本文目录:
- 一、project目录
- 二、utils里的两个工具包
- (一)common.py
- (二)log.py
- 三、src文件夹代码
- (一)模型训练(train.py)
- (二)模型预测(predict.py)
- 四、代码整体:
- 五、最终运行生成图像
- (一)负荷分析图
- (二)预测效果图
电力负荷预测项目:该项目基于历史的电力负荷数据,训练XGBoost模型,实现时序预测里多变量单步的电力负荷预测。
一、project目录

data:获取到历史电力负荷数据。
log:根据写好代码,在代码运行过程中会生成相应日志。
model:建立一个空文件夹来存储训练好的模型。
二、utils里的两个工具包
(一)common.py
# -*- coding: utf-8 -*-
import pandas as pd
import numpy as np
#这是哪儿来的?def data_preprocessing(path):"""1.获取数据源2.时间格式化,转为2024-12-20 09:00:00这种格式3.按时间升序排序4.去重:param path::return:"""# 1.获取数据源data = pd.read_csv(path)# 2.时间格式化data['time'] = pd.to_datetime(data['time']).dt.strftime('%Y-%m-%d %H:%M:%S')# 3.按时间升序排序data.sort_values(by='time', inplace=True)# 4.去重data.drop_duplicates(inplace=True)return datadef mean_absolute_percentage_error(y_true, y_pred):"""低版本的sklearn没有MAPE的计算方法,需要自己定义,高版本的可以直接调用:param y_true: 真实值:param y_pred: 预测值:return: MAPE(平均绝对百分比误差)"""n = len(y_true)if len(y_pred) != n:raise ValueError("y_true and y_pred have different number of output ")abs_percentage_error = np.abs((y_true - y_pred) / y_true)return np.sum(abs_percentage_error) / n * 100
(二)log.py
# -*- coding: utf-8 -*-
import logging
import osclass Logger(object):# 日志级别关系映射level_relations = {'debug': logging.DEBUG,'info': logging.INFO,'warning': logging.WARNING,'error': logging.ERROR,'crit': logging.CRITICAL}def __init__(self, root_path, log_name, level='info', fmt='%(asctime)s - %(levelname)s: %(message)s'):# 指定日志保存的路径self.root_path = root_path# 初始logger名称和格式self.log_name = log_name# 初始格式self.fmt = fmt# 先声明一个 Logger 对象self.logger = logging.getLogger(log_name)# 设置日志级别self.logger.setLevel(self.level_relations.get(level))def get_logger(self):# 指定对应的 Handler 为 FileHandler 对象, 这个可适用于多线程情况path = os.path.join(self.root_path, 'log')os.makedirs(path, exist_ok=True)file_name = os.path.join(path, self.log_name + '.log')rotate_handler = logging.FileHandler(file_name, encoding="utf-8", mode="a")# Handler 对象 rotate_handler 的输出格式formatter = logging.Formatter(self.fmt)rotate_handler.setFormatter(formatter)# 将rotate_handler添加到Loggerself.logger.addHandler(rotate_handler)return self.logger
注意:可再另外在utils文件夹下新建一个__init__py,方便在下文src的py中导入utils的工具包方法。
三、src文件夹代码
(一)模型训练(train.py)
import os
import pandas as pd
import matplotlib.pyplot as plt
import datetime
from utils.log import Logger
from utils.common import data_preprocessing
