目录
- 1. 序列化和反序列化
- 1.1 序列化
- 1.2 反序列化
- 2. 网络版本计算器(自定义协议)
- 3. 再次理解OSI七层模型
- 4. HTTP协议
- 4.1 HTTP协议格式
- 4.2 HTTP的方法
- 4.3 HTTP的状态码
- 4.4 HTTP常见Header
- 4.5 长连接和短连接
- 4.6 Cookie
- 5. HTTPS协议
- 5.1 对称加密和非对称加密概念
- 5.2 HTTPS:对称加密+非对称加密+证书认证
- 6. UDP协议
- 6.1 UDP协议的特点
- 6.2 UDP协议端格式
- 6.3 UDP有接收缓冲区,没有发送缓冲区。
- 7. TCP协议
- 7.1 TCP协议段格式
- 7.1.1 为什么一个TCP报文中同时需要序号和确认序号?
- 7.1.2 TCP为什么是面向字节流的,UDP是面向数据报呢?
- 7.2 确认应答(ACK)机制
- 7.3 超时重传机制
- 7.4 TCP三次握手
- 7.4.1 连接管理机制
- 7.4.2 为什么握手是三次
- 7.5 TCP 四次挥手
- 7.6 滑动窗口
- 7.6.1 滑动窗口的结构
- 7.6.2 快重传
- 7.7 延迟应答
- 7.7.1 延迟应答的概念
- 7.7.2 延迟应答的作用和触发条件
- 7.8 流量控制
- 7.9 拥塞控制
- 7.10 粘包问题
- 7.10 TCP的异常退出
1. 序列化和反序列化
序列化:value 对象 ——> str 字符串
1.1 序列化
函数原型:
作用:把 Json::Value 对象转化为 格式化的 JSON 字符串(有缩进、有换行)
namespace Json {class StyledWriter {public:std::string write(const Json::Value& root);};
}作用:把 Json::Value 对象转化为 紧凑的 JSON 字符串(无缩进、无换行)
namespace Json {class FastWriter {public:std::string write(const Json::Value& root);};
}
示例:
#include <iostream>
#include <string>
#include <jsoncpp/json/json.h>int main()
{int x=1, y=2; char op='/';Json::Value root;std::string str1;std::string str2;root["x"] = x;root["y"] = y;root["op"] = op;Json::FastWriter w1; //JSON紧凑写入器(无缩进、无换行)Json::StyledWriter w2; // JSON美化写入器(有缩进、有换行)str1 = w1.write(root); // 序列化str2 = w2.write(root); // 序列化std::cout << str1 << std::endl;std::cout<<std::endl;std::cout << str2 << std::endl;return 0;
}
输出:
{"x":1,"y":2,"op":"/"}{"x" : 1,"y" : 2,"op" : "/"
}
1.2 反序列化
反序列化:str 字符串 ——> value 对象
函数原型:
namespace Json {class Reader {public:bool parse(const std::string& document, Value& root, bool collectComments = true);};
}
示例:
std::string str="{"x" : 1,"y" : 2,"op" : "/"
}";
Json::Value root;
Json::Reader r;
r.parse(str, root); // 反序列化
2. 网络版本计算器(自定义协议)
源码如下:网络版本计算器
在博客里面就放了一个套接字封装和自定义协议,想看完整代码可以查看gitee源码。
Socket.hpp: 套接字封装
#pragma once
#include<iostream>
#include<sys/socket.h> //套接字函数(如:socket()...)
#include<netinet/in.h> //定义网络地址结构(如 struct sockaddr_in)和协议常量(如 AF_INET、SOCK_STREAM)
#include<arpa/inet.h> //IP 地址转换函数,字节序转换函数
#include<unistd.h>
#include<cstring>
#include<string>
#include<assert.h>
#include"Log.hpp" //TCP服务端:1. socket() → 2. bind() → 3. listen() → 4. accept() → 5. write()/read() → 6. close()
//TCP客户端:1. socket() → 2. connect() → 3. write()/read() → 4. close()//客户端比较于服务端来说,只有3个不同:
//1. 客户端不用自己绑定端口,系统自己绑定,即没有bind函数
//2. 服务端在连接之前还要listen
//3. 客户端:connect 服务端:accept//socket:直接得到两端的套接字
//connect:要服务端的所有信息 accept:得到客户端的所有信息 只有accept能得到新套接字(连接套接字)
//注意:write()/read()只需要一个套接字就行,而客户端还是用socket的那个套接字,而服务端必须用新套接字//主机序列,网络字节序的转化永远是int在转(指uint32_t/uint64_t),所以只有port才会转,才要转//使用说明:
//Sock listensock;
//listensock.Sock(); ... enum
{Socket_ERR=1,Bind_ERR,Listen_ERR,Accept_ERR,Close_ERR,Connect_ERR,
};//适用于TCP的客户端和服务端
class Sock
{private:int _socket;public:void Socket(){_socket=socket(AF_INET, SOCK_STREAM, 0);if(_socket<0){lg(Fatal,"socket error, _socket: %d。 %s",_socket,strerror(errno));exit(Socket_ERR);}}void Bind(uint16_t port){struct sockaddr_in address;address.sin_addr.s_addr=INADDR_ANY; address.sin_family=AF_INET;address.sin_port=htons(port);if(bind(_socket,(struct sockaddr*)&address,sizeof(address))<0){lg(Fatal,"bind error, _socket: %d。 %s",_socket,strerror(errno));exit(Bind_ERR);}}//服务端void Listen(){if(listen(_socket,10)){lg(Fatal,"listen error, _socket: %d。 %s",_socket,strerror(errno));exit(Listen_ERR);}}//服务端专业函数,返回连接套接字//可以得到客户端的信息,虽然这些信息不能对读写有任何帮助,然后需要打印出客户信息int Accept(std::string* clientip,uint16_t* clientport){ struct sockaddr_in tmp;memset(&tmp,0,sizeof(tmp));socklen_t len=sizeof(tmp);int newfd=accept(_socket,(sockaddr*)&tmp,&len);if(newfd<0){lg(Fatal,"accept error, _socket: %d; newfd: %d 。