一、什么是 LLM?
LLM,全称为 Large Language Model(大语言模型),是一种基于神经网络(主要是 Transformer 结构)的大规模自然语言处理(NLP)模型。其核心能力在于理解、生成、翻译和总结自然语言,已广泛应用于问答系统、机器翻译、对话机器人、代码生成、文本创作等场景中。
LLM 的基本任务:给定一段文本,预测接下来的 token(语言片段),也可以理解为:LLM 是一种基于上下文预测下一个 token 的概率分布的模型。
一个典型的 LLM“7B 模型”表示拥有 70 亿参数(billion),使用 float32 存储时,模型大小约为 28GB(7B × 4 字节)。模型规模常见有 0.5B、1B、7B、13B、33B、65B,甚至超过 100B。
二、LLM 模型结构
总体看,LLM 结构有以下几种:
- Decoder-only 架构(主流 LLM,如 GPT-4、LLaMA、PaLM):骨干结构由多个 Decoder 层堆叠而成,且每个 Decoder 层包含自注意力机制和前馈网络,用于从左到右生成文本。
- Encoder-only 架构(如 BERT):这类模型仅使用 Transformer 的 Encoder,用于理解文本而非生成。
- Encoder-Decoder 架构(如 T5、BART):这类 LLM 同时使用了 Transformer 的 Encoder 和 Decoder,Encoder 处理输入(如源文本),Decoder 生成输出(如翻译结果)
当前 GPT、LLaMA 等主流模型采用 Decoder-only 架构堆叠组成,通过自回归方式生成文本。一个典型的 Transformer Decoder 层包括以下组件:
- Self-Attention(自注意力层):对输入序列进行全局信息建模,使模型捕捉上下文关系。
- Feed Forward Network(前馈网络,FFN):通过两层全连接神经网络实现非线性变换。
- Layer Normalization + 残差连接:保证训练稳定性与深层信息流通。
- 多层堆叠:一个 LLM 通常包含几十甚至上百层的 Decoder。每一层都会基于当前输入和之前的 token 信息进行信息融合与加工,形成更深层次的语言理解能力。
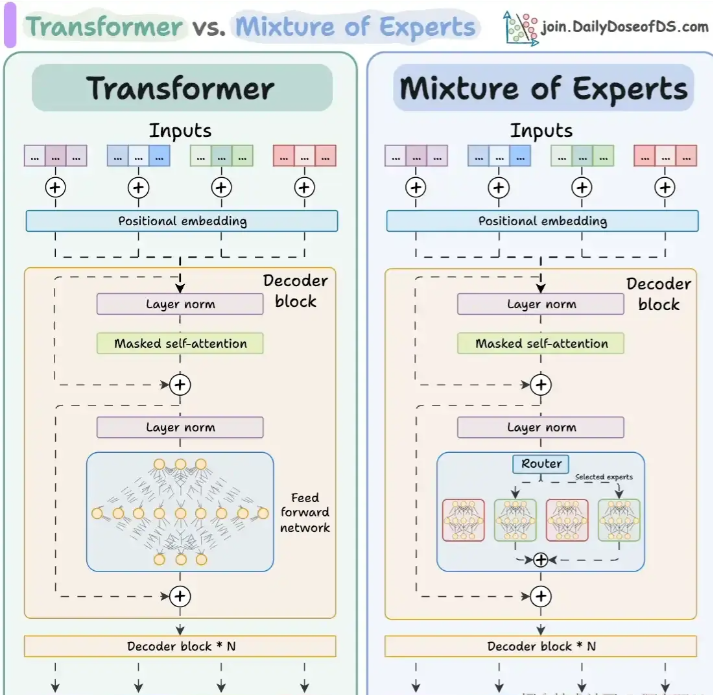
传统 Transformer:每个解码器块使用固定的前馈网络 MoE 架构:通过 Router 动态选择部分专家网络,提升模型容量同时减少计算量。
图片来源:https://blog.csdn.net/LLM88888888/article/details/147580799
