ELK 简介
ELK(Elasticsearch, Logstash, Kibana)是一个目前主流的开源日志监控平台。由三个主要组件组成的:
Elasticsearch: 是一个开源的分布式搜索和分析引擎,可以用于全文检索、结构化检索和分析,它构建在Lucene搜索引擎库之上,是当前使用较为广泛的开源搜索引擎之一。
Logstash: 一个用于收集、处理和转发日志数据的数据处理管道。Logstash可以从不同的日志源(如文件、应用程序日志、数据库等)中收集日志数据,并对其进行过滤、解析和转换,然后将其发送到Elasticsearch中进行存储和索引。
Kibana: 一个用于可视化和分析存储在Elasticsearch中的日志数据的用户界面。Kibana提供了一个直观且功能强大的仪表盘,可以根据特定需求创建各种图表、表格和地图,并进行实时数据可视化和监控。
安装Elasticsearch和Kibana
参考我之前写的博客
安装 Logstash
官方下载地址:https://www.elastic.co/cn/downloads/past-releases#logstash
与 Elasticsearch 一致
进入bin 目录,输入logstash.bat -e "input { stdin {} } output { stdout {} }"启动。
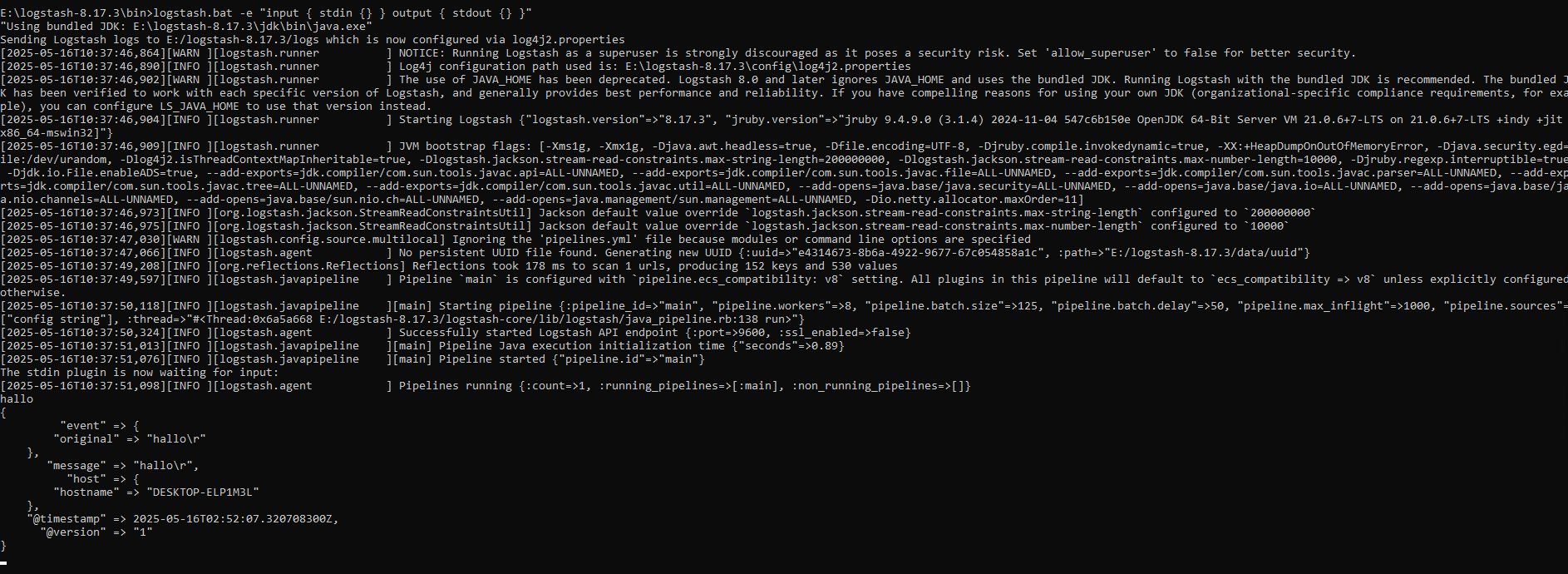
日志收集DEMO
创建SpringBoot应用
依赖导入
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies>日志配置文件 logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration><!-- 日志存放路径 --><property name="log.path" value="./logs"/><!-- 日志输出格式 --><property name="log.pattern" value="%d{HH:mm:ss.SSS} [%thread] %-5level %logger{20} - [%method,%line] - %msg%n"/><!