
【导读】
应对气候变化对非洲象的生存威胁,本研究创新采用无人机航拍结合AI姿态分析技术,突破传统观测局限。团队在肯尼亚桑布鲁保护区对比测试DeepLabCut与YOLO-NAS-Pose两种模型,首次将后者引入野生动物研究。通过检测象群头部、脊柱等关键点(50像素分辨率),YOLO-NAS-Pose在RMSE、PCK、OKS等指标上全面超越实验室常用工具,实现多目标行为动态解析。该技术突破为裂变-融合社会结构的大象群体行为研究提供高精度自动化解决方案,推动无人机生态监测在保护生物学中的应用进程。>>更多资讯可加入CV技术群获取了解哦~

论文题目:
Whole-Herd Elephant Pose Estimation from Drone Data for Collective Behavior Analysis
论文链接:
https://arxiv.org/pdf/2411.00196
目录
一、方法
数据集
千款模型+海量数据,开箱即用!
DeepLabCut工作流程
YOLO-NAS-Pose工作流程
性能评估
无需代码,训练结果即时可见!
从实验到落地,全程高速零代码!
二、实验结果
三、讨论
四、结论
一、方法
-
数据集
本研究采用配备广角摄像头的无人机技术观测象群,确保单帧画面可呈现整个群体。无人机数据采集带来特定挑战。"拯救大象"野外团队在保证数据质量最大化的同时,尽可能减少对大象的干扰以捕捉真实行为。此前研究表明无人机会引发大象不同程度的反应。虽然更高分辨率数据更具优势,但使用多架无人机可能改变大象自然行为。为此,无人机在肯尼亚允许的最高飞行高度(400英尺)进行操作,通过稳定云台平台以29帧/秒、3840×2160分辨率拍摄视频。研究期间无人机固定于设定高度进行俯拍,确保视角统一。在该飞行高度下,视频中幼象从鼻到尾约占8像素,成年象最多占70像素。图1展示了无人机视频的示例帧。

研究重点识别与社交行为相关的关键点,如头部朝向和耳朵扇动等。因此选择图2所示的8个关键点作为姿态估计目标。
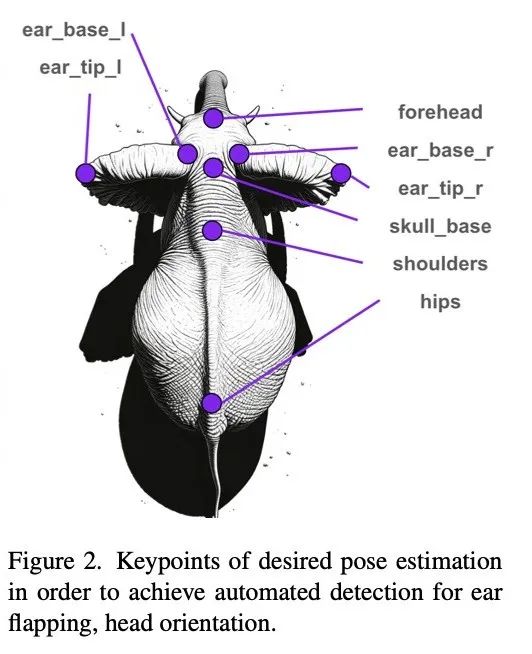
数据集包含23段视频,每段约5分钟时长。从中选取俯拍帧,最终得到包含1308头大象的133帧图像。基于这些帧创建了人工标注的训练数据集,包括边界框和图2定义的关键点。标注时,对特别幼小的象崽若无法辨别耳朵,则仅标注脊柱关键点,耳朵标记为"遮挡"。
标注数据集按90-10-10比例划分为训练集-验证集-测试集。测试集来自完全独立的四段视频,确保与训练集和验证集无视频来源重叠。
-
千款模型+海量数据,开箱即用!
平台汇聚国内外开源社区超1000+热门模型,覆盖YOLO系列、Transformer、ResNet等主流视觉算法。同时集成300+公开数据集,涵盖图像分类、目标检测、语义分割等场景,一键下载即可投入训练,彻底告别“找模型、配环境、改代码”的繁琐流程!

