之前做个几个大模型的应用,都是使用Python语言,后来有一个项目使用了Java,并使用了Spring AI框架。随着Spring AI不断地完善,最近它发布了1.0正式版,意味着它已经能很好的作为企业级生产环境的使用。对于Java开发者来说真是一个福音,其功能已经能满足基于大模型开发企业级应用。借着这次机会,给大家分享一下Spring AI框架。
注意:由于框架不同版本改造会有些使用的不同,因此本次系列中使用基本框架是 Spring AI-1.0.0,JDK版本使用的是19。
代码参考: https://github.com/forever1986/springai-study
目录
- 1 Embedding
- 1.1 什么是Embedding
- 1.2 嵌入模型(Embeddings Model)
- 2 Spring AI 中的Embeddings Model
- 2 示例演示
- 3 加载本地模型
前面几乎将Spring AI的聊天模型的功能都讲了一遍,接下来开始几章将会讲解其它类型的大模型。在聊天模型中Spring AI提供了ChatClient做了一层常用的功能性封装,比如聊天记忆、RAG、MCP等应用场景。很遗憾其它类型的大模型并没有提供再次封装的上层API,不过通过前面对聊天模型ChatModel的使用,也知道可以直接使用类似ChatModel对模型的操作,在Spring AI中一样对各类大模型进行了类似ChatModel的封装。这一章先从嵌入模型(Embeddings Model)开始。
1 Embedding
使用嵌入模型(Embeddings Model)之前,需要了解Embedding是什么?为什么要使用Embedding?
1.1 什么是Embedding
首先在人类社会中使用的文字、图片、音频、视频等数据,如何让大模型识别。这里拿文字来说明这个过程:
1)编码: 计算机只会识别0和1,那么这时候要让计算机识别文字,就需要把所有文字进行编码,以中文为例比如00001代表男,00002代表女,这样每个字都有一个编码。
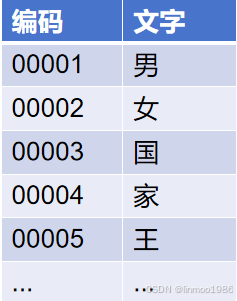
虽然编码可以让计算机识别,但是还是有缺点的。最大的缺点就是文字之间是有一定的关联关系,也就是说每个字独立编码,那么机器是不理解文字之间的关系,为了解决这个问题,分词就出现了。
2)Tokenizer : 为了解决文字之间的关系。这时候就有人想到使用Tokenizer 分词器。在每个语言体系中,并不是所有的字都要独立编码,有些文字他们的语言体系中就是一直连在一起使用的,他们之间是有一定的含义,这样可能只需要对子词进行编码即可。这样就可以通过一定数据训练得到合理的分词表,这个过程就是Tokenizer做的事情。
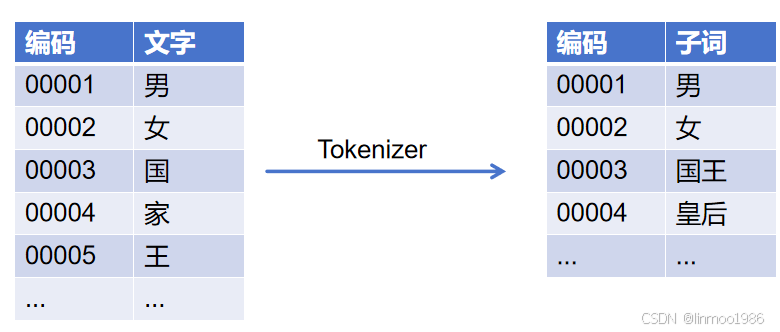
Tokenizer 虽然解决了一定的语义关系,但也造成一个问题,就是过于稀疏,占用过多资源。因为在底层都是2进制表示,那么10万个子词需要一个17维度(2的17次方)才能描述完,但是实际上很多位置上都是0。那么有没有一种办法使用更少的维度来表示更多的子词,这时候就出现了Embedding。子词之间的语义上关系,可能可以通过一个向量维度来表示,一个768维的就能表示768种语义关系可能就已经足够描述所有关系。
3)Embedding: Embeding就是将每个子词ID映射为n维向量,并与位置编码、段落编码相加。这个维度可以简单理解就是相关性。比如其中一个维度表示性别,那么男人和国王在这个维度上面应该是相等的,而女人和皇后在这个维度应该也是相等的。这种通过多维度表示其实就是向量化,而且向量化之后的子词还可以做运算,比如:国王-男=皇后-女 ,其结果在性别这个维度是相等的。
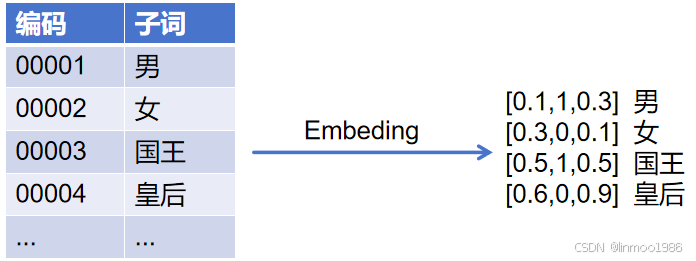
上图示例中就是一个3维来表示,其中中间那个维度表示性别,那么国王-男和皇后-女的向量运算结果在这个性别维度上都是0。当然实际上可能会很多维,比如512、768、1024等,越多维度表示的语义更为准确,但是造成的效果就是需要更多计算量。
通过Embedding技术将文本、图像和视频转换为一系列浮点数数组(即向量),能够捕捉输入之间的关系。这些向量旨在捕捉文本、图像和视频的含义。Embedding数组的长度被称为向量的维度。通过计算两段文本的向量表示之间的数值距离,应用程序能够确定用于生成嵌入向量的两个对象之间的相似度。这就是Embedding的意义。
1.2 嵌入模型(Embeddings Model)
Embeddings Model模型经过这些年的不断改进,出现了各种各样的Embeddings Model。这里需要注意的是Embeddings Model也是一个训练好的模型,这里不详细讲述,大家有兴趣可以去了解更深入。这个主要给大家讲述几个重要选择Embeddings Model的实战参考。在之前我写的《RAG实践系列》中的这一章《检索增强生成RAG系列3–RAG优化之文档处理》已经提到过。
对于我们如何选择一个embedding,我根据一些实战中的经验总结如下:
- 排行榜:首先要知道有哪些embedding模型,一般可以去hugging face的排行版上找:https://huggingface.co/spaces/mteb/leaderboard
- 语言:在排行榜中,你可以根据你的业务选择语言
- embedding维度:这个需要根据你的业务,如果你业务语义丰富,那么选择维度更高更好,如果语义不丰富,其实选择维度更低会更好。
- sequence length:不同embedding模型支持不同sequence length,因此需要根据你的业务选择不同的模型
- 模型大小:这个会根据实际你有多少资源作为选择标准
- 业务效果:以上几个标准可能只是基本维度,最终还是需要看看业务效果,因此你可能需要选择几个比较合适的模型,然后再逐一的去测试一下其效果相对于你的业务结果如何
2 Spring AI 中的Embeddings Model
在Spring AI中,定义了一个EmbeddingModel接口,旨在便于与人工智能和机器学习中的嵌入模型进行集成。其主要功能是将文本转换为数值向量,通常称为“嵌入”。这些嵌入对于诸如语义分析和文本分类等任务至关重要。下面是其源代码:
public interface EmbeddingModel extends Model<EmbeddingRequest, EmbeddingResponse> {/*** 需要各个模型厂家实现调用call方法 */@OverrideEmbeddingResponse call(EmbeddingRequest request);/*** 将一个text进行embedding,返回结果向量*/default float[] embed(String text) {Assert.notNull(text, "Text must not be null");List<float[]> response = this.embed(List.of(text));return response.iterator().next();}/*** 将一个文档进行embedding,返回结果向量*/float[] embed(Document document);/*** 将多个text进行embedding,返回结果向量*/default List<float[]> embed(List<String> texts) {Assert.notNull(texts, "Texts must not be null");return this.call(new EmbeddingRequest(texts, EmbeddingOptionsBuilder.builder().build())).getResults().stream().map(Embedding::getOutput).toList();}/*** 将多个文档进行embedding,返回结果向量*/default List<float[]> embed(List<Document> documents, EmbeddingOptions options, BatchingStrategy batchingStrategy) {Assert.notNull(documents, "Documents must not be null");List<float[]> embeddings = new ArrayList<>(documents.size());List<List<Document>> batch = batchingStrategy.batch(documents);for (List<Document> subBatch : batch) {List<String> texts = subBatch.stream().map(Document::getText).toList();EmbeddingRequest request = new EmbeddingRequest(texts, options);EmbeddingResponse response = this.call(request);for (int i = 0; i < subBatch.size(); i++) {embeddings.add(response.getResults().get(i).getOutput());}}Assert.isTrue(embeddings.size() == documents.size(),"Embeddings must have the same number as that of the documents");return embeddings;}/*** 将多个text进行embedding,但返回请求的结果Response */default EmbeddingResponse embedForResponse(List<String> texts) {Assert.notNull(texts, "Texts must not be null");return this.call(new EmbeddingRequest(texts, EmbeddingOptionsBuilder.builder().build()));}/*** 获取嵌入向量的维度数量。请注意,通常情况下,此操作默认会执行。*/default int dimensions() {return embed("Test String").length;}}