-- 控制台输出 --><appender name="console" class="ch.qos.logback.core.ConsoleAppender"><encoder><pattern>${log.pattern}</pattern></encoder></appender><!-- 系统日志输出 --><appender name="file_info" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${log.path}/sys-info.log</file><!-- 循环政策:基于时间创建日志文件 --><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!-- 日志文件名格式 --><fileNamePattern>${log.path}/sys-info.%d{yyyy-MM-dd}.log</fileNamePattern><!-- 日志最大的历史 60天 --><maxHistory>60</maxHistory></rollingPolicy><encoder><pattern>${log.pattern}</pattern></encoder><!-- 是否在当天日志滚动时,对当天日志进行改名 --><timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"><maxFileSize>100MB</maxFileSize></timeBasedFileNamingAndTriggeringPolicy><filter class="ch.qos.logback.classic.filter.LevelFilter"><!-- 过滤的级别 --><level>INFO</level><!-- 匹配时的操作:接收(记录) --><onMatch>ACCEPT</onMatch><!-- 不匹配时的操作:拒绝(不记录) --><onMismatch>DENY</onMismatch></filter></appender><!-- 系统错误日志输出 --><appender name="file_error" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${log.path}/sys-error.log</file><!-- 循环政策:基于时间创建日志文件 --><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!-- 日志文件名格式 --><fileNamePattern>${log.path}/sys-error.%d{yyyy-MM-dd}.log</fileNamePattern><!-- 日志最大的历史 60天 --><maxHistory>60</maxHistory></rollingPolicy><encoder><pattern>${log.pattern}</pattern></encoder><!-- 是否在当天日志滚动时,对当天日志进行改名 --><timeBasedFileNamingAndTriggeringPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedFNATP"><maxFileSize>100MB</maxFileSize></timeBasedFileNamingAndTriggeringPolicy><filter class="ch.qos.logback.classic.filter.LevelFilter"><!-- 过滤的级别 --><level>ERROR</level><!-- 匹配时的操作:接收(记录) --><onMatch>ACCEPT</onMatch><!-- 不匹配时的操作:拒绝(不记录) --><onMismatch>DENY</onMismatch></filter></appender><!-- 用户访问日志输出 --><appender name="sys-user" class="ch.qos.logback.core.rolling.RollingFileAppender"><file>${log.path}/sys-user.log</file><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!