-
预处理
在进入任一工作流程之前,都要对数据进行预处理,以满足 YOLOv5 模型对对象尺寸的要求。标记的视频帧被平铺为 800x800 像素,窗口间距有 33% 的重叠,以确保帧内大象有合适的对象尺寸。然后使用以下两个工作流程对数据进行姿态估计。
-
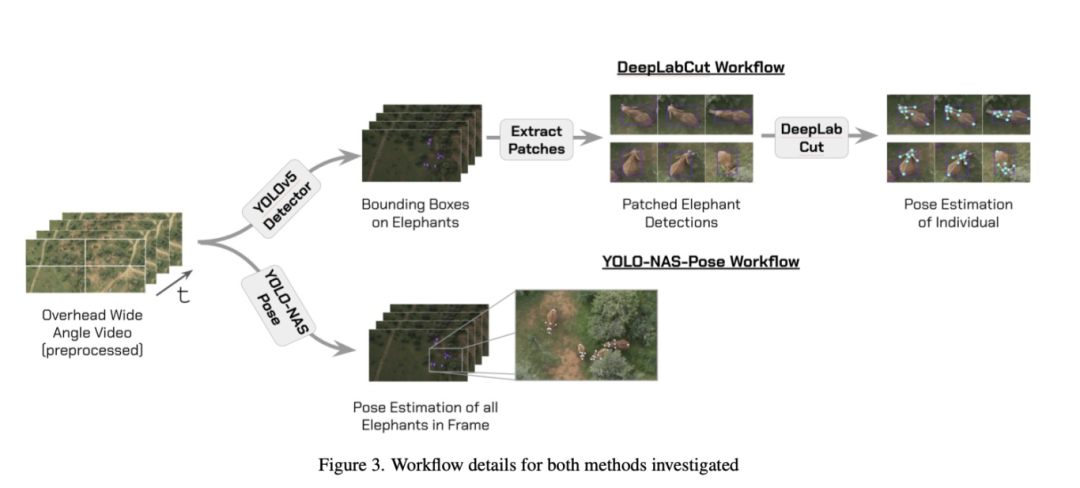
DeepLabCut工作流程
-
大象检测器
首先采用YOLOv5模型和MegaDetector预训练模型对前文定义的数据集进行微调。这些模型被训练用于生成画面中大象的边界框。
当预测出边界框后,以检测框为中心截取正方形图像,其边长取边界框最大尺寸增加20%余量。这些图像块随后被调整为100×100像素。该格式用于训练DeepLabCut,通过提供居中放大的动物图像来消除背景不一致带来的干扰。
-
DeepLabCut
使用姿态数据集训练DeepLabCut模型。数据被转换为DLC训练格式,模型训练80万次迭代直至损失收敛。
-
YOLO-NAS-Pose工作流程
为了训练 YOLO-NAS-Pose 网络,使用了与训练检测器和 DeepLabCut 工作流程相同的数据集,并添加了手动注释的姿势。然后对模型进行训练,以提供整个图像的边界框和姿势。
-
性能评估
采用独立测试集评估两种工作流程。YOLOv5检测器与YOLO-NAS-Pose的边界框准确性通过平均精度均值(mAP)评估。两种工作流程的姿态估计均采用均方根误差(RMSE)、正确关键点百分比(PCK)和物体关键点相似度(OKS)进行评估。为保证公平比较,由于DeepLabCut仅能在提取的边界框上进行姿态估计,评估时仅选取YOLO-NAS-Pose工作流程中正确检测的边界框。
为识别正确检测目标,YOLO-NAS-Pose输出的边界框经非极大值抑制(NMS)处理,最大重叠阈值设为0.5。经过去重的边界框按置信度排序后与真实标注计算交并比(IoU)。当预测框与真实标注框IoU≥0.5时视为候选匹配,若多个预测框对应同一真实框,则选取置信度最高者。
-
可视化视频追踪
虽然连续视频并非训练或定量评估的必要条件,但个体连续影像对定性评估大有助益。通过DeepSORT算法对每帧检测个体生成追踪视频片段。该方法通过比较图像块位置、嵌入特征和物体运动动量来识别视频中的连续目标。由于部分个体分辨率过低,本研究排除边界框小于50像素的幼象,重点分析成年象行为。最终从训练集、验证集和测试集的原始视频中提取25段视频用于姿态估计评估。
如果你也想要使用模型进行训练或改进,Coovally——新一代AI开发平台,为研究者和产业开发者提供极简高效的AI训练与优化体验!Coovally支持计算机视觉全任务类型,包括目标检测、文字识别、实例分割、并且即将推出关键点检测、多模态3D检测、目标追踪等全新任务类型。
-
无需代码,训练结果即时可见!
在Coovally平台上,上传数据集、选择模型、启动训练无需代码操作,训练结果实时可视化,准确率、损失曲线、预测效果一目了然。无需等待,结果即训即看,助你快速验证算法性能!
-
从实验到落地,全程高速零代码!
无论是学术研究还是工业级应用,Coovally均提供云端一体化服务:
-
免环境配置:直接调用预置框架(PyTorch、TensorFlow等);
-
免复杂参数调整:内置自动化训练流程,小白也能轻松上手;
-
高性能算力支持:分布式训练加速,快速产出可用模型;
-
无缝部署:训练完成的模型可直接导出,或通过API接入业务系统。
!!点击下方链接,立即体验Coovally!!
平台链接:https://www.coovally.com
无论你是算法新手还是资深工程师,Coovally以极简操作与强大生态,助你跳过技术鸿沟,专注创新与落地。访问官网,开启你的零代码AI开发之旅!
二、实验结果
在初始工作流程中发现,采用YOLOv5标准预训练权重的检测效果优于megadetector权重。边界框检测器的mAP指标如表1所示。