%s",_socket,newfd,strerror(errno));exit(Accept_ERR);}char ipstr[64];*clientport=ntohs(tmp.sin_port);inet_ntop(AF_INET, &tmp, ipstr,sizeof(ipstr));*clientip=ipstr;return newfd;}//客户端//需要服务端的信息bool Connect(const std::string &serverip,const uint16_t &serverport){sockaddr_in server;memset(&server,0,sizeof(server));server.sin_family=AF_INET;server.sin_port=htons(serverport);inet_pton(AF_INET,serverip.c_str(),&(server.sin_addr));socklen_t len=sizeof(server);if(connect(_socket,(sockaddr*)&server,len)<0){std::cerr << "connect to " << serverip << ":" << serverport << " error" << std::endl;return false; }return true;}void Close(){if(close(_socket)<0){exit(Close_ERR);}}int Fd(){return _socket;}
};
Protocol.hpp: 自定义协议
#pragma once
#include<string>
#include"json/json.h"//序列化,反序列化,编码,解码//使用说明:
//Request:
//Request req(data1,data2,op); req.Serialize(&str); //序列化, 通过data1,data2,op 得到了 str
//Request req; req.DeSerialize(str); //反序列化, 通过str 得到了 data1,data2,op//Response:
//Response rsp(result,code); rsp.Serialize(&str); //序列化, 通过result,code 得到了 str
//Response rsp; rsp.DeSerialize(str); //反序列化, 通过str 得到了 result,codeconst std::string protocol_sep = "\n";//编码: 发送的报文是:"内容长度" + 分隔符 + "原始内容" + 分隔符
void EnCode(const std::string& content,std::string *package)
{*package+=std::to_string(content.size());*package+=protocol_sep;*package+=content;*package+=protocol_sep;
}//解码
bool DeCode(std::string& package,std::string *content) //package可能会有两条内容或者半条内容
{//找分隔符auto pos=package.find(protocol_sep);if(pos==std::string::npos)return false;//提取内容长度std::string len_str =package.substr(0,pos);int len=std::stoi(len_str.c_str()); //内容长度//查看整个报文是否有一条报文的长度int total_len=len_str.size()+2+len;if(package.size()<total_len)return false;//提取len长度的内容*content=package.substr(pos+1,len);//package丢弃一条报文长度package.erase(0,total_len);return true;
}class Request
{public:int _data1;int _data2;char _op; //value不能有char类型,value中直接用int就行public:Request(int data1,int data2,char op):_data1(data1),_data2(data2),_op(op){}Request(){}// 用root(用类成员生成) 转成strbool Serialize(std::string* str){Json::Value root;root["data1"]=_data1;root["op"]=(int)_op;root["data2"]=_data2;Json::StyledWriter w;*str=w.write(root);return true;}// 已知的str 转成root(root可以完善类)bool DeSerialize(const std::string str){Json::Value root;Json::Reader r; r.parse(str,root);_data1=root["data1"].asInt();_data2=root["data2"].asInt();_op=root["op"].asInt();return true;}std::string GetRequest(){std::string quest;quest+=std::to_string(_data1);quest+=_op;quest+=std::to_string(_data2);quest+="=?";return quest;}};class Response
{public:int _result=0;int _code=0; // 0,可信,否则!0具体是几,表明对应的错误原因public:// 用root(用类成员生成) 转成strbool Serialize(std::string* str){Json::Value root;root["result"]=_result;root["code"]=_code;Json::StyledWriter w;*str=w.write(root);return true;}// 已知的str 转成root(root可以完善类)bool DeSerialize(const std::string str){Json::Value root;Json::Reader r; r.parse(str,root);_result=root["result"].asInt();_code=root["code"].asInt();return true;}std::string GetResult(){std::string ret;ret+="result: ";ret+=std::to_string(_result);ret+=" code: ";ret+=std::to_string(_code);return ret;}
};
3. 再次理解OSI七层模型
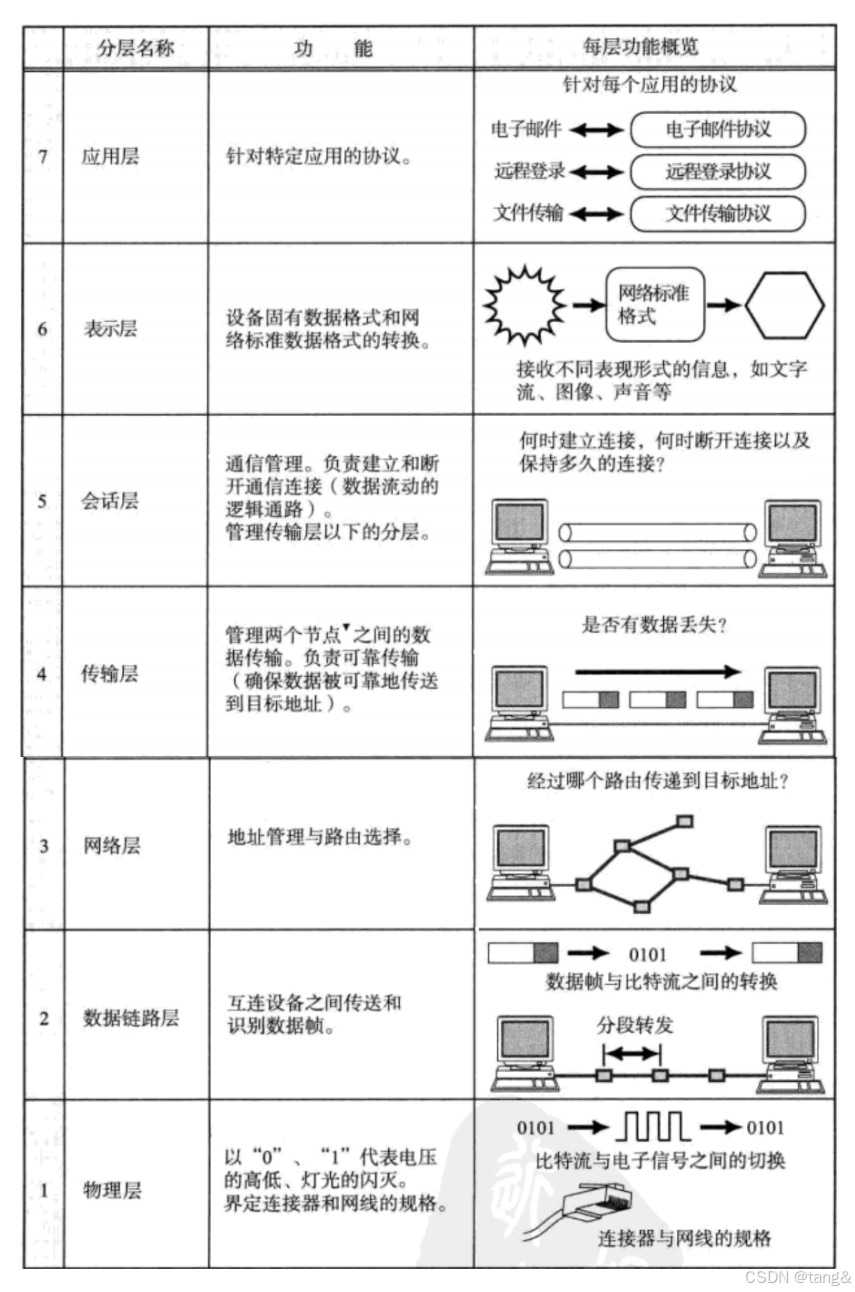
4. HTTP协议
4.1 HTTP协议格式
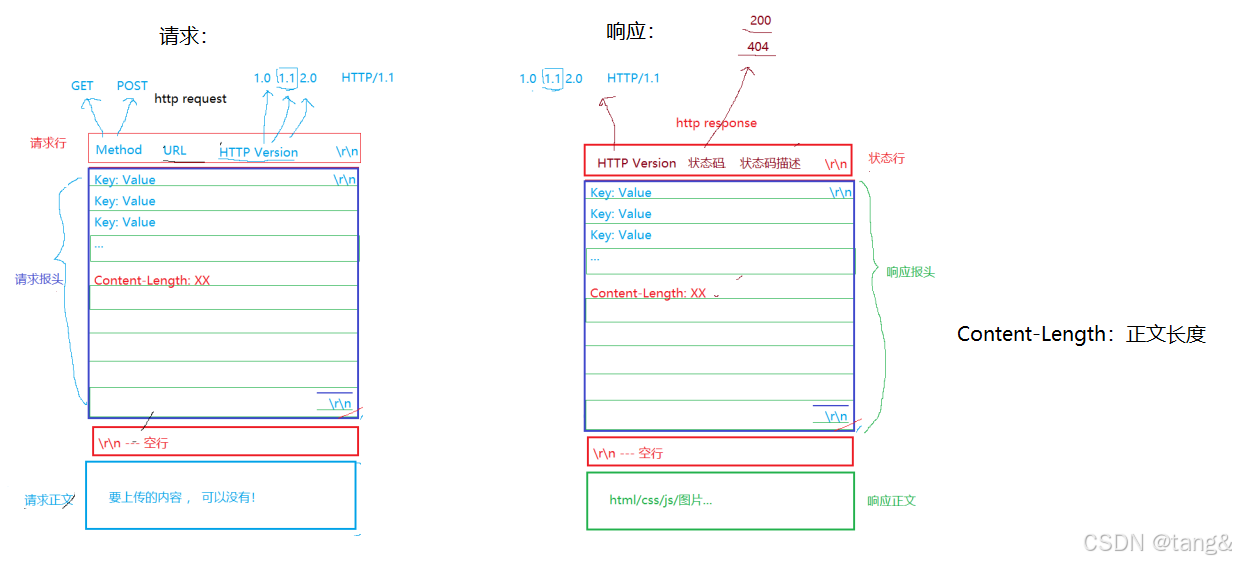
4.2 HTTP的方法
HTTP的方法最主要的就是GET 和 POST。
GET:用于请求数据(从服务器获取资源,如网页、图片、API数据)。
POST:用于提交数据(向服务器发送数据以创建或修改资源,如表单提交、文件上传)。
GET:
- 数据通过URL参数传递(附加在URL后,形如 ?key1=value1&key2=value2)。
- 数据可见(暴露在地址栏、浏览器历史、服务器日志中)。
- 有长度限制(受浏览器和服务器限制,通常不超过2048字符)。
POST
- 数据通过请求体(Request Body)传递。
- 数据不可见(不显示在URL中,适合敏感信息)。
- 无严格长度限制(可传输大量数据,如文件上传)
4.3 HTTP的状态码
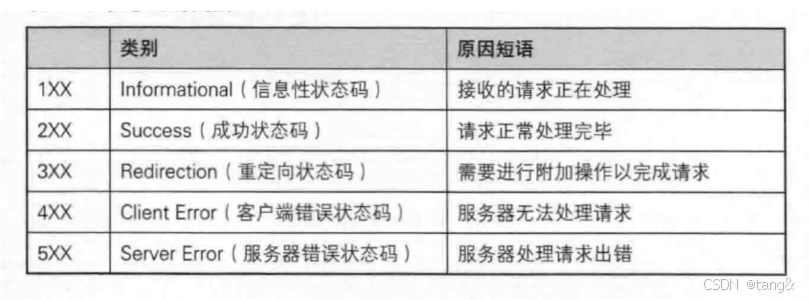
最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
4.4 HTTP常见Header
请求头(Request Headers)
客户端发送给服务器的头信息,用于告知服务器客户端的请求信息:
- Host
告诉服务器请求的资源所在的主机和端口(主机和端口是服务端的)(如 Host: www.example.com:443)。 - User-Agent
声明客户端的操作系统、浏览器版本等信息(如 User-Agent: Mozilla/5.0 (Windows NT 10.0))。 - Referer