三、Token 与 Tokenizer 理论
token 是指文本中的一个词或者子词,经过 Tokenizer(分词器)将原始文本拆解为子词、单词或字符,同时保留语义和结构信息。
tokenizer 将字符串分为一些 sub-word token string,再将 token string 映射到 id,并保留来回映射的 mapping。
embeddings 将 token id 编码成向量,例如下面 bert 示例中:ID=101 → 向量 [0.1, 0.2, …, 0.5] (bert 768 维)
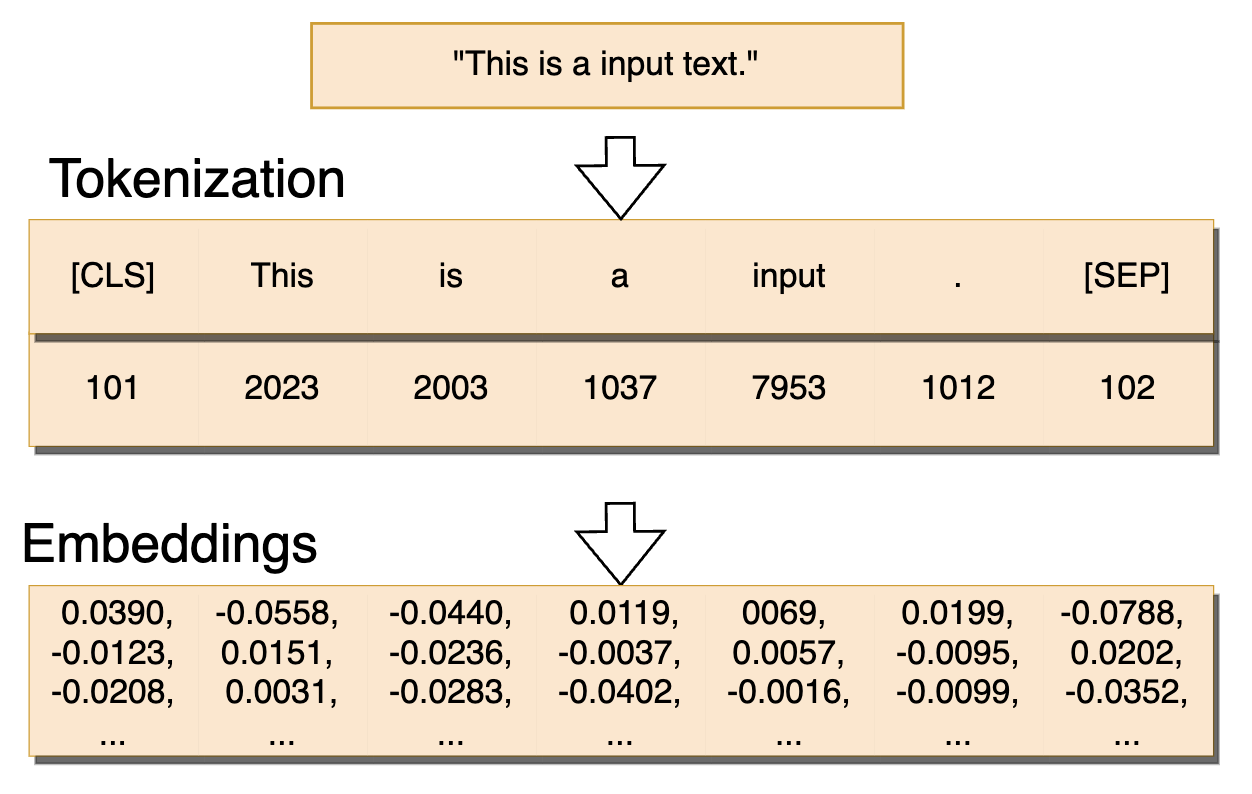
四、bert 实操解读
代码如下:
# 注意,需要 pip install transformers 安装 transformers 库
from transformers import BertTokenizer, BertModel sentence = "Hello, my son is cuting."# 问题1:'bert-base-uncased'从哪来,有哪些内容?
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 问题2:return_tensors='pt'有什么作用?
encoded_input = tokenizer(sentence, return_tensors='pt')
print("encoded_input: ", encoded_input)
# encoded_input: {'input_ids': tensor([[ 101, 7592, 1010, 2026, 2365, 2003, 3013, 2075, 1012, 102]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}# 问题3:分词encoded_input表示什么?
model = BertModel.from_pretrained("bert-base-uncased")
output = model(**encoded_input)
print("output: ", output)
print(output.last_hidden_state.shape) # torch.Size([1, 10, 768]),输出形状为 [1, seq_len, hidden_size]
print(output.pooler_output.shape) # torch.Size([1, 768])
# 问题4:bertmodel输出是什么?怎么理解?
问题 1:'bert-base-uncased’从哪来,有哪些内容?
运行目录:
.
