作者: Lucien-卢西恩 原文来源: https://tidb.net/blog/e7034d1b
Java 应用开发技术发展历程
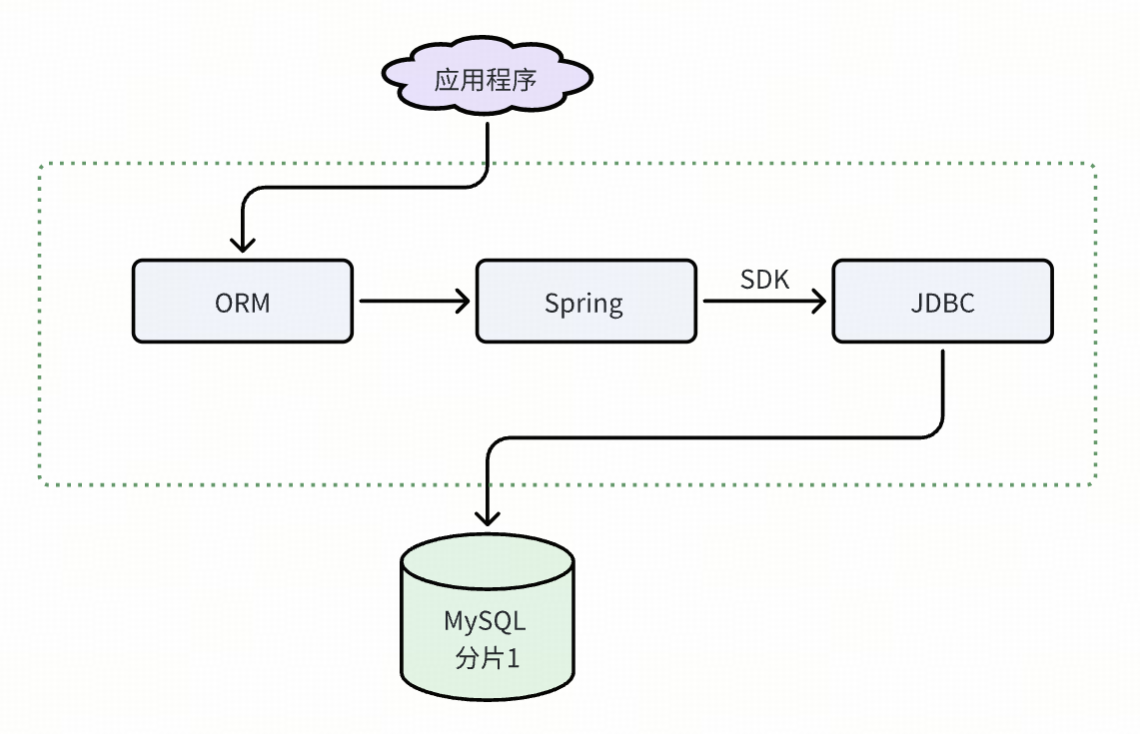
在业务开发早期,用 Java 借助 JDBC 进行数据库操作,虽能实现基本交互,但需手动管理连接、编写大量 SQL 及处理结果集,开发与维护成本高且易出错。随着业务发展,数据库表结构复杂,这种方式弊端凸显。为解决该问题,ORM 技术诞生。它将数据库表映射为 Java 类,使开发者能用面向对象方式操作数据库,提高开发效率、降低耦合度。
而企业级应用规模扩大、业务逻辑变复杂后,需要更有效的管理和组织。Spring 框架应运而生,它提供 IoC 和 AOP 等核心功能。在数据访问上,Spring 可整合 JDBC,通过 spring-JDBC、spring-TX 简化使用;也能与 ORM 框架集成,如 Spring Data JPA。其还结合事务管理功能保证数据一致性,让开发者能依业务选合适访问方式,更好应对业务需求。
名词解释:
- ORM(对象关系映射,Object Relational Mapping):可以把它想象成一座桥梁,连接着 Java 这样的编程语言和数据库。在编程中,我们习惯用对象来处理数据,而数据库是以表和字段的形式存储数据。ORM 就负责把 Java 里的对象和数据库中的表对应起来,让我们能用面向对象的方式操作数据库,不用再写大量复杂的 SQL 语句。比如,有一个 “用户” 对象,ORM 能自动把这个对象的属性(像用户名、密码等)和数据库里 “用户表” 的字段对应上,进行保存、读取等操作 。
- IoC(控制反转,Inversion of Control):这就好比你开一家餐厅,以前是自己亲自去买菜、做菜、上菜,所有事情都得自己操心。现在通过 IoC,你把这些工作交给专业的供应商和服务员,你只需要告诉他们你的需求,具体的执行就由他们负责。在 Java 开发里,IoC 就是把对象的创建和管理工作从代码中剥离出来,交给专门的容器去处理。这样一来,代码变得更简洁,各个模块之间的依赖关系也更好管理,提高了代码的可维护性和可扩展性。
- AOP(面向切面编程,Aspect - Oriented Programming):传统的编程方式就像切蛋糕,按照业务功能一块一块地切;而 AOP 则是横着切,把一些通用的功能,比如日志记录、事务管理、权限控制等,单独拿出来做成 “切面”。这些切面可以在不修改原有业务代码的基础上,动态地添加到程序中。比如,在一个电商系统里,不管是用户下单、支付还是查询订单,都需要记录日志。使用 AOP,就可以把日志记录功能做成一个切面,统一添加到各个业务方法上,而不用在每个方法里都重复写日志记录代码 。
在数字化浪潮下,企业数据量呈爆炸式增长,传统数据库在处理海量数据和高并发访问时力不从心。同时,企业为提升业务灵活性和扩展性,需分布式数据库解决方案。MyCat 等分布式数据库中间件应运而生,作为一款专注于开源分布式数据库中间件,它能将数据分散存储于多个节点,提高系统性能与可扩展性。
