文章目录
目录
前言
一、基础概念:什么是 MySQL 索引?
二、底层数据结构:为什么 InnoDB 偏爱 B + 树?
B + 树的结构特点(以短链接表short_link的short_code索引为例):
B + 树的优势:
三、索引类型:按功能和结构划分
1. 按功能划分(常用类型)
2. 按物理存储划分(InnoDB 核心区别)
四、工作原理:索引如何加速查询?
场景 1:通过short_code查询长链接(SELECT long_url FROM short_link WHERE short_code = 'abc123')
场景 2:查询 “用户 123 创建的所有短链”(SELECT * FROM short_link WHERE user_id = 123 ORDER BY create_time)
五、优缺点:索引不是 “银弹”
优点:
缺点:
六、最佳实践:如何正确使用索引?
1. 适合建索引的场景
2. 不适合建索引的场景
3. 避免索引失效的常见坑
总结
前言
MySQL 索引是数据库性能优化的核心工具,如同书籍的目录,能帮助数据库快速定位数据,避免全表扫描。下面从基础概念、底层结构、类型划分、工作原理、优缺点及最佳实践六个维度详细解析,并结合实际业务场景(如短链接平台、电商系统)说明其应用
一、基础概念:什么是 MySQL 索引?
索引是 MySQL 在存储引擎层(如 InnoDB)创建的数据结构,通过对表中特定字段的值进行排序和组织,实现 “快速定位数据位置” 的功能。
- 核心目标:减少磁盘 I/O 次数(数据库操作中最耗时的环节),提升查询效率。
- 类比:查询表中
short_code = 'abc123'的短链接时,无索引需逐行扫描全表;有索引时,可直接通过索引定位到该记录的物理地址,类似查字典时通过拼音目录找汉字。
二、底层数据结构:为什么 InnoDB 偏爱 B + 树?
MySQL 索引的底层数据结构取决于存储引擎,InnoDB(MySQL 默认引擎)的索引基于B + 树实现,而非哈希表、二叉树等,原因是 B + 树更适合数据库的读写场景。
B + 树的结构特点(以短链接表short_link的short_code索引为例):
- 层级化结构:由根节点、非叶子节点、叶子节点组成,层级通常为 3-4 层(百万级数据仅需 3 次 I/O)。
- 叶子节点存完整数据(聚簇索引)或主键(非聚簇索引):
- 叶子节点按
short_code值有序排列,且通过双向链表连接,支持范围查询(如short_code > 'abc' AND short_code < 'def')。 - 非叶子节点仅存 “索引值 + 子节点指针”,不存实际数据,节省内存空间。
- 叶子节点按
B + 树的优势:
- 平衡性:左右子树高度差不超过 1,保证查询效率稳定(不会出现极端情况下的长路径)。
- 范围查询高效:叶子节点的双向链表可快速遍历连续数据(如查询 “创建时间在 2023-01-01 到 2023-01-31 的短链接”)。