├── 1_code_run.py
└── bert-base-uncased├── config.json├── pytorch_model.bin├── tokenizer_config.json├── tokenizer.json└── vocab.txt
所需文件到:https://huggingface.co/google-bert/bert-base-uncased/tree/main 中获取。
- tokenizer.json:存储分词器的核心映射规则(token 与 ID 对应关系等 ),用于文本转 token ID。
- tokenizer_config.json:配置分词器的参数(如词表路径、模型类型等 ),让 BertTokenizer 能正确初始化。
- vocab.txt:词表文件,记录模型可识别的所有基础 token,是分词和编码的基础。
- config.json:存储模型的架构配置(层数、隐藏层维度、注意力头数等 ),用于构建 BertModel 的网络结构。
- pytorch_model.bin:PyTorch 格式的模型权重文件,加载后为模型提供推理 / 训练所需参数。
使用 from_pretrained 时,只要本地路径(或缓存路径)包含这些文件,transformers 库会自动加载,无需手动逐个指定,把这些文件放在本地对应模型名的文件夹(如 bert-base-uncased 命名的文件夹),然后 from_pretrained 传入该文件夹路径即可。
问题 2:return_tensors='pt’有什么作用?
BertTokenizer 默认返回的是 Python 列表,而 PyTorch 模型需要 torch.Tensor 类型的输入,在调用分词器时,添加 return_tensors=‘pt’ 参数,可以强制返回 PyTorch 张量。
问题 3:分词 encoded_input 表示什么?
- input_ids:token 对应的编号
- token_type_ids:句子类型(如问句/答句)
- attention_mask:是否为有效 token 的掩码
问题 4:bertmodel 输出是什么?怎么理解?
output: BaseModelOutputWithPoolingAndCrossAttentions(last_hidden_state=tensor([[[ 0.1343, 0.2069, -0.1056, ..., -0.3678, 0.3318, 0.4747],[ 0.7642, 0.0530, 0.3679, ..., -0.0856, 0.6686, -0.0110],...,[ 0.6652, 0.3903, -0.0479, ..., 0.0236, -0.5730, -0.3705]]],grad_fn=<NativeLayerNormBackward0>), pooler_output=tensor([[-8.4724e-01, -3.6394e-01, -7.2207e-01, 6.6477e-01, 4.1991e-01,2.4143e-02, 8.3331e-01, 2.9624e-01, -5.0529e-01, -9.9998e-01,...,8.8765e-01, 8.4602e-01, -3.0099e-01, 4.3198e-01, 5.7014e-01,-4.6997e-01, -6.4236e-01, 9.0241e-01]], grad_fn=<TanhBackward0>), hidden_states=None, past_key_values=None, attentions=None, cross_attentions=None)
前面有介绍到:BERT 是 Encoder-only 架构,仅使用 Transformer 的 Encoder,用于理解文本而非生成。
- last_hidden_state
- 维度一般是 [batch_size, sequence_length, hidden_size](示例里 batch_size=1 ,因单条输入;sequence_length 是句子分词后 token 数量;hidden_size 是模型隐藏层维度,BERT-base 通常为 768 )。
- 含义:模型对输入序列中每个 token 编码后的向量表示。比如句子分词后有 5 个 token,就对应 5 个向量,每个向量维度是 hidden_size,可用于细粒度的 token 级任务(例如,文本分类时可取特定位置的 token 向量做分类依据)。
- 示例里的 tensor([[[ 0.1343, 0.2069, -0.1056, …, -0.3678, 0.3318, 0.4747], … ]]) ,就是每个 token 经 BERT 编码后的高维语义向量。
- pooler_output:维度是 [batch_size, hidden_size] (示例里 batch_size=1 ),表示对整个输入序列的全局语义总结,可用于句子级任务(如文本分类、情感分析,输入分类器判断类别)。
- hidden_states:值为 None ,默认 BERT 不会输出各层(如 embedding 层、各 Transformer 层 )的隐藏状态。若初始化模型时设 output_hidden_states=True ,会输出从输入到各层的隐藏状态列表,可用于分析模型各层对语义的加工过程。
- past_key_values:值为 None ,用于增量解码(如文本生成场景 ),默认不输出。若开启相关配置,会保存前一步注意力键值对,加速后续 token 生成。
- attentions:值为 None ,默认不输出注意力权重。若设 output_attentions=True ,会输出各层注意力头的权重,可分析模型关注输入序列的哪些部分,辅助调试和理解模型聚焦点。
- cross_attentions:值为 None ,BERT 是 Encoder 结构,无交叉注意力(一般 Decoder 或 Encoder-Decoder 结构有 ),所以这儿无输出。
型关注输入序列的哪些部分,辅助调试和理解模型聚焦点。
5. cross_attentions:值为 None ,BERT 是 Encoder 结构,无交叉注意力(一般 Decoder 或 Encoder-Decoder 结构有 ),所以这儿无输出。
后续会对 LLM 推理具体过程进行介绍~

 -- 网卡队列)



之加载Mapper)








)
)

FedViT:边缘视觉转换器的联邦持续学习)
研究利用PBFT中的动态视图变换机制,实现区块链系统高效运转)
—— 分组、子查询与窗口函数全攻略)