测试集的各项评估指标结果(包括各关键点及整体平均值)展示在表2。
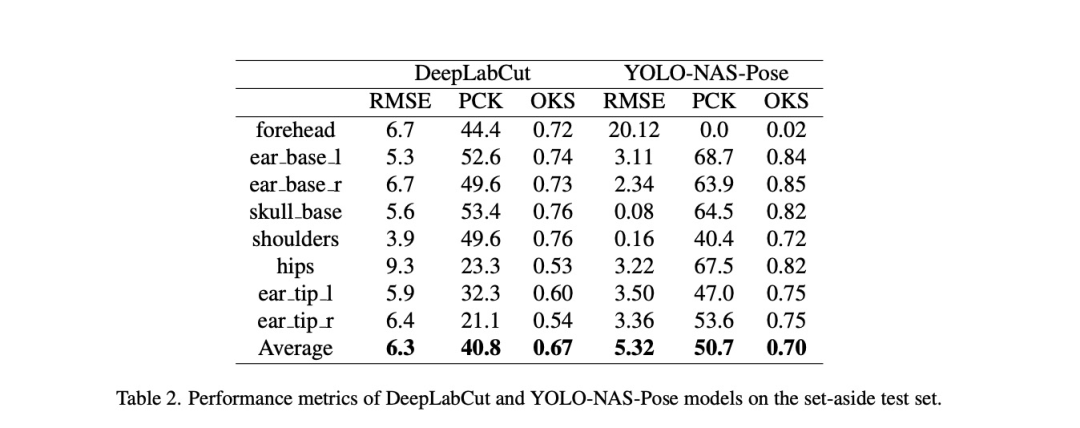
图4展示了DeepLabCut在提取图像块上的应用效果。补充材料包含带有姿态估计叠加的训练验证集追踪视频,既有效果良好的案例,也存在耳部检测不准的情况——虽然脊柱对齐效果稳定,但在快速运动或非常规姿态时耳尖检测容易出现偏差。

图5展示了YOLO-NAS-Pose在单帧视频中的定性结果。整体关键点标注准确,仅漏检一只幼象,但"前额"关键点持续偏置于头部后方。

三、讨论
本研究开创了无人机视频数据自动姿态估计在野生动物研究中的应用。实验结果对野生动物行为监测的改进提供了重要启示。
从表2指标可见,两种模型在测试集均表现合理。YOLO-NAS-Pose在所有指标上均表现良好(虽未达完美),证明其作为野生动物行为研究工具的潜力。但当前精度尚未达到全自动化流程要求,仍需进一步优化。
需注意关键点准确度差异:DeepLabCut耳尖检测精度较低(因其运动范围大且标注置信度最低),但髋部成为最差关键点(可能因缺乏相邻参考点)。这与YOLO-NAS-Pose形成反差——后者髋部表现最佳却在前额关键点遇到困难(可能因象鼻伸展时难以定位面部)。未来将探究这些差异成因。
定性分析显示,DeepLabCut整体表现良好,但存在耳部追踪失败(尤其在幼象上表现为默认"中立"耳姿)。值得注意的是,全帧多象姿态估计与个体图像块估计各有优势:前者简化工作流程利于自动化,后者通过筛选成年象可避免低分辨率幼象的干扰,且能平衡训练集姿态分布。
虽然DeepLabCut未超越YOLO-NAS-Pose,但在小样本场景(约100帧)仍具价值。这对标注数据有限但需快速获取全视频姿态的研究尤为重要。
展望未来,针对低分辨率姿态估计,通过分析视频序列变化检测复杂关键点是重要方向。单帧耳部定位的困难凸显了当前逐帧估计的局限,后续可探索光流或循环神经网络等跨帧分析方法来提升运动连续性检测精度。
四、结论
这项研究通过比较不同的姿态估计技术,在将自动行为分析方法纳入野生动物研究方面取得了重大进展。它为在自然栖息地对野生动物行为进行更复杂的研究铺平了道路,这些研究涉及大范围场景中的多个个体。研究结果表明,YOLO-NAS-Pose 是一种可行且有吸引力的姿态估计方法,它提供了简单明了的工作流程和卓越的性能指标。不过,还需要进一步的开发和改进。这项工作的意义超出了对大象行为的研究,它为未来基于无人机的野生动物行为研究在不同物种和生态环境中的发展提供了宝贵的见解。









)








--Java版)
)