from xgboost import XGBRegressor
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.metrics import mean_squared_error,mean_absolute_error
import joblibplt.rcParams['font.family'] = ['SimHei']
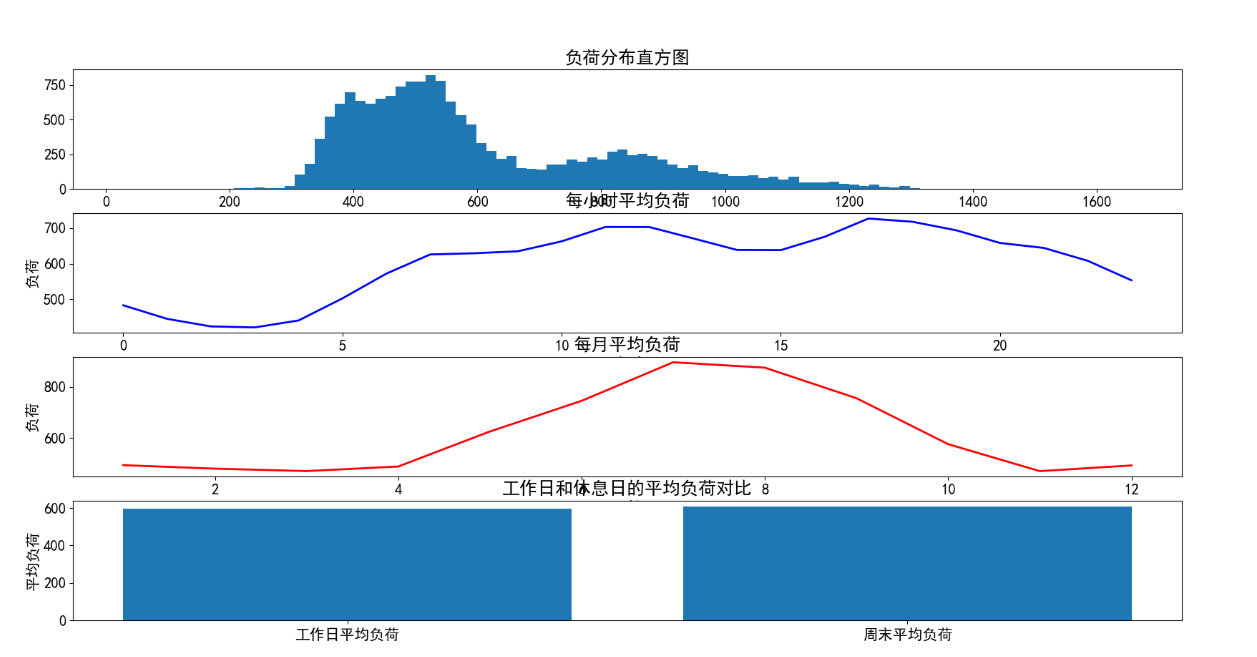
plt.rcParams['font.size'] = 15def power_data(data):data=data.copy(deep=True)print(data.columns)# print(data.info)print(data.head())fig=plt.figure(figsize=(20,10))ax1=fig.add_subplot(411)ax1.hist(data['power_load'],bins=100)ax1.set_title('负荷分布直方图')# plt.show()ax2 = fig.add_subplot(412)# print(type(data['time'][1]))#时间是字符串类型data['hour'] = pd.to_datetime(data['time']).dt.hourprint(data.head())data_hour_avg=data.groupby('hour')['power_load'].mean()#data_hour_avg=data.groupby('hour',as_index=False)['power_load'].mean()print(data_hour_avg) #数据类型为series:以hour为索引,平均值为列# ax2.plot(data_hour_avg['hour'],data_hour_avg['power_load'],color='r',linewidth=2)ax2.plot(data_hour_avg.index,data_hour_avg.values,color='b',linewidth=2)ax2.set_title('每小时平均负荷')ax2.set_xlabel('小时')ax2.set_ylabel('负荷')# plt.show() #注意:画图时,如果有多张图,plt.show()必须放在最后,同时如果有savefig需求,需要将savefig函数放在show函数前面。ax3 = fig.add_subplot(413)data['month'] = pd.to_datetime(data['time']).dt.monthdata_month_avg=data.groupby('month')['power_load'].mean()print(data_month_avg)ax3.plot(data_month_avg.index,data_month_avg.values,color='r',linewidth=2)ax3.set_title('每月平均负荷')ax3.set_xlabel('月份')ax3.set_ylabel('负荷')# plt.show()ax4 = fig.add_subplot(414)data['weekday'] = pd.to_datetime(data['time']).dt.weekdaydata_weekday_avg=data.groupby('weekday')['power_load'].mean()print(data_weekday_avg)data['is_workday']=(data['weekday']>=4).astype(int) #直接转换,效率比apply高print(data.head())power_load_holiday_avg=data[data['is_workday']==0]['power_load'].mean()power_load_workday_avg=data[data['is_workday']==1]['power_load'].mean()ax4.bar(x=['工作日平均负荷','周末平均负荷'],height=[power_load_workday_avg,power_load_holiday_avg])ax4.set_title('工作日和休息日的平均负荷对比')ax4.set_ylabel('平均负荷')# plt.show()plt.savefig('../data/fig/负荷分析图.png')def feature_engineering(data,logger):logger.info("===============开始进行特征工程处理===============")result = data.copy(deep=True)logger.info("===============开始提取时间特征===================")# 1、提取出时间特征# 1.1提取出对应的小时,用以表示短期的时间特征result['hour'] =pd.to_datetime(result['time']).dt.hour# 1.2提取出对应的月份,用以表示长期的时间特征result['month'] =pd.to_datetime(result['time']).dt.month# 