写在前面
本系列推文为《R for Data Science (2)》的中文翻译版本。所有内容都通过开源免费的方式上传至Github,欢迎大家参与贡献,详细信息见:
Books-zh-cn 项目介绍:
Books-zh-cn:开源免费的中文书籍社区
r4ds-zh-cn Github 地址:
https://github.com/Books-zh-cn/r4ds-zh-cn
r4ds-zh-cn 网站地址:
https://books-zh-cn.github.io/r4ds-zh-cn/
目录
-
1.4 可视化分布图
-
1.5 可视化关系图
-
1.6 保存你的绘图
-
1.7 常见问题
-
1.8 总结
1.4 可视化分布图
可视化变量的分布方式取决于变量的类型:分类变量或数值变量。
1.4.1 一个分类变量
如果一个变量只能取一小组值中的一个,则该变量是分类变量(categorical)。要检查分类变量的分布情况,可以使用条形图。条形图的高度显示了每个 x 值出现的观测次数。
ggplot(penguins, aes(x = species)) +geom_bar()
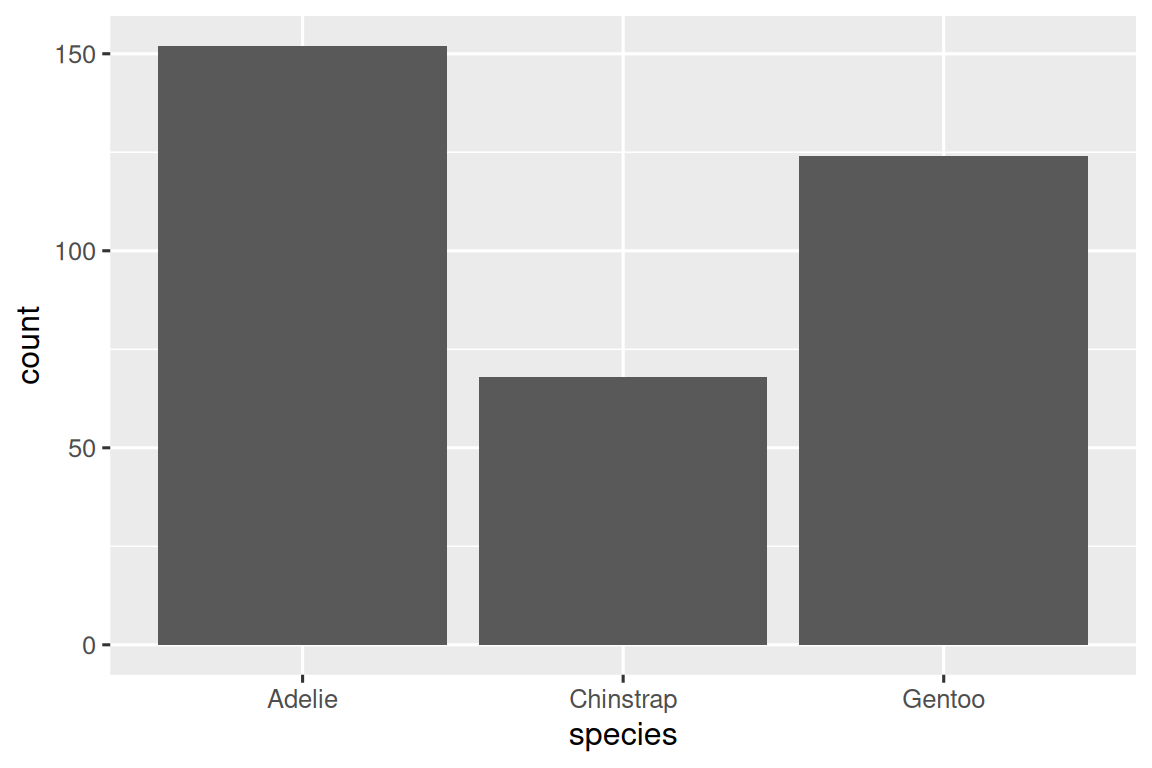
在具有无序级别的分类变量的条形图中,例如上面的企鹅物种(species),通常最好根据它们的频率重新排序条形。为此,需要将变量转换为因子(factor)(R 如何处理分类数据),然后重新排序该因子的级别(levels)。
ggplot(penguins, aes(x = fct_infreq(species))) +geom_bar()
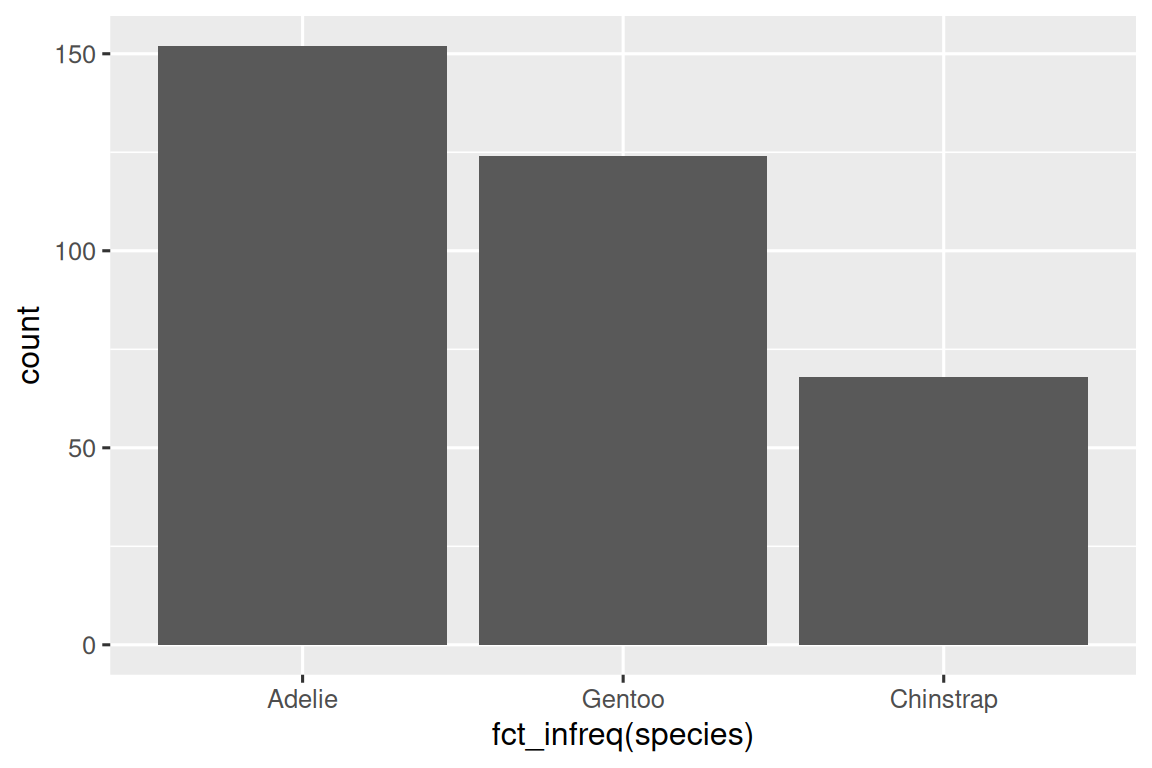
您将在 Chapter 16 中进一步了解有关因子(factors)和处理因子的函数(如上面所示的 fct_infreq())的知识。
