这是一个技术爆炸的时代。一起来看看 GPT 诞生后,与BERT 的角逐。
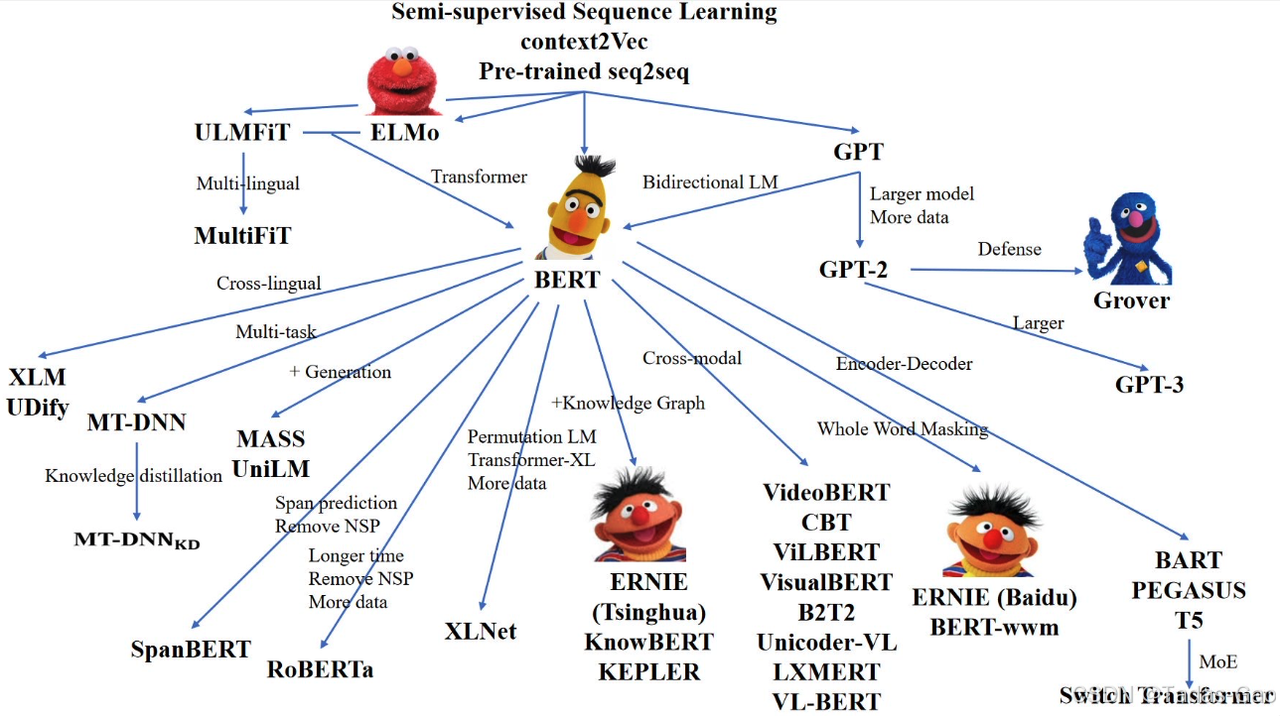
BERT 和 GPT 是基于 Transformer 模型架构的两种不同类型的预训练语言模型。它们之间的角逐可以从 Transformer 的编码解码结构角度来分析。
BERT(Bidirectional Encoder Representations from Transformers):
- Bert 主要基于编码器结构,采用了双向 Transformer 编码器的架构。它在预训练阶段使用了大量的无标签文本数据,通过 Masked Language Model(MLM)任务来学习双向上下文表示。Bert 只使用编码器,不包含解码器部分,因此在生成文本方面有一定局限性。
- Bert 的优势在于能够更好地理解句子中的上下文信息,适用于各种自然语言处理任务,如文本分类、语义理解和命名实体识别等。
GPT(Generative Pre-trained Transformer):
- GPT 则是基于 Transformer 的解码器结构,采用了自回归的方式来进行预训练。它通过语言模型任务来学习生成文本的能力,可以根据输入文本生成连续的文本序列。GPT 在预测下一个词的过程中,考虑了所有前面的词,从而能够逐步生成连贯的文本。
- GPT 在生成文本方面表现出色,能够生成流畅的语言并保持一致性。但由于没有编码器部分,GPT 不擅长处理双向上下文信息。
BERT 和 GPT 在编码解码结构方面有着明显的差异。BERT 更适用于需要双向上下文信息的任务,而 GPT 则擅长生成连贯的文本。在实际应用中,可以根据任务需求选择合适的模型进行使用。
GPT(Generative Pre-trained Transformer)诞生于2018年,采用解码器架构,以无监督学习方式预训练。它通过大规模文本数据的学习,能够生成自然流畅的文本,并在多项自然语言处理任务中取得了较好的成绩。然而,虽然GPT在生成型任务上表现卓越,但在理解和联系信息方面相对较弱。