-- 按天回滚 daily --><fileNamePattern>${log.path}/sys-user.%d{yyyy-MM-dd}.log</fileNamePattern><!-- 日志最大的历史 60天 --><maxHistory>60</maxHistory></rollingPolicy><encoder><pattern>${log.pattern}</pattern></encoder></appender><!-- 系统模块日志级别控制 --><logger name="com.project" level="info"/><!-- Spring日志级别控制 --><logger name="org.springframework" level="warn"/><root level="info"><appender-ref ref="console"/></root><!--系统操作日志--><root level="info"><appender-ref ref="file_info"/></root><root level="info"><appender-ref ref="file_error"/></root><!--系统用户操作日志--><logger name="sys-user" level="info"><appender-ref ref="sys-user"/></logger>
</configuration>
创建Logstash配置文件
进入Logstash的config目录,创建一个名为 logstash.conf文件,并进行如下配置
input {#监控所有服务的error.log文件file {path => "F:/twj/mygitee/project/logs/sys-error.log"start_position => "beginning"sincedb_path => "E:/logstash-8.17.3/sincedb_error_file"codec => "plain"type => "error"}#监控所有服务的user.log文件file {path => "F:/twj/mygitee/project/logs/sys-user.log"start_position => "beginning"sincedb_path => "E:/logstash-8.17.3/sincedb_user_file"codec => "plain"type => "info"}}filter {# 使用 grok 解析日志内容grok {match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:loglevel} %{DATA:thread} --- \[%{DATA:logger}\] \: %{GREEDYDATA:message}" }}# 如果需要从文件路径中提取服务名grok {match => { "path" => "logs/(?<service_name>[^/]+)/.*" }}# 时间字段转换为标准的时间格式date {match => [ "timestamp", "ISO8601" ]}# 过滤掉低于 ERROR 的日志(只保留 ERROR 日志)# if [loglevel] == "ERROR" {# mutate {# add_field => { "is_error_log" => "true" }# }# }
}output {# 将 error 日志发送到 Elasticsearchif [type] == "error" {elasticsearch {hosts => ["http://localhost:9201"]index => "sys-error.log-%{+YYYY.MM.dd}"user => "elastic"password => "qD+=4WRHuM7JgmJVo-ZD"}}# 将 user 日志发送到 Elasticsearchif [type] == "info" {elasticsearch {hosts => ["http://localhost:9201"]index => "sys-user.log-%{+YYYY.MM.dd}"user => "elastic"password => "qD+=4WRHuM7JgmJVo-ZD"}}# 可选:你也可以将日志输出到文件(调试用)# file {# path => "C:/path/to/output/logstash_output.json"# }