1.4.2 一个数值变量
如果一个变量可以取一系列广泛的数值,并且可以对这些数值进行加减或求平均,那么该变量就是数值变量(numerical)。数值变量可以是连续的(continuous)或离散的(discrete)。
直方图(histogram)是一种常用的连续变量分布可视化方法。
ggplot(penguins, aes(x = body_mass_g)) +geom_histogram(binwidth = 200)
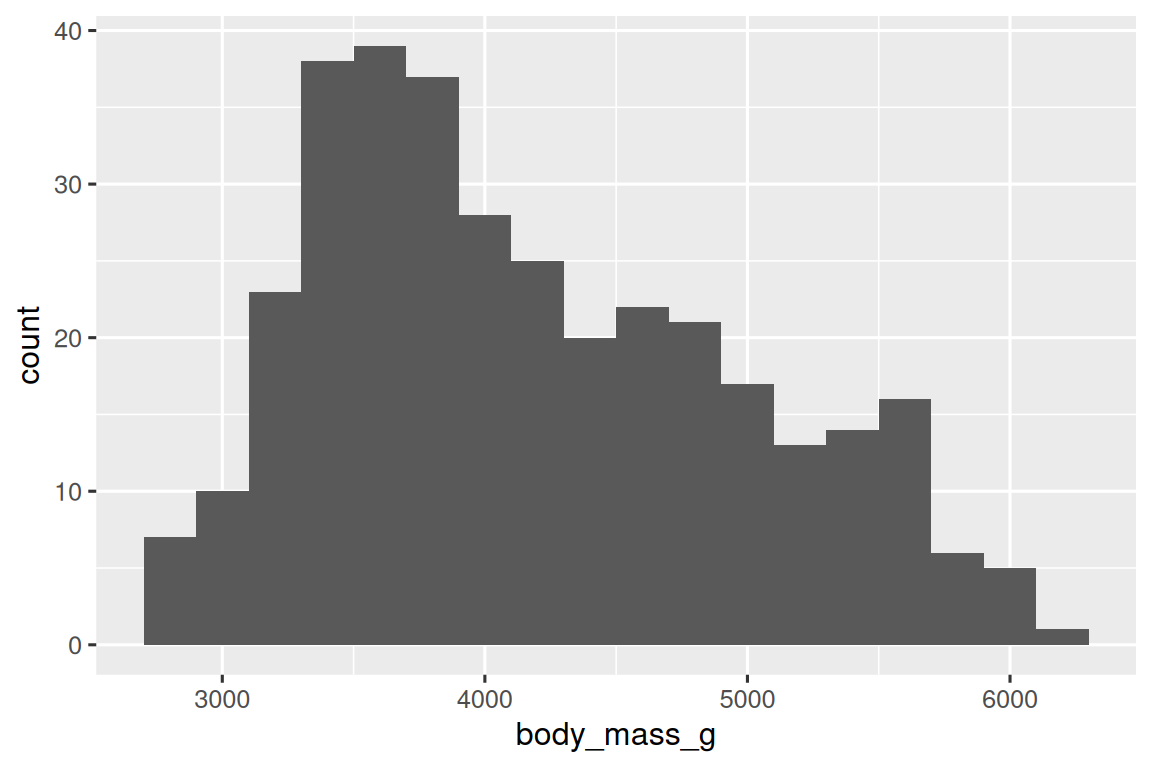
直方图将 x-axis 均匀地分成多个区间(bins),并使用条的高度显示落入每个区间的观测次数。在上面的图中,最高的条表示有 39 个观测值的 body_mass_g 值介于 3,500 到 3,700 克之间,这个区间是条的左右边缘。
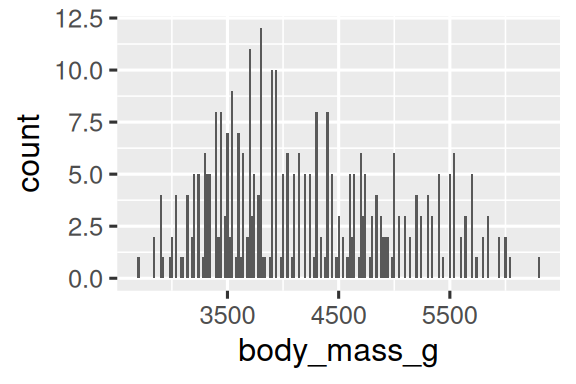
您可以使用 binwidth 参数设置直方图中的区间宽度,该参数以 x 变量的单位进行测量。在使用直方图时,应该尝试不同的区间宽度,因为不同的区间宽度可以展现不同的模式。在下面的图中,区间宽度为 20 太窄了,导致有太多的条,使得难以确定分布的形状。类似地,区间宽度为 2,000 太大了,导致所有的数据都被分到了只有三个条中,也难以确定分布的形状。区间宽度为 200 提供了一个合理的平衡点。
ggplot(penguins, aes(x = body_mass_g)) +geom_histogram(binwidth = 20)
ggplot(penguins, aes(x = body_mass_g)) +geom_histogram(binwidth = 2000)
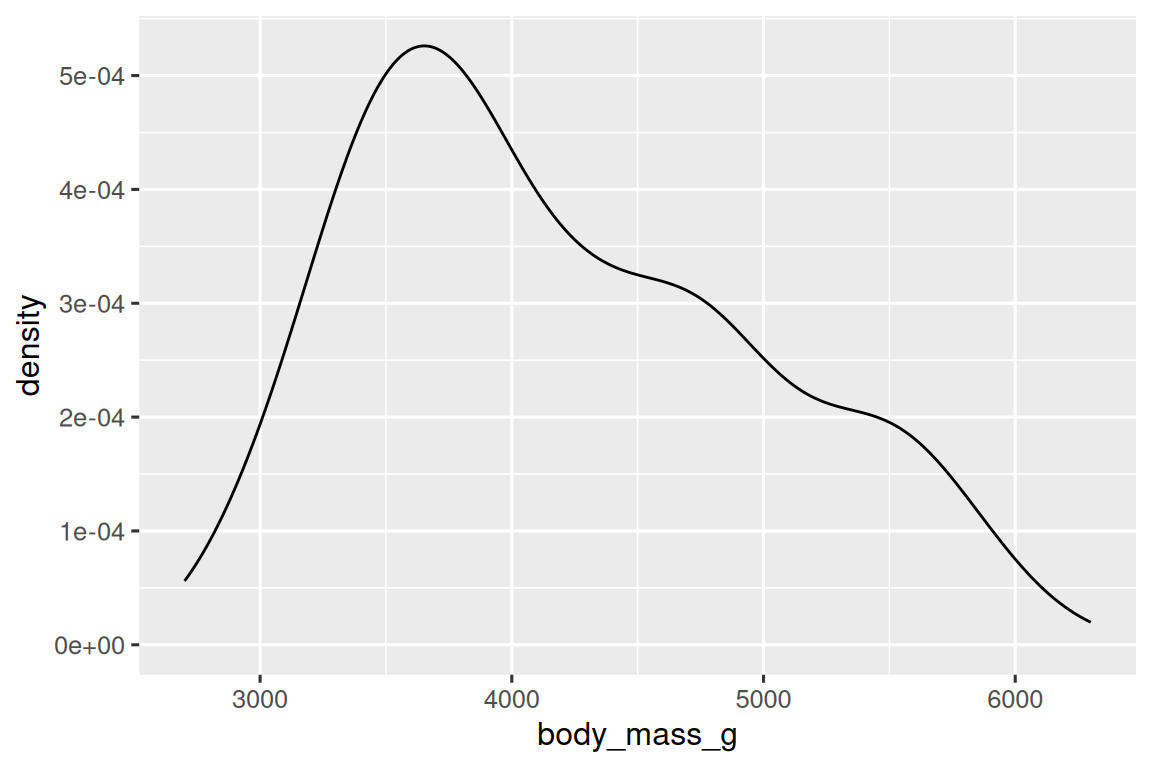