分布式数据库中间件位于应用程序与数据库之间,承担性能优化、高可用保障、负载均衡、数据分片管理等重任。比如 ShardingSphere 和 MyCAT,支持数据分片、读写分离,能应对海量数据和高并发。它还负责管理数据库连接,保障数据一致性与安全性,降低应用与数据库耦合,为 Java 开发构建稳定、高效的数据交互架构。
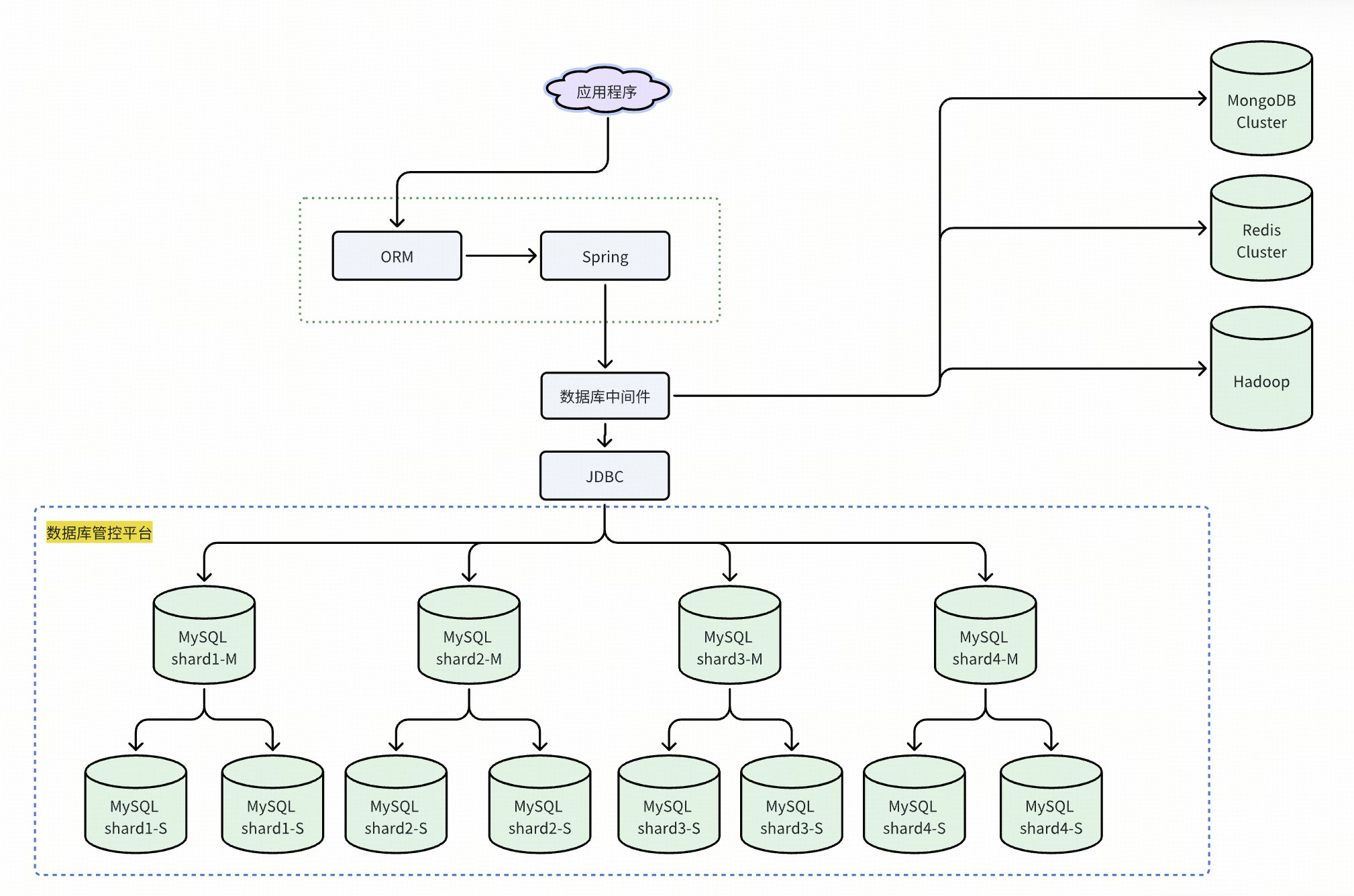
MyCat 等数据库中间件产品具备诸多优势。它支持多种数据分片策略,如范围、哈希、枚举分片等,可根据业务需求灵活分配数据;提供读写分离功能,自动将读写请求路由到不同数据库节点,减轻主库压力,提升系统并发处理能力;还支持分布式事务,采用两阶段提交协议,保障数据一致性。此外,像专注于 MySQL 数据库中间件产品如 DBLE 完全兼容 MySQL 协议和语法,应用程序无需大幅修改代码即可集成,降低了企业使用成本和技术门槛。
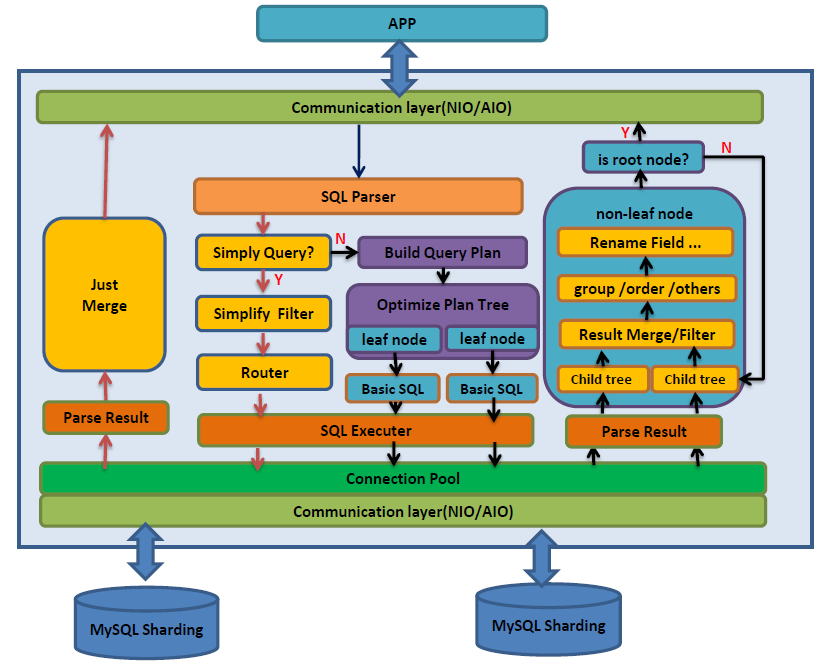
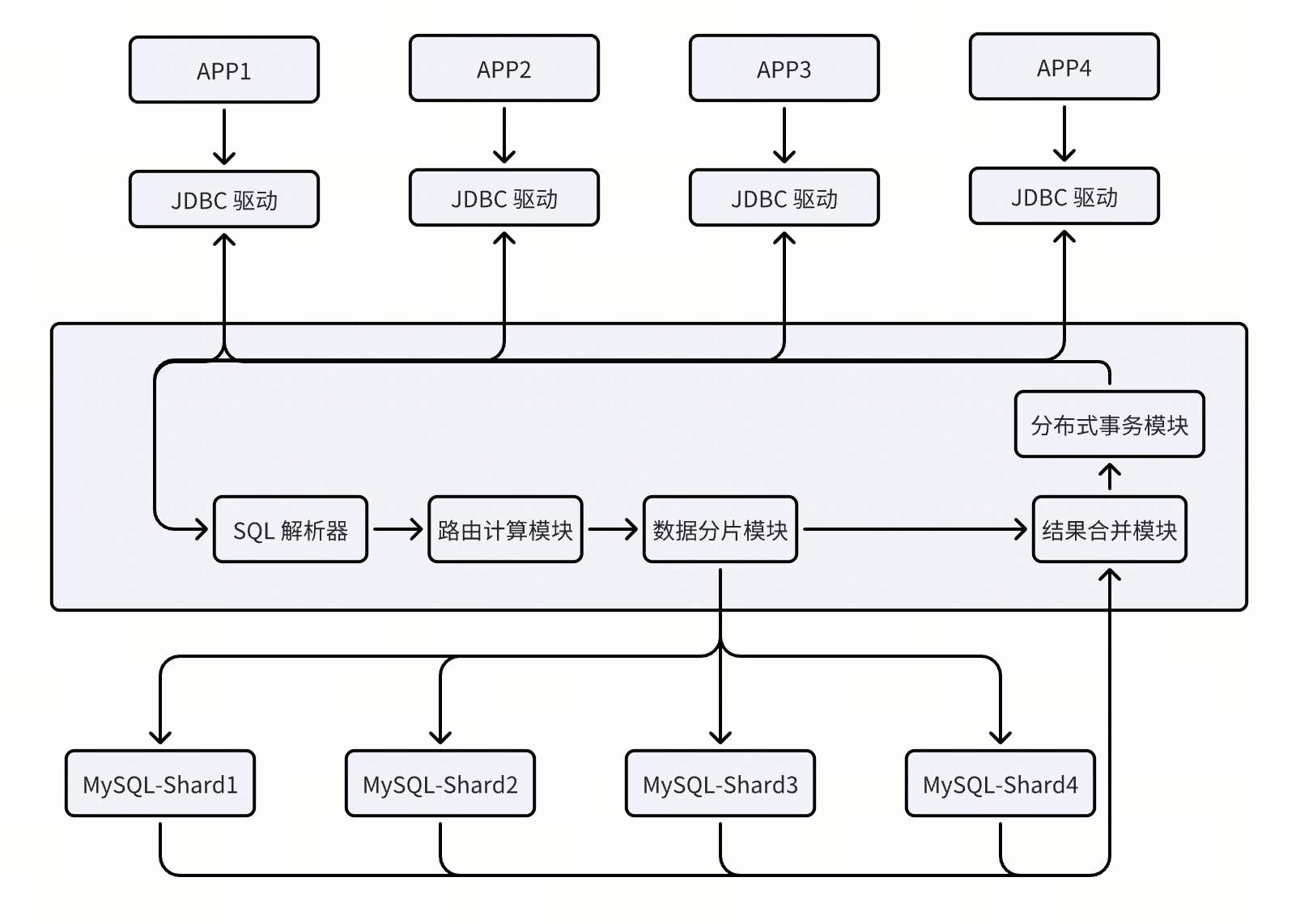
在电商、金融等行业,基于开源 MyCat 分布式数据库中间件开发企业级数据库中间件广泛应用。电商平台借助数据库中间件的数据分片和读写分离功能,能轻松应对大促期间的高并发访问。金融系统利用其分布式事务特性,确保交易数据的准确与完整。客户端层的 Java 应用程序有与数据库交互需求,通过 JDBC 层的 JDBC 驱动与数据库中间件通信,JDBC 驱动将 Java 应用的 SQL 请求转换为适合与数据库中间件交互的格式。数据库中间件核心层的 SQL 解析器接收请求后进行语法和语义分析并转化为抽象语法树,路由计算模块依据解析结果和分片规则算出路由节点,数据分片模块按结果将请求分发到数据库驱动层。数据库驱动层包含对应不同 MySQL 数据库节点的 MySQL 驱动以及可选的其他数据库驱动,负责将数据库中间件的 SQL 语句转换为对应数据库协议格式并处理结果返回。数据库层有 MySQL 数据库节点和可选的其他数据库存储实际数据。数据库中间件核心层的结果合并模块收集各驱动返回的结果进行合并处理,事务管理模块管理分布式事务保证数据一致性,最终处理结果经 JDBC 驱动返回给 Java 应用程序。
业务开发技术不同阶段对比
从代码开发维护成本的层面展开对比,在 20 世纪末至 21 世纪初这段时期,由于互联网基础设施持续完善,互联网企业以及传统企业的数字化转型顺势而生,各式各样的业务架构和数据架构纷纷涌现,用于支撑业务的发展与迭代。伴随业务数据处理请求呈现井喷式增长且不断演进,对于分布式架构以及分布式数据库的需求变得越发显著。在数据处理架构进行迭代以满足当下业务需求的过程中,也遭遇了诸多问题。通过下面的列表进行概括,可以知晓典型场景中面临的挑战。
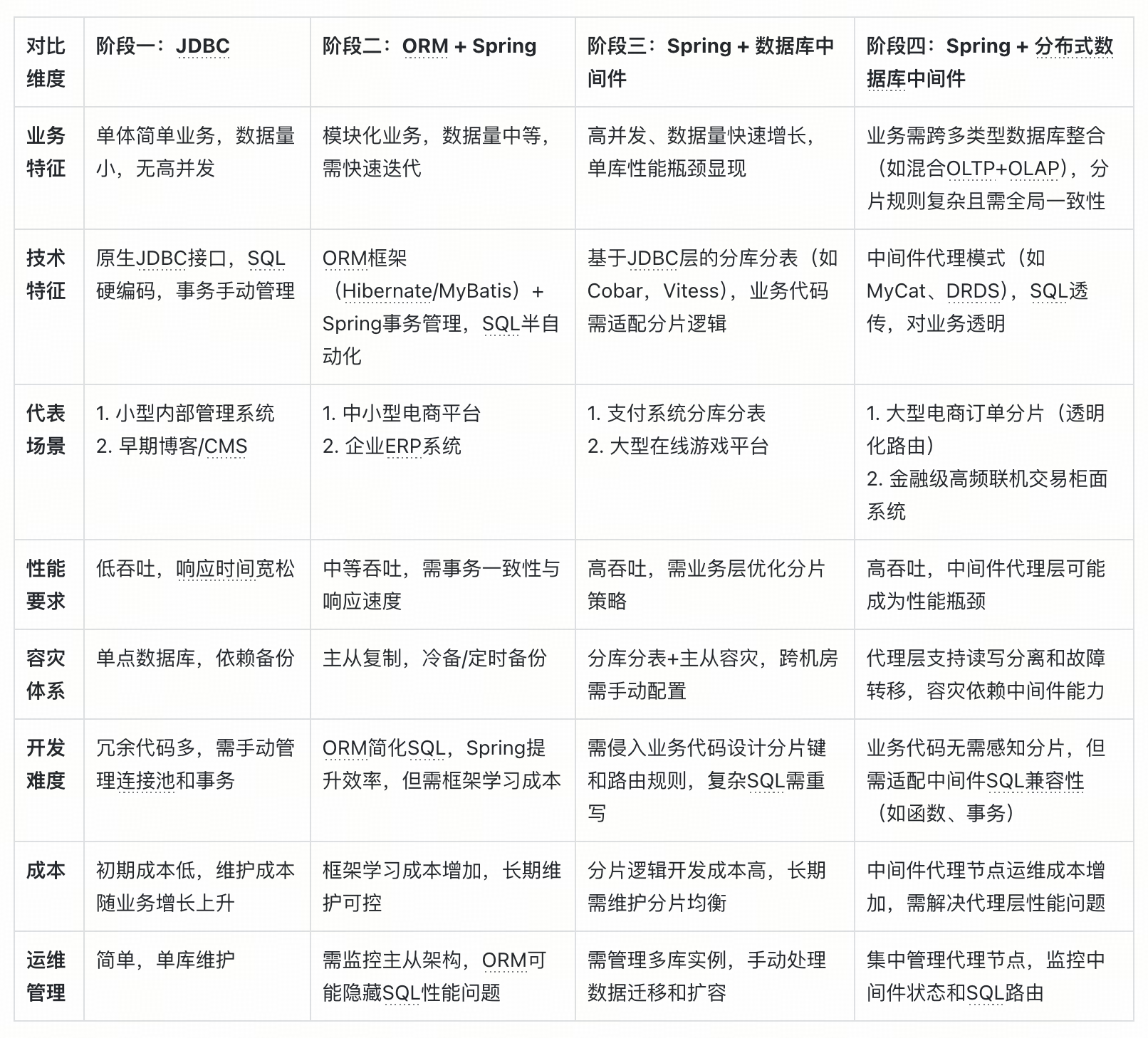
以上 4 类数据架构方案中,简单总结出以下几类显著问题:
- 直连 JDBC 架构存在手动处理数据库连接、SQL 编写及结果解析导致开发成本高,且应对表结构和业务变化时维护成本大的问题,适合在小规模高频量化交易场景快速业务上线支撑;
