本文来自作者 莫尔索 的 企业级 AI 应用开发与最佳实践指南, 欢迎阅读原文。
大家好,我之前出版的《LangChain 编程:从入门到实践》一书获得了良好的市场反响和读者认可。近期推出了第二版,我对内容进行了大幅更新:近 60% 的文字内容和全部代码示例均已重写。本次修订的目标,是让本书不再仅聚焦 LangChain 框架本身,而是从 LangChain 全家桶中各类工具的设计理念出发,深入探讨企业级 AI 应用的构建方法与当前 AI 工程化的最佳实践。
LangChain 不止是一个框架
日常交流下来,发现很多人对 LangChain 的印象还停留在一个「功能臃肿、过度抽象」的 AI 应用开发框架,这是一种常见的误解。事实上,自 0.3 版本起,LangChain 框架本身已经变得更加轻量和高效。更重要的是,LangChain 不只是一个开发框架,它代表了一整套完整的 AI 应用开发解决方案,涵盖了从原型设计、Beta 测试到生产部署的全流程,已被 Replit、Lovable 等知名 AI 产品所采用。
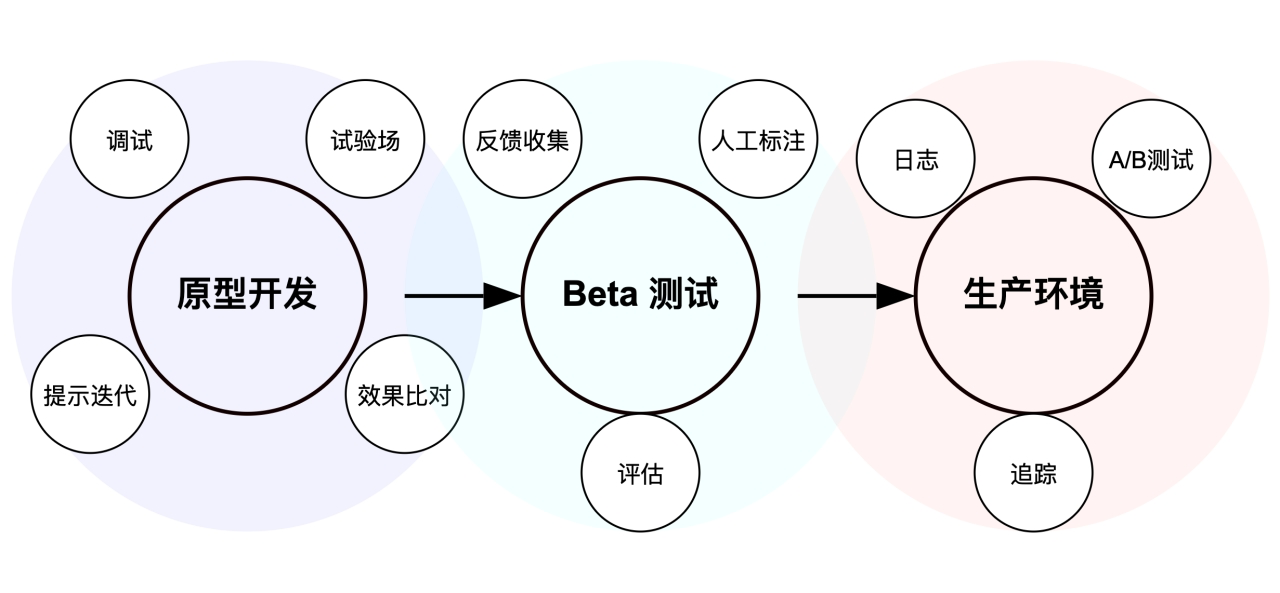
LangChain 生态系统包含七个关键工具,能够高效支持 AI 应用的构建。无论是基于规则的工作流(使用 LangChain)、具备复杂状态管理的 Agentic 工作流(结合 LangChain 与 LangGraph),还是完全自主的 Agent 模式(使用 LangGraph),都能找到相应的工具支持:
- 使用 LangChain CLI 创建标准化项目结构:
pip install langchain-cli - 利用 LangChain 核心框架快速进行原型开发:
pip install langchain - 通过 LangServe 快速启动应用 API 服务:
pip install "langserve[all]" - 使用 LangSmith 实现 AI 应用的可观测性、评估与生产监控:
pip install langsmith - 通过 LangGraph 实现复杂智能体工作流的编排:
pip install langgraph - 使用 LangGraph Studio 进行智能体工作流的可视化设计
- 利用 LangGraph Platform 实现智能体工作流的生产部署