一种用于可视化数值变量分布的替代方法是密度图(density plot)。密度图是直方图的平滑版本,特别适用于连续数据,这些数据来自于一个平滑分布。我们不会详细讨论 geom_density() 如何估计密度(您可以在函数文档中相关信息),但我们可以通过类比来解释绘制密度曲线的过程。想象一个由木块组成的直方图。然后,想象一根煮熟的意大利面条放在上面。面条垂挂在木块上的形状可以被视为密度曲线的形状。它展示的细节比直方图少,但可以更容易地快速了解分布的形状,特别是关于峰值和偏斜度方面的特征。
ggplot(penguins, aes(x = body_mass_g)) +geom_density()
#> Warning: Removed 2 rows containing non-finite outside the scale range
#> (`stat_density()`).
1.4.3 练习
-
创建一个关于
penguins数据集中的species变量的条形图(bar plot),将species分配给yaesthetic。这个图与之前的图有何不同? -
下面两个图形有何不同?
color和fill这两个美学映射中,哪一个更适合改变条形图的颜色?
ggplot(penguins, aes(x = species)) +geom_bar(color = "red")ggplot(penguins, aes(x = species)) +geom_bar(fill = "red")
-
geom_histogram()中的bins参数有什么作用? -
在加载 tidyverse 包时,可以使用
diamonds数据集中的carat变量创建一个直方图(histogram)。尝试使用不同的区间宽度(binwidths)来观察结果。哪个区间宽度(binwidths)可以显示出最有趣的模式?
1.5 可视化关系图