}input部分: 定义了日志输入来源及其处理方式。配置中有两个 file 输入插件,用于读取不同的日志文件,*表示匹配该目录下的所有文件
- path => “E:/work/sinosoft/logs/*/debug.log”: 这个配置指向所有子目录中的 debug.log 文件。
- start_position => “beginning”: 从文件的开始位置开始读取。如果是首次读取,它会从文件开头读取。
- sincedb_path => “E:/soft/ELK/logstash_sincedb/sincedb_debug_file”: sincedb 文件用于记录 Logstash 已经处理过的文件位置,确保在 Logstash 重启时能够继续读取未处理的日志。
- codec => “plain”: 指定使用 plain 编解码器,即不对日志内容做任何特殊编码。
- type => “debug”: 设置事件类型为 debug,用于后续在输出部分区分 debug 和 error 类型的日志。
filter部分: 用于对输入的日志数据进行解析和处理。
使用grok解析日志内容
- 使用 grok 解析日志中的 message 字段,匹配日志的标准模式(例如时间戳、日志级别、线程、日志记录器、实际日志消息等)。
该表达式将日志分解为以下字段:
timestamp: 时间戳
loglevel: 日志级别(例如 INFO, ERROR 等)
thread: 线程名
logger: 日志记录器名
message: 实际的日志消息内容
- 从日志的文件路径中提取服务名称,正则表达式 (?<service_name>[^/]+)/.* 会从路径
logs/{service_name}/ 中提取 service_name 字段。 - 将 timestamp 字段的时间格式转换为标准的时间格式(ISO8601),这样可以确保时间字段在 Elasticsearch
中存储为正确的时间戳格式。 - 过滤低于ERROR的日志,如果日志级别是 ERROR,则通过 mutate 插件给事件添加一个 is_error_log 字段,值为