表示当前请求是从哪个页面跳转过来的(如 Referer: https://www.google.com)。 - Cookie
客户端携带的Cookie数据,用于会话管理(如 Cookie: session_id=abc123)。
响应头(Response Headers)
服务器返回给客户端的头信息,用于控制客户端行为或补充响应内容:
- Content-Type
告知客户端返回数据的类型(如 Content-Type: text/html; charset=utf-8)。 - Content-Length
表示响应体的长度(字节数),如 Content-Length: 1024。 - Location
搭配 3xx重定向状态码,告诉客户端下一步跳转的URL(如 Location: /new-page)。
特殊情况说明
- Cookie 虽然是客户端发送的,但服务器也可以通过 Set-Cookie(响应头)让客户端存储Cookie。
- Content-Type 和 Content-Length 在极少数情况下也可能出现在请求头中(如POST请求提交数据时)。
4.5 长连接和短连接
短连接
特点:
1.每次请求-响应后关闭 TCP 连接。
2. 下次请求需重新建立连接(三次握手)。
3. HTTP/1.0 默认行为(除非显式设置 Connection: keep-alive)。
工作流程:
1.客户端发起请求 → TCP 三次握手建立连接。
2. 服务器返回响应。
3. 服务器主动关闭 TCP 连接(四次挥手)。
4. 后续请求重复步骤 1~3。
缺点
1.高延迟:每次请求需重新握手,增加 RTT(Round-Trip Time)时间。
2.资源浪费:频繁创建/销毁连接消耗 CPU 和内存。
3.性能瓶颈:不适合高频请求场景(如网页加载多个资源)。
适用场景
1.低频请求(如传统静态网页)。
2.无需保持状态的简单交互。
长连接
特点
1.复用 TCP 连接处理多个请求-响应。
2.默认在 HTTP/1.1 中启用(无需显式设置)。
3.通过 Connection: keep-alive 头部协商(HTTP/1.0 需手动开启)。
工作流程
1.客户端发起首次请求 → TCP 三次握手建立连接。
2.服务器返回响应,保持连接不关闭。
3.客户端复用同一 TCP 连接发送后续请求。
4.空闲一段时间后(超时时间由服务器设定),连接自动关闭。
优点
1.降低延迟:避免重复握手(尤其 HTTPS 的 TLS 握手更耗时)。
2.减少资源消耗:复用连接减少 CPU/内存开销。
3.提升吞吐量:适合高频请求(如现代网页加载 JS/CSS/图片)。
适用场景
1.高频请求(如 API 调用、动态网页)。
2.需要低延迟的交互(如 WebSocket 前置握手)。
Connection (请求头和响应头)
Connection 是一个 HTTP 请求头(Request Header)和响应头(Response Header),用于控制当前 TCP 连接的行为,尤其是决定是否保持长连接(Keep-Alive)。
- 客户端请求头:
客户端通过 Connection 头告知服务器是否希望保持长连接。
GET /example HTTP/1.1
Host: api.example.com
Connection: keep-alive # 表示客户端希望保持连接
- 服务器响应头:
服务器通过 Connection 头确认是否支持长连接。
HTTP/1.1 200 OK
Connection: keep-alive # 服务器同意保持连接
Keep-Alive: timeout=60, max=1000
Connection 可以取值 keep-alive 和 close :
keep-alive:客户端或服务器希望保持连接(HTTP/1.1 默认启用,无需显式设置)。
close:明确要求当前请求完成后关闭连接(使用短连接)。
4.6 Cookie
Cookie 是 HTTP 协议中用于 在客户端(浏览器)存储小型数据 的机制,主要用于会话管理(如用户登录状态)、个性化设置(如语言偏好)和用户行为跟踪(如广告定向)。以下是全面解析:
-
Cookie 的工作原理
基本流程:- 服务器设置 Cookie
通过 HTTP 响应头的 Set-Cookie 字段向浏览器发送 Cookie:
HTTP/1.1 200 OK Set-Cookie: session_id=abc123; Path=/; Secure; HttpOnly- 浏览器存储 Cookie
浏览器将 Cookie 存储在本地(内存或硬盘),后续请求自动附加到请求头的 Cookie 字段:
GET /profile HTTP/1.1 Cookie: session_id=abc123- 服务器读取 Cookie
服务器解析请求头的 Cookie 字段,识别用户身份或状态。
- 服务器设置 Cookie
-
Cookie 的分类
-
会话 Cookie(Session Cookie)
不设置 Expires 或 Max-Age,浏览器关闭后自动删除。 -
持久 Cookie(Persistent Cookie)
设置过期时间,长期存储在硬盘中。
-
-
Cookie 的应用场景
(1)会话管理
用户登录后,服务器下发 Session ID(Session ID是根据用户名和密码生成的在整个服务器中的唯一的ID,确保每个用户都不一样)Set-Cookie: session_id=xyz789; Path=/; HttpOnly; Secure; SameSite=Lax后续请求自动携带该 Cookie,服务器验证 Session ID 维持登录状态。
(2)个性化设置
存储用户语言、主题偏好
5. HTTPS协议
HTTPS = HTTP + TLS/SSL 加密
TLS/SSL在应用层:
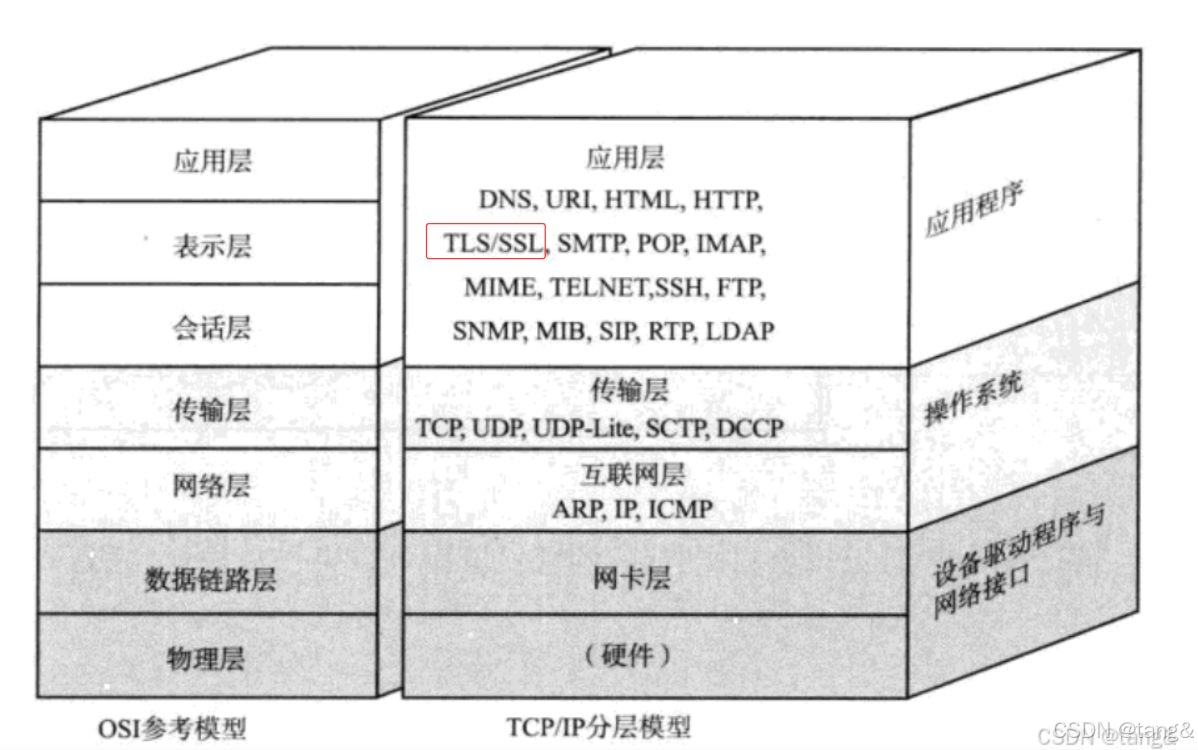
5.1 对称加密和非对称加密概念
对称加密:
定义:对称加密是指加密和解密使用相同密钥的加密方式。
特点:
- 加解密速度快,适合大数据量加密
- 密钥管理困难(需要安全地共享密钥)
- 算法相对简单
工作流程:
- 通信双方协商一个共享密钥
- 发送方用该密钥加密数据
- 接收方用相同密钥解密数据
典型应用场景:
- 大量数据的加密(如文件加密、数据库加密)
- SSL/TLS协议中的数据加密部分
- 磁盘加密
非对称加密:
定义:非对称加密使用一对密钥(公钥和私钥),公钥用于加密,私钥用于解密。
特点:
- 加解密速度慢,不适合大数据量加密
- 解决了密钥分发问题
- 可实现数字签名功能
- 算法复杂度高
工作流程:
- 接收方生成密钥对(公钥和私钥)
- 接收方将公钥发送给发送方
- 发送方用公钥加密数据
- 接收方用私钥解密数据
典型应用场景:
- 安全密钥交换(如SSL/TLS握手)
- 数字签名
- 身份验证
- 小数据量加密
5.2 HTTPS:对称加密+非对称加密+证书认证
HTTPS使用对称加密+非对称加密+证书认证的方式来加密:
-
如果只使用对称加密+非对称加密来加密:
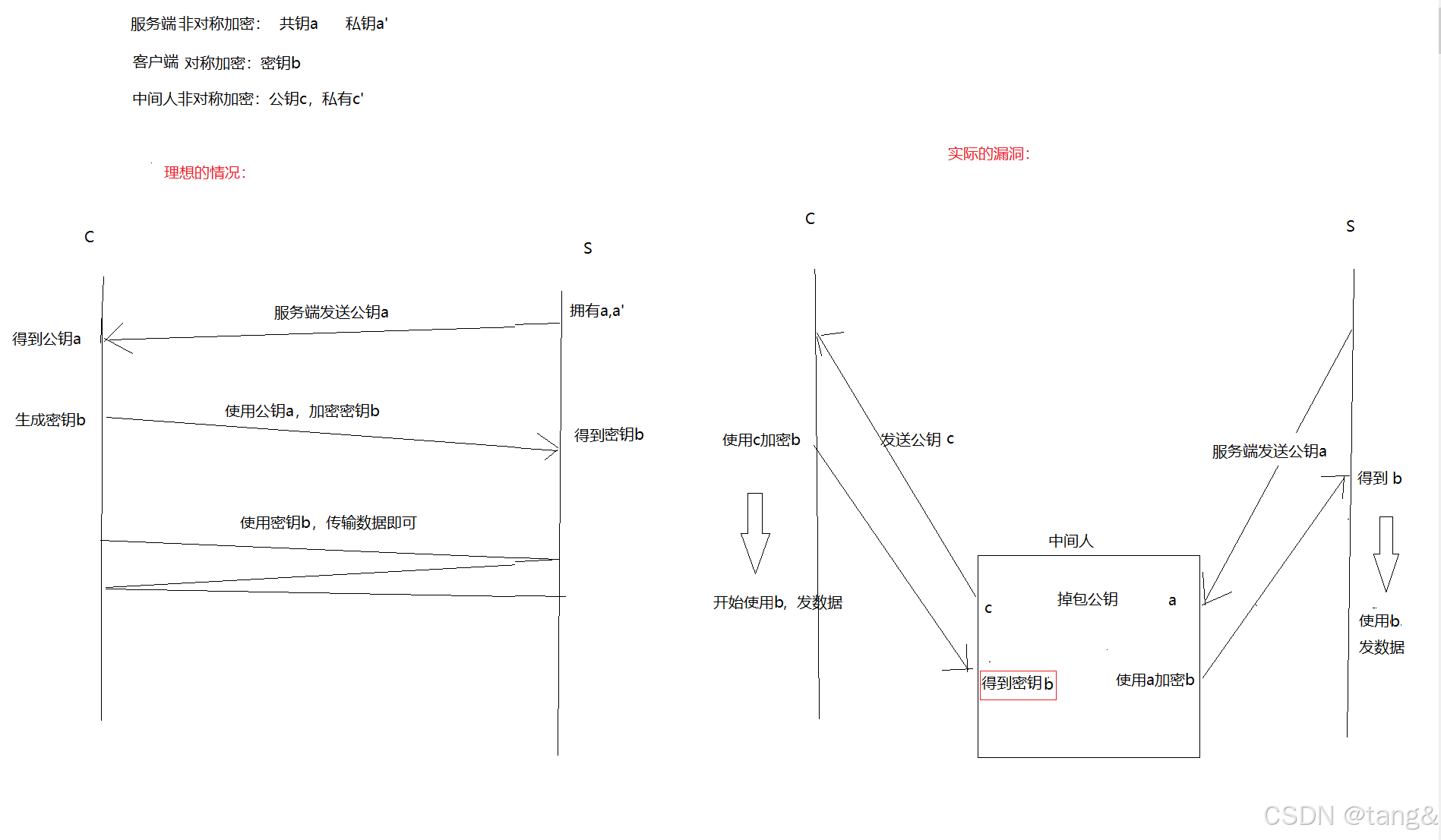
关键问题就是:服务端发来的公钥被调包了,即客户端没法判断公钥是否是合法的。
我们可以用证书认证来证明公钥的合法性。 -
证书(使用了数字签名):

签名形成的过程也被叫做对数据进行数字签名。
数字签名是基于非对称加密算法。 -
如何使用对称加密+非对称加密+证书认证来数据传输:
客户端浏览器都内置了CA机构的公钥
-
步骤1:验证证书的真假:
- 客户端用CA公钥对发来的证书的签名进行解密
- 解密后的结果和INFO进行对比,
相等,这个证书就是CA机构验证过的证书;不相等,就是假证书 - 查看INFO中的域名是否和服务端一样,一样就是服务端的证书
防止中间人在CA机构申请了证书来窃听消息。(域名具有唯一性)
-
步骤2:提取证书中的公钥a,客户端用公钥a来加密密钥b传输给服务端
-
步骤3:双方用密钥b来传输消息。
-
-
提示:
- CA机构的公钥用于解密,私钥用于加密,这是一个特例。
- 如果中间人修改了证书的INFO,那么客户端用公钥解密后,签名和INFO不匹配;如果中间人修改了证书的签名,他没有私钥加密,那么最后客户端用公钥解密后,签名和INFO还不匹配。
- 只有真正的CA机构的证书才会签名和INFO匹配。即使中间人使用了真正的CA证书,客户端查看证书INFO域名也会知道这不是客户端域名
总结
HTTPS ⼯作过程中涉及到的密钥有三组:
第⼀组(⾮对称加密): ⽤于校验证书是否被篡改。
第⼆组(⾮对称加密): ⽤于传递对称加密的密钥.
