目录
引言
虚拟内存
页表
单级页表
页表项
单级页表的不足
二级页表
四级页表
快表TLB
结语
引言
一个系统中,CPU和内存是被所有进程共享的,而且一个系统中往往运行着多个进程。如果一个进程不小心写了另一个进程的内存,那么被写入的进程可能会发生一些迷惑行为。

虚拟内存
一个进程,只有在它运行起来的时候才知道它实际占用哪块内存,程序员在写代码的时候是无法确定的。为了实现独立编址,既不考虑内存是否能容纳整个程序,也不考虑程序最终是在内存中的什么位置,大佬们突发奇想,能不能等到程序运行时,才为每一个程序分配一定的运行空间,由地址转换部件将编程时的地址转换成实际物理内存中的地址呢? 当然可以!于是,就引入了虚拟内存技术。
关于什么是虚拟内存,举个例子:假设你开了一家“超能快递公司”,但真实的仓库(物理内存)只有一块很小的场地(比如100㎡)。不过你打广告说:“我们有10个足球场大的货架空间!(虚拟内存)” —— 吸引无数顾客(程序)来寄送快递。
说白了虚拟内存本质上就是骗程序,让每个程序以为自己独占整个内存。它有以下几个优势:
1) 内存隔离与保护:每个程序拥有独立的虚拟地址空间,避免程序间直接访问彼此内存。
2) 简化编程模型:程序员无需关心物理内存的实际分配情况。
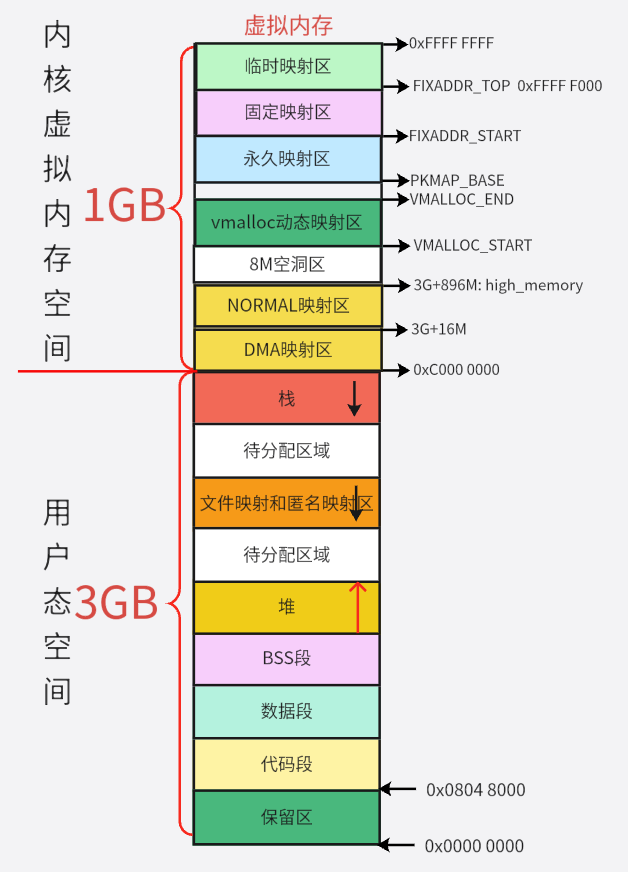
页表
页表是操作系统内存管理中的核心数据结构,用于实现虚拟地址到物理地址的转换。它由操作系统的内存管理单元MMU来维护。每个进程都有自己的页表,页表实际上还对内存起到了保护的作用,在虚拟地址到物理地址转换的页表项里,设置了权限位,如果权限不够,我们是拿不到对应的物理地址的,这对内核的数据起到了保护的作用。关于页表项的权限位后面再详细介绍。
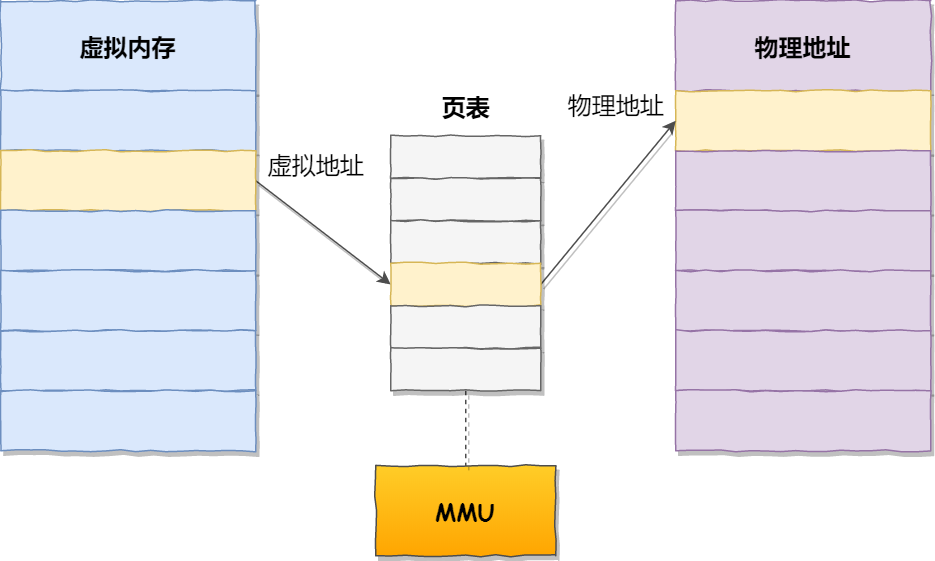
可以先通过上面这张图在脑海里建立一个虚拟地址到物理地址转换的模型,后面我们在持续填充细节。
单级页表
单级页表的地址转换过程:
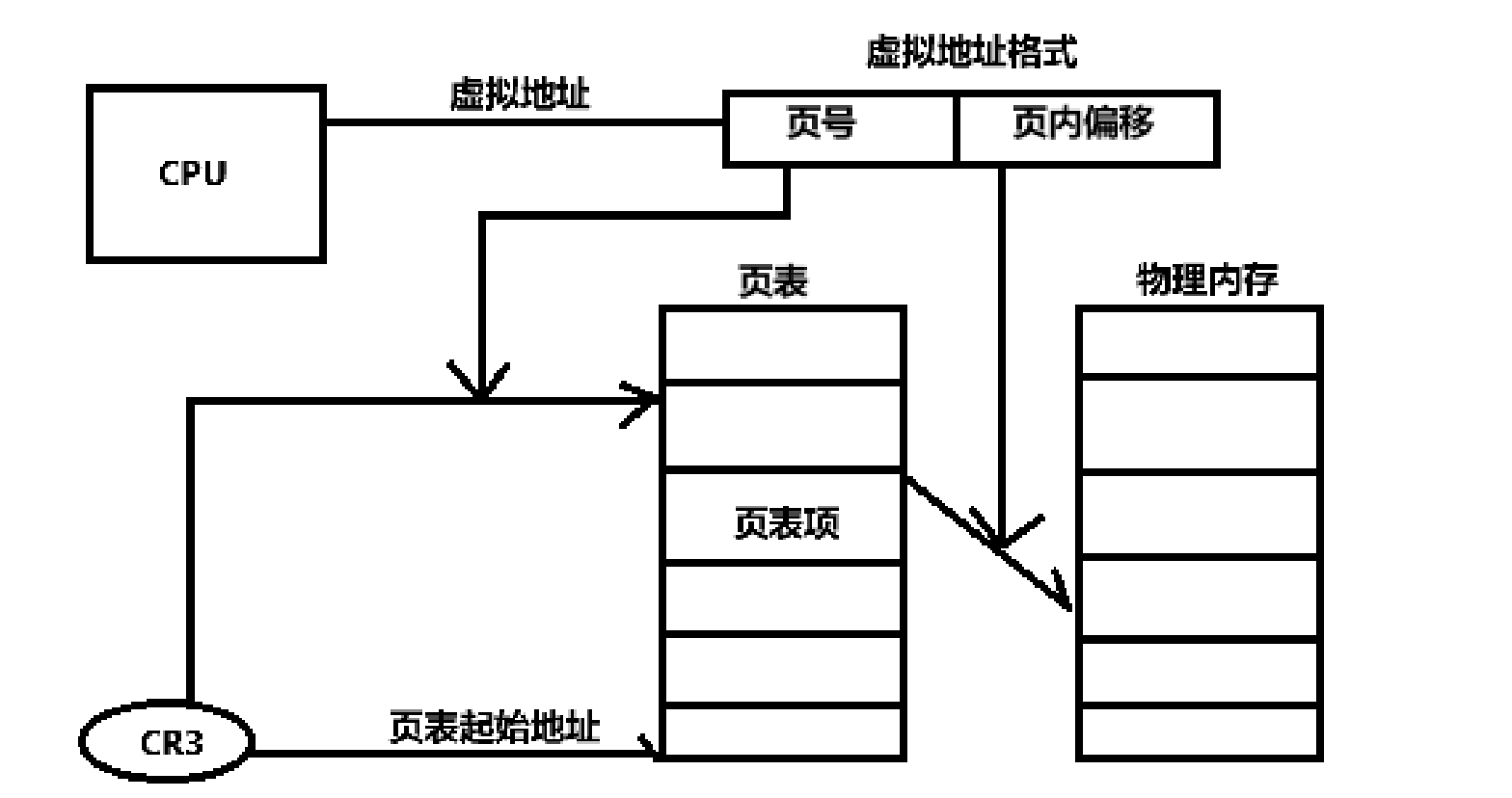
