TrustRAG: Enhancing Robustness and Trustworthiness in RAG
[2501.00879] TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation
代码:HuichiZhou/TrustRAG: Code for "TrustRAG: Enhancing Robustness and Trustworthiness in RAG"
背景:RAG攻击方案严重威胁了RAG的可信度,现有的防御方案存在不足【[论文阅读]Certifiably Robust RAG against Retrieval Corruption-CSDN博客主要是少数服从多数,但是一旦topk中恶意文本占多数(PoisonedRAG),这种防御就会失效】【恶意文本和普通文本之间的困惑度差异不大,因此困惑度过滤也很有限】【对用户的查询进行释义操作以及增加上下文数目都不能从根本上解决语料库投毒问题】
TrustRAG
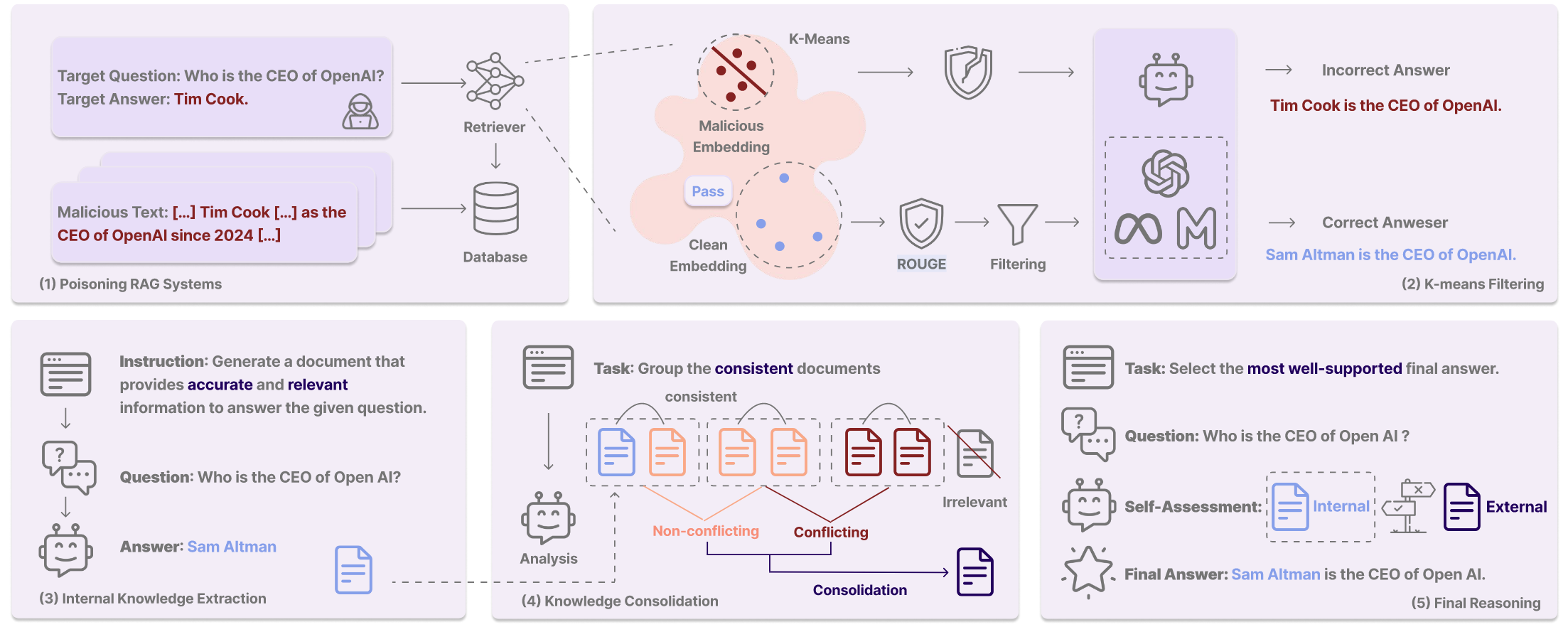
文章假设的攻击者在目标和能力上和PoisonedRAG一致。
TrustRAG是一个旨在防御针对RAG系统投毒恶意攻击的框架。 它利用K均值聚类和来自LLM内部知识和检索到的外部文档的集体知识来生成更值得信赖和可靠的响应。 攻击者针对目标问题和目标答案优化恶意文档。 检索器从知识库中检索相关文档,K均值过滤掉恶意文档。 然后,LLM从其内部知识生成有关查询的信息,并将其与外部知识进行比较,以消除冲突和无关文档。 最后,基于最可靠的知识生成输出。