第三组(对称加密): 客⼾端和服务器后续传输的数据都通过这个对称密钥加密解密.
6. UDP协议
UDP(User Datagram Protocol,用户数据报协议)是传输层的协议,位于OSI模型的第四层和TCP/IP模型的传输层。
6.1 UDP协议的特点
- 无连接: 知道对端的IP和端口号就直接进行传输, 不需要建立连接;
- 不可靠: 没有确认机制, 没有重传机制; 如果因为网络故障该段无法发到对方, UDP协议层也不会给应用层返回任何错误信息;
- 面向数据报: 不能够灵活的控制读写数据的次数和数量
6.2 UDP协议端格式
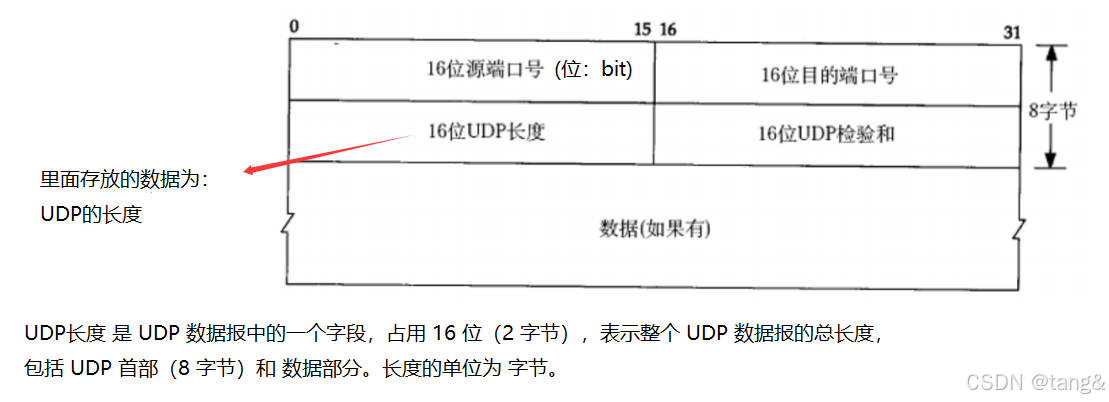
6.3 UDP有接收缓冲区,没有发送缓冲区。
接收缓冲区在传输层。
- UDP 的发送是“直接提交”:调用 sendto() 时,数据通常直接交给网络层(IP 层),不会像 TCP 一样在传输层缓存。
- UDP 通常没有发送缓冲区(数据直接提交给网络层)。这是因为UDP 的轻量化设计:牺牲缓冲和可靠性,换取更低的开销和延迟(适合实时应用如视频、DNS)。UDP 的无连接和不可靠特性决定了其缓冲机制的简化。
- UDP 有接收缓冲区(防止数据丢失,但满时会丢弃新数据)。
- TCP 的复杂性:需要缓冲区管理重传、排序、流量控制等机制。
- UDP是全双工的。全双工:允许同一套接字(Socket)同时发送和接收数据

7. TCP协议
TCP协议也是在传输层。TCP全称为 “传输控制协议”。
7.1 TCP协议段格式
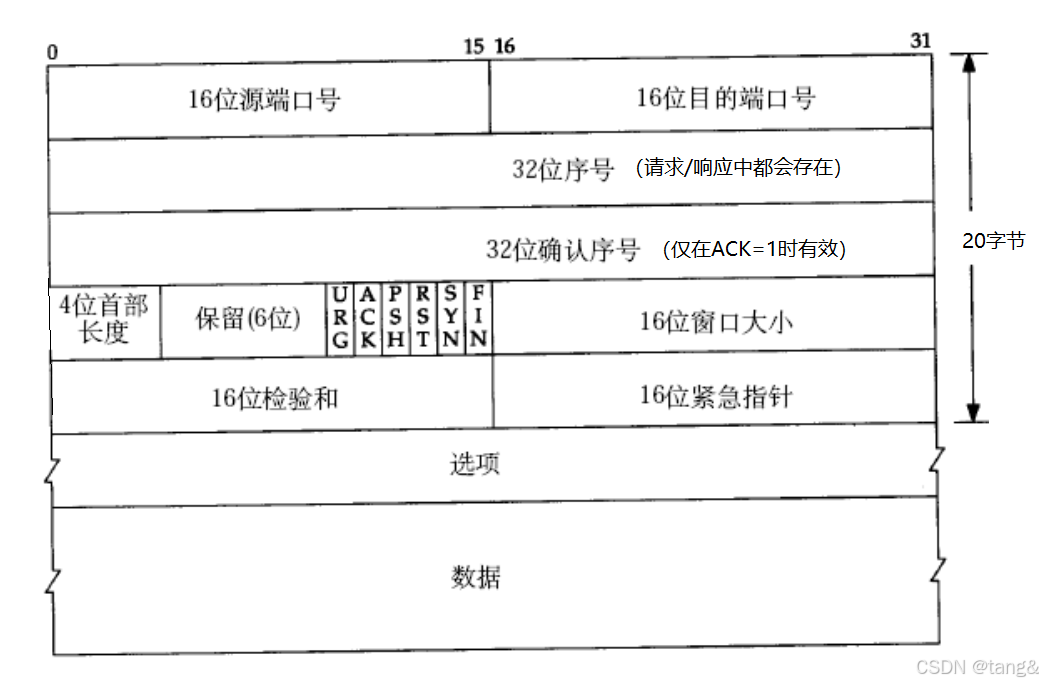
-
32位序号
- 作用:
- 标识 当前报文段数据部分的第一个字节 在整个数据流中的位置(字节偏移量)。
- 用于解决乱序问题,确保接收方能按正确顺序重组数据。
- 初始值(ISN):
- 在 TCP 三次握手时,双方随机生成初始序号(ISN),避免历史报文干扰。
- 增长规则:
- 每次发送数据后,序号按 数据字节数 递增。例如:
发送 100 字节数据(序号=0),则下一个报文段的序号=100。
- 每次发送数据后,序号按 数据字节数 递增。例如:
- 作用:
-
32位确认序号
- 作用:
- 期望收到的下一个字节的序号,表示该序号之前的所有数据已正确接收。
- 实现 可靠传输(通过 ACK 确认机制)
- 规则:
- 若接收方收到序号=0、长度=100 的数据,则发回的确认序号=100。
- 仅当 ACK 标志位=1 时有效(如普通数据报的 ACK 或纯确认报文)。
- 作用:
-
4位首部长度
- 作用:
- 指示 TCP 首部的 总长度(单位为 4字节)。
- 首部的 总长度 = 固定20字节 + 选项长度(0~40字节)
- 计算方式:
- 首部长度 = 4位值 × 4(字节)。
- 最小值=5(即 20 字节,无选项),最大值=15(即 60 字节)。
- 示例:
- 若 4 位值为 1010(十进制 10),则首部长度=10×4=40 字节。
- 作用:
-
16 位窗口大小
- 表示该报文发送端的接收窗口的大小(单位是字节)
- 接收窗口在TCP协议层,在接受缓冲区,接收窗口大小 = 接收缓冲区总大小 - 已占用缓冲区大小。
- 接收方通过窗口大小告知发送方 当前可接收的数据量(单位:字节),防止发送方速率过快导致接收方缓冲区溢出。
- 发送方必须保证 未确认的数据量 ≤ 接收方通告的窗口大小。 未确认的数据 是指发送方已发出但尚未收到对应ACK报文的数据
- 对于发送方来讲,发送速度由对方的接受缓冲区中剩余空间的大小决定!
-
6位标志位
- 6个标记位:区分了报文的类型
- 每一个标记位都是一个bit,如果这一位为1,则表示这一位的标记位有效;为0,则反之。
- ACK: 确认序号是否有效,用于应答报文(ACK为1,则有效)
- PSH: 发送端发送,提示接收端应用程序(应用层)立刻从TCP缓冲区(传输层)把数据读走
- FIN: 通知对方, 本端要关闭了。(发送完这个报文,本端的写端关闭,读端未关,用于四次挥手的第一次挥手)
- SYN:表示请求建立新的TCP连接。用于三次握手的前两次握手。
- URG:紧急指针标志,表示该报文段中存在紧急数据,需要优先处理。
- 紧急指针(Urgent Pointer):
这是一个16位的偏移量,与序列号(Sequence Number)结合使用,指向紧急数据的末尾位置。接收方会根据紧急指针快速定位找到并处理紧急数据(如中断命令)。
- 紧急指针(Urgent Pointer):
- RST:复位标志,表示发送方要求立即重新连接。
- 当连接断开时,B不知情,还在向A发送消息,A就会发送RST,要求重新连接
7.1.1 为什么一个TCP报文中同时需要序号和确认序号?