首先介绍一下虚拟地址的格式:它由两部分组成,一部分是页号,另一部分是页内偏移。页号是用来找到页表中的页表项,页表就是一个连续的空间,页号就是要找页表项在页表中的偏移量,相当于数组下标。页内偏移,是指在物理内存页中的偏移,单个物理内存页也是连续的,也可以把它看做一个数组,页内偏移当做下标。
CR3:它是个寄存器,在进程创建的时候初始化,用来存放当前进程的顶级页表起始地址。
CPU发出要访问的虚拟地址后,可以通过虚拟地址中的页号加上CR3中存放的页表起始地址定位到相应的页表项,一个页表项的大小是固定的,为4个字节。页表项里存放着对应物理内存页起始地址,然后在结合虚拟地址中的页内偏移,即可得到完整的物理地址,定位到相应位置上。
页表项

1)P:对应的物理内存页是否在内存中。1表示在内存中,0表示不在。如果不在,就会出发缺页中断,把对应的数据换入内存。
2)RW:表示该进程对该内存页具有的读写权限。1表示具有读写权限,0表示具有只读权限。
3)US:值为0表示该物理内存只有内核才能访问,值为1表示用户空间的进程也可以访问。
4)PWT:值为1表示CPU的cache中数据发生修改后,采用全写的方式进行同步,为0表示采用写回的方式进行同步。