LangChain 早期版本通过“链”的概念,将 AI 应用中的基础模型、提示模板、外部数据和 API 工具等组件模块化串联,提供了高度灵活的设计能力。这种架构激发了开发者社区的广泛集成,使 LangChain 成为功能全面、生态丰富的 AI 开发“瑞士军刀”。随着 Agentic 工作流的兴起,LangChain 团队推出了 LangGraph,采用更灵活的状态图模型,以应对包含循环、条件判断和状态控制等复杂逻辑的智能体任务。
使用 LangChain 构建企业级 AI 应用
LangChain 通过其两大开源框架 —— LangChain 和 LangGraph,以及两款商业化工具 —— LangSmith 和 LangGraph Platform,支持企业级 AI 应用的构建。其中,商业化工具已被用于多家知名 AI 产品的生产环境托管,而开源框架则广泛受到大型企业的采纳。以下是一些典型的企业级 AI 应用案例。

字节打造通用 Agent
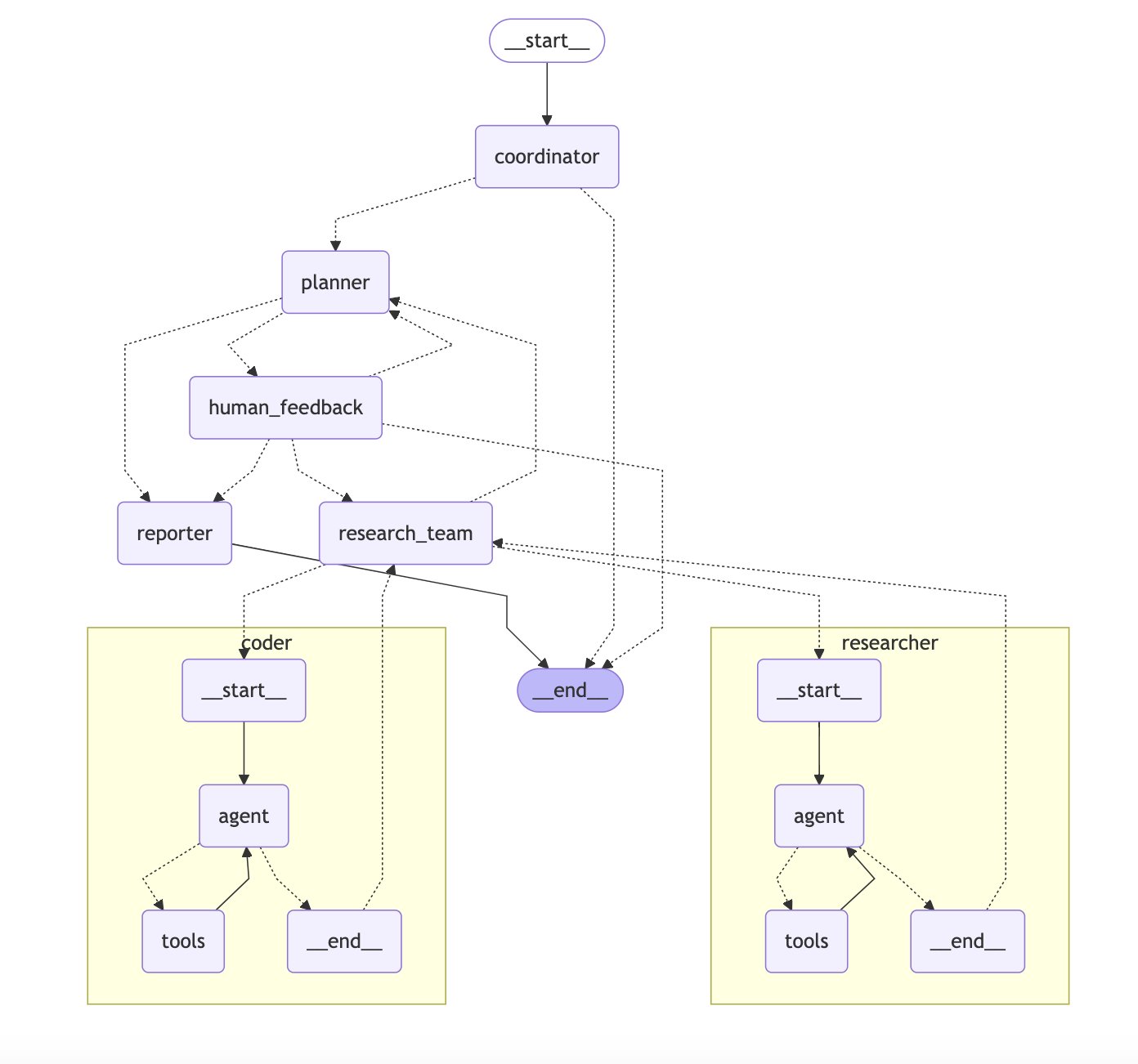
字节跳动开源的 DeerFlow 是一个成熟的通用 Agent 类工具,在 GitHub 上已获得 15,700 颗 Star。其项目依赖通过 pyproject.toml 配置,核心基于 LangChain 与 LangGraph 构建。
dependencies = ["httpx>=0.28.1","langchain-community>=0.3.19","langchain-experimental>=0.3.4","langchain-openai>=0.3.8","langgraph>=0.3.5","readabilipy>=0.3.0",..."langchain-mcp-adapters>=0.0.9","langchain-deepseek>=0.1.3",
]
下面是 DeerFlow 架构图,使用 LangGraph 自带的工具可以直接导出(print(graph.get_graph().draw_mermaid()))。
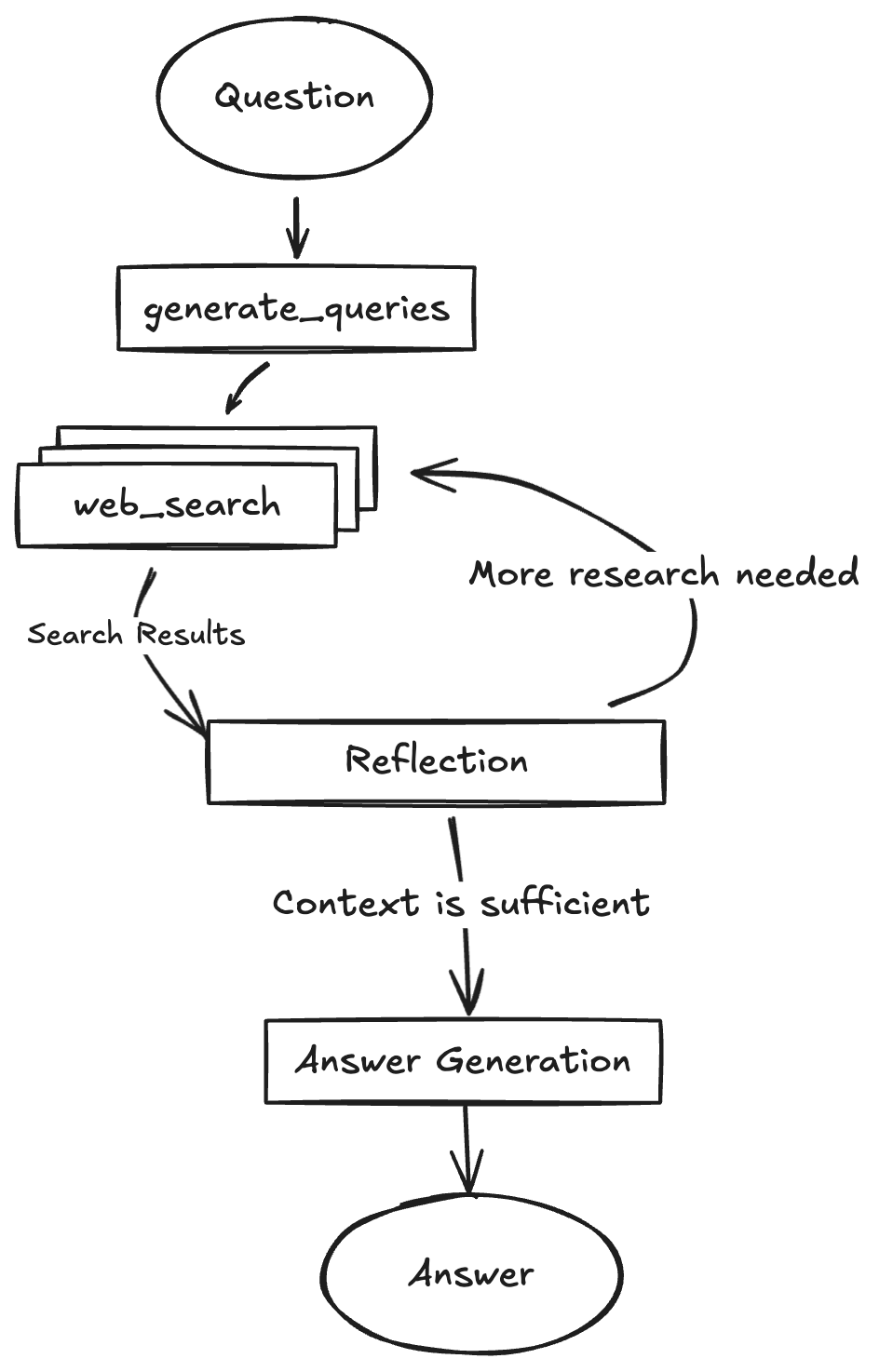
谷歌实现 Deep Reasearch
