整合了以下五大核心技术:R-Drop、PGM 对抗训练、EMA、标签平滑、CosineAnnealing 学习率调度。
1. R-Drop(Regularized Dropout)
原理:同一个样本做两次前向传播(同 dropout mask),计算两次输出的 KL 散度,作为正则项加入损失中。
目标:增强鲁棒性,提升泛化能力。
损失组合:
loss = CrossEntropy(logits1, labels) + CrossEntropy(logits2, labels) + α * KL(logits1 || logits2)
2. PGM(Projected Gradient Method)对抗训练
机制:
在词嵌入空间中添加扰动,制造“敌意样本”。
多步迭代(PGM_STEPS=3),每步计算扰动梯度并累积。
作用:
增强模型对小扰动的鲁棒性,提高对抗泛化能力。
干预时机:在每次主 loss 反向传播后注入对抗 loss 的梯度。
3. EMA(Exponential Moving Average)
思路:
模型参数滑动平均(shadow weights),推理时使用这些平滑参数。
核心优势:
抑制训练波动、缓解过拟合、稳定收敛。
4. 标签平滑(Label Smoothing)
方式:将 one-hot 标签略微“平滑”,防止模型过度自信。
具体值:label_smoothing=0.1
结果:能缓解过拟合、提升模型稳定性。
5. Cosine Annealing 学习率衰减
调度策略:余弦退火(cosine),带 warmup。
优势:
前期快速学习,后期逐步收敛;适合 fine-tuning 场景。
模型训练流程
Trainer 子类化:自定义 AdvancedTrainer,重载 compute_loss 以支持双前向(R-Drop)训练。
Callbacks 集成:
PGMCallback:注入多步对抗扰动。
EmaCallback:更新并应用 shadow 参数。
EarlyStoppingCallback:监控 f1,连续 3 轮无改进则提前停止。
总体优势
多重正则和鲁棒性增强机制叠加,极大提升模型泛化能力和抗干扰能力。
适合工业级 NLP 分类任务的强化训练。
代码
# Advanced RoBERTa Sentiment Classifier with R-Drop + PGM + EMA + LabelSmoothing + CosineAnnealingimport os
import numpy as np
import torch
import torch.nn as nn
from transformers import (AutoTokenizer,AutoModelForSequenceClassification,Trainer,TrainingArguments,DataCollatorWithPadding,set_seed,EarlyStoppingCallback,TrainerCallback
)
from datasets import load_dataset
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score# 固定随机种子
set_seed(42)# 配置参数
MODEL_NAME = "roberta-base"
NUM_LABELS = 2
R_DROP_ALPHA = 5.0
LABEL_SMOOTHING = 0.1
PGM_EPSILON = 1.0
PGM_ALPHA = 0.3
# --- PGM 多步迭代次数 ---
PGM_STEPS = 3 # 例如,迭代 3 次来生成对抗扰动
EMA_DECAY = 0.999
# 加载数据
dataset = load_dataset("imdb")
train_dataset = dataset["train"]
test_dataset = dataset["test"]# Tokenizer
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)def preprocess_function(examples):return tokenizer(examples["text"], truncation=True)train_dataset = train_dataset.map(preprocess_function, batched=True)
test_dataset = test_dataset.map(preprocess_function, batched=True)# 数据整理器
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)# 加载模型
model = AutoModelForSequenceClassification.from_pretrained(MODEL_NAME, num_labels=NUM_LABELS
)# --- R-Drop Loss ---