EmbeddingModel接口设计围绕着两个主要目标展开:
- 可移植性:此接口确保了在各种嵌入式模型之间能够轻松实现适应性。它使开发人员能够通过最少的代码更改来切换不同的嵌入技术或模型。这种设计符合 Spring 的模块化和可互换性理念。
- 简洁性:EmbeddingModel 简化了将文本转换为嵌入的流程。通过提供诸如 embed(String text) 和 embed(Document document) 这样简单的方法,它消除了处理原始文本数据和嵌入算法的复杂性。这一设计选择使得开发人员,尤其是那些对人工智能不熟悉的人,能够更轻松地在其应用程序中使用嵌入,而无需深入研究底层机制。
2 示例演示
代码参考lesson17子模块
示例说明:本示例使用智谱的线上embedding模型进行嵌入(由于智谱的embedding模式是付费的,请保证账号有钱!)
1)新建lesson17子模块,其pom引入如下:
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-starter-model-zhipuai</artifactId></dependency>
</dependencies>
2)配置application.properties文件
## API KEY
spring.ai.zhipuai.api-key=你的智谱模型的API KEY
3)创建演示类EmbeddingController:
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;@RestController
public class EmbeddingController {private final EmbeddingModel embeddingModel;public EmbeddingController(EmbeddingModel embeddingModel) {// 自动注入智谱的EmbeddingModel模型this.embeddingModel = embeddingModel;}@GetMapping("/ai/embeded")public float[] embeded(@RequestParam(value = "message", required = true, defaultValue = "测试进行嵌入") String message) {float[] embed = embeddingModel.embed(message);System.out.println("输出的嵌入向量维度:"+embed.length);return embed;}
}
4)创建启动类Lesson17Application:
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class Lesson17Application {public static void main(String[] args) {SpringApplication.run(Lesson17Application.class, args);}}
5)演示效果
说明:可以看智谱默认的embedding模型的维度是1024维
3 加载本地模型
上面的示例是通过加载线上模型,其实有很多优秀的开源embedding模型,比如BGE-M3、M3E等等,很多大厂的embedding也都开源,这个大家可以上网搜一下。但是有个问题,就是很多模型的权重都是基于pytorch或者tensorflow等python框架训练出来的,那么Java中如何加载呢?这部分在前面的RAG中讲过《系列之十 - RAG-加载本地嵌入模型》,大家可以回去看看该示例,这里就不在累述了。
结语:本章先简单浅入的带大家了解了什么是embedding,之后再讲解的Spring AI中的EmbeddingModel,其提供了基础的接口,由各大embedding模型厂商自行实现。最后举例说明如何使用远程和本地的EmbeddingModel。嵌入是大模型的一个基础,它解决了人类社会的内容(文字、图像、视频等)与大模型直接的交互语言,因此了解embedding是非常有必要的。下一章将继续讲解非聊天模型之图像大模型。
Spring AI系列上一章:《Spring AI 系列之二十 - Hugging Face 集成》
Spring AI系列下一章:《Spring AI 系列之二十二 - ImageModel》



)
——链接预测在社交网络分析中的应用)



》免费中文翻译 (第1章) --- Data visualization(2))

)
)