- 核心原因:全双工通信
- TCP是全双工协议,即通信双方可以同时发送和接收数据。因此,单个报文需要:
- 序号:标识本方发送的数据的字节流位置。
- 确认序号:确认对方发送的数据的接收情况。
7.1.2 TCP为什么是面向字节流的,UDP是面向数据报呢?
- TCP:
- 流程:
- 发送方:send()是把要发送的数据拷贝进入了传输层的发送缓冲区中,然后由操作系统自己来分配数据到每个报文中,然后发送报文;
- 接收方:操作系统自己接收报文并把报文分离,提取数据,放入接收缓冲区中,接收方通过recv()得到接收缓冲区的数据。
- 字节流抽象:
- TCP 将数据视为连续的字节序列,而非独立报文。发送方和接收方通过序号(Sequence Number)跟踪字节位置,确保数据按序到达
- 无数据边界
- 发送方:多次调用 send() 写入的数据会被合并为一个连续的字节流。
- 接收方:调用 recv() 时可能一次性读取多个发送端 send() 的内容,或分多次读取一个 send() 的内容。
- 流程:
- UDP:
- 流程:
- 发送方:sendto()直接将用户数据加上UDP首部(8字节)形成数据报,直接交给IP层发送;
- 接收方:操作系统自己接收报文并把报文分离,提取数据,放入接收缓冲区中,但是是按照一个报文一个报文的分离好数据,recvfrom()接收只能接收一个报文的数据
- 数据报抽象:
- UDP 将每个 send() 调用视为一个独立报文,接收方必须按报文边界读取。
- 保留数据边界
- 发送方:每次 send() 对应一个 UDP 数据报。
- 接收方:每次 recv() 读取一个完整的报文,若缓冲区小于报文大小,多余数据会丢失。
- 流程:
7.2 确认应答(ACK)机制
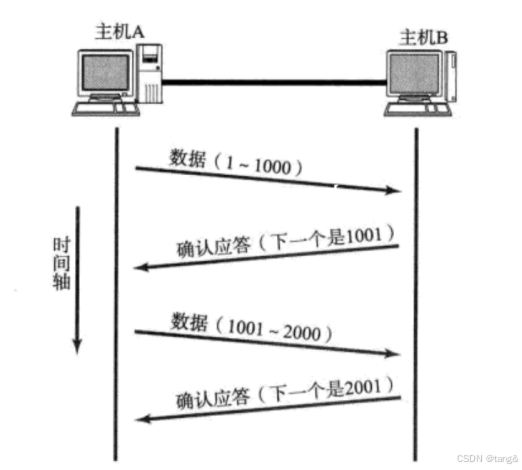
应答:
- 接收方每接收到一条报文,都要向发送方发送一条应答。(应答也是报文)报文多时,应答是一大批一起发送的。例如,接收了10个报文之后,然后再一起发送10一个应答。
- 应答(ACK)的本质:
作用:接收方通过 ACK 告知发送方“数据已成功接收”,并指示期望接收的下一个字节序号。 - 核心字段:
ACK 标志位:置 1 时表示该报文是应答。
确认序号:值为最后一个有序接收的字节序号 + 1
7.3 超时重传机制
TCP 是可靠传输协议,保证数据一定能到达对端。如果发送的数据包丢失了,TCP 会通过 超时重传 机制重新发送丢失的报文段。下面详细讲解它的工作原理。
- 为什么需要超时重传?
- 网络不可靠:IP 层不保证数据包一定能到达,可能会因为拥塞、链路故障、路由器丢包等原因丢失。
- TCP 必须保证可靠传输,所以要有机制检测丢包并重传。
- 超时重传的基本流程
- 发送方发送数据包,并启动一个 重传计时器(Retransmission Timer)。
- 等待 ACK:
- 如果接收方成功收到数据,会回复 ACK(确认)。
- 如果 ACK 在超时时间内到达,发送方取消计时器,继续发下一个数据包。
- 如果超时未收到 ACK:
- 发送方认为数据包丢失,重传该数据包。
- 同时调整超时时间(通常加倍,避免频繁重传加剧网络拥塞)。
- 超时重传时间(RTO)不宜太短或太长
- 如果 RTO 设置得太短,可能在 ACK 还在路上时,就误判丢包并重传。
- 如果 RTO 设置过长,即使真的丢包,也要等很久才重传。降低了效率
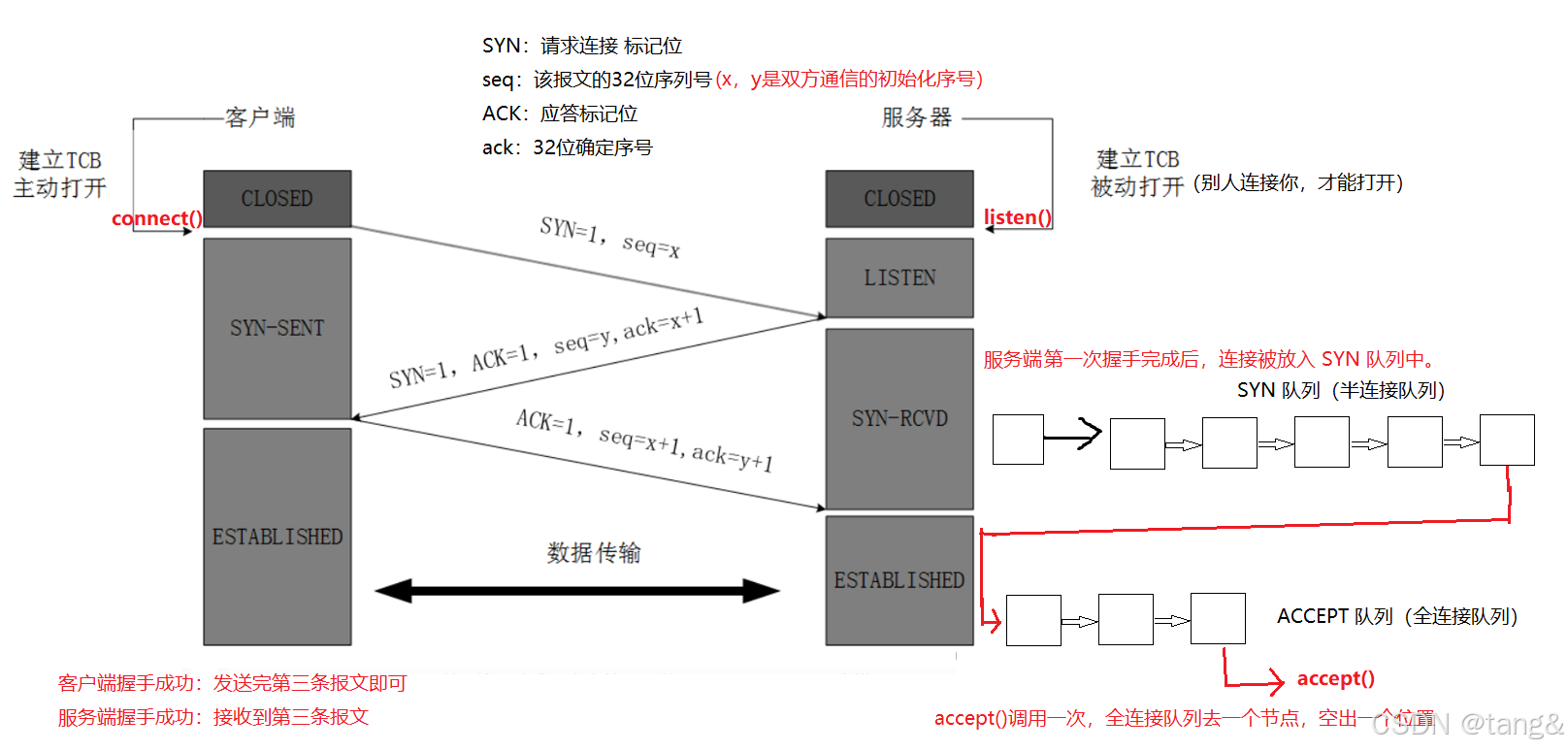
7.4 TCP三次握手
-
状态变化
- 客户端状态流:
CLOSED → SYN-SENT → ESTABLISHED - 服务器状态流:
CLOSED → LISTEN → SYN-RCVD → ESTABLISHED
- 客户端状态流:
-
在TCP三次握手中,客户端序列号从x变为x+1的原因
- 关键原因:SYN标志位消耗序列号
- TCP协议规定:
- 任何带有SYN或FIN标志的TCP报文,即使不携带应用数据,也会使序列号+1
- 这是因为SYN和FIN都被视为需要确认的"逻辑数据"
-
listen() - 服务器准备接收连接
- 服务器调用listen()后,进入LISTEN状态,开始监听指定端口的连接请求。
- 它并不直接参与三次握手,而是为握手提供条件:内核会为监听端口维护一个未完成连接队列(SYN队列)和一个已完成连接队列(ESTABLISHED队列)。
- 如果没有listen(),服务器即使收到SYN包也会直接丢弃
- listen()在握手开始前调用,是服务器能够响应客户端SYN的前提条件。
7.4.1 连接管理机制
在 TCP 三次握手过程中,服务器内核维护 两个关键队列 来管理连接状态:
- SYN 队列(半连接队列,syns queue)
- 存储已收到 SYN(第一次握手),但未完成三次握手的连接。
- 这些连接处于 SYN_RCVD 状态。
- ACCEPT 队列(全连接队列,accept queue)
- 储已完成三次握手(ESTABLISHED),但尚未被 accept() 取出的连接。
三次握手中 SYN 队列 和 ACCEPT 队列 的交互流程:
- 第一次握手(客户端connext()):
- 服务器收到 SYN,将该连接放入 SYN 队列
- 第二次握手
- 第三次握手
- 客户端:三次握手已经完成,客户端那边可以开始通信了
- 服务端:看 ACCEPT 队列有没有位置。
-
没有位置(即服务端没有调用accept() 或者 调用了accept(),但是SYN 队列前面还有连接,没有轮到它)
- Linux 默认行为:直接丢弃 ACK,不完成第三次握手,连接保留在 SYN 队列,等待ACCEPT 队列位置。—— 还在SYN 队列,三次握手没完成
- 客户端发起请求,会收不到响应,然后超时重传 ACK。如果说持续较长时间没完成三次握手的话,客户端放弃重传(连接超时失败)。
- 如果 net.ipv4.tcp_abort_on_overflow=1,服务器会直接回复 RST 重置连接。
-
有位置,并且该连接在SYN 队列头,可以占据该位置
- 内核将该连接从 SYN 队列 移至 ACCEPT 队列中 —— 到达 ACCEPT 队列,三次握手完成
-
- 所以对于服务端来说,该连接进入了ACCEPT 队列,即三次握手完成
- 两端三次握手完成,服务端是否发起accept()
- 不发起或者发起了,但还没轮到该连接。—— 该连接仍然在TCP协议层
- 客户端可以正常发送数据,且 不会收到 RST 重置连接(只要连接在 ACCEPT 队列 中)。
- 服务端内核会接收数据并缓存,但应用层无法读取(直到 accept() + read())。服务端也无法发送数据,但可以发送不带数据的报文。
- 如果服务端的接收窗口满了,服务端就会发送报文,提醒客户端控制发消息,客户端就会阻塞或丢包。( TCP 流量控制机制)
- 发起了,并且该连接在ACCEPT 队列头
- ACCEPT 队列删除连接,该连接被提取到应用层(其实是应用层拿到该连接的管理权)应用层通过accept()得到通信套接字,可用于数据传输。
- 不发起或者发起了,但还没轮到该连接。—— 该连接仍然在TCP协议层
小知识点:
- SYN 队列(半连接队列)不会长期维护未完成的连接
- listen的第二个参数为backlog,backlog+1表示全连接队列的最大连接长度。
int listen(int sockfd, int backlog);
SYN 洪水攻击:
-
什么是 SYN 洪水攻击?