- ORM + Spring 架构有 ORM 映射性能损耗及学习框架成本高,但是开发效率提升加快更大规模多模态业务的搭建,在构建 O2O 小规模电商场景类业务应用较多。
- Spring + 数据库中间件架构面临系统复杂度和故障排查难度增加带来的成本提升,随着业务井喷式增长,多模态业务复杂度逐步增加,需要跨业务间的数据频繁交互以及数据聚合,大型电商一体化平台业务平台逐步成本市场的引领者,且架构灵活面向 OLTP 简单事务处理以及并发分析处理能力得以快速上线。但是在数据库中间件层需要进行开发维护成本也指数级增加。
- Spring + 分布式数据库中间件架构则因分布式系统极高复杂度和高昂资源投入致使开发维护成本极高等等。在绝大部份业务场景中,维护分布式数据库中间层的分片路由、扩容节点 等开发运维工作中,从开发及维护层面中低效、成本高的问题日益凸显。
典型数据库中间件应用示例
以 MyCat 类数据库中间件为例,假设有一个 Orders 订单表,按照订单金额和订单创建时间进行分片路由。
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100"><table name="orders" dataNode="dn1,dn2,dn3" rule="order_rule"></table>
</schema><dataNode name="dn1" dataHost="localhost1" database="db1"/>
<dataNode name="dn2" dataHost="localhost2" database="db2"/>
<dataNode name="dn3" dataHost="localhost3" database="db3"/><dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="hostM1" url="jdbc:mysql://127.0.0.1:3306" user="root" password="password"/>
</dataHost>
<dataHost name="localhost2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="hostM2" url="jdbc:mysql://127.0.0.2:3306" user="root" password="password"/>
</dataHost>
<dataHost name="localhost3" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100"><heartbeat>select user()</heartbeat><writeHost host="hostM3" url="jdbc:mysql://127.0.0.3:3306" user="root" password="password"/>