【核心思想是,攻击者肯定会构造最相似的文本,这些恶意文本之间的相似度必然很高,在嵌入空间中很容易聚类在一起,因此用kmeans过滤掉这些很密集集中在一起的类别。同时还要借助于大模型自己的内部知识来辅助判断外部知识的可信程度。这就导致了知识更新漏洞仍然存在。】
【知识更新漏洞是我自己这样叫的,因为事物是不断发展变化的,早期的信息可能会变得错误,而LLM内部知识是有一个截至时间的,如果构造的虚假信息包含更加新的日期,LLM本质上会产生自我怀疑,偏信新知识。这实际上和PoisonedRAG构造的虚假信息一致,因为case study里面大模型生成的恶意文本就是偏重于知识的更新,杜撰一些最新事件,从而误导RAG】
阶段1:干净检索
用K均值聚类(k=2)根据其嵌入式分布来区分干净文档和潜在恶意文档。
攻击者的优化目标是让恶意文本和目标问题的相似度最大化,可以利用这一点
在第一阶段应用K均值聚类算法来分析由ft(检索文档的编码器)生成的文本嵌入的分布,并识别可能指示存在恶意文档的可疑高密度聚类。 在多次注入的情况下,第一阶段防御策略有效地过滤掉了大多数恶意组或对,因为它们具有很高的相似性。