- SYN 洪水是一种 拒绝服务攻击(DoS/DDoS),攻击者利用 TCP 三次握手的机制缺陷,伪造大量虚假的 SYN 包 发送给目标服务器,消耗其资源(如半连接队列和内存),导致服务器无法处理正常用户的连接请求。
-
SYN 洪水攻击流程:
- 攻击者伪造大量 SYN 包:
- 使用虚假 IP(如随机源地址)发送 SYN,不回复 ACK。(不给第三次握手)
- 服务器资源被耗尽:
- 每收到一个 SYN,服务器分配内存并回复 SYN-ACK,连接滞留在半连接队列。
- 由于SYN队列满了,正常用户的 SYN 被丢弃,服务瘫痪。
- 攻击者伪造大量 SYN 包:
7.4.2 为什么握手是三次
TCP采用三次握手(3-way handshake)建立连接,而不是一次、两次、四次或更多次,这是为了在可靠性和效率之间取得最佳平衡。以下是详细解释:
-
为什么不能是「一次握手」?
- 问题:客户端发送连接请求后直接开始传输数据,服务端无法确认自己是否准备好了。
- 风险:
- 服务端可能未准备好接收数据(资源未分配)。
- 网络中的延迟或重复的旧连接请求(历史报文)可能导致服务端误判。
-
为什么不能是「两次握手」?
- 表面看:客户端发送请求(SYN),服务端回复确认(SYN-ACK),似乎足够了。
- 实际缺陷:
- 无法防止历史连接问题:如果客户端的第一个SYN因网络延迟很久才到达服务端(旧连接的SYN),服务端会直接建立连接,但客户端可能早已放弃,导致服务端资源浪费。
- 无法确认客户端的接收能力:服务端不知道客户端是否能收到自己的SYN-ACK,若客户端未收到,服务端会一直等待
-
为什么「三次握手」是完美的?
- 关键作用:
- 双方确认彼此的发送和接收能力。
- 同步初始序列号(ISN),保证数据顺序。
- 防止资源被无效历史连接占用。
- 三次是>=3的最小奇数次,最后一定是最开始发送连接请求的客户端发送最后一条报文,即服务端接收最后一条报文
- 如果第三次握手的报文丢失,客户端三次握手成功,形成连接,服务端失败,不形成连接,那么资源消耗的代价是在客户端,而不是服务端。
- 如果客户端后续发送数据(而不仅是ACK):服务端收到非SYN报文时,会回复RST复位报文(因为其连接未建立)。
- 客户端收到RST后,会立即释放连接。
- 关键作用:
-
为什么不需要四次或五次?
- 三次已足够:三次握手后,双方已完全确认通信能力,更多次数不会带来额外好处。
- 效率问题:更多握手次数会增加延迟和开销,但不会提高可靠性。
7.5 TCP 四次挥手
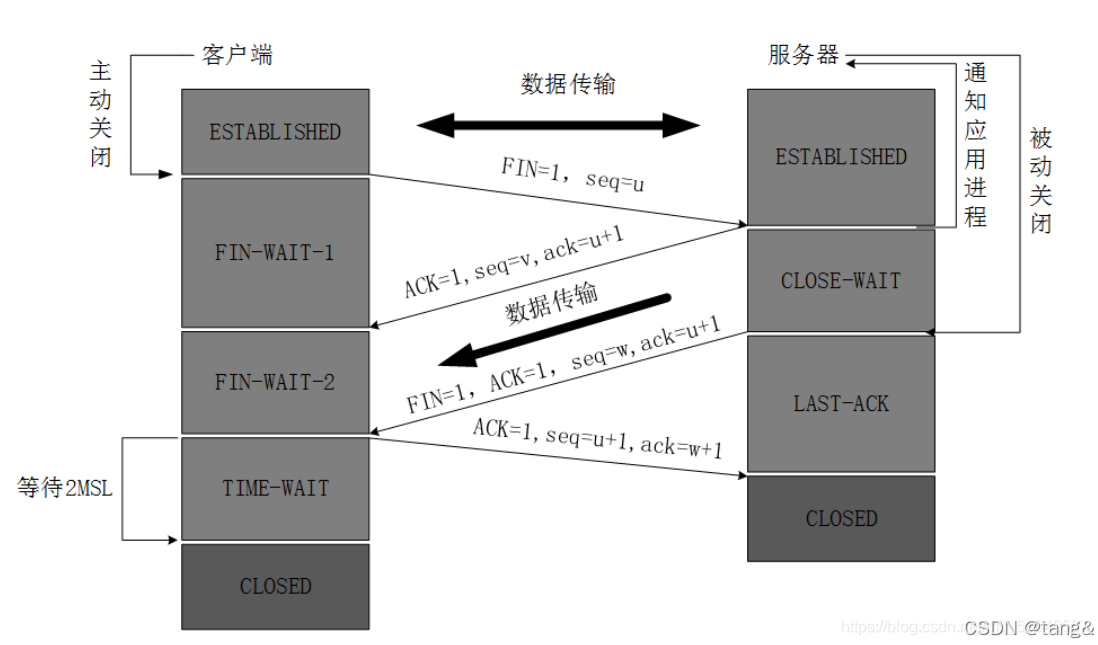
- MSL:报文在网络中,最大生存时间
- 主动断开连接的一方,在4次挥手完成之后,要进入time-wait状态,等待若干时长,之后,自动释放
- 为什么要等待 2MSL 才释放?
主要有 4个原因:- (1) 确保最后一个ACK能到达对方
- 如果主动关闭方最后发送的ACK丢失,对方(被动关闭方)会重传FIN。
- TIME_WAIT的存在使得主动关闭方可以再次发送ACK,避免对方一直处于LAST_ACK状态。
- (2) 让网络中残留的旧报文失效
- TCP报文可能在网络中因延迟而滞留(如路由器抖动),如果相同的四元组(源IP、源端口、目标IP、目标端口)的新连接建立,可能会收到旧连接的脏数据。
- 等待2MSL可以确保所有属于旧连接的报文都从网络中消失。
- (3) 保证TCP全双工可靠关闭
- 确保双方都能正常完成关闭流程,避免一方因丢包导致连接未正确终止。
- (4) 兼容不可靠网络
- 在网络不稳定的环境下,TIME_WAIT能减少因丢包或乱序导致的新连接数据错乱问题。
- (1) 确保最后一个ACK能到达对方
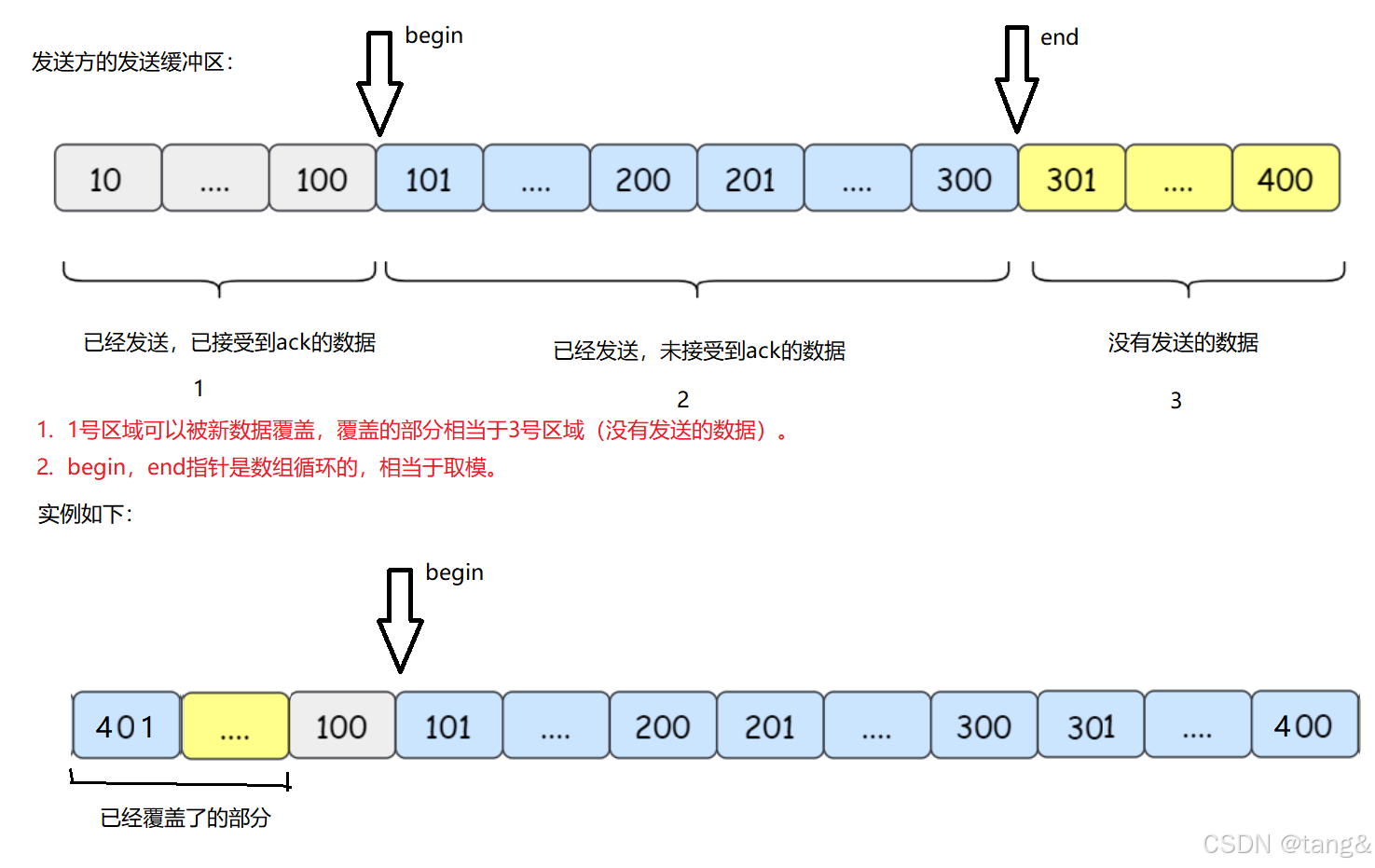
7.6 滑动窗口
因为有滑动窗口区域,我们才可以一次向对方发送大量的tcp报文!