5)PCD:表示对应的物理内存页是否可以缓存在CPU的cache中,1表示不可以,0表示可以。
6)A:表示对应的物理内存最近是否被访问过。1表示被访问过,0表示没有。CPU的内存管理单元MMU会经常检查该位置,来判断对应的物理内存页是否活跃,作为换入换出的依据。
后面几个就不介绍了~
单级页表的不足
有了上面的认识,我们知道:一个页表项大小为4B,它可以映射一张大小为4KB物理内存页,一张页表的大小也是4KB,包含1024个页表项。
这样一算,一张页表可以映射4MB的物理内存。那么32位系统下,内存大小为4GB,就需要1024张页表。一张页表4KB,那么一共就是需要4MB的物理内存来存放1024张页表。但是,随着系统的运行,很难找到这么一大片的连续空间。更要命的是,每个进程都需要有自己独立的页表,就更难找到这么多块连续的4MB内存空间了。进程一旦多起来,这也是一笔不小的开销呀~
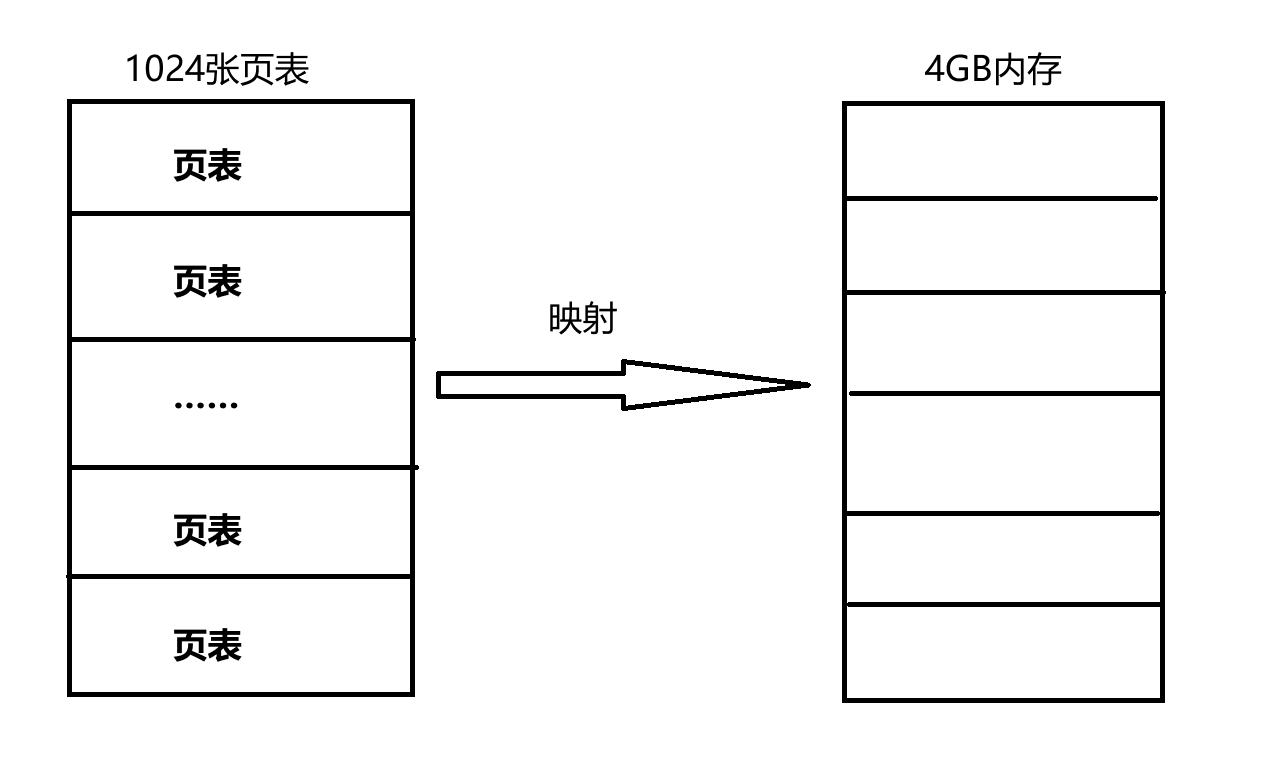
但是,话又说回来,有必要进程一启动就给它分配4MB的内存空间去存放那么多张页表吗?
