e);}}/*** 获取Topic详情*/public TopicDescription getTopicDescription(String topicName) {try {Map<String, TopicDescription> descriptions =adminClient.describeTopics(Collections.singleton(topicName)).all().get();return descriptions.get(topicName);} catch (InterruptedException | ExecutionException e) {Thread.currentThread().interrupt();throw new RuntimeException("Failed to get topic description: " + topicName, e);}}/*** 获取所有Topic列表*/public Set<String> listAllTopics() {try {ListTopicsResult topics = adminClient.listTopics();return topics.names().get();} catch (InterruptedException | ExecutionException e) {Thread.currentThread().interrupt();throw new RuntimeException("Failed to list topics", e);}}/*** 安全关闭AdminClient*/public void close() {if (adminClient != null) {adminClient.close();}}
}4.2.5 创建测试接口
为了方便验证效果,这里创建一个接口,通过接口发送消息到kafka的topic中,然后通过监听器到topic中的消息就算成功。参考下面的代码。
package com.congge.kafka;import com.congge.utils.KafkaProducerService;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;@RestController
@RequestMapping("/api/kafka")
public class KafkaController {private final KafkaProducerService kafkaProducerService;private final KafkaTopicService topicService;public KafkaController(KafkaProducerService kafkaProducerService,KafkaTopicService topicService) {this.kafkaProducerService = kafkaProducerService;this.topicService = topicService;}//localhost:8082/api/kafka/send-string?message=test producer@GetMapping("/send-string")public String sendStringMessage(@RequestParam String message) {kafkaProducerService.sendStringMessage(message);return "String message sent: " + message;}//localhost:8082/api/kafka/send-object?id=1&content=test producer@GetMapping("/send-object")public String sendObjectMessage(@RequestParam Long id, @RequestParam String content) {kafkaProducerService.sendObjectMessage(id, content);return "Object message sent with ID: " + id + " and content: " + content;}@GetMapping("/send-with-key")public String sendMessageWithKey(@RequestParam String key, @RequestParam String message) {kafkaProducerService.sendMessageWithKey(key, message);return "Message with key sent: " + key + " - " + message;}/*** 创建Topic* localhost:8082/api/kafka/create-topic?topicName=eva&partitions=1&replicationFactor=2**/@GetMapping("/create-topic")public ResponseEntity<String> createTopic(@RequestParam String topicName,@RequestParam(defaultValue = "1") int partitions,@RequestParam(defaultValue = "1") short replicationFactor) {if (topicService.topicExists(topicName)) {return ResponseEntity.badRequest().body("Topic already exists: " + topicName);}try {topicService.createTopic(topicName, partitions, replicationFactor);return ResponseEntity.ok("Topic created successfully: " + topicName);} catch (Exception e) {return ResponseEntity.internalServerError().body("Failed to create topic: " + e.getMessage());}}
}4.2.6 效果验证
1)创建一个测试使用的topic
如果你已经提前通过命令行工具创建过topic了的话,就不用执行接口创建了,这里创建一个名为zcy-test的topic,调用上面的创建接口