要可视化一个关系(relationship),我们至少需要将两个变量映射到绘图的 aesthetics 中。在接下来的章节中,您将学习常用的用于可视化两个或多个变量之间关系的图表以及用于创建这些图表的几何对象(geoms)。
1.5.1 一个数值和一个分类变量
要可视化数值变量和分类变量之间的关系,我们可以使用并列箱线图。箱线图(boxplot)是一种用于描述分布位置(百分位数)的视觉工具。它还可以用于识别潜在的异常值(outliers)。如 Figure 1.1 所示,每个箱线图由以下几部分组成:
-
一个 box,用于表示数据的中间一半的范围,也就是四分位距(IQR),从分布的第 25 个百分位数延伸到第 75 个百分位数。box 的中间有一条线,显示分布的中位数,即第 50 个百分位数。这三条线可以让您了解分布的扩展程度以及分布是否关于中位数对称或倾斜于一侧。
-
用于显示位于 box 边缘 1.5 倍 IQR 之外的观测值的可视化点。这些异常点是不寻常的,因此会单独绘制出来。
-
从 box 的每一端延伸出一条线(或者称为 whisker),并延伸到分布中最远的非异常点。
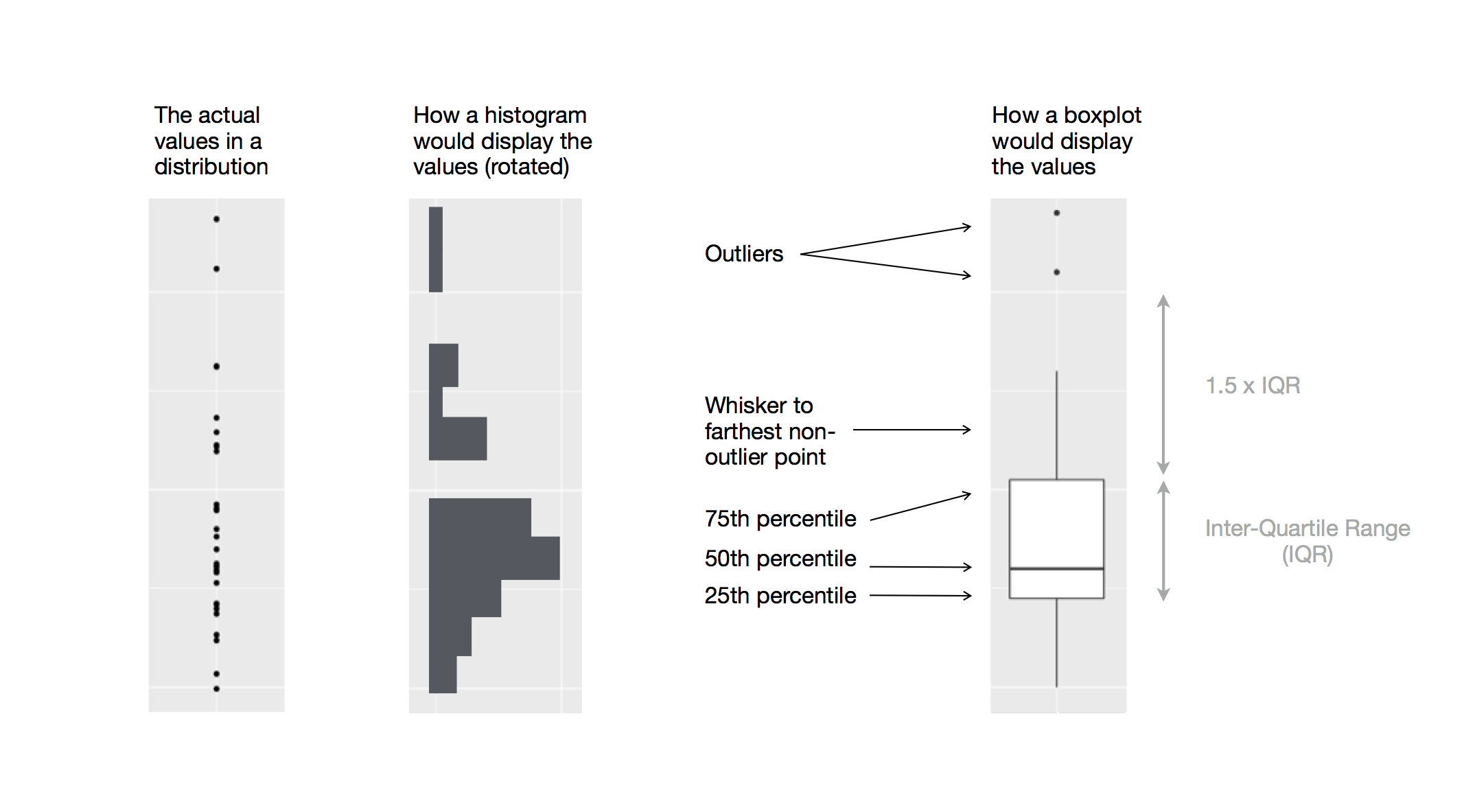
Figure 1.1: 图表描绘了如何创建箱线图。
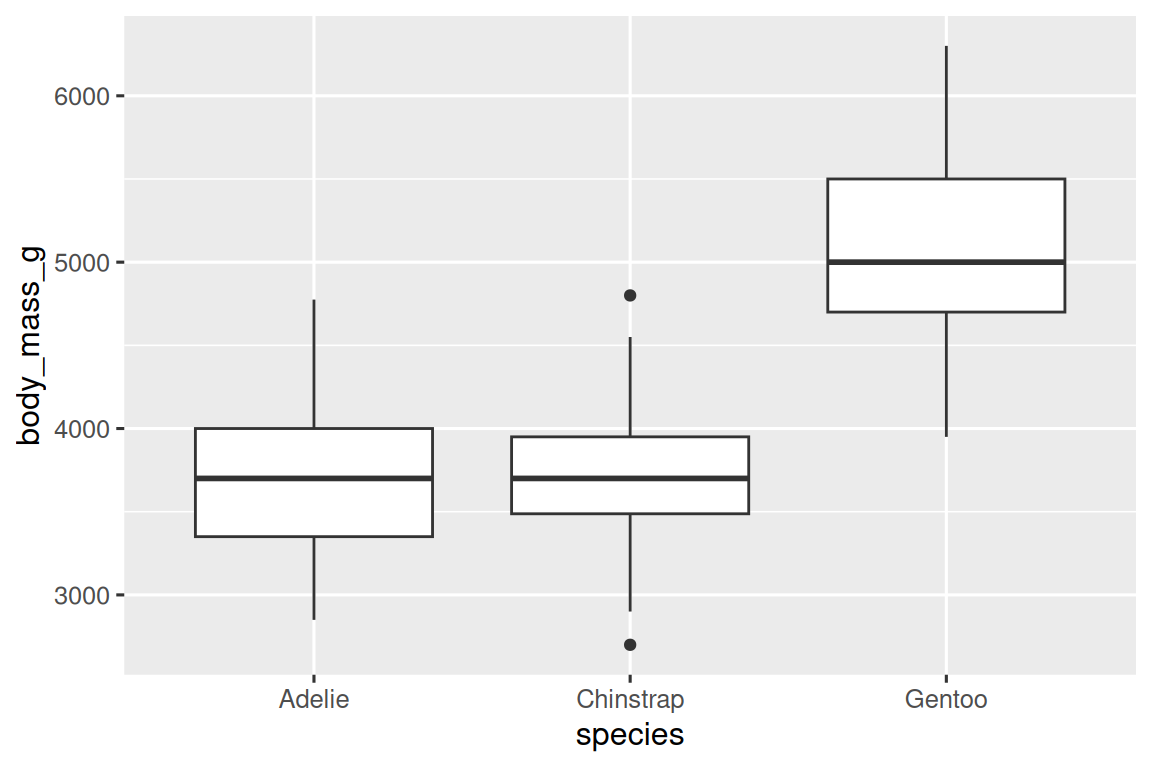
让我们使用 geom_boxplot() 来查看不同物种(species)的体重(body mass)分布:
ggplot(penguins, aes(x = species, y = body_mass_g)) +geom_boxplot()
或者,我们可以使用 geom_density() 创建密度图(density plots)。
ggplot(penguins, aes(x = body_mass_g, color = species)) +geom_density(linewidth = 0.75)