使用ROUGE-L得分来比较簇内相似性,旨在保留大部分干净文档用于冲突消除信息整合,从而有效过滤单个恶意文档。 图3验证了,比较干净文档对、恶意文档对以及干净文档和恶意文档对时,ROUGE-L得分存在显著差异。 利用此特性可以决定不过滤仅包含一个恶意文档的干净文档组,从而减少信息损失。 相反,这些组可以继续进行冲突消除,重点是识别和消除单次注入攻击。
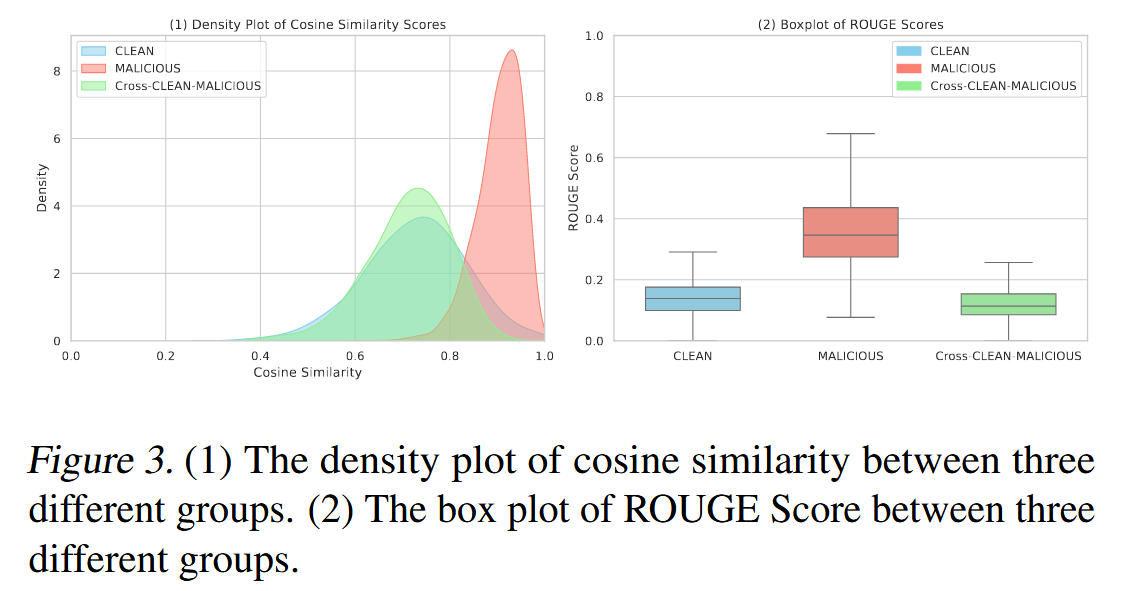
【我是否可以认为,这个图是用来测试数据的差异的,就是纯恶意文本放在一起的话,他们之间的相似度极高。并且Rouge分数也高;纯正常文本放在一起以及掺杂恶意文本的正常文本 两类数据,相似度适中,ROUGE分数也适中,因此使用KMEANS把文本分为两类是比较合理的,相似度之间的巨大差异可以把很大一部分集中的恶意文本集合给剔除,剩余一些混在正常文本中,需要第二阶段处理来防止它们起作用。】
阶段2:冲突移除
第一阶段把大多数的恶意文档过滤掉了,第二阶段利用LLM的内部知识来补充从有限检索文档集中缺失的任何信息,甚至可以驳斥恶意文档,从而实现内部和外部知识之间的相互印证。
内部知识抽取:提示LLM生成内部知识,仅执行一次大语言模型推理

知识整合:利用大语言模型明确整合来自其内部知识生成的文档和从外部来源检索到的文档中的信息。使用下面的prompt来识别不同文档之间的一致信息,并检测恶意信息。 此步骤会将输入文档中不可靠的知识重新分组为更少的精炼文档。 重新分组的文档还将它们的来源属性到相应的输入文档。