根据程序的局部性原理,程序不会在一上来就要访问所有内存,相反进程对于内存的访问表现出明显的倾向性,更倾向于访问最近访问过的地址周围的一些数据。最近访问过的地址以及它周围的数据很可能通过同一张页表就可以找到。
因为单级页表存在的一些不足,页表开始向多级页表演进。
二级页表
二级页表就是在单级页表的基础上,增加了一个目录结构。
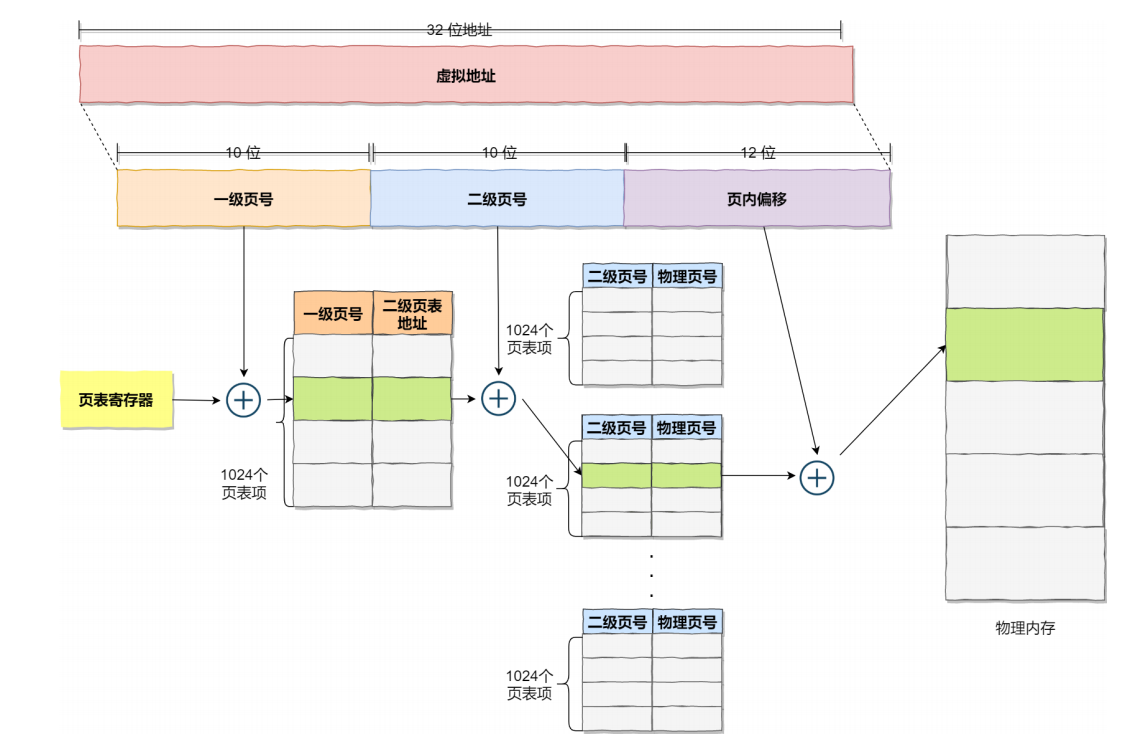
相较于单级页表来说,地址转换的时候要多一层,同时虚拟地址中也要多保存一级页号。
一张一级页表中,也同样有1024个页表项,一个页表项映射一张二级页表,一张二级页表映射4MB物理内存。那么一张一级页表就可以映射4GB的内存。原来单级页表需要4MB,现在优化到4KB。只有一级页表常驻在内存中,二级页表存在磁盘上,根据需要进行换入和换出。
四级页表
深刻理解了单级页表和二级页表以后,其实四级页表也一样,在虚拟地址上多了几级页号,然后进行地址转换的时候要多走几层。