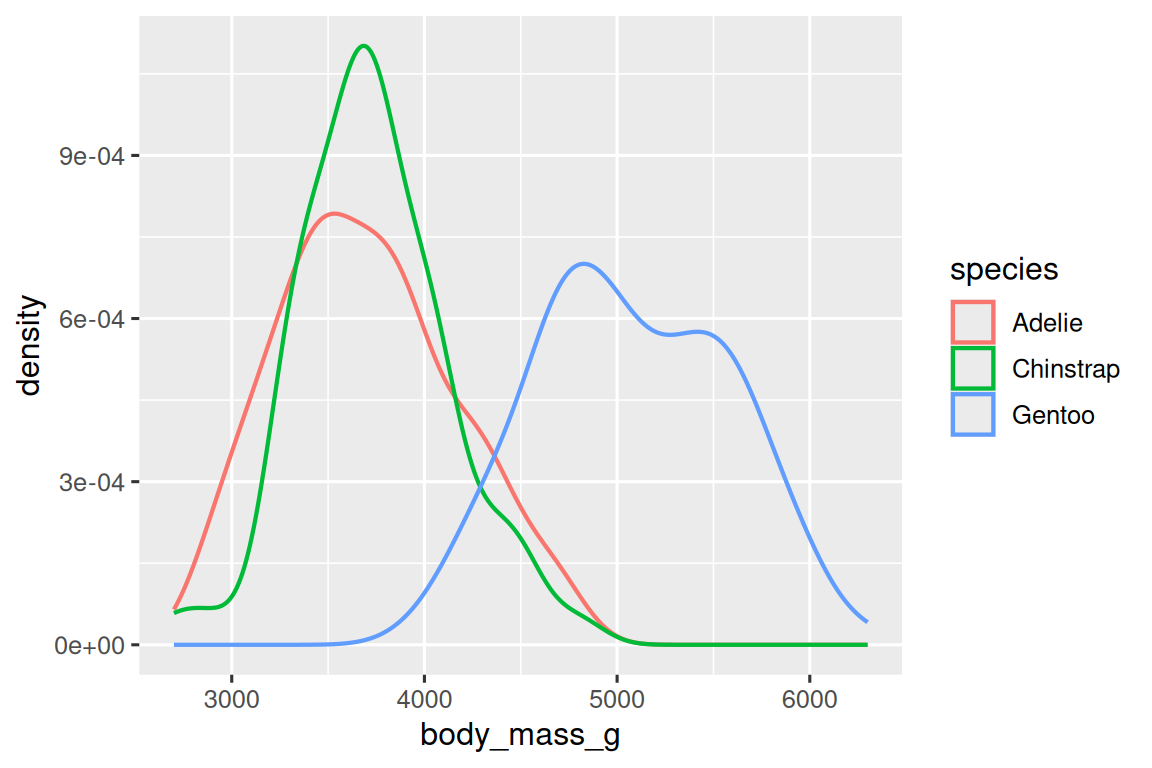
我们还使用 linewidth 参数自定义了线条的粗细,以使其在背景中更加突出。
此外,我们可以将 species 映射到 color 和 fill aesthetics,并使用 alpha aesthetic 为填充的密度曲线添加透明度。这个 aesthetic 的取值范围在 0(完全透明)和 1(完全不透明)之间。 在下面的图中,它被设置为 0.5。
ggplot(penguins, aes(x = body_mass_g, color = species, fill = species)) +geom_density(alpha = 0.5)
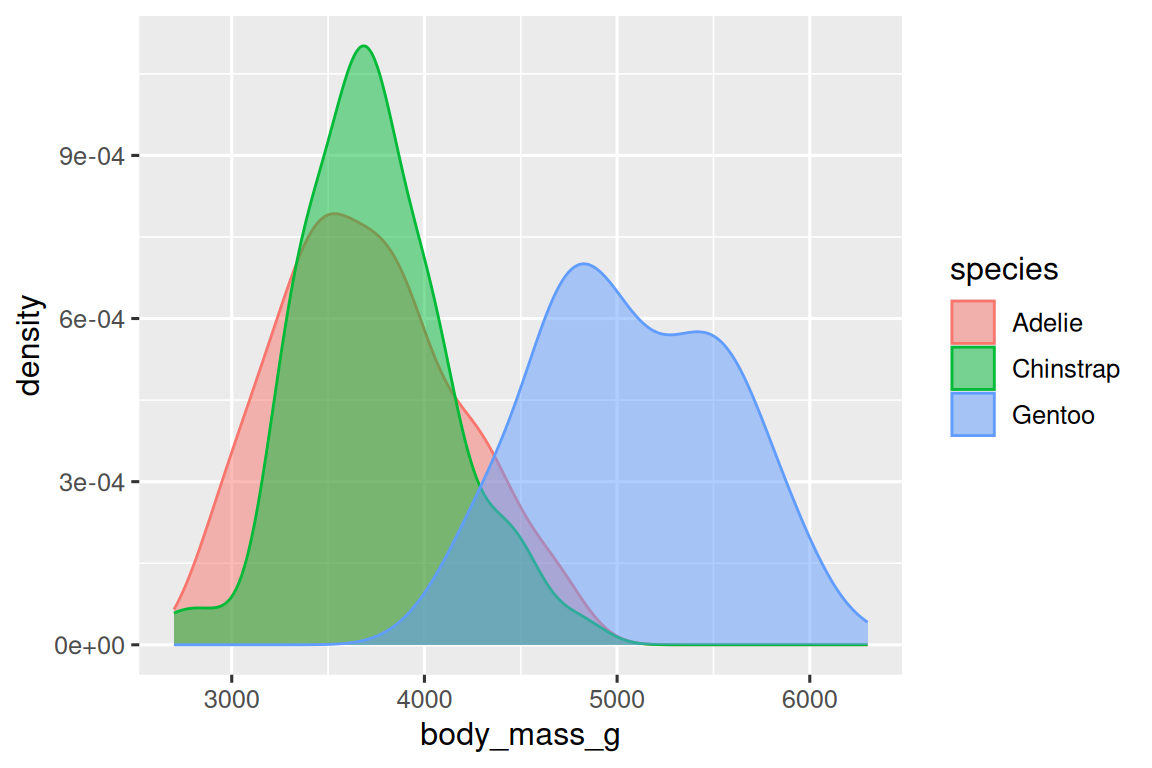
请注意我们在这里使用的术语:
-
如果我们希望由变量的值决定该美学属性的视觉特征的变化,我们会将变量映射(map)到美学属性。
-
否则,我们会设置(set)美学属性的值。
1.5.2 两个分类变量
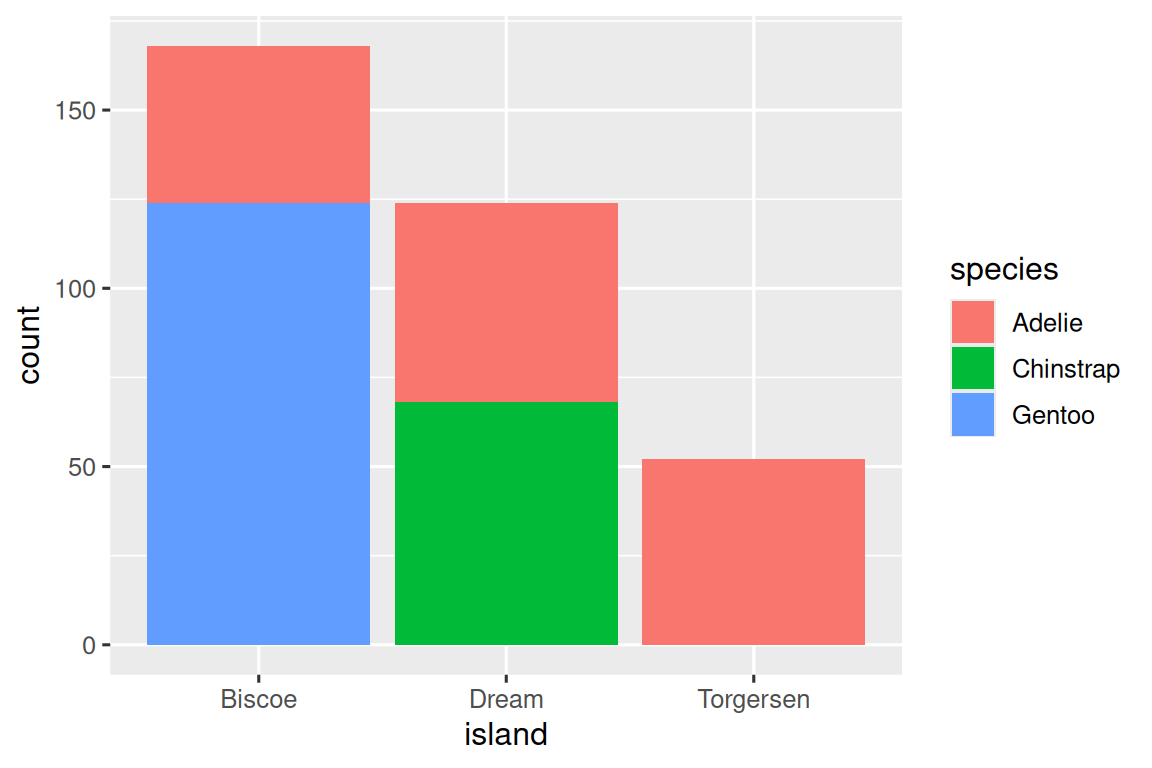
我们可以使用堆叠条形图(stacked bar plots)来可视化两个分类变量之间的关系。例如,以下两个堆叠条形图都显示了 island 和 species 之间的关系,具体而言,可视化了每个岛上 species 的分布。
第一个图显示了每个岛上各种企鹅物种的频率。频率图显示在每个岛上,Adelie 的数量是相等的。但我们无法很好地了解每个岛内的百分比分布情况。
ggplot(penguins, aes(x = island, fill = species)) +geom_bar()