相比之下,BERT(Bidirectional Encoder Representations from Transformers)于2018年底问世,采用编码器架构,通过双向训练方式将上下文信息有效地融入到语言表示中。BERT的出现引领了预训练技术的新浪潮,迅速成为自然语言处理领域的一匹黑马。其优势在于对上下文信息的充分利用,使得在理解和推断任务上有着出色的表现。
不可否认,BERT家族的发展壮大,吸引了众多研究者和工程师的关注,取得了许多重要的突破。然而,GPT作为一种全新的生成式模型,也顺利地在自然语言处理领域站稳了脚跟。它在生成任务上展现出的出色表现,逐渐赢得了更多人的喜爱和认可。
在两个顶尖模型之间的角逐中,GPT虽然起步较晚,但其独特的架构和颠覆性的设计,使得它在自然语言处理的发展中扮演着不可或缺的角色。BERT的强大并不意味着GPT的失败,两者各有所长,相互之间的竞争与合作将推动自然语言处理技术的不断进步和创新。在未来的发展中,无论是GPT还是BERT,都将在人工智能领域继续书写属于自己的辉煌篇章。
从 GPT 的发展来看技术的演进过程。
GPT-1:学会微调(Finetune)
GPT-1的训练数据是从哪里获取的呢?GPT-1是基于海量的无标签数据,通过对比学习来进行训练的。这个思路来源于从 Word2Vec 到 ELMo 的发展过程中积累的经验。它们都通过在大规模文本数据上进行无监督预训练,学习到了丰富的语言知识。
GPT-1的微调方法是,使用预训练好的模型来初始化权重,同时在 GPT-1 的预训练模型后面增加一个线性层,最后只要根据下游具体 NLP 任务的训练数据来微调更新模型的参数就可以了。
下图展示了四个经典 NLP 场景的改造方法,分别是文本分类、蕴含关系检测、相似性检测和多项选择题的改造方式。通过这样的微调策略,GPT-1能够迅速适应各种NLP任务,而无需重新训练整个模型。
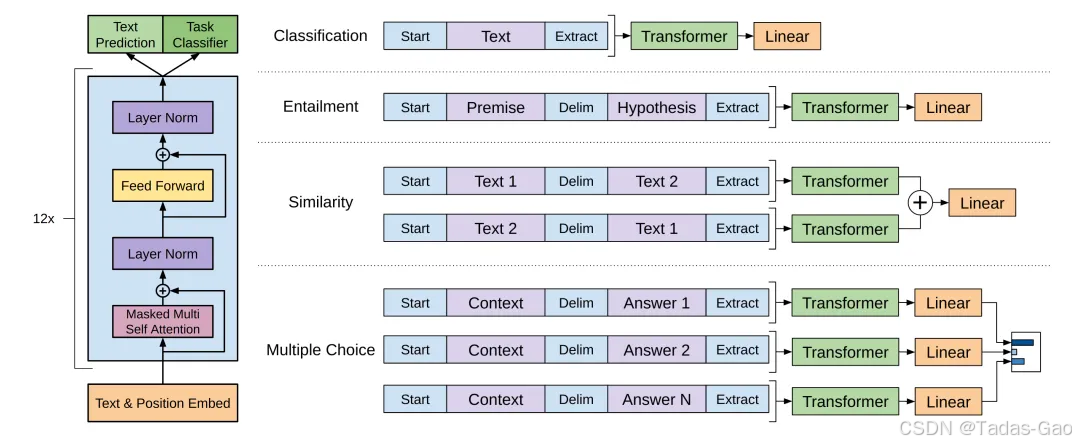
GPT-1的模型结构其实就是 Transformer 的架构。与 Transformer 不同的是,GPT-1 使用了一个只包含解码器部分的架构。它是一个单向的语言模型,通过自回归地生成文本,来模拟序列生成的过程。自回归指的是使用前面的观测值,来预测未来的值,GPT模型一个词一个词往外“蹦”,就是源于它的特性。