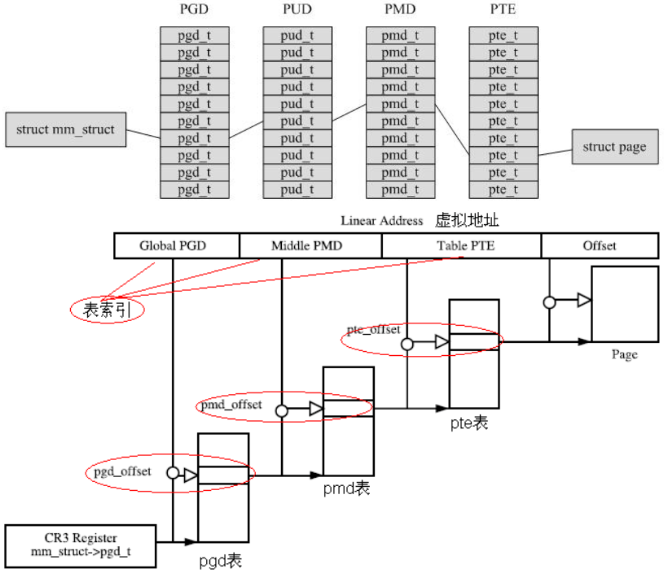
PGD:全局页目录 PUD:上层页目录 PMD:中间页目录 PTE:页表项
快表TLB
快表,本质上就是MMU的一个缓存,缓存常用页表项以加速地址转换。
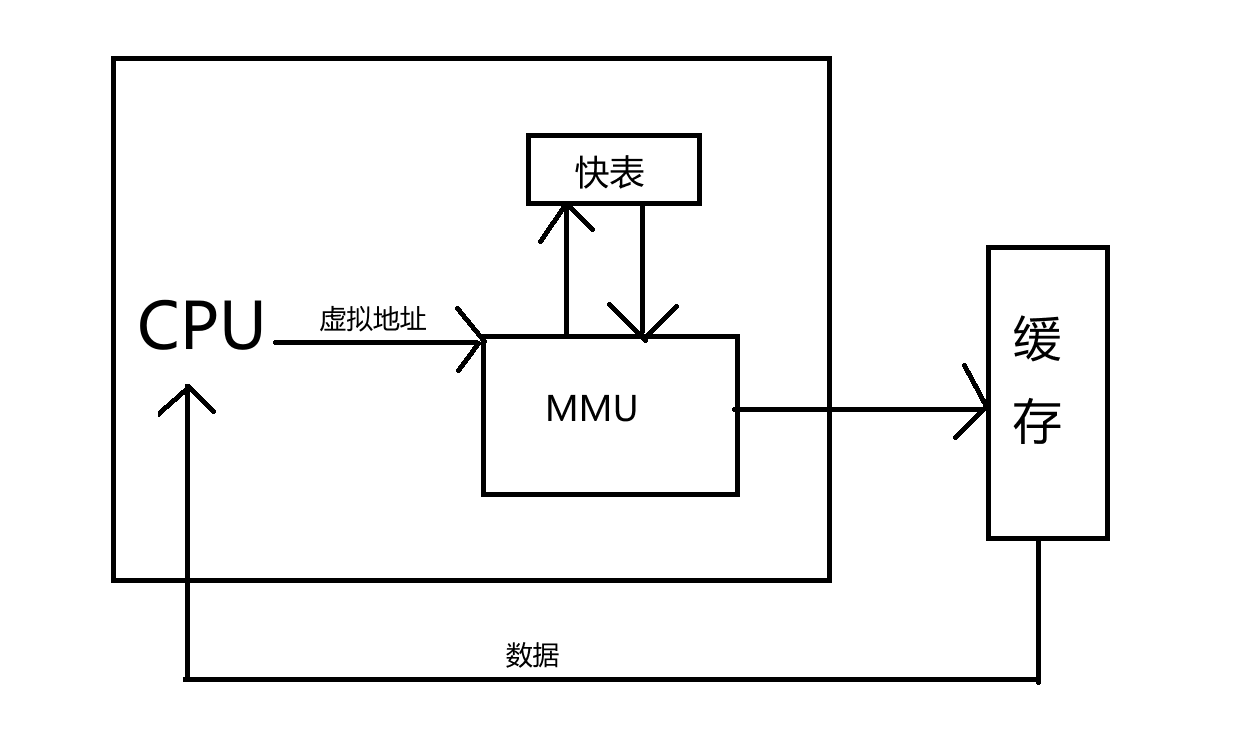
CPU发出虚拟地址后,MMU首先去快表中查找是否存在对应的页表项,如果存在就直接返回对应的物理地址,然后通过该地址去缓存中找到对应的数据,然后将数据传入CPU。以上是快表缓存命中的情况,通过这一过程,也就了解了什么是快表以及它的作用何在了。
结语
页表的设计永远需要在「空间效率」、「查询速度」和「灵活性」之间找到动态平衡,没有完美的方案,只有适合场景的取舍。
推荐阅读:https://www.cnblogs.com/binlovetech/p/17571929.html
感谢支持~











讲解与实战(9))







的结构)