第二个图是一个相对频率图,通过在 geom 中设置 position = "fill" 创建,它对比较跨岛屿的物种分布更有用,因为它不受岛屿上企鹅数量不均衡的影响。使用这个图表,我们可以看到 Gentoo 企鹅全部生活在 Biscoe 岛上,并占该岛企鹅总数的大约 75%,Chinstrap 企鹅全部生活在 Dream 岛上,并占该岛企鹅总数的大约 50%,而 Adelie 企鹅分布在所有三个岛屿上,并占据 Torgersen 岛上所有的企鹅。
ggplot(penguins, aes(x = island, fill = species)) +geom_bar(position = "fill")
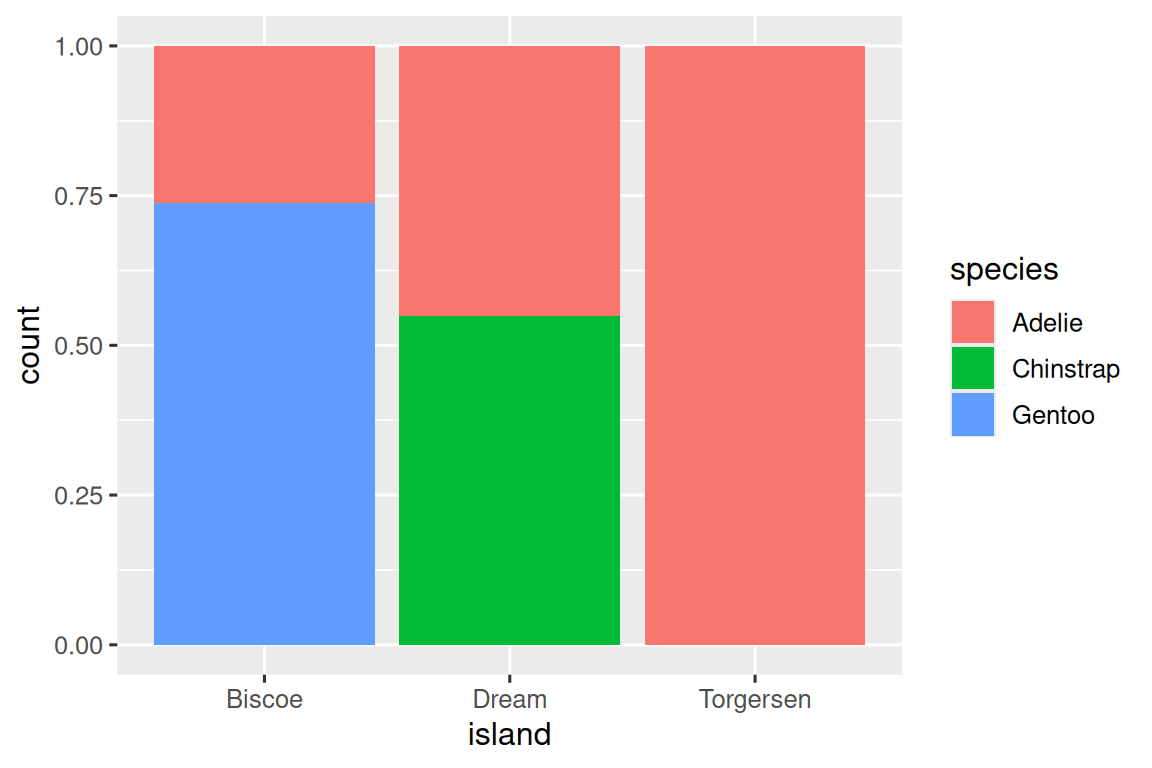
在创建这些条形图时,我们将要分隔成条的变量映射到 x aesthetic,将用于改变条内颜色的变量映射到 fill aesthetic。
1.5.3 两个数值变量
到目前为止,你已经学习了使用 geom_point() 创建散点图和使用 geom_smooth() 创建平滑曲线来可视化两个数值变量之间的关系。散点图可能是最常用的用于可视化两个数值变量之间关系的图表之一。
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +geom_point()
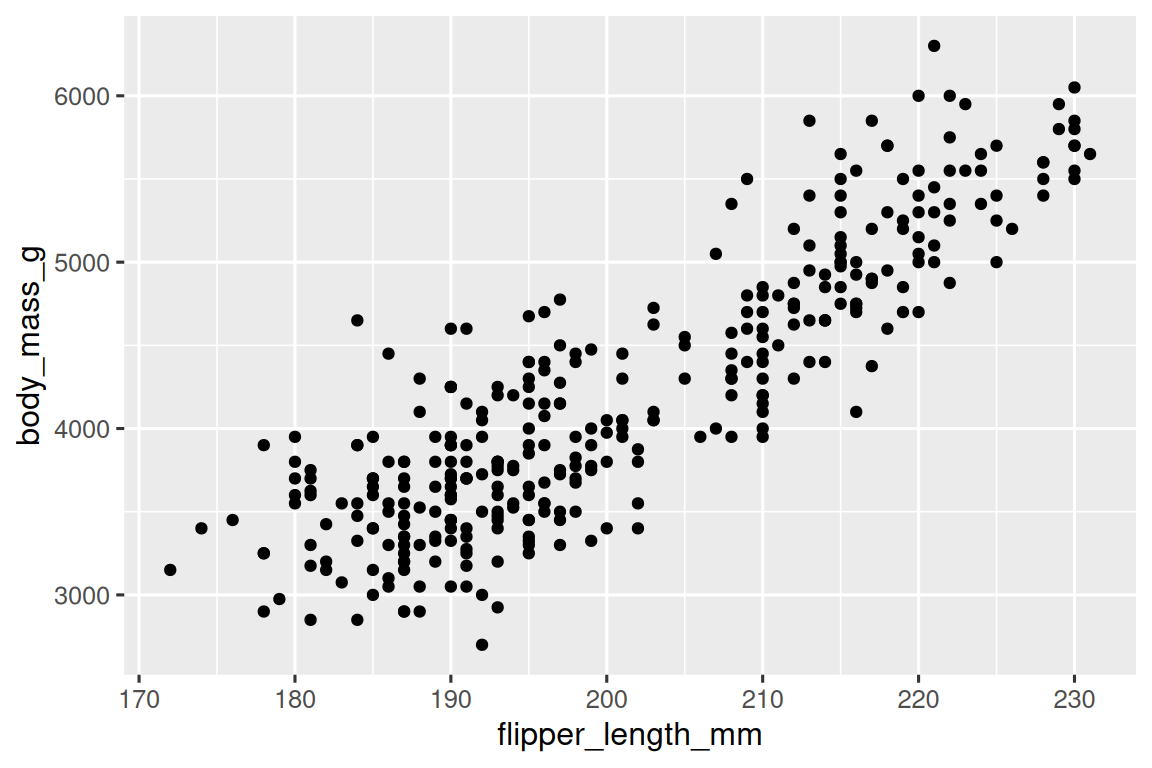
1.5.4 三个或更多变量
正如我们在 Section 1.2.4 中所看到的,我们可以通过将它们 mapping 到其他 aesthetics 来将更多变量融入到图表中。例如,在下面的散点图中,点的颜色代表物种(species),点的形状代表岛屿(islands)。
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +geom_point(aes(color = species, shape = island))