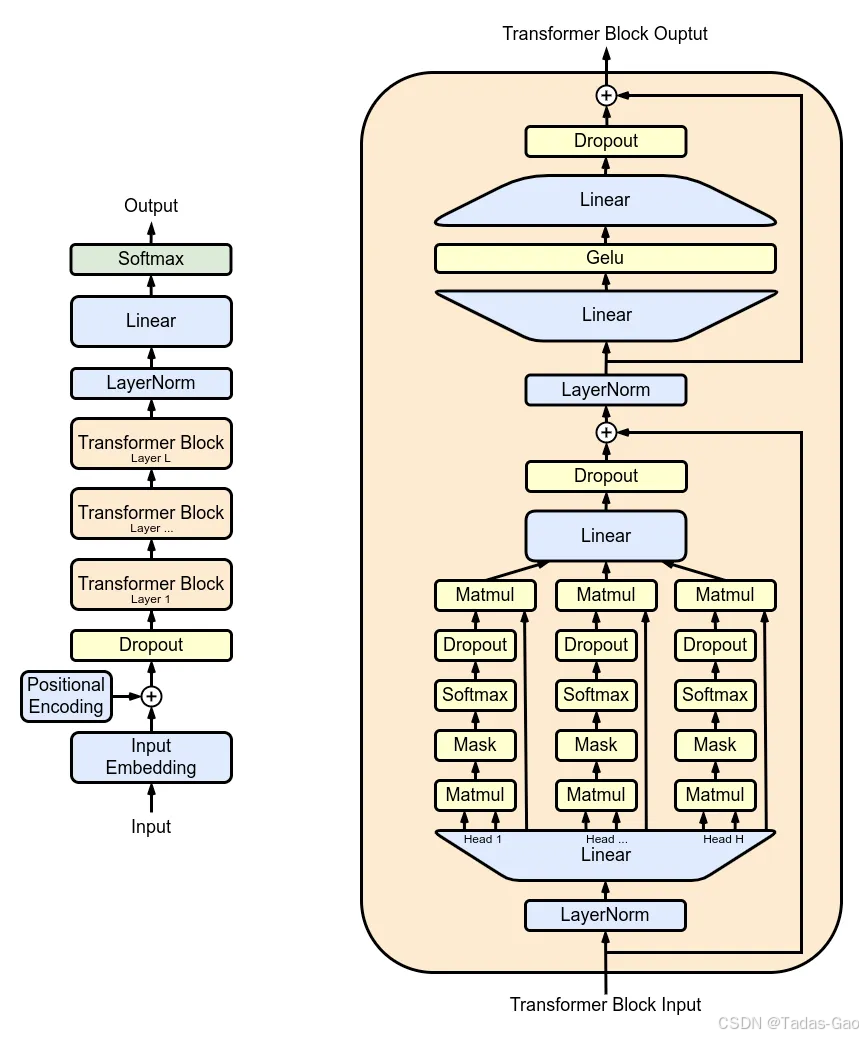
| Transformer层 | 类比的语言层级 | 具体功能示例 |
| 第1层 | 单词/局部语法 | - 识别词性(动词/名词) - 捕捉邻近词关系(如“吃”→“苹果”) |
| 第2~3层 | 句子结构 | - 分析主谓宾关系 - 处理短距离指代(如“他”→“医生”) |
| 深层(4~6+层) | 篇章/语义 | - 理解长程依赖(如跨句指代) - 把握情感倾向或逻辑连贯性 |
具体层数分配因模型规模和任务而异,例如BERT-base有12层,GPT-3多达96层。
在自回归生成的过程中,GPT-1 会为序列开始后的每个时刻生成一个词,并把它当作下一个时刻生成的上下文。
GPT-1 在训练过程中则会根据海量数据,统筹考量不同上下文语境下生成的文本在语法和语义上的合理性,来动态调整不同词的生成概率,这个能力主要由它所使用的 12 个 Transformer 共同提供。
这便是 GPT-1 所提供的一整套完备的预训练加微调的 NLP PTM 方法论,它也是第一个提出这种方法的。从这个角度说,GPT-1 的创新度是在 BERT 之上的。
GPT-2:放下微调(Zero-shot)
BERT 是在 GPT-1 诞生后不久发布的,BERT 使用了与 GPT-1 类似的思想和更大数据集,达到了比它更好的效果,所以 OpenAI 团队一直在憋着想要打赢这场翻身仗,他们的反击,就是 GPT-2。
GPT-2 第一次推出了 WebText 这个百万级别的数据集。BERT 你的数据多是吧?我比你还多。而且,GPT-2 还使用了比 BERT 更大的 15 亿参数的 Transformer,BERT 你模型大吧?我比你还大。有了更大的数据集和参数,GPT-2 就能更好地捕捉复杂的语言特征和更长距离的上下文语义关系。
事实证明,GPT-2在各种标准任务中表现出色。然而,OpenAI团队并没有满足于在标准任务上取得的进步,而是想到既然已经投入了大量资源来构建这个“小怪物”,为什么还需要下游任务进行微调呢?