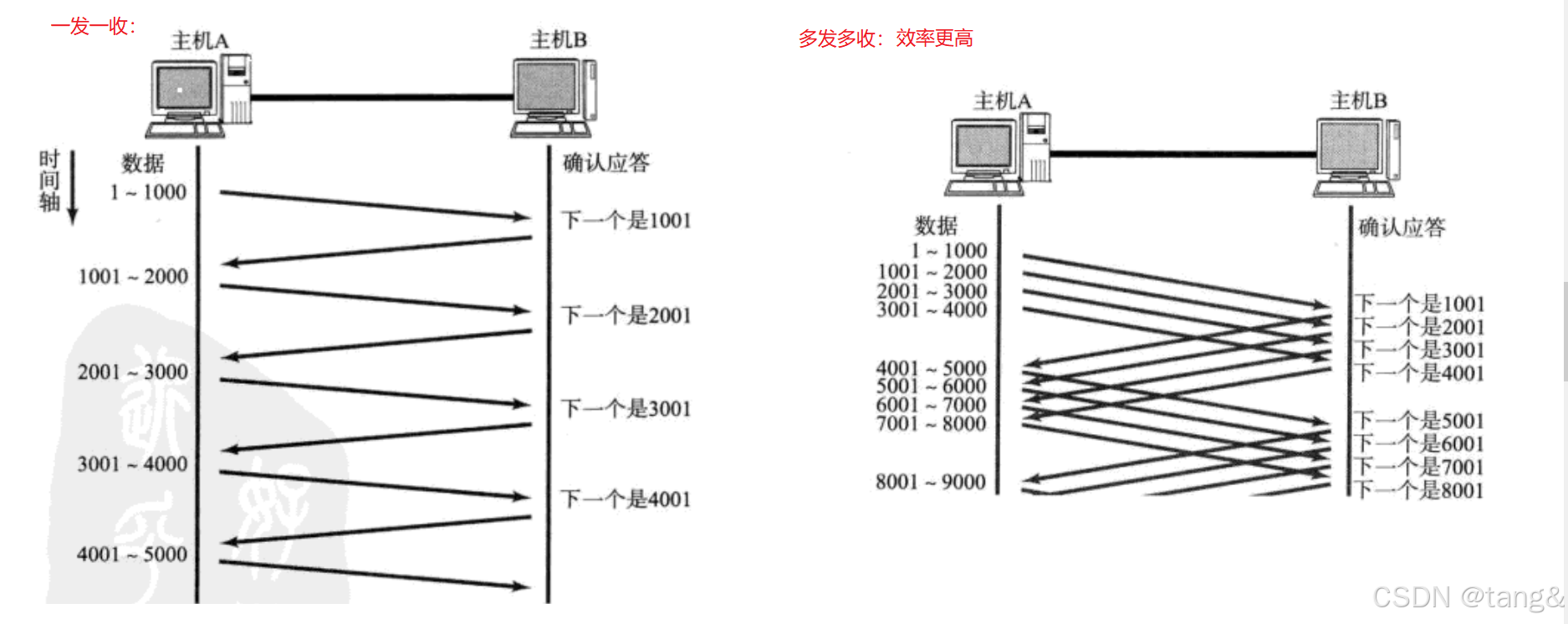
7.6.1 滑动窗口的结构
滑动窗口是发送方的发送缓冲区的一部分。
7.6.2 快重传
快重传是TCP的一种丢包恢复机制,用于在检测到数据包丢失时快速触发重传,而无需等待超时,从而减少延迟、提高传输效率。
- 快重传的核心原理
当发送方连续收到 3个重复的ACK 时,立即重传丢失的单个数据包(无需等待超时)。如同所示:
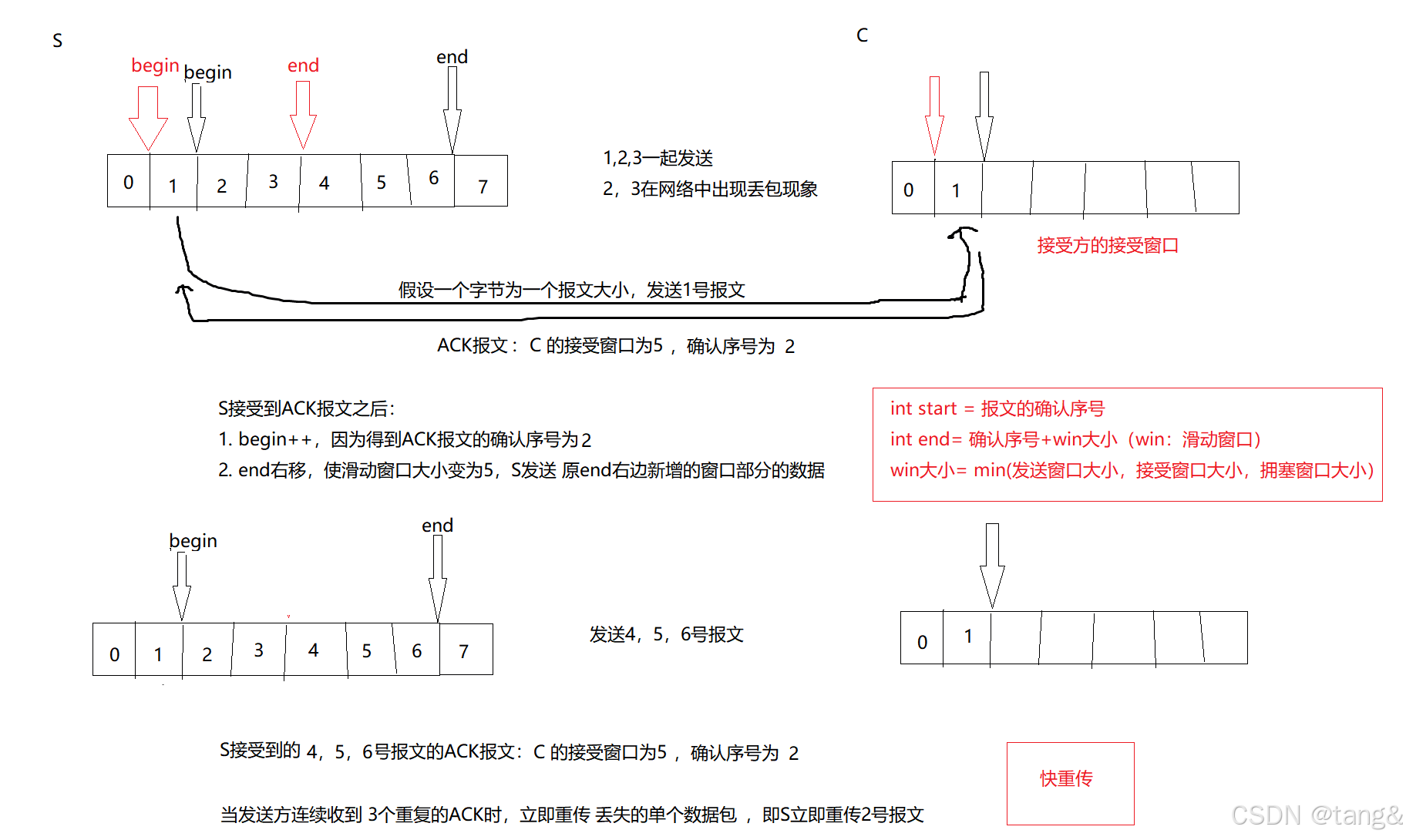
快重传:快速检测并修复单包丢失,避免等待超时,提高传输效率。
超时重传:处理严重丢包或连接中断等快重传无法覆盖的场景。(即发送方没法连续收到 3个重复的ACK的时候)。
7.7 延迟应答
7.7.1 延迟应答的概念
- “延迟应答”就是接收方收到数据后,故意等一等再回复ACK(确认消息),目的是减少网络中小ACK包的数量,提高传输效率。
- 网络传输中,数据确实是被分割成一个个报文/包(Packet)发送的,可以选择 “逐包发送” 或者 “批量发送” 。“批量发送”:减少头部开销,提高吞吐量。
通俗版详解:
想象你网购收快递:
- 没有延迟应答(普通模式)
快递员(发送方)每送一个包裹(数据包),你就(接收方)必须立刻喊一声:“收到啦!”(ACK)。
问题:如果快递员连续送10个包裹,你要喊10次“收到啦!”,很累且浪费力气(网络带宽)。
- 开启延迟应答(优化模式)
快递员送第一个包裹时,你开始憋着不吭声(启动200ms延迟计时器)。
如果200ms内他又送第二个包裹:你直接喊“两个都收到啦!”(合并ACK,即把多条ACK打包在一起形成一个大包)。
如果200ms内他没送新包裹:你超时后喊“第一个收到啦!”(单独发ACK)。
7.7.2 延迟应答的作用和触发条件
-
延迟应答的作用
-
减少ACK报文数量:
若每次收到数据都立即回复ACK,会导致大量小包(如40字节的纯ACK)占用带宽。
示例:发送方连续发送10个数据包,立即ACK会生成10个小包;延迟ACK可能合并为1个ACK。 -
提高网络利用率:
合并ACK可减少网络拥塞,尤其在高延迟或低带宽环境中(如移动网络)。 -
触发捎带应答:
延迟期间若接收方有数据要发送(如HTTP响应),可将ACK“捎带”在数据包中,完全避免单独发送ACK。 -
延迟应答通过暂缓发送确认(ACK),为应用程序争取时间从缓冲区读取数据。这使得接收方能够向发送方通告一个更大的可用窗口(RWND),从而允许发送方一次性发送更多数据,显著提升网络吞吐效率和带宽利用率。
-
-
延迟应答的触发条件
接收方在以下任一条件满足时发送ACK:- 超时时间到:通常延迟200ms(Linux默认值)。
- 收到两个数据包:即使未超时,收到第二个包后必须立即ACK(RFC 1122规定)。
- 有数据需要发送:直接捎带ACK。
7.8 流量控制
流量控制(Flow Control) 是一种机制,其根本目的是防止发送方发送数据过快、过多,导致接收方来不及处理,最终造成数据丢失。
它是一种点对点的(通常是接收方控制发送方)、保证可靠性的机制。
一个生动的比喻:水池与水龙头
想象一个水池(接收方的缓冲区)和一个水龙头(发送方)。
- 正常情况:你打开水龙头,水流入水池,同时水池的排水管也在排水。进水和排水速度相当,水池不会满。
- 问题出现:如果水龙头开得太大(发送方发送太快),而排水管很细(接收方处理能力慢),水池里的水就会越积越多。
- 最终结果:如果不加控制,水池最终会满溢,水会漫出来造成浪费(数据包丢失)。
- 流量控制的作用:水池上有一个水位刻度尺(接收窗口)。当水位过高时,水池会向水龙头发送一个信号:“水位高了,关小一点!”(通告一个较小的窗口值)。水龙头收到信号后就调小水流(降低发送速率)。当水位下降后,水池又说:“现在可以开大一点了”(通告一个较大的窗口值)。
- 这个“根据水池水位动态调整水龙头大小”的过程,就是流量控制。
实际的过程:
- 接收端将自己可以接收的缓冲区大小放入 TCP 首部中的 “窗口大小” 字段, 通过ACK端通知发送端;
- 窗口大小字段越大, 说明网络的吞吐量越高;
- 接收端一旦发现自己的缓冲区快满了, 就会将窗口大小设置成一个更小的值通知给发送端;
- 发送端接受到这个窗口之后, 就会减慢自己的发送速度;
- 如果接收端缓冲区满了, 就会将窗口置为0; 这时发送方不再发送数据, 但是需要定期发送一个窗口探测数据段, 使接收端把窗口大小告诉发送端.