1.3 对时间特征进行one-hot编码# 1.3.1对小时数进行one-hot编码hour_encoding = pd.get_dummies(result['hour'])hour_encoding.columns = ['hour_' + str(i) for i in hour_encoding.columns]print(hour_encoding)# 1.3.2对月份进行one-hot编码month_encoding = pd.get_dummies(result['month'])month_encoding.columns = ['month_' + str(i) for i in month_encoding.columns]# 1.3.3 对one-hot编码后的结果进行拼接result = pd.concat([result, hour_encoding, month_encoding], axis=1)logger.info("==============开始提取相近时间窗口中的负荷特征====================")# 2指定window_size下的相近时间窗口负荷window_size = 3shift_list = [result['power_load'].shift(i) for i in range(1, window_size + 1)]shift_data = pd.concat(shift_list, axis=1)shift_data.columns = ['前' + str(i) + '小时' for i in range(1, window_size + 1)]result = pd.concat([result, shift_data], axis=1)logger.info("============开始提取昨日同时刻负荷特征===========================")# 3提取昨日同时刻负荷特征# 3.1时间与负荷转为字典time_load_dict = result.set_index('time')['power_load'].to_dict()# 3.2计算昨日相同的时刻result['yesterday_time'] = result['time'].apply(lambda x: (pd.to_datetime(x) - pd.to_timedelta('1d')).strftime('%Y-%m-%d %H:%M:%S'))# 3.3昨日相同的时刻的负荷result['yesterday_load'] = result['yesterday_time'].apply(lambda x: time_load_dict.get(x))# 4.剔除出现空值的样本result.dropna(axis=0, inplace=True)# 5.整理特征列,并返回time_feature_names = list(hour_encoding.columns) + list(month_encoding.columns) + list(shift_data.columns) + ['yesterday_load']logger.info(f"特征列名是:{time_feature_names}")return result, time_feature_namesdef model_train(data, features, logger):"""1.数据集切分2.网格化搜索与交叉验证3.模型实例化4.模型训练5.模型评价6.模型保存:param data: 特征工程处理后的输入数据:param features: 特征名称:param logger: 日志对象:return:"""logger.info("=========开始模型训练===================")# 1.数据集切分x_data = data[features]y_data = data['power_load']# x_train:训练集特征数据# y_train:训练集目标数据# x_test:测试集特征数据# y_test:测试集目标数据x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.3, random_state=22)# # 2.网格化搜索与交叉验证# # 2.1备选的超参数# print("开始网格化搜索")# print(datetime.datetime.now()) # 2024-11-26 15:38:26.898828# param_dict = {# 'n_estimators': [50, 100, 150, 200],# 'max_depth': [3, 6, 9],# 'learning_rate': [0.1, 0.01]# }# # 2.2实例化网格化搜索,配置交叉验证# grid_cv = GridSearchCV(estimator=XGBRegressor(),# param_grid=param_dict, cv=5)# # 2.3网格化搜索与交叉验证训练# grid_cv.fit(x_train, y_train)# # 2.4输出最优的超参数组合# print(grid_cv.best_params_) # {'learning_rate': 0.1, 'max_depth': 6, 'n_estimators': 150}# print("结束网格化搜索")# print(datetime.datetime.now()) # 2024-11-26 15:39:07.216048# logger.info("网格化搜索后找到的最优的超参数组合是:learning_rate: 0.1, max_depth: 6, n_estimators: 150")# 3.