</dataHost><function name="order_rule" class="io.dble.route.function.AutoPartitionByLong"><property name="mapFile">partition-long.txt</property><property name="defaultNode">0</property>
</function>
在 partition-long.txt 中定义分片规则:
# 订单金额范围和时间范围组合的分片规则
# 金额区间 0 - 1000 且时间在 2024 年之前
0-1000|2024-01-01 00:00:00=0
# 金额区间 1001 - 5000 且时间在 2024 年之前
1001-5000|2024-01-01 00:00:00=1
# 金额大于 5000 且时间在 2024 年之前
5001-99999999|2024-01-01 00:00:00=2
# 金额区间 0 - 1000 且时间在 2024 年之后
0-1000|2024-01-01 00:00:01=0
# 金额区间 1001 - 5000 且时间在 2024 年之后
1001-5000|2024-01-01 00:00:01=1
# 金额大于 5000 且时间在 2024 年之后
5001-99999999|2024-01-01 00:00:01=2
在 Java 代码块示例
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.sql.Timestamp;public class DBLEComplexShardingDemo {private static final String JDBC_URL = "jdbc:mysql://your_dble_host:your_dble_port/TESTDB";private static final String USER = "your_username";private static final String PASSWORD = "your_password";public static void main(String[] args) {try (Connection connection = DriverManager.getConnection(JDBC_URL, USER, PASSWORD)) {// 插入订单数据insertOrder(connection, 2000, Timestamp.valueOf("2023-12-31 12:00:00"));insertOrder(connection, 6000, Timestamp.valueOf("2024-01-02 12:00:00"));// 查询订单数据queryOrders(connection);} catch (SQLException e) {e.printStackTrace();}}private static void insertOrder(Connection connection, int