2)发送字符串消息
调用发消息接口,发送成功后

然后在监听器中监听到了,实际业务中,你要处理的业务逻辑就在监听器中进行处理
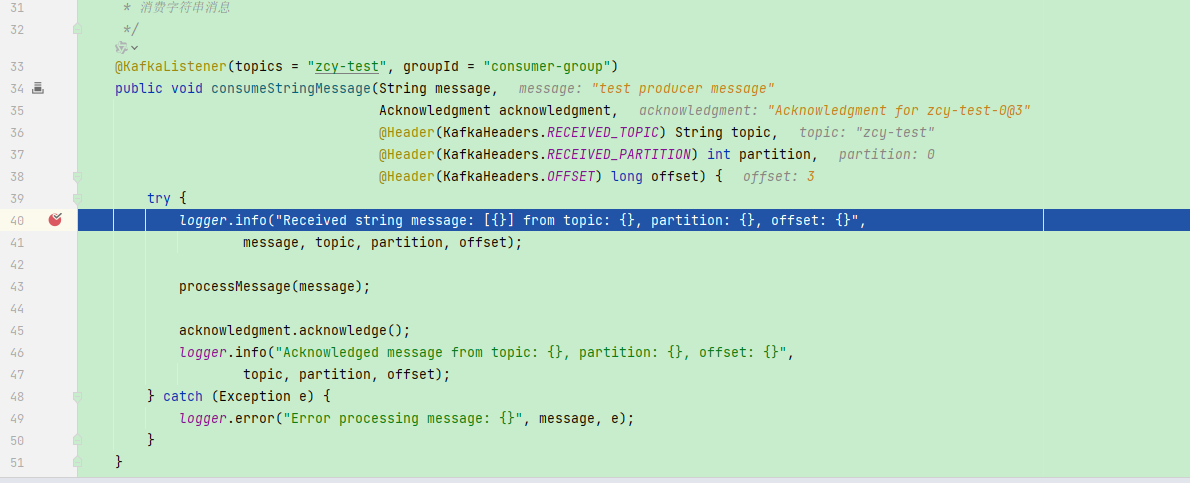
3)发送对象消息
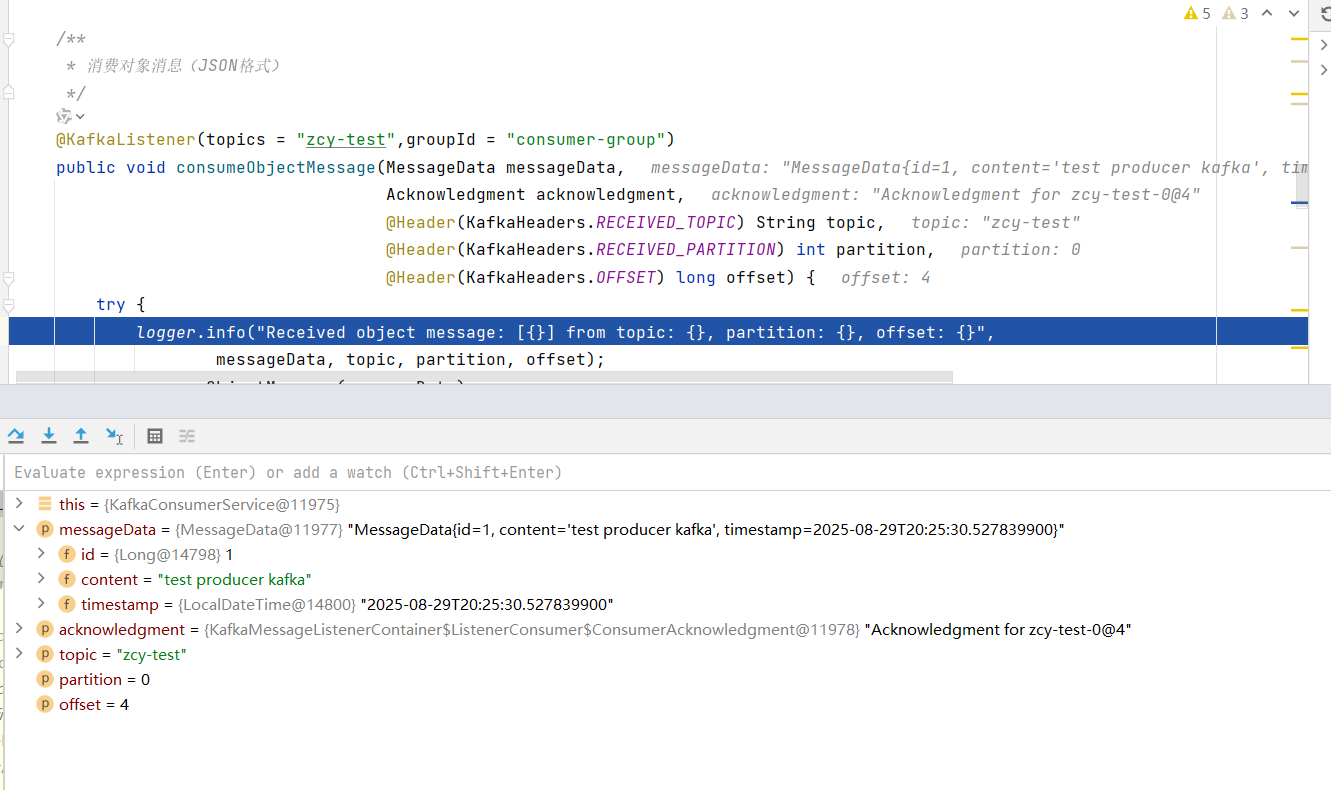
在实际业务中,为了更方便的对消息进行处理,发送对象消息也是很常用的一种方式,参考下面的接口示例

然后在基于对象方式的监听器中就可以看到了
五、写在文末
本文比较详细的介绍了如何在SpringBoot集成和使用Kakfa,并通过案例详细演示了其使用过程,更深入的技术点有兴趣的同学可以基于此继续深入研究,本篇到此结束,感谢观看。
)
)





)

)



)
)