模型训练xgb = XGBRegressor(n_estimators=150, max_depth=6, learning_rate=0.1)xgb.fit(x_train, y_train)# 4.模型评价# 4.1模型在训练集上的预测结果y_pred_train = xgb.predict(x_train)# 4.2模型在测试集上的预测结果y_pred_test = xgb.predict(x_test)# 4.3模型在训练集上的MSE、MAPEmse_train = mean_squared_error(y_true=y_train, y_pred=y_pred_train)mae_train = mean_absolute_error(y_true=y_train, y_pred=y_pred_train)print(f"模型在训练集上的均方误差:{mse_train}")print(f"模型在训练集上的平均绝对误差:{mae_train}")# 4.4模型在测试集上的MSE、MAPEmse_test = mean_squared_error(y_true=y_test, y_pred=y_pred_test)mae_test = mean_absolute_error(y_true=y_test, y_pred=y_pred_test)print(f"模型在测试集上的均方误差:{mse_test}")print(f"模型在测试集上的平均绝对误差:{mae_test}")logger.info("=========================模型训练完成=============================")logger.info(f"模型在训练集上的均方误差:{mse_train}")logger.info(f"模型在训练集上的平均绝对误差:{mae_train}")logger.info(f"模型在测试集上的均方误差:{mse_test}")logger.info(f"模型在测试集上的平均绝对误差:{mae_test}")# 5.模型保存joblib.dump(xgb, '../model/xgb.pkl')class PowerLoadModel(object):def __init__(self, filename):# 配置日志记录logfile_name = "train_" + datetime.datetime.now().strftime('%Y%m%d%H%M%S')self.logfile = Logger('../', logfile_name).get_logger()# 获取数据源self.data_source = data_preprocessing(filename)if __name__ == '__main__':file=r'D:\data\train.csv'# power_data(data)model = PowerLoadModel(file)# 2.分析数据power_data(model.data_source)# 3.特征工程processed_data, feature_cols = feature_engineering(model.data_source, model.logfile)# 4.模型训练、模型评价与模型保存model_train(processed_data, feature_cols, model.logfile)
(二)模型预测(predict.py)
# -*- coding: utf-8 -*-
import os
import pandas as pd
import numpy as np
import datetime
from utils.log import Logger
from utils.common import data_preprocessing
from sklearn.metrics import mean_absolute_error
import matplotlib.ticker as mick
import joblib
import matplotlib.pyplot as pltplt.rcParams['font.family'] = 'SimHei'
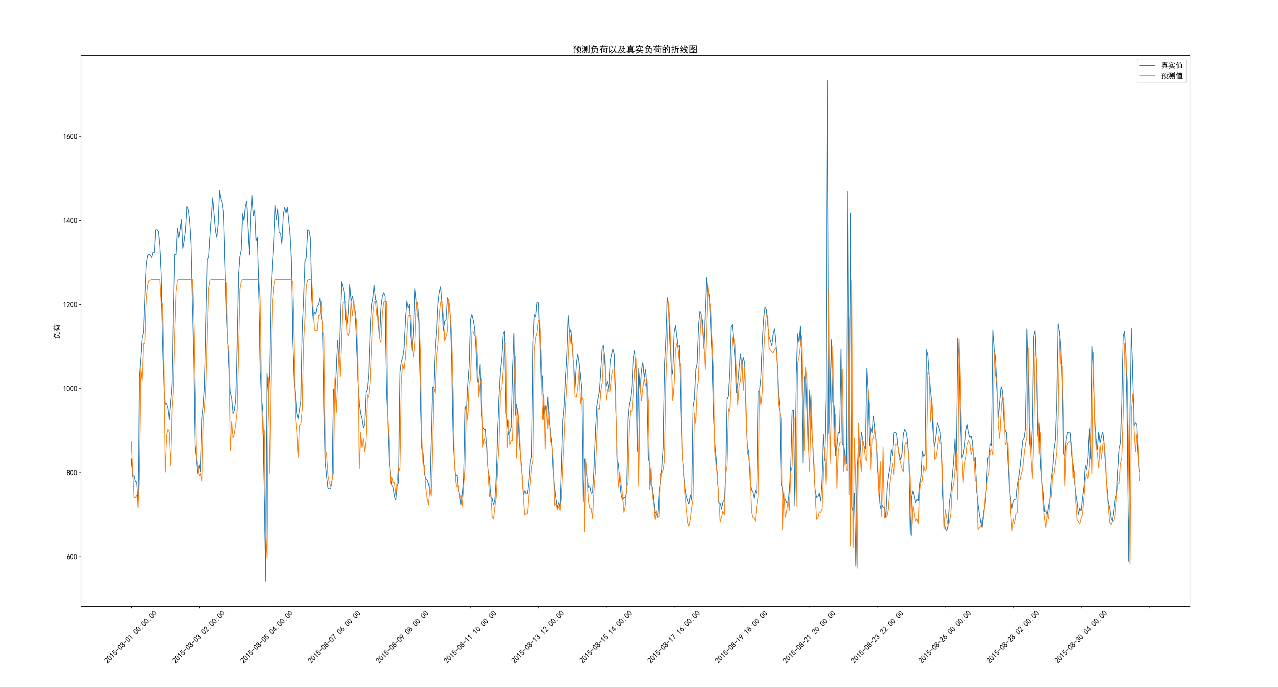