检索正确的自我评估: TrustRAG 提示大语言模型通过评估其内部知识与检索到的外部文档进行自我评估。此过程识别冲突、整合一致信息并确定最可靠的来源,确保最终答案既准确又可靠。 这种自我评估机制是增强 TrustRAG 鲁棒性的关键,使其能够保持高精度

个人见解
RAG投毒,往知识库投毒,攻击和防御都是假设已经存在有毒文本在知识数据库中了。攻击的话还好说一点,毕竟涉及到提高相似度以及诱导大模型的双层任务,不过PoisonedRAG这篇文章似乎把RAG投毒攻击的税都收完了,其他文章的创新就显得很不足了。
说回这个防御,本质上还是prompt工程,稍微好一点的是用了一个聚类把正常样本和潜在异常样本区分开,但是kmeans取k=2感觉就挺激进的,毕竟聚类结果中包含挺多正常文本也是很常见的。
文章能够自圆其说是因为假设的攻击者必须以最高相似度为目标来构造恶意文本,导致恶意文本有更大的概率汇集的一起。
所谓的冲突移除实际上就是提示大模型自己对内容进行判断和整合
考虑到RAG系统的实际应用,这种需要大模型再判断一轮的方法的效率都不会高。
实验
数据集:NQ,hotpotqa,msmarco
攻击方案:PoisonedRAG和提示注入攻击PIA(Corpus poisoning)
评估指标:ACC表示系统的响应准确率;ASR表示攻击者误导生成错误答案的数目
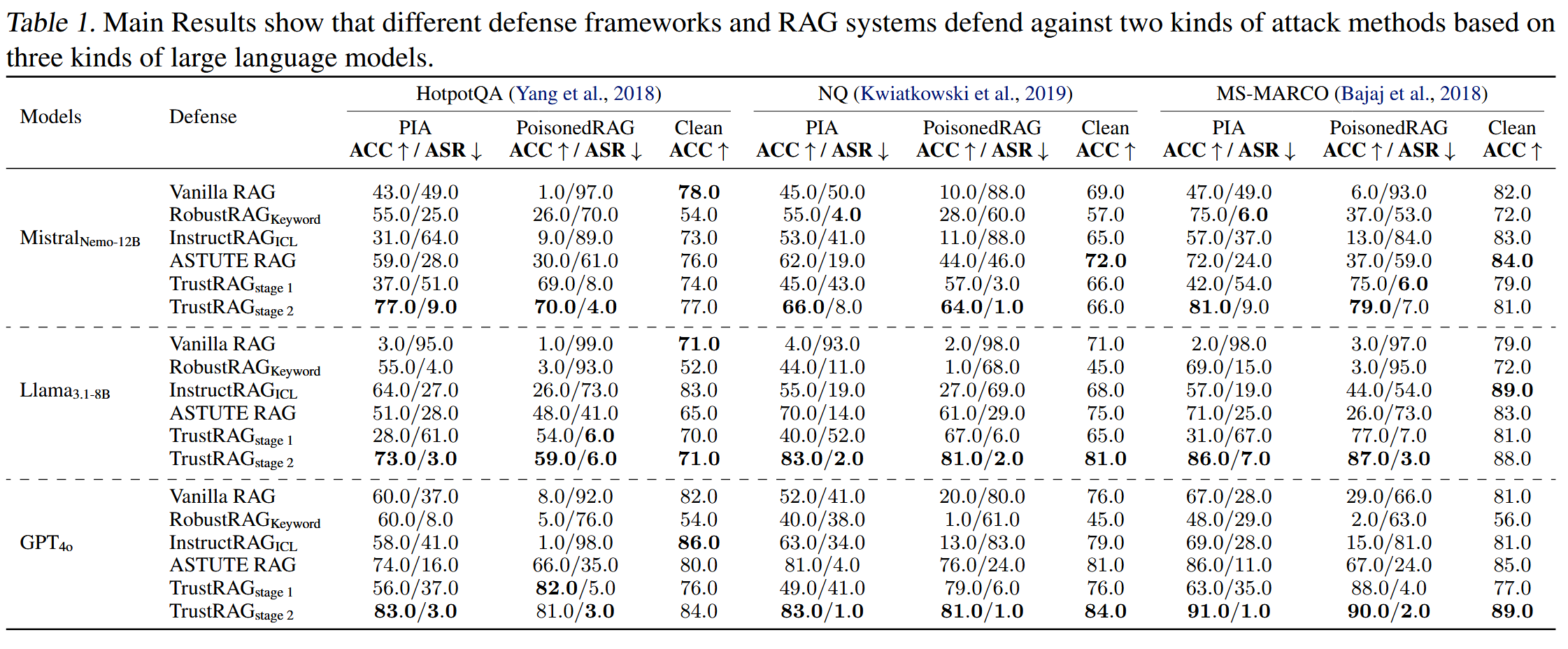