谷歌开源的 gemini-fullstack-langgraph-quickstart 项目在 GitHub 上获得 15,900 颗 Star🌟,展示了如何构建一个高度完善的深度研究(Deep Research)类产品,核心基于 LangGraph 。
阿里云百炼 AI 应用观测
以下是阿里云大模型服务平台“百炼”的应用观测功能截图。
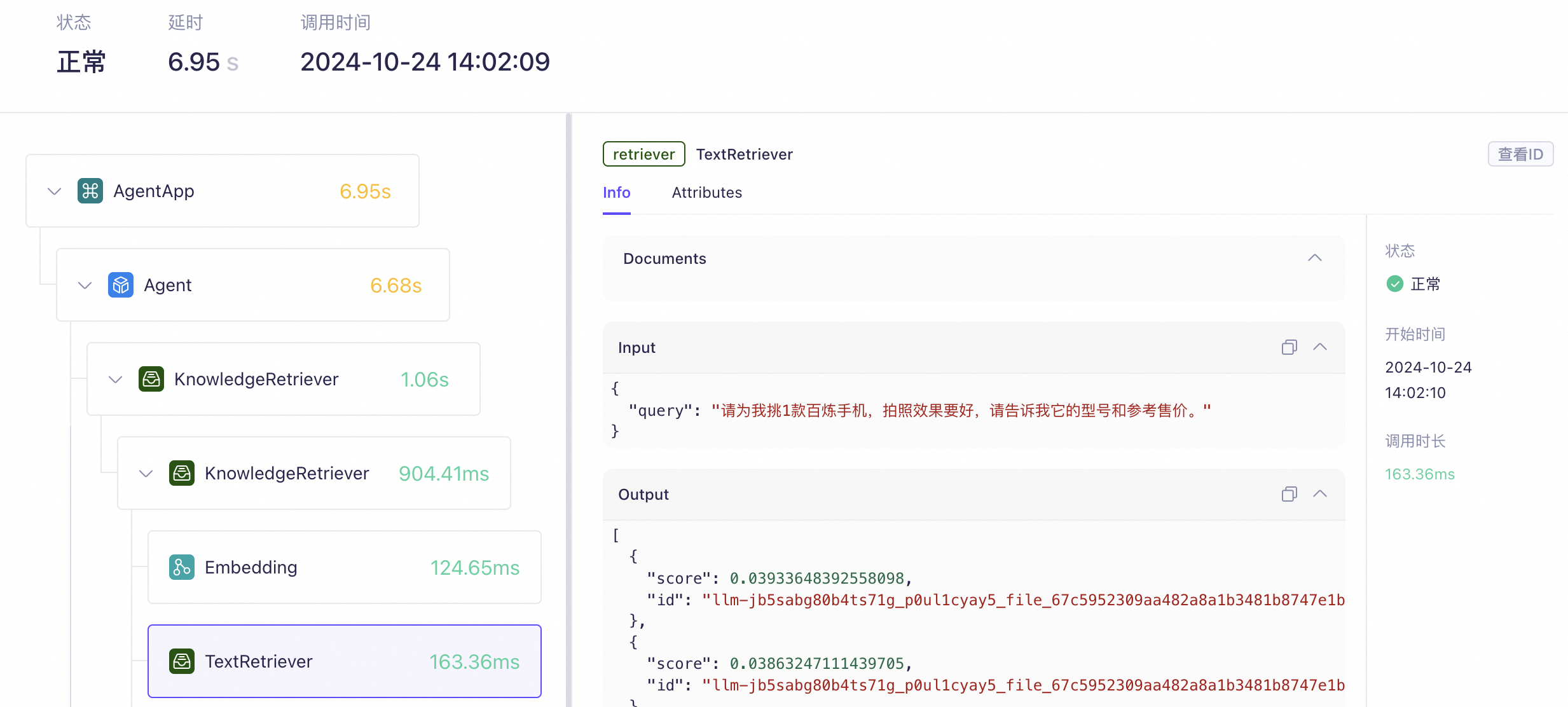
对比来看,LangSmith 提供了指标(metric)、追踪(trace)和日志(log)等核心能力,百炼的应用观测功能正是对标 LangSmith 的设计,旨在支持生产环境中 AI 应用的全面监控与分析。
扣子罗盘的观测功能
最近,AI 领域值得关注的一个事件是,在 C 端用户中广受好评的扣子平台宣布开源。其中,广受好评的 Coze Loop(扣子罗盘)的观测机制,借鉴了 LangChain 的设计理念。根据官方文档 的说明,「扣子罗盘基于 LangChain 的 callback 机制,提供一键集成能力,可自动完成 Trace 数据的上报」。以下示例展示了如何在 LangChain 的 LCEL 模式中无缝集成扣子罗盘的 Trace 功能,从而实现对 AI 模型调用过程的监控与分析。
import osimport cozeloop
from langchain_core.runnables import RunnableConfig
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParserfrom cozeloop.integration.langchain.trace_callback import LoopTracerdef do_lcel_demo():# 配置CozeLoop环境变量os.environ['COZELOOP_API_TOKEN'] = '{your_token}'os.environ['COZELOOP_WORKSPACE_ID'] = '{your_workspace_id}'# 创建cozeloop clientclient = cozeloop.new_client()# 注册callbacktrace_callback_handler = LoopTracer.get_callback_handler(client)llm_model = ChatOpenAI()lcel_sequence = llm_model | StrOutputParser()output = lcel_sequence.invoke(input='用你所学的技巧,帮我生成几个有意思的问题',config=RunnableConfig(callbacks=[trace_callback_handler]))print(output)# 程序退出前,需要调用Close方法,否则可能造成trace数据上报丢失。Close后无法再执行任何操作。client.close()if __name__ == "__main__":do_lcel_demo()
类似的案例还有很多,这里不再一一列举。关于如何开发可观测性插件与企业自有 IT 系统集成的实现方法,我已在第一版中进行了详细介绍,第二版会从设计角度进行更详细的论述。

LangChian 为什么值得学习
需要再次强调,本书第二版的关注点不局限于 LangChain 框架本身,而是能够从 LangChain 全家桶中的各类工具设计思想出发,探讨企业级 AI 应用的构建过程以及 AI 工程化的最新最佳实践。尽管市面上存在众多可替代的框架、工具和产品,LangChain 的优势在于能够提供 Agent 应用从设计、开发、评估、部署到监控的完整实践路径。通过这一路径,读者可以先动手实践,再结合自身的积累与判断力,去评估甚至设计更优秀的框架。在此基础上,读者将能更清晰地辨别其他框架在设计上的优劣,深入理解其组件背后的设计原则,最终成长为合格的 Agent 应用开发者或 Agent 平台架构师。
领先的 Agent 架构设计
Claude Code 最新推出的 Subagents(子智能体) 功能,是指预配置的 AI 角色,专为执行特定任务而设计,具备独立的上下文窗口和定制的系统提示,有助于提高任务处理效率。从设计角度来看,Subagents 与 LangGraph 中的 Subgraphs(子图) 相似:子图本质上是嵌套在另一个图中的图,作为其中的一个节点使用。
该功能适用于以下场景:
- 构建多智能体系统:适用于在复杂系统中引入多个独立的任务处理单元。
- 代码复用:当多个流程图中需要重复使用一组具有共同状态的节点时,可将这些节点封装为子图,并在多个父图中调用。