7.9 拥塞控制
我们通过理解cwnd(拥塞窗口)来理解拥塞控制。
cwnd(拥塞窗口)就是:
- 发送方心里的一套“交通规则”,它规定了自己一次最多能往马路上扔多少辆车(数据包),怕的是把路给堵死了。
- 每一个发送者都有cwnd(拥塞窗口),并且是自己通过cwnd来控制自己的发送,而不是通过网络统一控制,网络没有这个能力。接收方也管不着发送方的cwnd。
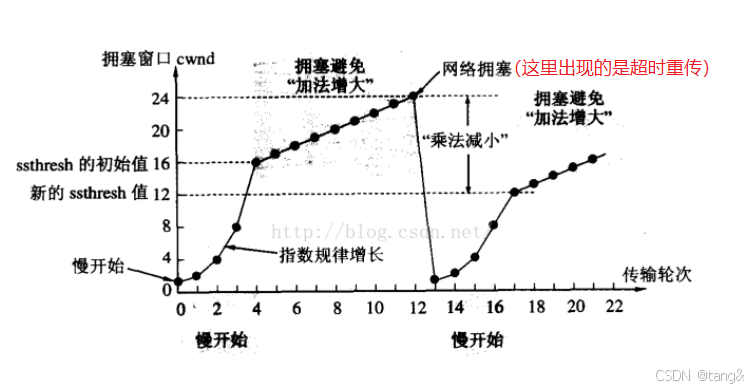
举例说明,拥塞控制的过程。
现在,你(发送方)是个车队经理,你的任务就是往这条公路上发车。
如果没有 cwnd(疯狂经理):
你根本不管路上堵不堵,一口气把你所有的车(比如 1000 辆)全派上去。
结果就是:所有车在第一个路口就堵死了,谁也动不了。这就是网络拥塞。
有了 cwnd(聪明经理):
你不知道这条路有多宽,所以你得很小心。
- 第一步(慢启动): 你先派 1辆车 去探路。车顺利到达后,对方会回复你:“收到1号车了!”(这叫 ACK)。
你一收到这个回复,心里就想:“哦?路是通的?那我这次派 2辆车!”
2辆车都到了,对方回复两个确认。你就想:“太棒了!这次派 4辆车!”
这就是 cwnd 在增长:1 -> 2 -> 4 -> 8… 它代表了你一次性能派出去的车队规模。 - 第二步(拥塞避免): 当车队规模大到一定程度(比如快到你知道的某个路口容量极限了ssthresh),你就不敢翻倍派车了。改成一次只多派1辆车:8辆 -> 9辆 -> 10辆… 慢慢试探。
- 第三步(发现堵车):通过两种“信号”,你发现堵车了。不同信号,不同措施.
- 信号一:超时重传 (Timeout) —— “彻底失联”
- 情景比喻:你派出一队车(比如10辆)。结果,连第一辆车的确认消息都没回来。即你没有收到一个ACK。
- 发送方的判断:“完了!这已经不是普通拥堵了,这怕是重大交通事故,路完全断了(比如路由器队列满了开始丢包,或者链路中断)!连个信都传不回来。”
- 发送方的反应(非常严厉):
1. 大幅缩减车队规模:直接把 cwnd 降为 1(cwnd = 1)。回到最初的起点。
2. 降低预期:把慢启动阈值 ssthresh 设为当前拥塞窗口的一半(ssthresh = cwnd / 2)。
3. 重新慢启动:从 cwnd=1 开始,像刚开始一样,指数增长,重新探路。 - 特点:反应剧烈,效率较低,但用于处理最严重的网络问题。
- 信号二:重复ACK (Dup ACK) —— “收到投诉电话”
- 情景比喻:你收到了连续三个相同的ACK。
- 发送方的判断:“哦!对方已经收到2号车之后的数据了,但唯独3号车没送到!这说明网络可能只是轻度拥堵,丢了个别包,但路没完全断,后续的车队(4,5,6号)还是能到达的。”
- 发送方的反应(快速重传/恢复):
- 调整规模:它认为网络只是部分拥堵,所以反应温和一些。
把慢启动阈值 ssthresh 设为当前 cwnd 的一半(ssthresh = cwnd / 2)。
但 cwnd 不会重置为1! 而是被设置为新的 ssthresh 值(ssthresh 有的可能还会加3,因为收到了3个重复ACK)。 - 直接进入拥塞避免:因为cwnd==ssthresh ,所以直接进入线性增长的拥塞避免阶段,而不是慢启动。
- 立刻重传:它不会傻等到超时,而是立即把怀疑丢失的3号车重新发出去。这就是“快速重传”。
- 调整规模:它认为网络只是部分拥堵,所以反应温和一些。
- 特点:反应迅速且温和,避免了超时重传带来的性能暴跌,大大提高了效率。
- 信号一:超时重传 (Timeout) —— “彻底失联”
也可以发现,慢启动阈值 ssthresh 等于 最近一次发生拥塞控制时, cwnd 的一半(ssthresh = cwnd / 2)
7.10 粘包问题
那么所谓的“粘包”现象是什么?
两种常见情况:
- 多个消息粘在一起:发送方快速连续发送了两个消息 MessageA 和 MessageB,接收方可能一次 recv 就读到了 MessageA + MessageB。
- 一个消息被拆开:发送方发送了一个较大的消息 BigMessage,TCP 可能会将其拆分成多个数据包传输,接收方可能需要多次 recv 才能收齐整个消息。
所以“粘包”根本不是一个问题,粘包只是一种现象,UDP绝对没有“粘包”现象。
如何处理粘包问题?
既然 TCP 不管消息边界,那就必须由应用层自己来定义消息的边界。这是网络编程中设计应用层协议的关键。
常见的解决方案有:
- 定长消息
每个发送的消息都是固定的长度。那么我们就可以把接受到的一大穿字符串以固定长度分割成一个个消息。例如,规定每个消息都是 100 字节。如果不足,就用空格或 \0 填充。 - 使用特殊分隔符
在每个消息的末尾加上一个特殊的字符或字符串作为结束标记,例如换行符 \n。 - 长度前缀(最常用、最推荐的方法)
在消息体的前面,加上一个固定长度的字段(Header,头部),用来表示后面消息体(Body)的长度。
[ 4 字节的消息长度 ] [ 实际的消息数据 ](Header) (Body)例如,要发送 "Hello World",其长度为 11。发送的数据结构为:
[0x00, 0x00, 0x00, 0x0B] [H, e, l, l, o, , W, o, r, l, d]
7.10 TCP的异常退出
核心原则
TCP通过握手(SYN) 和挥手(FIN/RST) 来管理连接的生命周期。但这些报文也是普通的网络数据包,在极端异常情况下(如断电、断网)根本无法发出。因此,TCP需要一套机制来探测和清理这些“僵死”的连接。
分为两种情况。
第一种情况:进程终止或机器正常重启(有序关闭)
无论是进程调用 close() 退出,还是其他进程退出方式,或者操作系统正常重启,内核的协议栈都会完成标准的TCP四次挥手过程。
kill -9退出进程是例外。kill -9(不是ctr + c)退出进程的话,不会进行4次挥手,连接处理是第二种情况了。
第二种情况:机器掉电、宕机或网络中断(无序中断)
背景:通信一方宕机/断电(对端不知情)。假设服务器突然断电,客户端完全不知情。
- 阶段一:客户端不知情,连接看似存在
在客户端看来,TCP连接状态依然是 ESTABLISHED。它不知道服务器已经“挂了”。 - 阶段二 :分两种情况
- 客户端一直没有发消息,启动保活机制
- TCP内置了一个可选的 保活定时器
- 连接空闲(无数据交换)超过 tcp_keepalive_time(默认7200秒,即2小时)后,保活机制启动。
- 客户端开始发送保活探测包。这个包就是一个空的、序列号是对方期望序号-1的ACK包(纯粹是为了引发响应)。
- 发现服务器已崩溃:服务器无法响应。客户端在连续发送9次探测包(总计约 75 * 9 ≈ 11分钟)后都收不到任何ACK回复,则判定连接已死亡。
- 连接清理:客户端内核会将本地的TCP连接状态置为 CLOSED,并释放资源。
- 客户端向服务端发送数据(更快发现错误)
- 数据包在网络上根本无法到达服务器主机。它可能在某个路由器上就被丢弃了,然后超时重传,然后到重传一定次数判定连接失败。
- 连接清理:客户端内核会将本地的TCP连接状态置为 CLOSED,并释放资源。
- 客户端一直没有发消息,启动保活机制



与标准的 jsonrpc的区别)



)
![【题解】洛谷P1776 宝物筛选 [单调队列优化多重背包]](http://pic.xiahunao.cn/【题解】洛谷P1776 宝物筛选 [单调队列优化多重背包])
)





---初始轨迹生成后的关键点采样)
)

及与Kafka实现的对比分析)
)