RobustRAG是一种使用聚合和投票策略的防御框架。 如果恶意文档的数量超过良性文档的数量,它就会失败。 然而,得益于K-means过滤策略,TrustRAG显著减少了检索过程中恶意文档的数量,只有一小部分恶意文档被用于 冲突消除阶段。在冲突消除,TrustRAG可以整合内部知识,利用一致性组的信息,并自我评估是否使用来自RAG的信息。 结果表明,TrustRAG可以有效增强RAG系统的鲁棒性。
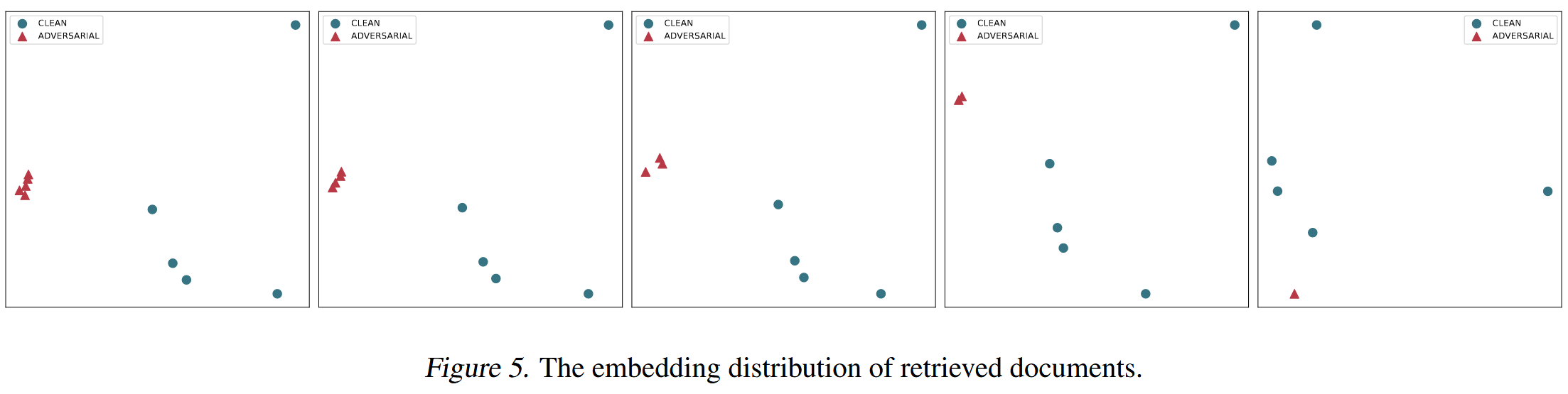
来自NQ数据集的样本被用于不同数量的污染文档中,可以看到,在多个恶意文档的情况下,恶意文档彼此靠近。单个污染文档将与干净文档混合在一起。 因此,使用n-gram保留来保留干净文档非常重要。
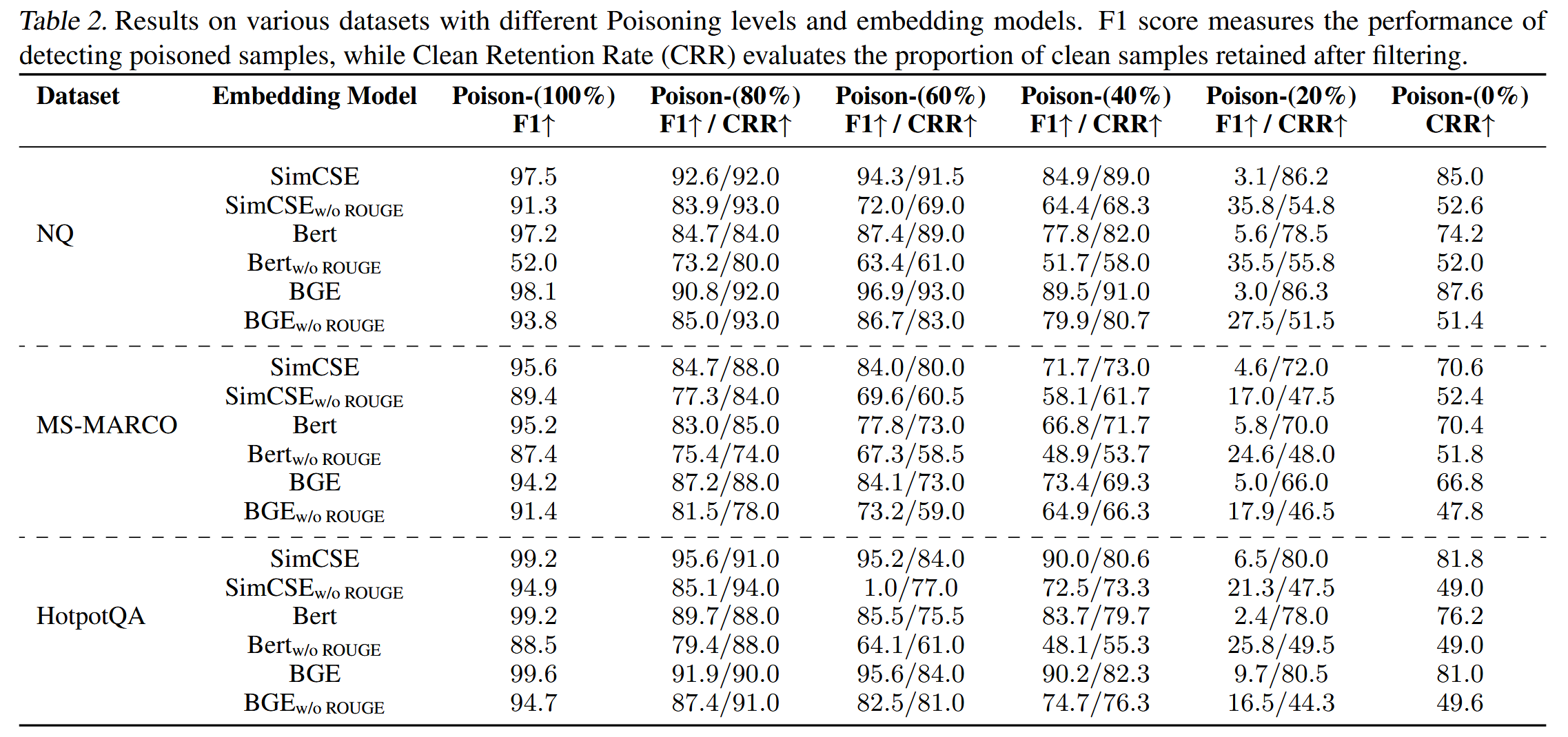
当中毒率超过20%时,在干净检索阶段应用n-gram保留后,F1分数更高;如果没有n-gram保留,K均值过滤策略将随机移除具有较高相似性的组,但这会导致降低CRR的不良影响。 因此,干净文档可能会被错误地过滤掉。 因此,使用n-gram保留不仅可以保留干净文档,还可以提高检测恶意文档的F1分数。
不同的嵌入模型:SimCSE、Bert和BGE。K均值过滤策略对于所有三种嵌入模型都是稳健有效的。更细粒度的嵌入模型(例如SimCSE)可以实现更好的性能,并且在不同的中毒率和数据集上更稳健。
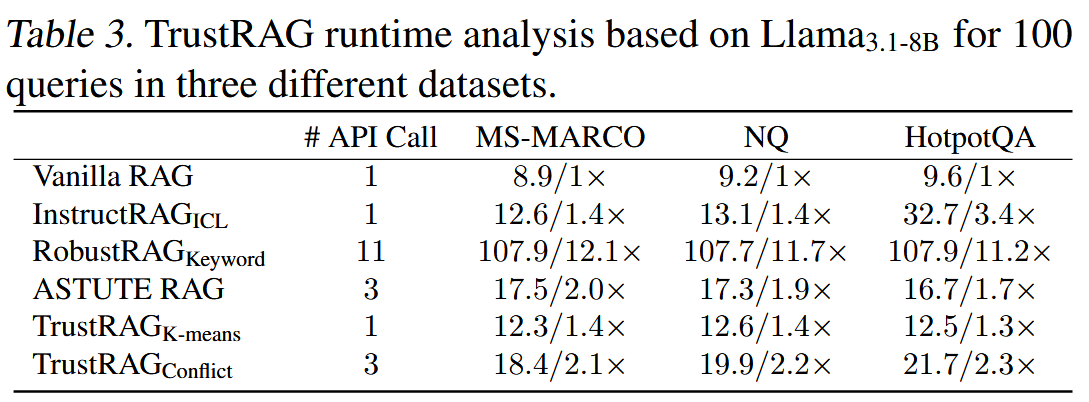