class RDropLoss(nn.Module):def __init__(self, alpha=1.0, label_smoothing=0.0):super().__init__()self.alpha = alphaself.ce = nn.CrossEntropyLoss(label_smoothing=label_smoothing)self.kl = nn.KLDivLoss(reduction="batchmean")def forward(self, logits1, logits2, labels):ce_loss1 = self.ce(logits1, labels)ce_loss2 = self.ce(logits2, labels)ce_loss = 0.5 * (ce_loss1 + ce_loss2)p = torch.log_softmax(logits1, dim=-1)q = torch.log_softmax(logits2, dim=-1)p_softmax = torch.softmax(logits1, dim=-1)q_softmax = torch.softmax(logits2, dim=-1)kl_loss = 0.5 * (self.kl(p, q_softmax) + self.kl(q, p_softmax))return ce_loss + self.alpha * kl_loss# --- PGM ---
class PGM:def __init__(self, model, epsilon=1.0, alpha=0.3, emb_name='embeddings.word_embeddings'):self.model = modelself.epsilon = epsilonself.alpha = alphaself.emb_name = emb_nameself.backup = {}
# 扰动词嵌入可以被理解为在原始单词的语义空间中进行微小的“移动”,
# 使其略微偏离原来的意义,但又不至于完全改变其含义,从而模拟“对抗性样本”。def attack(self, is_first_attack=False):for name, param in self.model.named_parameters():if param.requires_grad and self.emb_name in name and param.grad is not None:if is_first_attack:self.backup[name] = param.data.clone()norm = torch.norm(param.grad)if norm != 0:r_at = self.alpha * param.grad / normparam.data.add_(r_at)param.data = self.project(name, param.data, self.backup[name])def restore(self):for name, param in self.model.named_parameters():if name in self.backup:param.data = self.backup[name]self.backup = {}def project(self, param_name, param_data, param_backup):r = param_data - param_backupif torch.norm(r) > self.epsilon:r = self.epsilon * r / torch.norm(r)return param_backup + r# --- EMA ---
class EMA:def __init__(self, model, decay):self.model = modelself.decay = decayself.shadow = {}self.backup = {}def register(self):for name, param in self.model.named_parameters():if param.requires_grad:if name not in self.shadow:self.shadow[name] = param.data.clone()def update(self):for name, param in self.model.named_parameters():if param.requires_grad:if name not in self.shadow:continue # 保护:skip 未注册 param,避免 KeyErrornew_avg = (1.0 - self.decay) * param.data + self.decay * self.shadow[name]self.shadow[name] = new_avg.clone()def apply_shadow(self):for name, param in self.model.named_parameters():if param.requires_grad:if name not in self.shadow:continueself.backup[name] = param.data.clone()param.data = self.shadow[name]def restore(self):for name, param in self.model.named_parameters():if param.requires_grad:if name in self.backup:param.data = self.backup[name]self.backup = {}# --- Callbacks ---