- 团队协作:在不同团队需独立开发流程图的不同部分时,可将每个部分定义为一个子图。只要保持子图接口(即输入和输出格式)一致,父图即可在不了解其实现细节的前提下进行构建。
在多个子智能体之间如何实现平滑协作?LangGraph 提供了一种称为 交接(Handoff) 的机制。其核心思想是:当某个智能体无法独立完成任务时,可将对话流转交给更合适的智能体,而用户无需重复描述问题。这一概念也体现在 OpenAI Agents SDK 的设计中。
此外,在涉及人机协作(Human-in-the-loop)的场景中,如何在适当时机通知人工介入,以及智能体如何从故障中恢复等问题,LangGraph 也提供了相应的机制设计。
Agent 应用的构建过程应保持透明
HumanLayer 创始人 Dex Horthy 借鉴了「12-Factor App」的理念,提出了「12-Factor Agents」原则(相关视频)。其核心思想是:将 Agent 视为软件,将 LLM(大语言模型)视为可调用的纯函数,开发者应掌控整个流程。LLM 的作用是生成结构化的 JSON 输出,由确定性代码解析并执行,而不是隐藏在抽象的“工具调用”背后。Agent 的核心控制逻辑,包括循环与分支判断,应由开发者编写代码实现;LLM 仅负责决定“下一步该做什么”。流程的执行、中断与重试等操作,均由开发者编写的逻辑控制。
LangChain 可能从其早期框架设计中吸取了“过度抽象、封装过重”的教训。其后续推出的 LangGraph,成为目前开源 Agent 框架中控制最灵活、自由度最高的一个。我在这篇文章中曾深度分析过包括 OpenAI 的 Agents SDK、Google 的 ADK、Crew AI、Agno 和 AutoGen 等主流框架的设计思路。使用 LangGraph 构建 Agent 时,开发者可以完全掌控流程的执行、中断与重试。
此外,LangGraph 支持显式且统一地管理 Agent 的运行状态与业务状态(如对话历史),并将这些状态存储在数据库中。通过简单的 API,即可实现 Agent 的启动、暂停与恢复,非常适合处理长周期任务。
第二版主要更新内容
在介绍完 LangChain 生态之后,我们来看看本书第二版的变化。本书的标题《LangChain 编程:从入门到实践》在第二版中更具现实意义。如果说第一版中的“从入门到实践”是指“有一个想法,然后用 AI 实现并上线一个演示版本”,那么第二版的“实践”则意味着“从一个想法出发,构建出一个可支持百万用户访问的工具,并能持续收集反馈、进行测试与迭代的高效 AI 智能体应用”。那么,第二版具体有哪些更新呢?