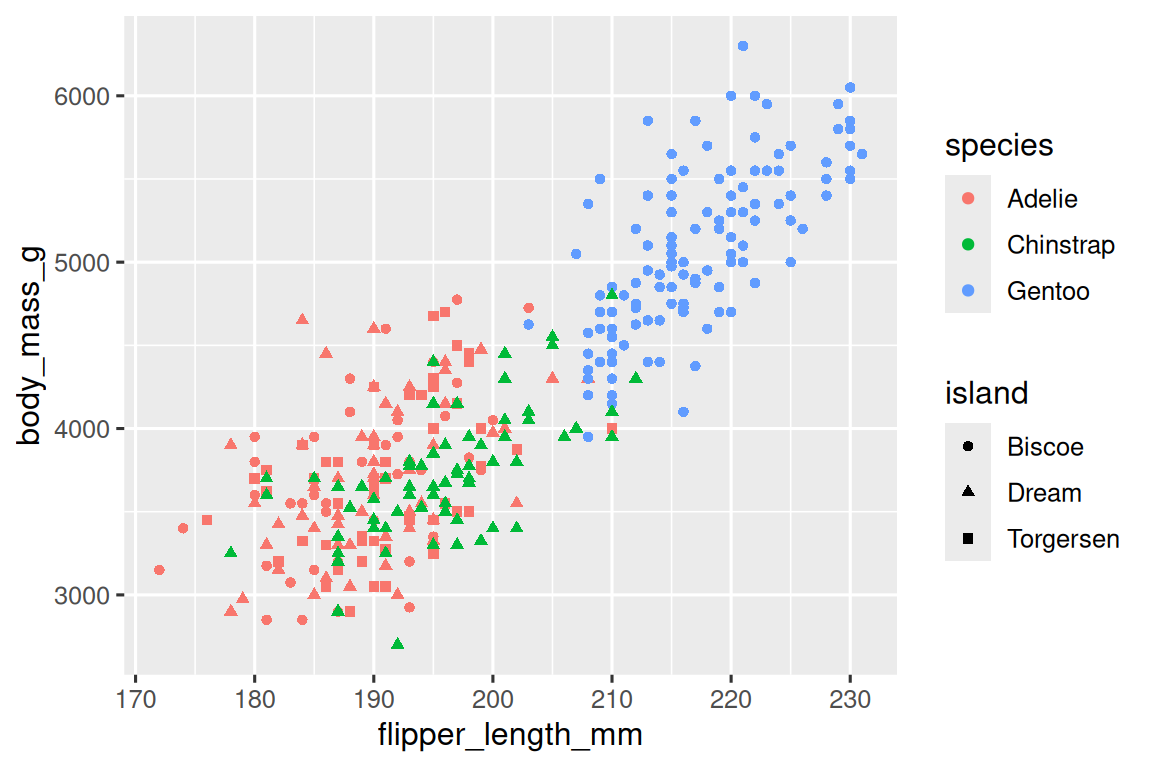
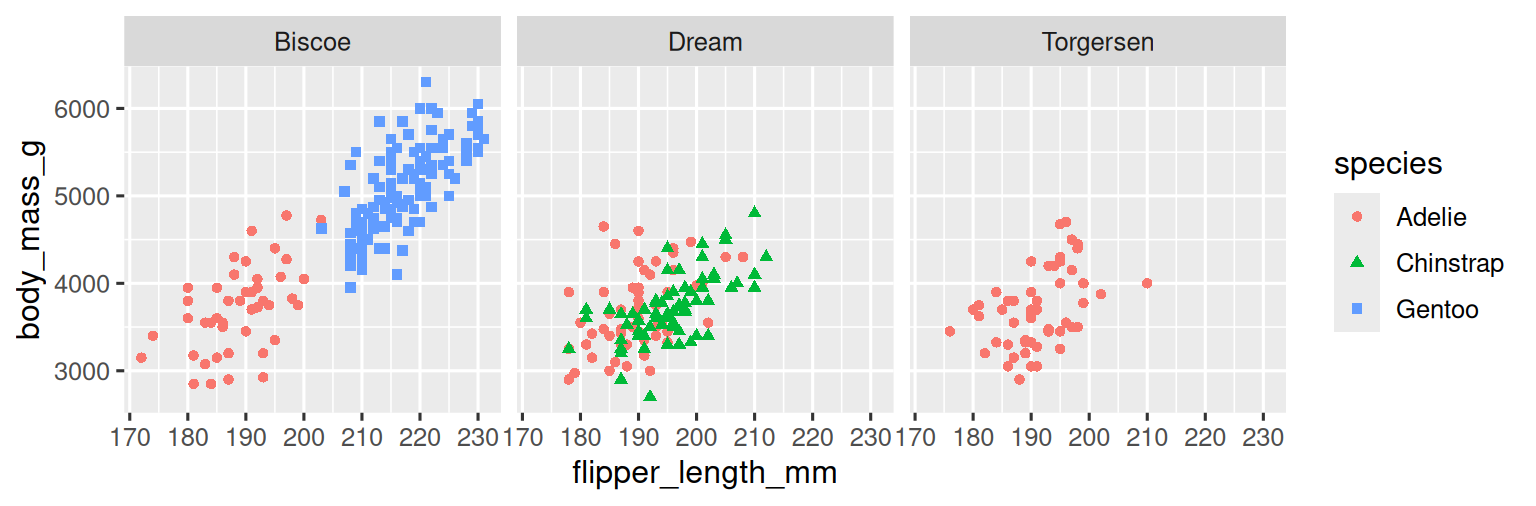
然而,如果将过多的 aesthetic mappings 添加到图表中,会使其变得杂乱且难以理解。另一种方法,特别适用于分类变量,是将图表分割为面板(facets),每个面板显示数据的一个子集。
要通过单个变量进行面板化,可以使用 facet_wrap() 函数。facet_wrap() 的第一个参数是一个公式,可以使用 ~ 后跟一个变量名来创建。传递给 facet_wrap() 的变量应该是分类变量。
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +geom_point(aes(color = species, shape = species)) +facet_wrap(~island)
您将在 Chapter 9 中学习到许多其他用于可视化变量分布和它们之间关系的几何对象(geoms)。
1.5.5 练习
-
根据 ggplot2 软件包中捆绑的
mpg数据框,该数据框包含了美国环境保护署收集的 234 个观测数据,涵盖了 38 个汽车型号。在 mpg 数据框中,哪些变量是分类变量?哪些变量是数值变量?(提示:输入?mpg来阅读数据集的文档。)当您运行?mpg时,如何查看这些信息? -
使用
mpg数据框创建一个hwyvs.displ的散点图。然后,将第三个数值变量映射到color、size、color和size以及shape。这些 aesthetics 在分类变量和数值变量上的行为有何不同? -
在
hwyvs.displ的散点图中,如果将第三个变量映射到linewidth会发生什么? -
如果将同一个变量映射到多个 aesthetics 会发生什么?