orderAmount, Timestamp orderTime) throws SQLException {String sql = "INSERT INTO orders (order_amount, order_time) VALUES (?, ?)";try (PreparedStatement preparedStatement = connection.prepareStatement(sql)) {preparedStatement.setInt(1, orderAmount);preparedStatement.setTimestamp(2, orderTime);preparedStatement.executeUpdate();System.out.println("Order inserted successfully.");}}private static void queryOrders(Connection connection) throws SQLException {String sql = "SELECT * FROM orders";try (PreparedStatement preparedStatement = connection.prepareStatement(sql);ResultSet resultSet = preparedStatement.executeQuery()) {while (resultSet.next()) {int orderId = resultSet.getInt("order_id");int orderAmount = resultSet.getInt("order_amount");Timestamp orderTime = resultSet.getTimestamp("order_time");System.out.println("Order ID: " + orderId + ", Amount: " + orderAmount + ", Time: " + orderTime);}}}
}
代码解释
- 中间件配置配置:在
schema.xml中定义了orders表的分片规则,根据order_rule函数进行分片。partition-long.txt文件中定义了根据订单金额和订单创建时间的复杂分片规则。 - Java 代码:使用 JDBC 连接到中间件,插入不同金额和时间的订单数据,并查询所有订单数据。MyCat 会根据配置的分片规则将数据路由到不同的数据库节点。
这个示例展示了一个较为复杂的分片逻辑,结合了订单金额和订单创建时间进行分片。你可以根据实际需求调整分片规则和代码逻辑。随着分片增加、主从节点读写分离、主从节点容灾切换 等路由逻辑会出现指数级复杂维护,也导致后续业务模型迭代受到路由分片规则方案的制约。
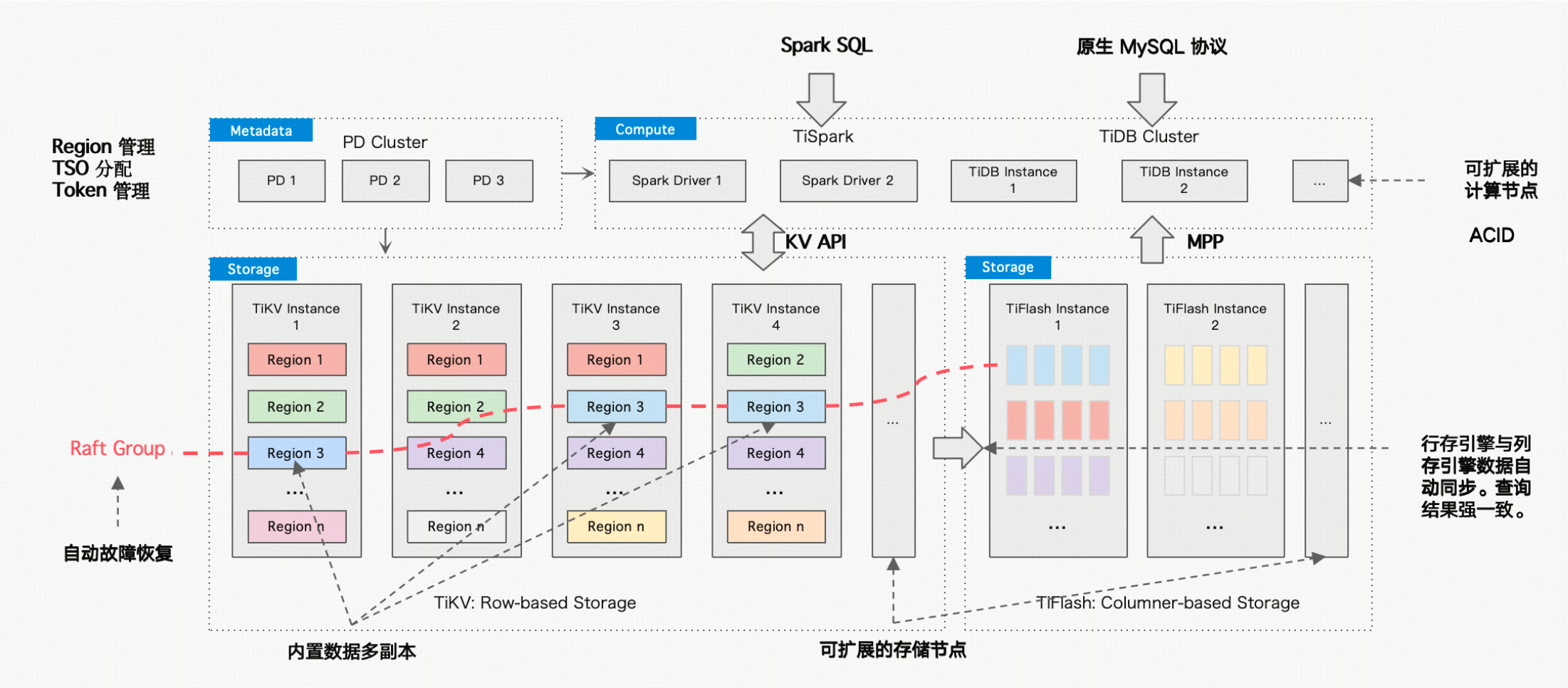