class PGMCallback(TrainerCallback):def __init__(self, pgm, rdrop_loss_fn, pgm_steps=1):self.pgm = pgmself.rdrop_loss_fn = rdrop_loss_fnself.pgm_steps = pgm_steps # 对抗迭代步数def on_after_backward(self, args, state, control, model=None, inputs=None, optimizer=None, **kwargs):# 备份原始的梯度状态,以便在对抗训练结束后恢复# PyTorch 优化器在 step() 时会清零梯度,但我们需要在 PGM 内部操作时保留它们# 更安全的做法是使用一个更细粒度的梯度累积或在每次 PGM 迭代后清零# 为了简化,我们假设在这个回调中梯度是可用的# 开始多步 PGMfor step in range(self.pgm_steps):is_first_attack = (step == 0)# 在第一次攻击时备份参数并施加扰动# 在后续攻击时,只施加扰动,不备份self.pgm.attack(is_first_attack=is_first_attack)# 在扰动后的模型上进行前向传播# 这里需要确保模型处于训练模式,并且梯度是开启的model.train() # 确保模型处于训练模式model.zero_grad() # 在每次PGM步清零模型梯度adv_outputs1 = model(**{k: v for k, v in inputs.items() if k != "labels"})adv_outputs2 = model(**{k: v for k, v in inputs.items() if k != "labels"})adv_logits1 = adv_outputs1.logitsadv_logits2 = adv_outputs2.logitslabels = inputs["labels"]# 计算对抗损失adv_loss = self.rdrop_loss_fn(adv_logits1, adv_logits2, labels)# 对抗损失的反向传播# 注意:这里不能简单地直接调用 .backward()# 因为 Trainer 已经处理了主损失的梯度累积和优化器步骤# PGM 的梯度应该累积到主梯度中,而不是覆盖它们# 最简单的集成方式是让对抗损失也产生梯度,并累积到参数上# 在 Hugging Face Trainer 的 on_after_backward 中,# 已经进行了一次主损失的 backward,因此这里的 adv_loss.backward() 会累积梯度。# 但是,为了避免在多步中梯度累积不当,需要更细致的控制。# 通常,PGM 是在优化器步骤之前,对参数进行修改并重新计算损失。# --- 关键点:如何处理多步 PGM 的梯度 ---# 这里的 `adv_loss.backward()` 会计算并累积梯度。# 由于每次 `pgm.attack()` 都会修改参数,所以 `adv_loss` 都会基于当前扰动后的参数计算。# 在每次 `step` 中,我们计算 `adv_loss` 的梯度并累加到参数上。# 注意:`model.zero_grad()` 放在循环内部可以确保每次 PGM 步只计算当前扰动下的梯度,# 如果放在循环外部,则所有 PGM 步的梯度会累积到同一个梯度值上。# 这里设置为每次 PGM 步清零梯度,然后计算当前步的对抗梯度。# 这样做可以确保 `adv_loss.backward()` 每次计算的是相对于当前扰动参数的梯度。accelerator = kwargs.get("accelerator", None)if accelerator is not None:accelerator.backward(adv_loss)else:adv_loss.backward()# 多步 PGM 结束后,恢复模型参数到原始状态(即未被 PGM 扰动前的状态)self.pgm.restore()# 此时,model 的所有 param.grad 中已经包含了# (主损失的梯度) + (最后一次 PGM 迭代的对抗损失的梯度)# HuggingFace Trainer 会紧接着调用优化器的 step() 方法来更新模型的参数。#最终留下并用于优化器更新的梯度,是最后一次 PGM 迭代所产生的对抗损失的梯度。class EmaCallback(TrainerCallback):def __init__(self, ema):self.ema = emadef on_step_end(self, args, state, control, **kwargs):self.ema.update()def on_evaluate(self, args, state, control, **kwargs):self.ema.apply_shadow()def on_evaluate_end(self, args, state, control, **kwargs):self.ema.restore()# --- AdvancedTrainer ---
class AdvancedTrainer(Trainer):def __init__(self, *args, alpha=1.0, label_smoothing=0.0, ema=None, **kwargs):super().__init__(*args, **kwargs)self.rdrop_loss_fn = RDropLoss(alpha=alpha, label_smoothing=label_smoothing)self.ema = emaif self.ema is not None:self.ema.register()def compute_loss(self, model, inputs, return_outputs=False, **kwargs):labels = inputs["labels"]# 两次前向传播用于 R-Dropoutputs1 = model(**{k: v for k, v in inputs.items() if k != "labels"})outputs2 = model(**{k: v for k, v in inputs.items() if k != "labels"})logits1 = outputs1.logitslogits2 = outputs2.logitsloss = self.rdrop_loss_fn(logits1, logits2, labels)return (loss, outputs1) if return_outputs else loss# --- Metrics ---