-
创建一个
bill_depth_mmvs.bill_length_mm的散点图,并按照species对点进行着色。将点按物种(species)着色有关于这两个变量之间关系的什么信息?通过对物种(species)进行分面绘图(faceting)又会发现什么? -
为什么下面的代码会产生两个独立的图例(legends)?如何修复它以合并这两个图例?
ggplot(data = penguins,mapping = aes(x = bill_length_mm, y = bill_depth_mm, color = species, shape = species)
) +geom_point() +labs(color = "Species")
-
创建下面的两个堆叠条形图。 第一个图可以回答哪个问题? 第二个图可以回答哪个问题?
ggplot(penguins, aes(x = island, fill = species)) +geom_bar(position = "fill")
ggplot(penguins, aes(x = species, fill = island)) +geom_bar(position = "fill")
1.6 保存你的绘图
一旦你创建了一个图形,你可能希望将其保存为图像文件以在其他地方使用。这时可以使用 ggsave() 函数来将最近创建的图形保存到磁盘中:
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +geom_point()
ggsave(filename = "penguin-plot.png")
这将把你的图形保存到你的工作目录中,你会在 Chapter 6 中更详细地了解到这个概念。
如果你没有指定 width 和 height 参数,它们将从当前绘图设备的尺寸中获取。为了获得可重现的代码,建议你指定这些参数。你可以在文档中了解更多关于 ggsave() 函数的信息。
然而,通常我们建议使用 Quarto 来组织最终的报告。Quarto 是一个可重复使用的创作系统,允许你将代码和文字交织在一起,并自动将图形包含在你的写作中。你将在 Chapter 28 中了解更多关于 Quarto 的内容。
1.6.1 练习
-
运行以下代码行。两个图中的哪一个保存为
mpg-plot.png?为什么?
ggplot(mpg, aes(x = class)) +geom_bar()
ggplot(mpg, aes(x = cty, y = hwy)) +geom_point()
ggsave("mpg-plot.png")
-
您需要在上面的代码中更改什么才能将绘图保存为 PDF 而不是 PNG?你如何找出哪些类型的图像文件可以在
ggsave()中工作?
1.7 常见问题
当您开始运行 R 代码时,可能会遇到一些问题。不要担心,这种情况对每个人都会发生。我们多年来一直在编写 R 代码,但每天我们仍然会写出一开始就无法正常工作的代码!
首先,仔细比较您正在运行的代码与书中的代码。R 非常挑剔,一个错位的字符可能会产生完全不同的结果。确保每个 ( 都与一个 ) 匹配,每个 " 都与另一个 " 配对。有时候您运行代码后什么都没有发生。检查您控制台的左侧:如果是 +,这意味着 R 认为您输入的不是完整的表达式,它正在等待您完成。在这种情况下,通常通过按 ESCAPE 键中止处理当前命令,然后重新开始会比较容易。
在创建 ggplot2 图形时,一个常见的问题是将 + 放在错误的位置:它必须放在行尾,而不是行首。换句话说,请确保您没有意外地编写了以下这种代码:
ggplot(data = mpg)
+ geom_point(mapping = aes(x = displ, y = hwy))
如果您仍然遇到困难,请尝试获取帮助。您可以在控制台中运行 ?function_name 来获取有关任何 R 函数的帮助,或者在 RStudio 中选中函数名并按下 F1 键。如果帮助信息似乎不太有用,不要担心,可以跳到示例部分,寻找与您尝试做的事情相匹配的代码示例。
如果这样还无法解决问题,请仔细阅读错误消息。有时候答案就埋在错误消息中!但是,当您刚开始接触 R 时,即使答案在错误消息中,您可能还不知道如何理解它。另一个很好的工具是 Google:尝试搜索错误消息,因为很可能有其他人遇到了同样的问题,并在网上寻求了帮助。
1.8 总结
在本章中,您学习了使用 ggplot2 进行数据可视化的基础知识。我们从支持 ggplot2 的基本思想开始:可视化是从数据中的变量到 aesthetic(如 position、color、size、shape)的 mapping。然后,您逐层学习了如何增加复杂性并改进绘图的呈现方式。您还学习了用于可视化单个变量分布以及可视化两个或多个变量之间关系的常用图表,通过使用附加的 aesthetic mappings 和/或使用 faceting 将绘图分割为小多面体进行绘制。
在本书的后续部分,我们将一次又一次地使用可视化,根据需要引入新的技术,并在 Chapter 9 到 Chapter11 中深入探讨如何使用 ggplot2 创建可视化。
在掌握了可视化的基础知识之后,在下一章中,我们将转换一下思路,为您提供一些实际的工作流程建议。我们将在本书的这一部分中穿插工作流程建议和数据科学工具,因为这将帮助您在编写越来越多的 R 代码时保持组织性。
-
您可以使用 conflicted 包来消除该消息,并在需要时强制进行冲突解决。随着加载更多的包,这变得更为重要。您可以在
https://conflicted.r-lib.org了解更多关于 conflicted 的信息。 -
Horst AM, Hill AP, Gorman KB (2020). palmerpenguins: Palmer Archipelago (Antarctica) penguin data. R package version 0.1.0. https://allisonhorst.github.io/palmerpenguins/. doi: 10.5281/zenodo.3960218.
-
在这里,"formula" 是
~创建的事物的名称,而不是 "equation" 的同义词。
--------------- 本章结束 ---------------
本期翻译贡献:
-
@TigerZ生信宝库

)
)
