在分布式数据库技术发展进程里,MyCat 作为聚焦 MySQL 的开源分布式数据库中间件,曾有效解决海量数据存储与高并发数据路由分片访问难题,大力推动了企业数字化转型。但当下,业务迭代面临严峻挑战。业务开发模式转变,平台化整合加速,企业对业务敏捷性和数据价值挖掘的需求飙升。系统架构需应对 PB 级数据容量、百万 QPS 吞吐量及混合业务模式;数据架构要灵活调整且支持多维度差异化访问和服务。传统分库分表产品在快速迭代中,数据访问局限尽显,难满足实时洞察与快速响应需求。在此背景下,TiDB 分布式云原生数据库应运而生,以独特优势带来新解,为企业应对复杂业务挑战提供了多元选择。
TiDB 为极简业务开发提效
TiDB 分布式云原生数据库,自带透明数据分片与水平弹性扩展能力,让开发者无需手动编写复杂的数据拆分、路由和合并代码,降低了数据库水平扩展模块的开发维护成本;同时其内置的数据强一致性解决方案,免去了开发者自行实现分布式事务协议的困扰。
TiDB 是一体化的分布式数据库,集计算、存储和分布式管理功能于一身,使用 TiDB 可以避免引入额外的中间件层,简化了系统架构。例如,在一些中小型企业的应用系统中,使用 TiDB 可以减少周边生态组件数量,降低架构的复杂性和维护成本。其具备自动将数据分散到不同的节点上,并根据节点的负载情况动态调整数据分布,保证系统的性能和稳定性。在电商系统中,随着业务的发展,商品数据量不断增加,TiDB 可以自动处理数据的分片和均衡,无需人工过多干预。数据存储层采用了 Raft 协议,能够提供分布式环境下的强一致性保证,确保数据在多个副本之间的一致性,对于对数据一致性要求较高的金融交易系统等场景非常适用。
名词解释:
Raft 协议:在分布式系统中,数据会存储在多个节点上,要保证这些节点的数据一致可不是件容易的事。Raft 协议就像是一个指挥官,负责协调各个节点,让它们在数据更新、故障恢复等情况下保持一致。它通过选举出一个领导者节点,其他节点作为跟随者,领导者负责接收客户端的请求,然后把数据同步给跟随者。如果领导者出现故障,就会重新选举新的领导者,确保系统能持续稳定运行,就像一个组织里有明确的领导和分工,即使领导临时有事,也能迅速选出新领导,保证组织正常运转。
- 数据库中间件在处理二级索引场景中,实现需手动协调多节点,查询交互频繁,开发调试难。而 TiDB 内置且自动管理维护,可以在线进行 DDL 操作,优化器智能利用二级索引实现数据分片检索,让开发人员专注业务开发;
- 数据库中间件依赖复杂协议实现分布式事务,要手动编写大量异常处理代码,大部分中间件产品会采用 GTM 单节点实现统一全局事务管理能力,额外需要采用 TCC、Saga 事务补偿机制带来大量代码开发量。TiDB 提供简单接口,用标准 SQL 管理,自动维护并发控制与全局一致性事务,通过 PD 微服务框架方案,可以实现并发处理数据自动负载、全局一致性事务 TSO 保障以及数据调度能力。
- 在复杂的 2PC (两阶段事务提交)分布式事务能力下,TiDB 提供更简单的事务处理提交方案,无论是 TB 级别复杂事务还是百万级 QPS 海量并发订单处理场景,都可以像单机 MySQL 一样实现事务自闭环处理。无需强制业务逻辑拆分来迎合数据库中间件产品能力。TiDB 提供分布式事务执行的可观测性全链路检测,高效处理事务响应问题,提供分析定位能力。