- 适配磁盘读写:节点大小通常为 16KB(InnoDB 页大小),单次 I/O 可加载整个节点,减少 I/O 次数。
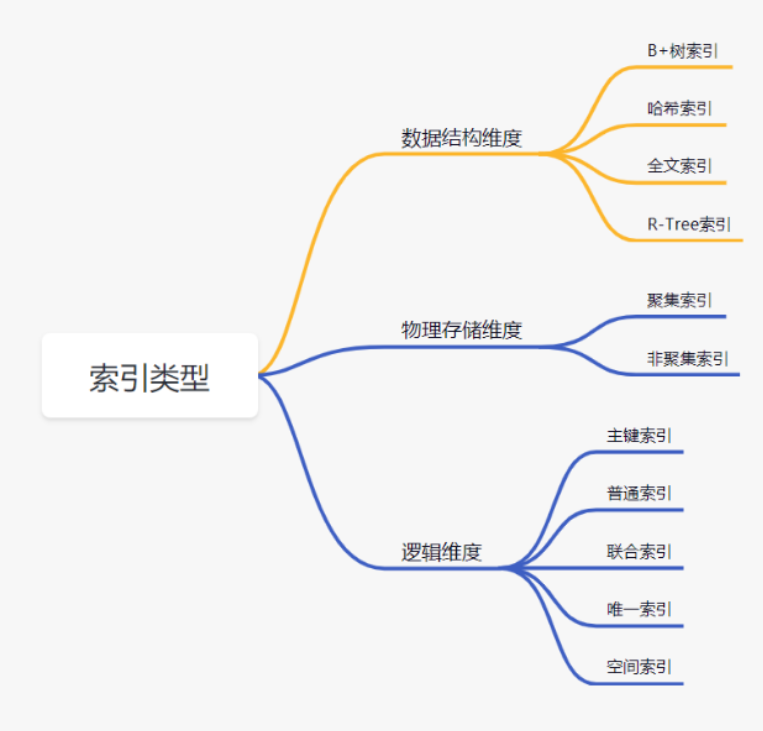
三、索引类型:按功能和结构划分
1. 按功能划分(常用类型)
| 索引类型 | 定义与特点 | 适用场景(结合业务) |
|---|---|---|
| 主键索引(PRIMARY KEY) | 表中唯一标识记录的索引,默认自动创建,字段值非空且唯一,InnoDB 中为主键聚簇索引。 | 短链接表short_link的id字段(自增主键),或short_code(唯一短链码),用于唯一定位单条记录。 |
| 唯一索引(UNIQUE) | 字段值唯一(允许 NULL,但最多一个 NULL),可避免重复数据。 | 短链接表的short_code字段(若不为主键),防止生成重复短链;用户表user的phone字段,确保手机号唯一。 |
| 普通索引(INDEX) | 无唯一性约束,最常用的索引类型,仅用于加速查询。 | 短链接表的user_id(查询 “某用户创建的所有短链”)、create_time(按时间筛选短链)。 |
| 联合索引(复合索引) | 对多个字段组合创建的索引,需遵循 “最左前缀原则”(查询条件需包含最左字段)。 | 电商订单表order的(user_id, create_time)联合索引,优化 “查询用户 A 在 2023 年的所有订单”。 |
| 全文索引(FULLTEXT) | 用于长文本字段(如varchar、text)的关键词检索,支持自然语言查询。 | 商品表product的description字段,实现 “搜索含‘红酒’关键词的商品”。 |
2. 按物理存储划分(InnoDB 核心区别)
-
聚簇索引(Clustered Index):
索引与数据存储在一起,叶子节点直接存储完整的行数据(仅 InnoDB 有)。- 默认以主键为聚簇索引;若表无主键,InnoDB 会用唯一索引代替;若均无,则生成隐藏的
row_id作为聚簇索引。 - 例:短链接表
short_link的主键id为聚簇索引,叶子节点存id, short_code, long_url, user_id等完整字段。
- 默认以主键为聚簇索引;若表无主键,InnoDB 会用唯一索引代替;若均无,则生成隐藏的
-
非聚簇索引(Secondary Index):
索引与数据分离,叶子节点仅存储 “索引值 + 聚簇索引值(主键)”,查询时需先查非聚簇索引得到主键,再通过聚簇索引查完整数据(称为 “回表”)。- 例:短链接表的
user_id普通索引,叶子节点存user_id + id,查询user_id=123的短链详情时,需先通过user_id索引找到id,再用id查聚簇索引获取完整数据。
- 例:短链接表的
四、工作原理:索引如何加速查询?