true,用于标识该事件是一个错误日志
output部分: 定义了日志最终的输出目标。
-
输出debug类型的日志到Elasticsearch
-
只有当事件的 type 字段为 debug 时,日志才会被发送到 Elasticsearch。
hosts => [“http://localhost:9201”]: Elasticsearch 的地址。
index => “sys-error.log-%{+YYYY.MM.dd}”: 日志会被索引到 sys-error.log-YYYY.MM.dd 这样的索引中,其中 %{+YYYY.MM.dd} 会自动替换为日志事件的年月(例如 2025.03.01)。
user => “elastic”: Elasticsearch 用户名(一般为 elastic)。并且按日或按周等创建索引,将%{+YYYY.MM.dd}里面的+YYYY.MM.dd替换成其他便可。
-
输出error类型的日志到Elasticsearch
-
只有当事件的 type 字段为 error 时,日志才会被发送到 Elasticsearch。
-
index => “sys-error.log-%{+YYYY.MM.dd}”: 错误日志会被索引到
sys-error.log-YYYY.MM.dd 这样的索引中。
调试用的文件输出,index => “sys-error.log-%{+YYYY.MM.dd}”: 错误日志会被索引到 sys-error.log-YYYY.MM.dd 这样的索引中。(可选)
索引创建频率:
根据配置,索引的创建是按月进行的。具体来说,索引名称为 sys-error.log-%{+YYYY.MM} 和 sys-error.log-%{+YYYY.MM},其中 %{+YYYY.MM} 会被替换为事件的年和月,因此每个月会自动创建一个新的索引。
例如,2025年3月1日的 debug 日志会被索引到 sys-user.log-2025.03.01,错误日志则会被索引到 sys-error.log-2025.03.01。
总结:
输入: 从多个文件中读取 debug.log 和 error.log,并根据文件路径设置不同的类型 (debug 和 error)。