plt.rcParams['font.size'] = 15def pred_feature_extract(data_dict, time, logger):"""预测数据解析特征,保持与模型训练时的特征列名一致1.解析时间特征2.解析时间窗口特征3.解析昨日同时刻特征:param data_dict:历史数据,字典格式,key:时间,value:负荷:param time:预测时间,字符串类型,格式为2024-12-20 09:00:00:param logger:日志对象:return:"""logger.info(f'=========解析预测时间为:{time}所对应的特征==============')# 特征列清单feature_names = ['hour_0', 'hour_1', 'hour_2', 'hour_3', 'hour_4', 'hour_5','hour_6', 'hour_7', 'hour_8', 'hour_9', 'hour_10', 'hour_11','hour_12', 'hour_13', 'hour_14', 'hour_15', 'hour_16', 'hour_17','hour_18', 'hour_19', 'hour_20', 'hour_21', 'hour_22', 'hour_23','month_1', 'month_2', 'month_3', 'month_4', 'month_5', 'month_6','month_7', 'month_8', 'month_9', 'month_10', 'month_11', 'month_12','前1小时', '前2小时', '前3小时', 'yesterday_load']# 小时特征数据,使用列表保存起来hour_part = []pred_hour =pd.to_datetime(time).hourprint(pred_hour)for i in range(24):if pred_hour == feature_names[i][5:7]:hour_part.append(1)else:hour_part.append(0)# 月份特征数据,使用列表保存起来month_part = []pred_month = pd.to_datetime(time).monthfor i in range(24, 36):if pred_month == feature_names[i][6:8]:month_part.append(1)else:month_part.append(0)# 历史负荷数据,使用列表保存起来his_part = []# 前1小时负荷last_1h_time = (pd.to_datetime(time) - pd.to_timedelta('1h')).strftime('%Y-%m-%d %H:%M:%S')last_1h_load = data_dict.get(last_1h_time, 600)# 前2小时负荷last_2h_time = (pd.to_datetime(time) - pd.to_timedelta('2h')).strftime('%Y-%m-%d %H:%M:%S')last_2h_load = data_dict.get(last_2h_time, 600)# 前3小时负荷last_3h_time = (pd.to_datetime(time) - pd.to_timedelta('3h')).strftime('%Y-%m-%d %H:%M:%S')last_3h_load = data_dict.get(last_3h_time, 600)# 昨日同时刻负荷last_day_time = (pd.to_datetime(time) - pd.to_timedelta('1d')).strftime('%Y-%m-%d %H:%M:%S')last_day_load = data_dict.get(last_day_time, 600)his_part = [last_1h_load, last_2h_load, last_3h_load, last_day_load]# 特征数据,包含小时特征数据,月份特征数据,历史负荷数据feature_list = [hour_part + month_part + his_part]# feature_list需要转成dataframe并返回,所以这里用append变成一个二维列表feature_df = pd.DataFrame(feature_list, columns=feature_names)return feature_df, feature_namesdef prediction_plot(data):"""绘制时间与预测负荷折线图,时间与真实负荷折线图,展示预测效果:param data: 数据一共有三列:时间、真实值、预测值:return:"""# 绘制在新数据下fig = plt.figure(figsize=(40, 20))ax = fig.add_subplot()# 绘制时间与真实负荷的折线图ax.plot(data['时间'], data['真实值'], label='真实值')# 绘制时间与预测负荷的折线图ax.plot(data['时间'], data['预测值'], label='预测值')ax.set_ylabel('负荷')ax.set_title('预测负荷以及真实负荷的折线图')# 横坐标时间若不处理太过密集,这里调大时间展示的间隔ax.xaxis.set_major_locator(mick.MultipleLocator(50))# 时间展示时旋转45度plt.xticks(rotation=45)plt.legend()plt.savefig('../data/fig/预测效果.png')class PowerLoadPredict(object):def __init__(self, filename):# 配置日志记录logfile_name = "predict_" + datetime.datetime.now().strftime('%Y%m%d%H%M%S')self.logfile = Logger('../', logfile_name).get_logger()# 获取数据源self.data_source = data_preprocessing(filename)# 历史数据转为字典,key:时间,value:负荷,目的是为了避免频繁操作dataframe,提高效率。