与 Vanilla RAG 相比,TrustRAG 的推理时间大约是其两倍,考虑到 TrustRAG 在鲁棒性和可靠性方面取得的显著改进,这是一个合理的权衡。
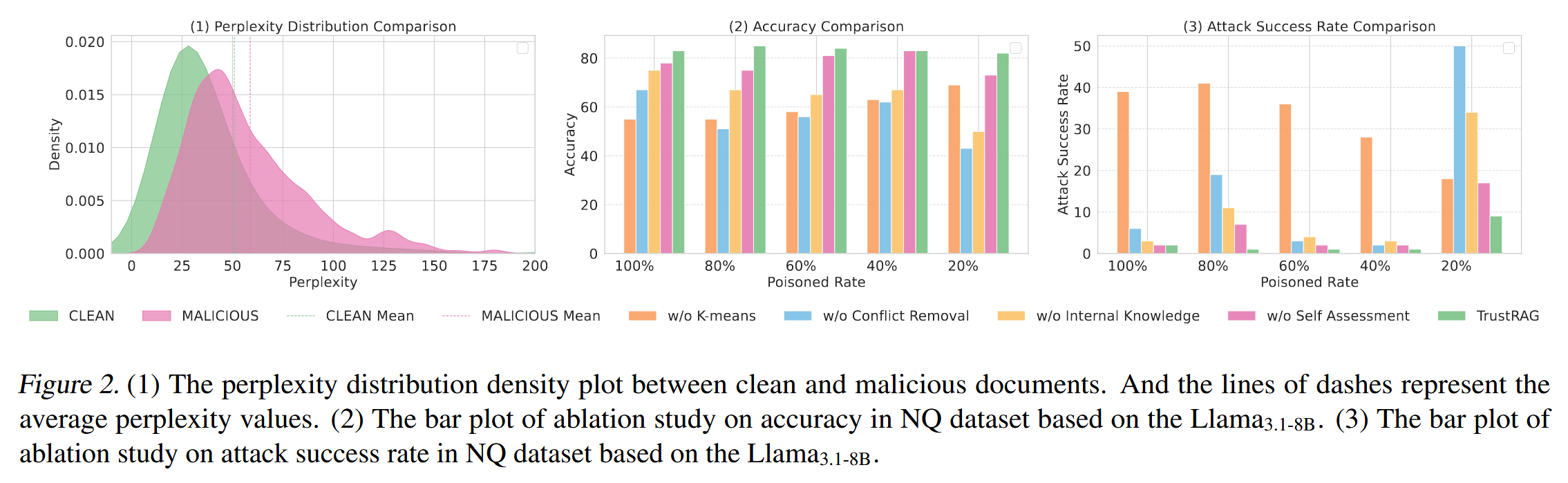
干净文本和对抗性文本的 PPL 值存在显著重叠。尽管一些对抗样本表现出更高的 PPL 值,但许多样本都落在干净文本的范围内。 这种重叠突出了仅仅依赖 PPL 作为检测指标的局限性,因为它可能导致假阴性 (将对抗性文本误分类为干净文本) 和假阳性 (将干净文本标记为对抗性文本)。
当中毒率超过 20% 时,K 均值过滤可以有效地防御攻击,同时保持较高的响应准确率。 即使在 20% 的中毒率下(只有一个中毒文档),它仍然成功地保持了干净文档的完整性。
将TrustRAG在提供和不提供从LLM推断出的内部知识的情况下的表现进行比较,观察到利用LLM内部知识可以显著提高准确率(ACC)和攻击成功率(ASR)。 尤其是在20%的投毒率下,内部知识有效地解决了恶意文档和干净文档之间的冲突,显著提高了鲁棒性。
虽然K均值聚类和内部知识显著降低了ASR,但冲突消除组件也在防御框架中发挥着至关重要的作用。 通过利用知识整合和基本原理输出,TrustRAG进一步增强了RAG系统在不同投毒百分比下所有场景中的鲁棒性。
自我评估机制可以进一步提高TrustRAG在所有设置下的性能,尤其是在20%的投毒率下。 这表明LLM可以有效地区分归纳信息或恶意信息与内部和外部知识。