过滤: 使用 grok 解析日志,提取必要的字段,并转换时间格式。只保留 ERROR 级别的日志。
输出: 根据日志类型,分别将 debug 和error 日志输出到不同的 Elasticsearch 索引中,索引按月创建。
这样配置的目的是将 debug 和 error 日志分开存储,便于查询和分析,并且确保日志的时间信息被标准化处理。
启动logstash
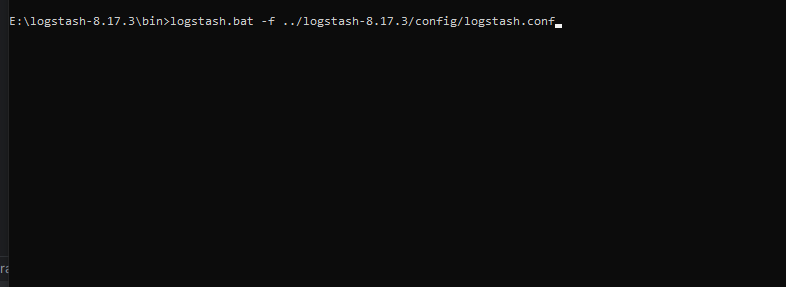
在将logstash.conf文件配置好并保存后,win+r打开终端(或者以管理员的方式),cd到bin目录下

输入命令:logstash.bat -f …/logstash-8.17.3/config/logstash.conf,启动logstash并且使用logstash.conf配置文件
启动成功后,logstash已经将配置文件中配置的将对应目录下的日志文件读入es中
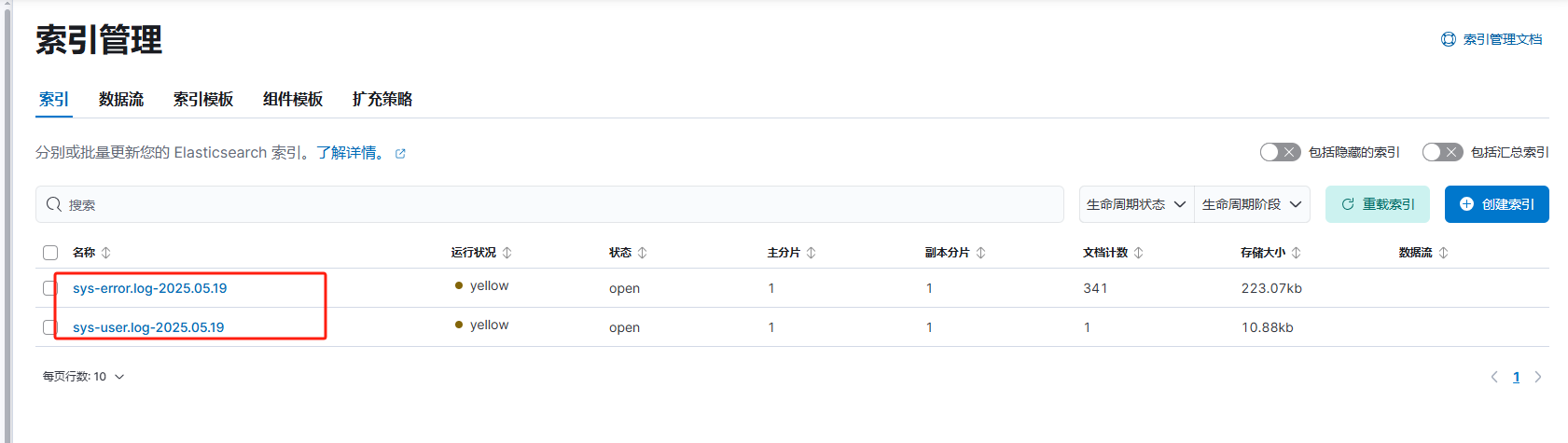
配置kibana
1、选择Management
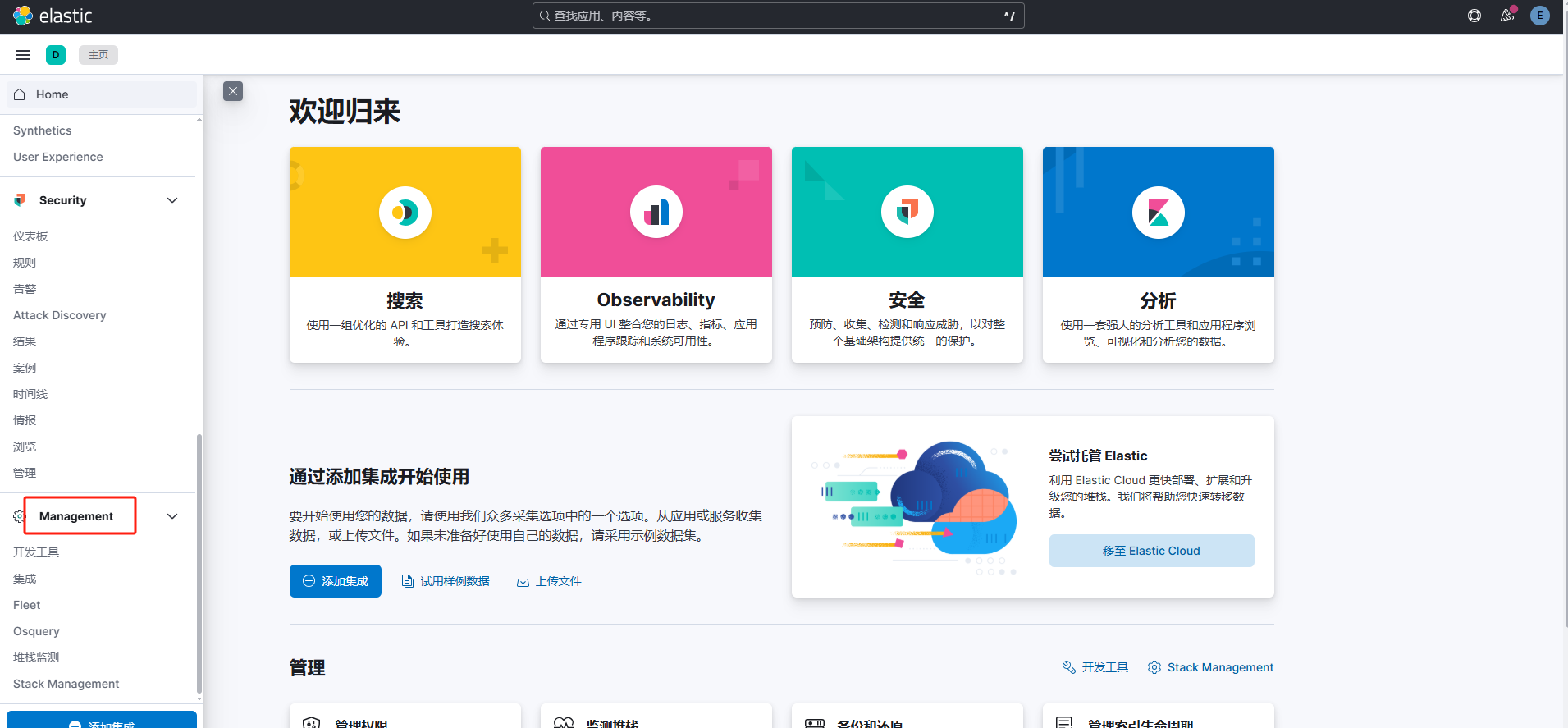
2、选择数据视图
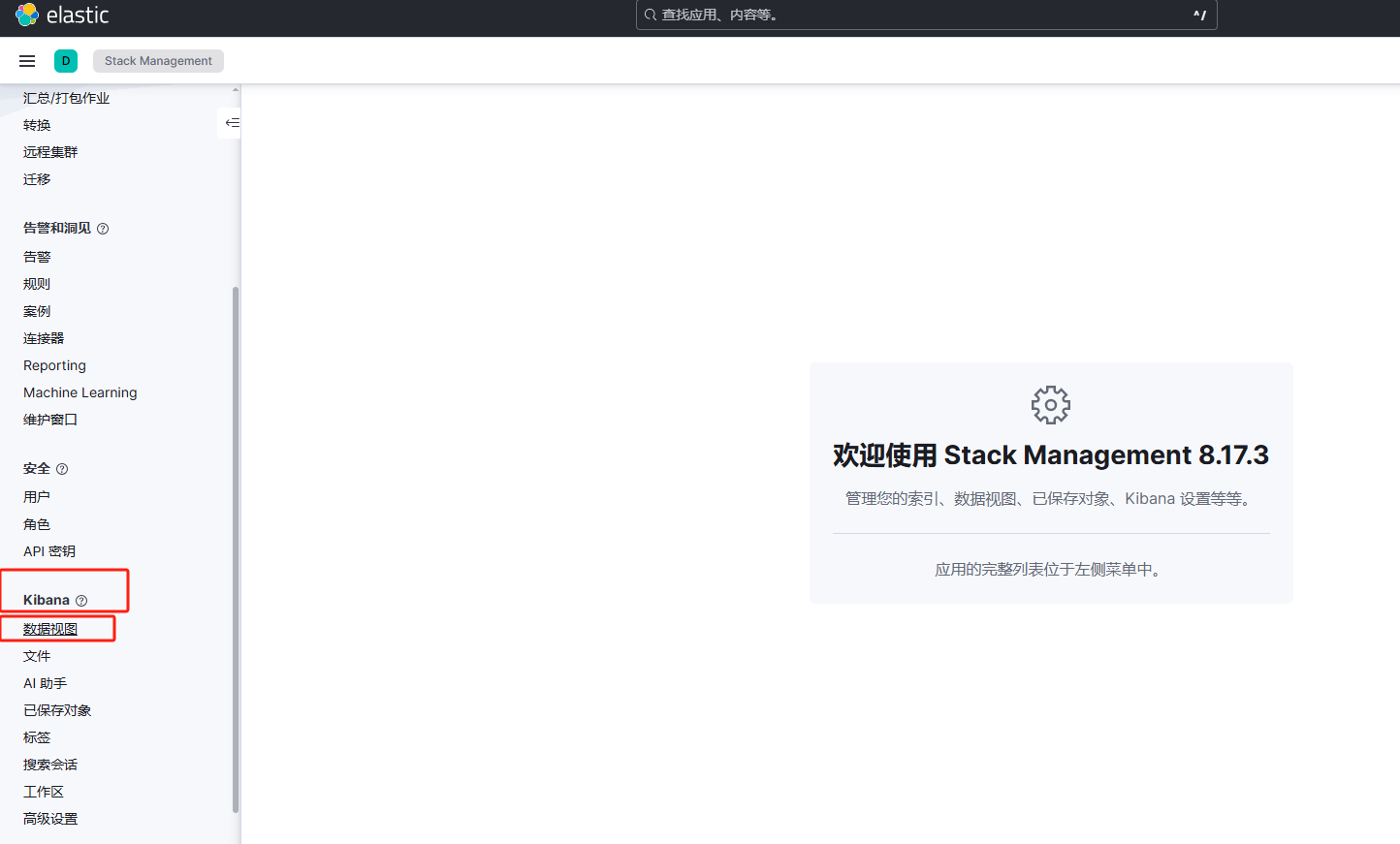
3、创建数据视图
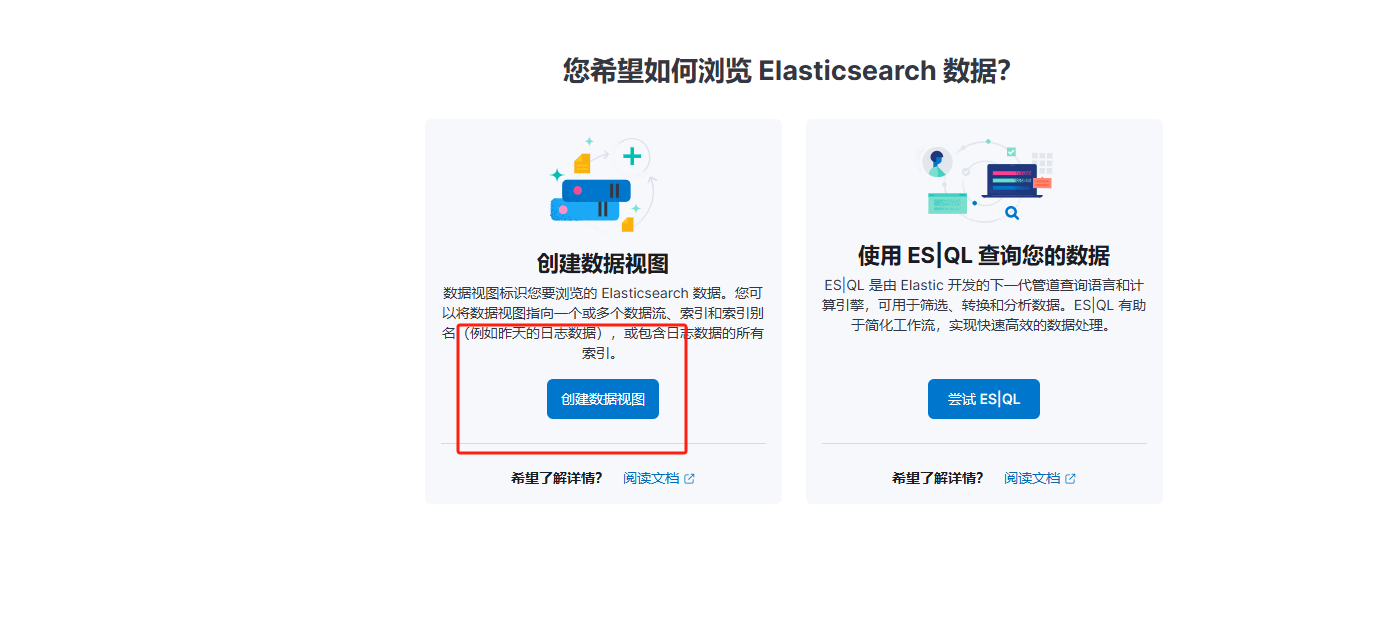
4、配置信息填写
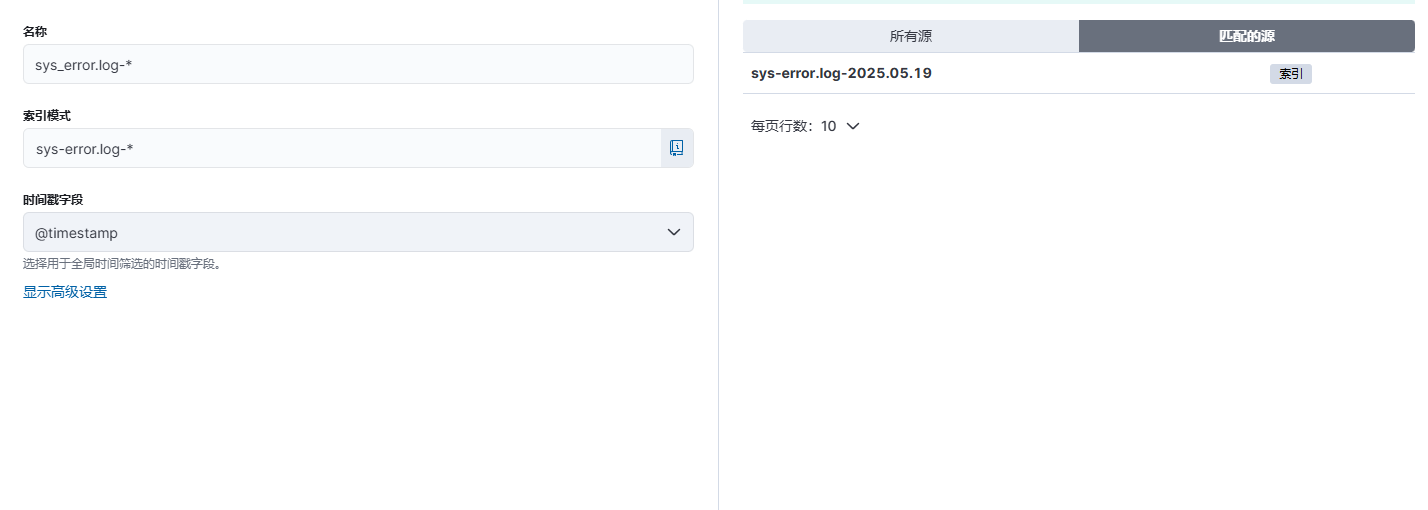
日志查看
1、点击Discover 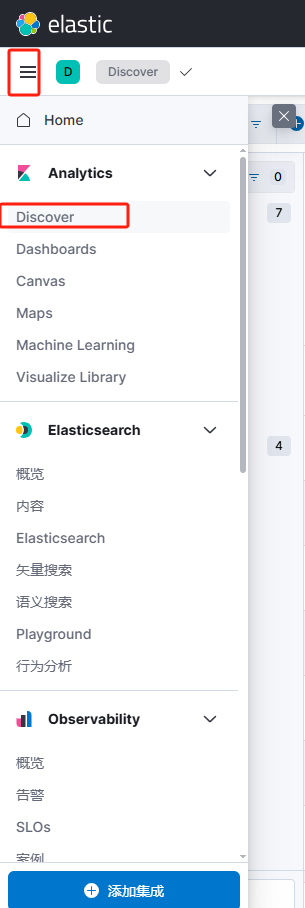
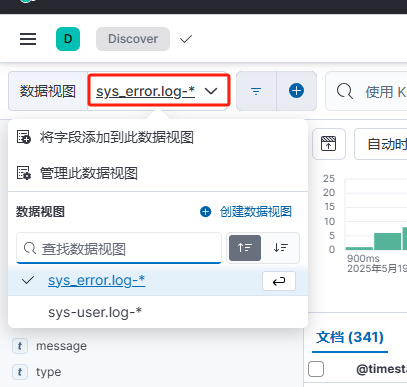
2、选择相应要查看的数据视图
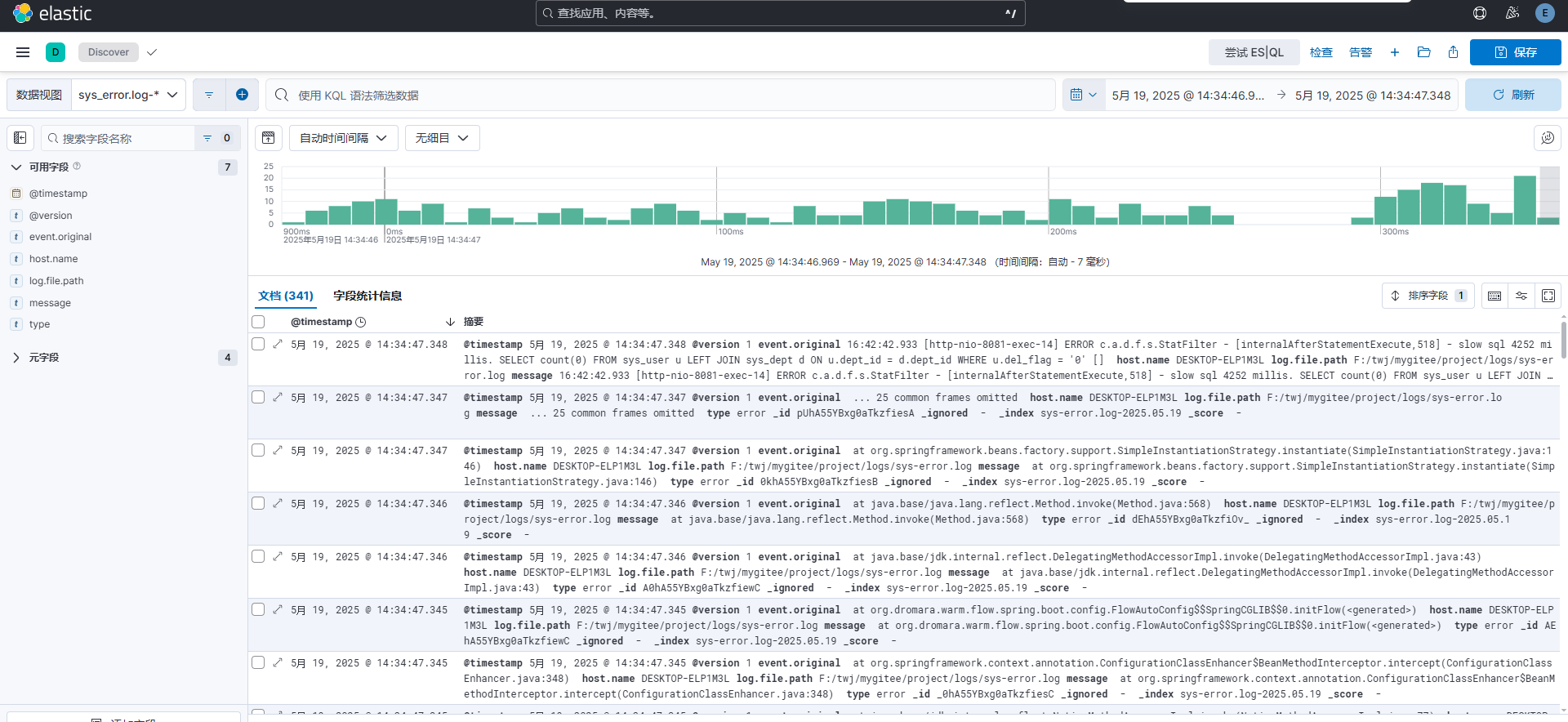

)
之 yolov5分类模型 训练自己的数据集)





在Qt中的应用)








)

![函数[x]和{x}在数论中的应用](http://pic.xiahunao.cn/函数[x]和{x}在数论中的应用)