实际开发场景中可以使用redis进行缓存self.data_dict = self.data_source.set_index('time')['power_load'].to_dict()if __name__ == '__main__':"""模型预测1.导包、配置绘图字体2.定义电力负荷预测类,配置日志,获取数据源、历史数据转为字典(避免频繁操作dataframe,提高效率)3.加载模型4.模型预测4.1 确定要预测的时间段(2015-08-01 00:00:00及以后的时间)4.2 为了模拟实际场景的预测,把要预测的时间以及以后的负荷都掩盖掉,因此新建一个数据字典,只保存预测时间以前的数据字典4.3 预测负荷4.3.1 解析特征(定义解析特征方法)4.3.2 利用加载的模型预测4.4 保存预测时间对应的真实负荷4.5 结果保存到evaluate_list,三个元素分别是预测时间、真实负荷、预测负荷,方便后续进行预测结果评价4.6 循环结束后,evaluate_list转为DataFrame5.预测结果评价5.1 计算预测结果与真实结果的MAE5.2 绘制折线图(预测时间-真实负荷折线图,预测时间-预测负荷折线图),查看预测效果 """# 2.定义电力负荷预测类(PowerLoadPredict),配置日志,获取数据源、历史数据转为字典(避免频繁操作dataframe,提高效率)input_file = r'D:\data\test.csv'pred_obj = PowerLoadPredict(input_file)# 3.加载模型model = joblib.load('../model/xgb.pkl')# 4.模型预测evaluate_list = []# 4.1确定要预测的时间段:2015-08-01 00:00:00及以后的时间pred_times = pred_obj.data_source[pred_obj.data_source['time'] >= '2015-08-01 00:00:00']['time']print(pred_times)print(type(pred_times))for pred_time in pred_times:print(f"开始预测时间为:{pred_time}的负荷")pred_obj.logfile.info(f"开始预测时间为:{pred_time}的负荷")# 4.2为了模拟实际场景的预测,把要预测的时间以及以后的负荷都掩盖掉,因此新建一个数据字典,只保存预测时间以前的数据字典data_his_dict = {k: v for k, v in pred_obj.data_dict.items() if k < pred_time}# 4.3预测负荷# 4.3.1解析特征processed_data, feature_cols = pred_feature_extract(data_his_dict, pred_time, pred_obj.logfile)print(type(processed_data))print(type(feature_cols))print(processed_data)print(feature_cols)# 4.3.2 模型预测pred_value = model.predict(processed_data[feature_cols])# 4.4真实负荷true_value = pred_obj.data_dict.get(pred_time)pred_obj.logfile.info(f"真实负荷为:{true_value}, 预测负荷为:{pred_value}")# 4.5结果保存到evaluate_list,三个元素分别是预测时间、真实负荷、预测负荷evaluate_list.append([pred_time, true_value, pred_value[0]])# 4.6evaluate_list转为DataFrameevaluate_df = pd.DataFrame(evaluate_list, columns=['时间', '真实值', '预测值'])# 5.预测结果评价# 5.1计算预测结果与真实结果的MAEmae_score = mean_absolute_error(evaluate_df['真实值'], evaluate_df['预测值'])print(f"模型对新数据进行预测的平均绝对误差:{mae_score}")pred_obj.logfile.info(f"模型对新数据进行预测的平均绝对误差:{mae_score}")# 5.2绘制折线图,查看预测效果prediction_plot(evaluate_df)plt.show()
四、代码整体:
备注:data里的train和test数据另存了位置,所以上面data文件里没有。
五、最终运行生成图像
(一)负荷分析图
(二)预测效果图
今天的分享到此结束。

)






)






)

Step-Back 回答回退策略扩大检索范围)