def compute_metrics(eval_pred):logits, labels = eval_predprobs = torch.softmax(torch.tensor(logits), dim=-1).numpy()predictions = np.argmax(logits, axis=-1)acc = accuracy_score(labels, predictions)f1 = f1_score(labels, predictions)try:auc = roc_auc_score(labels, probs[:, 1])except:auc = 0.0return {"accuracy": acc, "f1": f1, "auc": auc}# --- TrainingArguments ---
training_args = TrainingArguments(output_dir="./results_adv_rdrop_pgm_ema_multistep", # 更改输出目录eval_strategy="epoch",save_strategy="epoch",learning_rate=2e-5,per_device_train_batch_size=16,per_device_eval_batch_size=16,num_train_epochs=5,weight_decay=0.01,warmup_ratio=0.1,lr_scheduler_type="cosine",logging_dir="./logs_adv_rdrop_pgm_ema_multistep", # 更改日志目录logging_steps=50,load_best_model_at_end=True,metric_for_best_model="f1",fp16=True,save_total_limit=2,
)# --- 初始化模块 ---
pgm = PGM(model, epsilon=PGM_EPSILON, alpha=PGM_ALPHA)
ema = EMA(model, decay=EMA_DECAY)# --- Trainer ---
trainer = AdvancedTrainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=test_dataset,tokenizer=tokenizer, # 使用 tokenizer 而不是 processing_classdata_collator=data_collator,compute_metrics=compute_metrics,alpha=R_DROP_ALPHA,label_smoothing=LABEL_SMOOTHING,callbacks=[PGMCallback(pgm=pgm, rdrop_loss_fn=RDropLoss(alpha=R_DROP_ALPHA, label_smoothing=LABEL_SMOOTHING), pgm_steps=PGM_STEPS),EmaCallback(ema=ema),EarlyStoppingCallback(early_stopping_patience=3, early_stopping_threshold=0.01),],
)# --- 训练 ---
trainer.train()# --- 评估 ---
trainer.evaluate()
结果
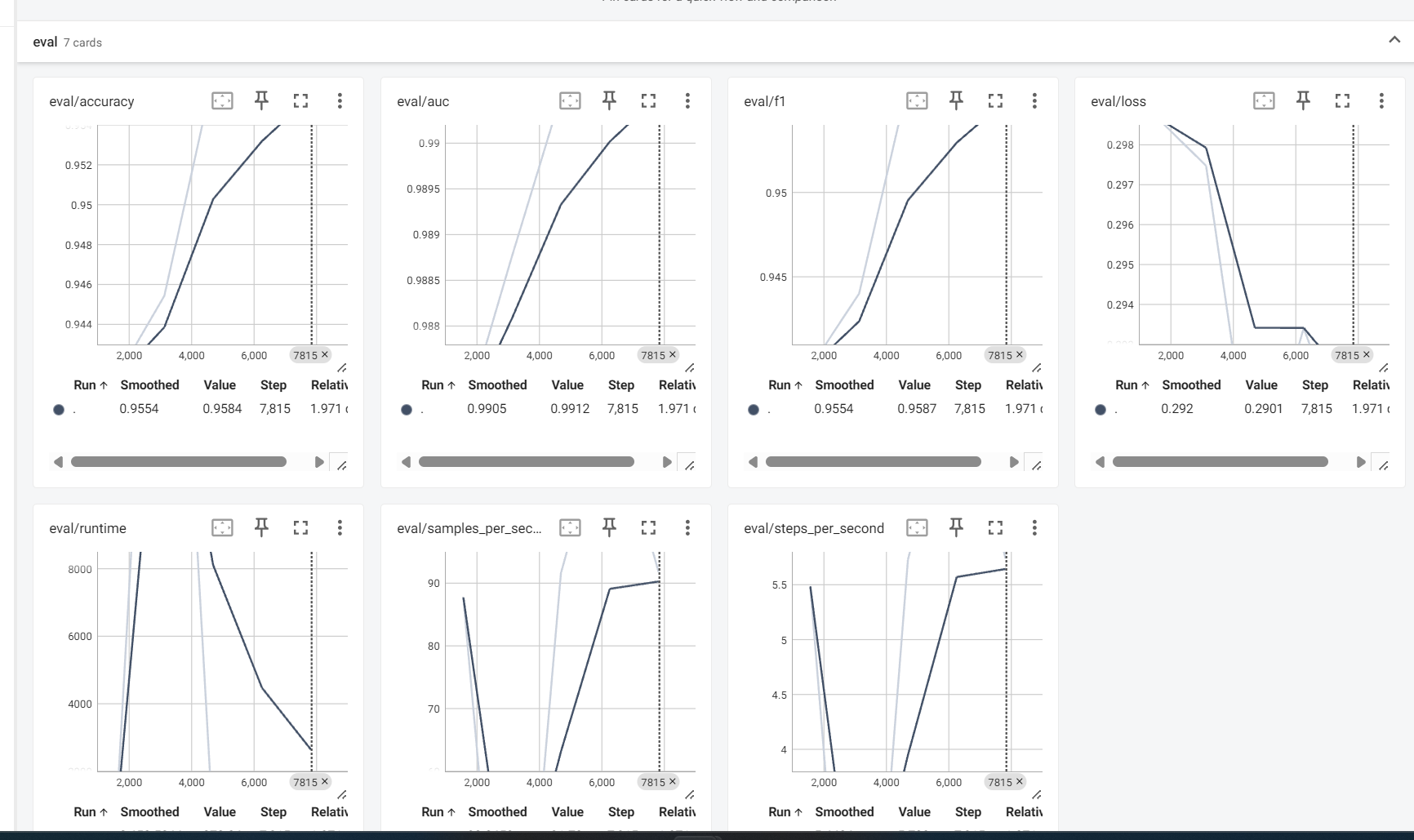
{'eval_loss': 0.2900645434856415, 'eval_accuracy': 0.95836, 'eval_f1': 0.9586822782298074, 'eval_auc': 0.9911689504000001, 'eval_runtime': 275.0978, 'eval_samples_per_second': 90.877, 'eval_steps_per_second': 5.682, 'epoch': 5.0}
{'train_runtime': 171019.0699, 'train_samples_per_second': 0.731, 'train_steps_per_second': 0.046, 'train_loss': 0.30841634256749756, 'epoch': 5.0}
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7815/7815 [47:30:19<00:00, 21.88s/it]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1563/1563 [04:32<00:00, 5.75it/s]
TensorBoard
注意
实际操作,这里要保存模型。还要转成ONNX模型,用C++ OnnxRuntime推理等等推理。












-----删除链表中指定值的节点)






自动曝光中Lv值的计算方式实现猜想)