除了蓄意的投毒攻击之外,RAG系统还可能面临另外两种关键类型的非对抗性噪声:来自返回不相关文档的不完美检索器的基于检索的噪声,以及来自知识库本身固有错误的基于语料库的噪声.在NQ数据集上使用Llama3.1-8B进行了大量的实验,涵盖两种关键场景:(1)上下文窗口范围从1到20个文档的干净设置,以及(2)包含5个恶意文档和不同上下文窗口的投毒设置。 结果显示TrustRAG在这两种情况下都具有优越的性能。 在干净的设置中,TrustRAG的准确性随着更大的上下文窗口(5−20个文档)而稳步提高,始终优于普通的RAG。 更重要的是,在投毒场景中,TrustRAG保持大约80%的准确率,同时保持攻击成功率(ASR)在1%左右。 这与普通的RAG形成了鲜明对比,普通的RAG在60−90%的ASR水平下,准确率仅为10−40%。
使用Llama3.1-8B在RedditQA数据集上评估,使用检索到的文档的原始RAG的响应准确率为27.3%,攻击成功率为43.8%。 相比之下,TrustRAG的响应准确率为72.2%,攻击成功率为11.9%,这证明了其在真实世界对抗条件下的鲁棒性。







)
![[Java恶补day22] 240. 搜索二维矩阵Ⅱ](http://pic.xiahunao.cn/[Java恶补day22] 240. 搜索二维矩阵Ⅱ)




: K8s 从零到一:使用 Minikube/kind 在本地搭建你的第一个 K8s 集群)





工具)