- 移除已废弃的 Chain 编程接口内容:由于 Chain 接口已被官方弃用,本书第二版不再介绍 LangChain 早期版本中提到的“六大模块/组件”相关内容,这些内容已过时。
- 移除旧版记忆组件示例:如
ConversationBufferMemory、ConversationStringBufferMemory等旧式记忆组件已被淘汰,相关内容已删除。记忆功能现在统一通过 LangGraph 中自定义的 Memory 模块进行管理。 - 新增对 LangGraph 的详细讲解:本书第二版新增了对 LangGraph 这一 Agent 编排框架的详细介绍,以及与其他主流 Agent 框架的对比分析。
- 全面迁移至 Pydantic 2:所有代码示例均已更新至 Pydantic 2 标准,并兼容
langchain_core的最新版本。 - 所有案例重构为 LangChain 新模块结构:随着 langchain 主包的拆分,本书代码已根据新的模块结构进行重构,包括:
- langchain-core:包含核心抽象(如聊天模型)、可运行性与可观测性工具;
- langchain:通用逻辑实现,适用于多种接口实现的通用代码(如
create_tool_calling_agent); - langchain-community:由社区维护的第三方集成;
- langchain-[partner]:针对特定热门集成(如
langchain-openai、langchain-anthropic)的官方支持包,通常具备更高的稳定性与维护优先级。
- 支持 LangChain 0.3 版本:全书代码示例和讲解均基于 LangChain 最新 0.3 稳定版本。
- 替换为国产模型支持:书中所有案例使用的模型已从 OpenAI 的 GPT 系列更换为国内主流模型,包括通义千问的文本嵌入模型、DeepSeek-V3 和 DeepSeek-R1。
- 新版更多内容介绍请参考图灵编辑部专题文章:《LangChain 学习必备,从入门到实践的全新版指南!》






:激活函数)




 ret2dir详细)