综合而言,分布式数据库中间件增加开发复杂度,TiDB 以透明化、自动化、智能化简化流程,为开发提效带来更多可能。
TiDB 作为一体化分布式数据库,有效整合软硬件资源,无需额外部署复杂的数据库中间件和多个数据库组件,从而显著减少了硬件采购与维护成本。例如,企业能够将原本分散用于不同功能数据库和中间件的服务器整合为一个集群。同时,TiDB 具备自动伸缩能力,可依据业务需求动态调整资源。像在促销活动期间增加资源,活动结束后释放,极大地节省了成本。此外,TiDB 兼容 MySQL 协议,降低了开发人员的学习成本和应用迁移难度,有效提升了开发效率。
TiDB 还提供了强大的数据隔离与流控隔离方案。基于数据的隔离方案,TiDB 借助 Placement rule 实现。通过 Placement rule,用户能够对数据的存储位置进行细粒度控制,可以将不同业务、不同重要级别的数据放置在不同的存储节点或存储区域,避免数据相互干扰,确保关键业务数据的高可用性和高性能。例如,将核心交易数据与普通日志数据分别存储在不同的节点组。基于流控的隔离方案则依托于 Resource control,它可将 TiDB 集群资源划分成不同资源组,并为每个组设置独立的资源使用限制和优先级,如 CPU、内存使用限制等。不同的 SQL 语句可分配到不同资源组执行,保证高优先级业务不受低优先级业务影响,提升资源使用效率和系统稳定性。

为提升整体资源利用效果,TiDB 建立完善的监控系统,实时监测集群资源使用和性能指标,依据监控数据调整 Placement rule 和 Resource control 配置,同时优化 SQL 语句与系统参数,达到资源利用最大化方案。此外,在运维期间,需定期评估业务需求,合理规划资源,使 TiDB 能够更好地适配业务变化,充分发挥其在降本增效、资源管控以及一体化方面的优势。
暂时无法在飞书文档外展示此内容
TiDB 对比分布式数据库中间件局限与权衡
前文阐述了 TiDB 在降本增效、资源管控及一体化方面展现出诸多优势,如软硬件整合降低成本、自动伸缩适应业务需求、借助 Placement rule 和 Resource control 实现有效资源隔离等。不过,与分布式数据库中间件相比,TiDB 也存在一定局限。TiDB 相比部分中间件方案,其在极少数需要深度定制化路由的场景中可能存在适应性限制。综合来看,TiDB 的优势仍使其在众多场景中成为极具竞争力的选择,接下来可进一步探讨如何在不同场景下权衡使用 TiDB 与分布式数据库中间件。
-
兼容多种数据库
- 分布式数据库中间件可以连接多种不同类型的数据库,如 MySQL、Oracle 等,实现对异构数据库的统一管理和访问。TiDB 主要是一个独立的分布式数据库,虽然它兼容 MySQL 协议,提供了结构化数据、半结构化、向量等数据的读写处理以及实时海量数据分析能力,但无法直接管理 NoSQL 类型的数据库。在一些企业中,可能同时存在多种不同类型的数据库,需要使用分布式数据库中间件来实现数据的整合和统一访问。
-
历史系统集成
