张量的简介
张量是多重线性映射在给定基下的坐标表示,可视为向量和矩阵的泛化。
- 0 维张量:标量(如
5) - 1 维张量:向量(如
[1, 2, 3]) - 2 维张量:矩阵(如
[[1, 2], [3, 4]]) - 3 维及以上张量:多维数组(如图像、视频、时间序列数据)
创建张量的方法
直接从数据创建
x = torch.tensor([5.5, 3]) # 从列表创建
print(x) # tensor([5.5000, 3.0000])![]()
创建了一个包含两个浮点数的一维张量,创建一个形状为 [2] 的张量,包含元素 [5.5, 3.0],数据类型默认为 torch.float32
默认情况下,张量会创建在 CPU 上。若要在 GPU 上运行,需显式指定(如 .to('cuda'))
全0或全1张量
zeros = torch.zeros(4, 3, dtype=torch.long) # 4x3全0矩阵,数据类型为long
ones = torch.ones(2, 2) # 2x2全1矩阵
print(zeros)

zeros 张量:使用 torch.zeros() 创建一个形状为 [4, 3] 的全零矩阵,数据类型指定为 torch.long(即 64 位整数)。
ones 张量:使用 torch.ones() 创建一个形状为 [2, 2] 的全一矩阵,数据类型默认为 torch.float32。
随机初始化张量
rand = torch.rand(4, 3) # 4x3随机矩阵(均匀分布[0,1))
randn = torch.randn(4, 3) # 4x3随机矩阵(标准正态分布)
print(rand)
print(randn)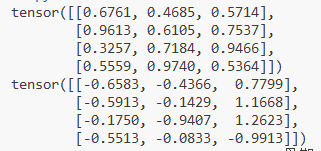
rand 张量:使用 torch.rand(4, 3) 创建一个形状为 [4, 3] 的随机矩阵,元素服从 均匀分布 U(0, 1)(范围从 0 到 1,包含 0 但不包含 1)。
randn 张量:使用 torch.randn(4, 3) 创建一个形状为 [4, 3] 的随机矩阵,元素服从 标准正态分布 N(0, 1)(均值为 0,标准差为 1)。
基于现有张量创建
x = torch.new_ones(4, 3, dtype=torch.double) # 全1矩阵,double类型
y = torch.randn_like(x, dtype=torch.float) # 与x形状相同的随机矩阵,float类型
print(x.size()) # torch.Size([4, 3])
print(y.shape) # 等价于.size()torch.new_ones():创建一个与调用对象(此处为torch)相同类型的全 1 张量。dtype=torch.double指定数据类型为 64 位浮点数(等价于torch.float64)。
torch.randn_like():基于已有张量的形状创建新张量。dtype=torch.float覆盖原始数据类型,生成 32 位浮点数(等价于torch.float32)的随机张量(正态分布)。
报错:
raise AttributeError(f"module '{__name__}' has no attribute '{name}'")
AttributeError: module 'torch' has no attribute 'new_ones'
错误的原因是 torch.new_ones() 并不是 PyTorch 的全局函数,而是 张量对象的方法(即需要通过已有的张量实例调用)。
# 正确写法:通过现有张量调用 new_ones()
# 1. 先创建一个基础张量(用于指定设备和数据类型)
base_tensor = torch.tensor([], dtype=torch.double) # 空张量,仅指定类型
# 2. 基于基础张量创建全1张量
x = base_tensor.new_ones(4, 3) # 形状为 (4, 3),数据类型与 base_tensor 一致(double)
print(x)
print(x.dtype) # 输出:torch.float64(即 double 类型)# 更简洁的等价写法:直接用 torch.ones() 指定形状和类型
x = torch.ones(4, 3, dtype=torch.double) # 效果与上面完全相同
print(x)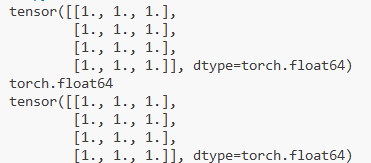
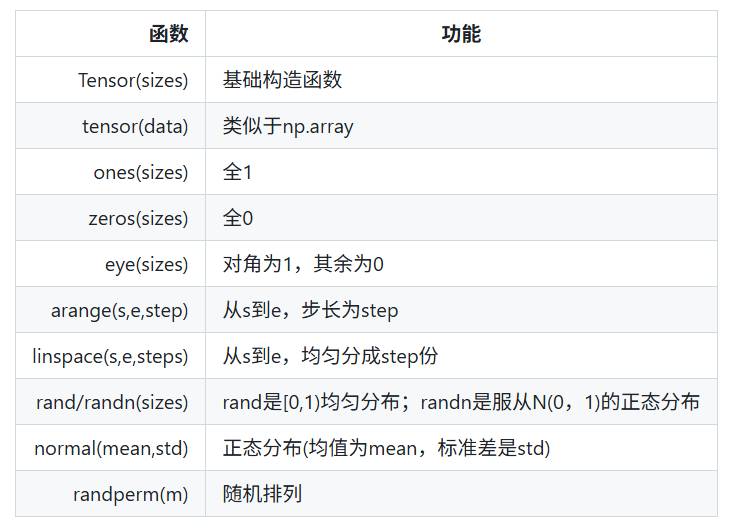
常用函数
torch.Tensor() 基础构造函数
torch.zeros() 全 0 张量
torch.ones() 全 1 张量
torch.rand() 均匀分布随机张量
torch.randn() 正态分布随机张量
torch.arange() 等差数列张量
torch.linspace() 等分数列张量
运算
三种加法
方式一
x = torch.rand(4, 3)
y = torch.rand(4, 3)
print(x + y)方式二
torch.add(x, y)方式三
y.add_(x)
print(y)
减乘除
print(x-y)
print(x*y)
print(x/y)
索引
x[k, :]取第k+1行,因为索引从0开始
x[:,k]取第k+1列
import torch
x = torch.rand(4, 3)
print(x)
print(x[1,:])
print(x[:,1])
另外可以用
x[p,q] = 100来修改特定位置的元素
索引操作返回的是原张量的视图(view),共享内存。如需独立副本,使用 .clone()。
维度变换
y = x.view(16) # 将x展平为1维向量
z = x.view(-1, 8) # -1表示该维度由其他维度推断(16/8=2)view()返回的是原张量的视图(共享内存),不复制数据。-1是动态推断维度的占位符,总元素数必须匹配(4×4=16)
print(x.size(), y.size(), z.size()) # 输出: [4, 4] [16] [2, 8]所有张量共享相同的 16 个元素,只是组织方式不同
# 功能类似view,但可能返回副本
a = x.reshape(2, 8)reshape()是更灵活的操作:若原张量内存连续,返回视图(等价于view());若不连续(如经过转置),会强制复制数据
# 使用clone()创建独立副本后再view
b = x.clone().view(16) x.clone() 创建了一个与 x 具有相同数据但内存独立的新张量。这意味着修改 b 不会影响原始张量 x。
.view(16) 将克隆后的张量调整为一维向量(长度为 16)。由于 clone() 返回的是连续内存的张量,view() 可以直接操作而无需额外复制。
import torch
x=torch.rand(4,3)
print(x)
y=x.view(12)
z=x.view(-1,2)
print(x.size(),y.size(),z.size())输出:

import torch
x=torch.rand(4,3)
print(x)
a=x.reshape(2,6)
print(a)
b=x.clone().view(12)
print(b)输出:

取值操作
x = torch.randn(1)
print(x) # tensor([-0.3456])
print(x.item()) # -0.3456234779701233(转为Python标量)广播机制
当对两个张量执行运算时,PyTorch 会按以下规则自动处理形状差异:
维度对齐:将维度较少的张量左侧补 1,使两者维度数相同。
例:a.shape = (2, 3, 4),b.shape = (3, 1) → 补全后 b.shape = (1, 3, 1)。
维度兼容性检查:对每个维度,若大小不同,则其中必须有一个为 1,否则广播失败。
兼容示例:(3, 1) 和 (1, 4) → 可广播为 (3, 4)。
不兼容示例:(2, 3) 和 (2, 4) → 最后一维 3≠4 且均不为 1,广播失败。
维度扩展:将维度为 1 的轴扩展到与另一张量对应维度相同的大小(实际计算中不复制数据,仅逻辑扩展)。
例:a.shape = (3, 4) 与补全后的 b.shape = (1, 4) → 广播后均为 (3, 4)。
当两个形状不同的张量进行运算时,PyTorch 会自动触发广播机制
import torcha = torch.tensor([1, 2, 3]) # shape: (3,)
b = torch.tensor(5) # shape: ()result = a + b
print(result) # tensor([6, 7, 8])a = torch.randn(2, 3) # shape: (2, 3)
b = torch.randn(3) # shape: (3,)result = a + b
print(result.shape) # torch.Size([2, 3])a = torch.randn(2, 1, 3) # shape: (2, 1, 3)
b = torch.randn(1, 3) # shape: (1, 3)result = a + b
print(result.shape) # torch.Size([2, 1, 3])a = torch.randn(2, 3) # shape: (2, 3)
b = torch.randn(2, 4) # shape: (2, 4)# 会报错
try:result = a + b
except RuntimeError as e:print(e)
# 输出: The size of tensor a (3) must match the size of tensor b (4) at non-singleton dimension 1a = torch.randn(1, 2, 1) # shape: (1, 2, 1)
b = torch.randn(3, 1, 4) # shape: (3, 1, 4)result = a + b
print(result.shape) # torch.Size([3, 2, 4])所有维度都会尝试广播:
第 0 维:1 vs 3 → 扩展为 3
第 1 维:2 vs 1 → 扩展为 2
第 2 维:1 vs 4 → 扩展为 4
结果形状为 (3, 2, 4)
a = torch.arange(1, 3).view(1, 2) # tensor([[1, 2]])
b = torch.arange(1, 4).view(3, 1) # tensor([[1], [2], [3]])
print(a + b)torch.arange()创建一个一维张量,包含从 start 到 end - 1(左闭右开)的等差数列。
torch.arange(start=0, end, step=1, dtype=None, device=None, requires_grad=False)start:起始值(默认为 0)
end:结束值(不包含)
step:步长(默认为 1)
dtype:数据类型(如 torch.int, torch.float 等)
b = torch.arange(1, 4) # start=1, end=4 → [1, 2, 3]
# tensor([1, 2, 3])a = torch.arange(1, 3).view(1, 2) # shape: (1, 2)
b = torch.arange(1, 4).view(3, 1) # shape: (3, 1)print(a + b)a = [[1, 2]] # shape (1, 2)
b = [[1],[2],[3]] # shape (3, 1)# 广播后:
a = [[1, 2],[1, 2],[1, 2]] # shape (3, 2)b = [[1, 1],[2, 2],[3, 3]] # shape (3, 2)# 相加:
result = [[2, 3],[3, 4],[4, 5]]广播机制 不会复制数据,而是通过“虚拟扩展”(broadcast)的方式,让不同形状的张量看起来像是相同形状,从而进行逐元素操作。这在内存和性能上都非常高效。