以短链接平台的两个核心查询为例,解析索引的工作流程:
场景 1:通过short_code查询长链接(SELECT long_url FROM short_link WHERE short_code = 'abc123')
-
若
short_code有唯一索引(非聚簇索引):- 数据库通过 B + 树查找
short_code = 'abc123'的叶子节点,获取对应的主键id = 1001。 - 再通过聚簇索引(主键
id)查找id = 1001的叶子节点,获取long_url(回表操作)。
- 数据库通过 B + 树查找
-
若查询字段仅为
short_code和id(SELECT id, short_code FROM ...):- 非聚簇索引的叶子节点已包含
short_code + id,无需回表,直接返回结果(称为 “覆盖索引”,性能更优)。
- 非聚簇索引的叶子节点已包含
场景 2:查询 “用户 123 创建的所有短链”(SELECT * FROM short_link WHERE user_id = 123 ORDER BY create_time)
-
若
user_id有普通索引,create_time有普通索引:- 先通过
user_id索引筛选出所有user_id=123的记录,得到对应的id列表。 - 再通过聚簇索引获取每条记录的完整数据,最后按
create_time排序(需额外排序操作)。
- 先通过
-
若建立
(user_id, create_time)联合索引:- 索引叶子节点按
user_id排序,同user_id内按create_time排序,筛选后可直接按顺序返回,无需额外排序(利用索引的有序性)。
- 索引叶子节点按
五、优缺点:索引不是 “银弹”
优点:
- 加速查询:大幅减少扫描行数,百万级表中查询耗时可从秒级降至毫秒级。
- 优化排序 / 分组:利用索引的有序性,避免
ORDER BY/GROUP BY时的文件排序(最耗时的操作之一)。
缺点:
- 占用存储空间:索引需单独存储,一张表若有 5 个索引,存储空间可能比表数据本身还大。
- 降低写入效率:新增 / 修改 / 删除数据时,需同步更新索引(B + 树的插入 / 平衡操作耗时),写入性能可能下降 50% 以上。
六、最佳实践:如何正确使用索引?
1. 适合建索引的场景
- 频繁查询的字段:如短链接表的
short_code(每次跳转都查询)、用户表的username(登录查询)。 - 排序 / 分组字段:如订单表的
create_time(按时间统计订单)、商品表的price(按价格排序)。 - 联合查询条件:如
WHERE a = ? AND b = ?,建立(a, b)联合索引比单字段索引更高效。
2. 不适合建索引的场景
- 低频查询的字段:如 “用户最后登录 IP”(半年查一次),建索引浪费空间。
- 字段值重复率高:如 “性别”(仅男 / 女),索引筛选效率低(几乎扫描全表)。
- 大字段:如
text类型的 “商品详情”,索引维护成本极高(字段越长,B + 树节点存储的索引值越少,层级越深)。
3. 避免索引失效的常见坑
- 函数 / 表达式操作索引字段:
WHERE SUBSTR(short_code, 1, 3) = 'abc'会导致short_code索引失效(索引存原始值,函数处理后无法匹配)。 - 类型转换:
WHERE short_code = 123(short_code是字符串)会触发隐式转换,索引失效(需写成WHERE short_code = '123')。 - 模糊查询左匹配:
WHERE short_code LIKE '%abc'(左模糊)索引失效,LIKE 'abc%'(右模糊)可命中索引。 - 违反最左前缀原则:
(a, b, c)联合索引,仅WHERE b = ? AND c = ?无法命中索引(需包含最左字段a)。
总结
MySQL 索引是 “以空间换时间” 的典型设计,核心价值是通过 B + 树等数据结构加速查询,但需根据业务场景合理设计(如短链接的short_code唯一索引、订单表的联合索引),避免滥用导致写入性能下降。理解索引的底层原理和失效场景,是数据库性能优化的关键。
详解(环境搭建+项目开发示例))


基础概念)


)
:基于IMX6ULL的点灯操作》)






![洛谷P9468 [EGOI 2023] Candy / 糖果题解](http://pic.xiahunao.cn/洛谷P9468 [EGOI 2023] Candy / 糖果题解)
大模型入门【3】--基于Chailit客服端实现页面AI对话)