- 对于一些已经存在的历史系统,可能已经与特定的分布式数据库中间件深度集成,替换为 TiDB 可能需要对系统进行大规模的改造,成本较高。在这种情况下,继续使用分布式数据库中间件可能是更合适的选择,以避免对现有系统造成过大的影响。从长远角度考虑,如果业务进行跨越式迭代产品升级,数据库中间件维护成本依然高于大规模改造分布式数据库成本。业务运营长尾收益角度,现代化应用架构设计应用 TiDB 分布式数据库。无论业务开发效率提升、数据库维护效能增强,都可以在 1-2 年左右有显著收益。
-
定制化路由和策略
- 分布式数据库中间件允许用户根据业务需求自定义复杂的路由规则和策略,如基于业务逻辑、数据特征等进行灵活的数据路由。TiDB 的分片和路由策略是基于其内部的算法和机制,虽然可以满足大多数场景的需求,但对于一些有特殊定制化需求的场景,可能不够灵活。TiDB 提供特定场景下业务架构改造的完整解决方案,TiDB 产品能力会不留余力得会将业务数据读写逻辑通过 TiDB 强大的数据热点离散均衡算法策略,充分利用存算分离分布式能力,使软硬件一体化的 ROI 最大化,达成企业高效基础软硬件转型目标。
极简开发体验做长期主义
数据库架构从 JDBC 到融合 ORM、数据库中间件,再到分布式数据库中间件,一路演进,各有其独特的应用场景与优劣势。JDBC 虽开发维护成本高,却在高频量化交易这类对性能和响应速度要求严苛的场景中,凭借其直接高效的交互优势站稳脚跟;ORM 结合 Spring 框架,大幅提升开发效率,降低维护难度,在小型电商管理系统等业务逻辑相对简单的场景中表现出色;引入数据库中间件,增强了对数据库的管理能力,实现读写分离与数据分片,满足了大型在线游戏平台等高并发、大数据量的业务需求,不过也带来了系统复杂度、扩容硬件成本指数倍增加等问题;分布式数据库中间件适用于金融级高频联机交易柜面系统这类对分布式事务强一致性和高可用性要求极高的场景,但其架构复杂、成本高昂。
TiDB 作为分布式云原生数据库,强兼容 MySQL 生态,并在降本增效、资源管控及一体化方面优势显著。它透明数据分片与自动水平垂直扩展能力,内置数据强一致性解决方案,实现软硬件资源整合,降低成本并提升开发效率;借助 Placement rule in SQL 和Resource control 实现强大的资源隔离。
选择 TiDB,是因为它集数据分片与自动扩展、数据一致性保障、软硬件资源整合、成本控制、资源管控以及 MySQL 协议兼容等诸多优势于一身,能有效简化系统架构、提升开发效率、降低运维成本,契合多样化业务场景需求 。让业务开发者释放出的精力用于业务开发迭代上面,实现 DBA、开发者、业务、企业共赢。

)

![[免费]微信小程序宠物医院管理系统(uni-app+SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】](http://pic.xiahunao.cn/[免费]微信小程序宠物医院管理系统(uni-app+SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】)
)




,支持经纬度定位与查找)







)