张量与 NumPy 的交互
import numpy as np# NumPy数组转PyTorch张量
a = np.array([1, 2, 3])
b = torch.from_numpy(a) # 共享内存
print(b) # tensor([1, 2, 3], dtype=torch.int32)# PyTorch张量转NumPy数组
c = torch.rand(3)
d = c.numpy() # 共享内存
print(d) # [0.1234 0.5678 0.9012]# 修改其中一个会影响另一个(因为共享内存)
a[0] = 100
print(b) # tensor([100, 2, 3], dtype=torch.int32)a = np.array([1, 2, 3])
b = torch.from_numpy(a) torch.from_numpy() 的作用:这是 将 NumPy 数组转换为 PyTorch 张量 的函数。
关键点:共享内存!也就是说,b 和 a 指向的是同一块内存区域。
如果修改 a,b 也会变;反之亦然。
print(b) # tensor([1, 2, 3], dtype=torch.int32)输出张量 b,其数据类型是 torch.int32,对应于 NumPy 的 np.int32 或 np.int64(根据系统)。
PyTorch 会根据 NumPy 数组的 dtype 自动推断张量的 dtype。
d = c.numpy().numpy() 的作用:.numpy() 是 PyTorch 张量的方法,用于将其转换为 NumPy 数组。
同样,共享内存!即 c 和 d 指向的是同一块内存空间。
自动求梯度(Autograd)
x = torch.tensor([2.0], requires_grad=True) torch.tensor([2.0]):创建一个包含单个元素的张量 x = 2.0。
requires_grad=True:告诉 PyTorch 需要为这个张量记录梯度。只有设置了这个参数的张量,才会在反向传播时计算梯度。默认情况下,requires_grad=False,即不记录梯度。
# 定义函数 y = x^2
y = x**2这里我们定义了一个函数 y = x^2。y 是一个张量,它是由 x 经过计算得到的。PyTorch 会自动记录这个计算过程,构建一个 计算图(computation graph),以便后续进行反向传播。
# 反向传播计算梯度
y.backward() # 等价于 y.backward(torch.tensor(1.0))y.backward():触发反向传播,计算 y 对所有需要梯度的输入张量(比如 x)的梯度。
因为 y 是一个标量(只有一个元素),所以不需要传入参数。
如果 y 是一个向量或更高维的张量,则需要传入一个与 y 同形状的 梯度向量,作为链式法则中的“上游梯度”。
y.backward() 等价于 y.backward(torch.tensor(1.0)),因为 PyTorch 默认对标量调用 .backward() 时使用 1.0 作为梯度。
# 查看梯度 dy/dx = 2x = 2*2 = 4
print(x.grad) # tensor([4.])x.grad:这是 x 的梯度,也就是 dy/dx。因为 y = x^2,所以 dy/dx = 2x。当 x = 2 时,dy/dx = 4。所以输出为:tensor([4.])。
# 1. 定义模型参数
w = torch.randn(1, requires_grad=True)
b = torch.randn(1, requires_grad=True)# 2. 输入数据
x = torch.tensor([2.0])# 3. 前向传播
y_pred = w * x + b# 4. 定义目标值和损失函数
y_true = torch.tensor([5.0])
loss = (y_pred - y_true)**2# 5. 反向传播
loss.backward()# 6. 查看梯度
print("w.grad:", w.grad)
print("b.grad:", b.grad)参考文章
thorough-pytorch/source/第二章/2.1 张量.md at main · datawhalechina/thorough-pytorch![]() https://github.com/datawhalechina/thorough-pytorch/blob/main/source/%E7%AC%AC%E4%BA%8C%E7%AB%A0/2.1%20%E5%BC%A0%E9%87%8F.md
https://github.com/datawhalechina/thorough-pytorch/blob/main/source/%E7%AC%AC%E4%BA%8C%E7%AB%A0/2.1%20%E5%BC%A0%E9%87%8F.md


)


中最常用的命令汇总和实战示例)
)






)


)

)