零样本学习就此诞生。
那什么是零样本学习呢,就是创造一个通用的、不需要任何额外样本,就能解决所有下游任务的预训练大模型。
于是,这次 OpenAI 索性就把所有可能用到的下游任务数据汇集成了一个多任务学习(MTL)的数据集,并将这些数据都加入到了 GPT-2 模型的训练数据当中,想要看看到底能合成出一个什么样的“新物种”。
这个想法很有吸引力,但是如果不进行下游任务的微调,模型要怎么知道自己该做什么任务呢。这时,OpenAI 提出了一种影响了后续所有语言模型工作的方法,那就是通过提示词(prompt)的方式,来告知模型它需要解决什么问题。
OpenAI 在预训练过程中,将各类 NLP 任务的数据都放到 GPT-2 的训练数据中,帮助大模型更好地理解和生成文本。在经过这些步骤以后,GPT-2 的预训练模型在未经过任何微调的情况下,就能战胜许多下游任务的最佳结果。
它不仅在很多 NLP 任务上超越了 BERT,还成功地提出并完成了 “零样本学习” 这个更为困难的任务。
GPT-3:超越微调(in-Context Learning)
“零样本学习”的方式仍然存在一定的局限性,因为下游的使用者,很难把新的下游数据注入到模型中,因为 GPT-3 预训练模型的规模已经变得非常庞大了,它是当时规模最大的模型之一,具有惊人的 1750 亿个参数,很少有机构有能力承担微调所需的巨大算力成本。
于是,OpenAI 提出了一个更新的理念,也就是全新的“少样本学习”(Few-Shot Learning)的概念。这和传统意义上模型微调的“少样本学习”是不一样的。GPT-3 所提出的方式是,允许下游使用者通过提示词(prompt)直接把下游任务样本输入到模型中,让模型在提示语中学习新样本的模式和规律,这种方法的学名叫做in-context learning。
def translate(text, model):instruction = "Translate the following English text to French:\n"example = "sea otter => loutre de mer\n"task = text + " => "# Construct the promptprompt = f"{instruction}{example}{task}"translation = model.generate_text(prompt)return translation这种方法也存在缺点,其中最明显的问题是,注入样本的数量完全受限于模型能接收的最大提示词长度。这就导致 GPT 向着参数规模越来越大、训练数据越来越多,还有提示词输入长度越来越长这样的趋势发展。你在 GPT-4 的各项参数中,一定也发现了这个规律。
正是 GPT-3 这种基于提示词的开放输入方式,让用户可以直接与大语言模型(LLM)进行互动,逐渐开始感受到了大模型的"涌现"和"思维链"等能力的魅力和价值。
GPT-3 的问世也引发了中小企业的担忧,这么高昂的训练成本可能会导致大公司在技术方面形成垄断,这让全球各公司逐渐认识到当中蕴含的价值,纷纷开始加入这场技术军备竞赛,这直接导致了 NVIDIA 的公司股价持续攀升。
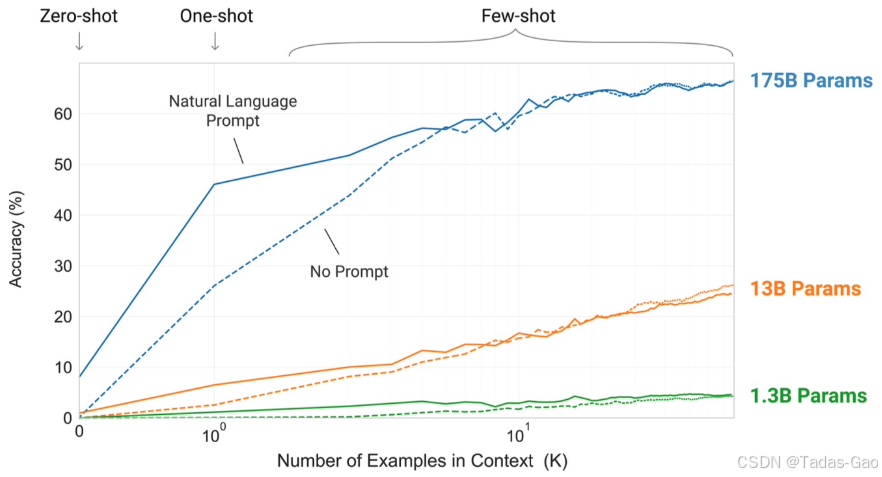
从上图可看出:不管多少参数量下,少样本学习的效果都明显优于零样本学习和One-shot。
OpenAI 的模型迭代:预训练与微调的共舞
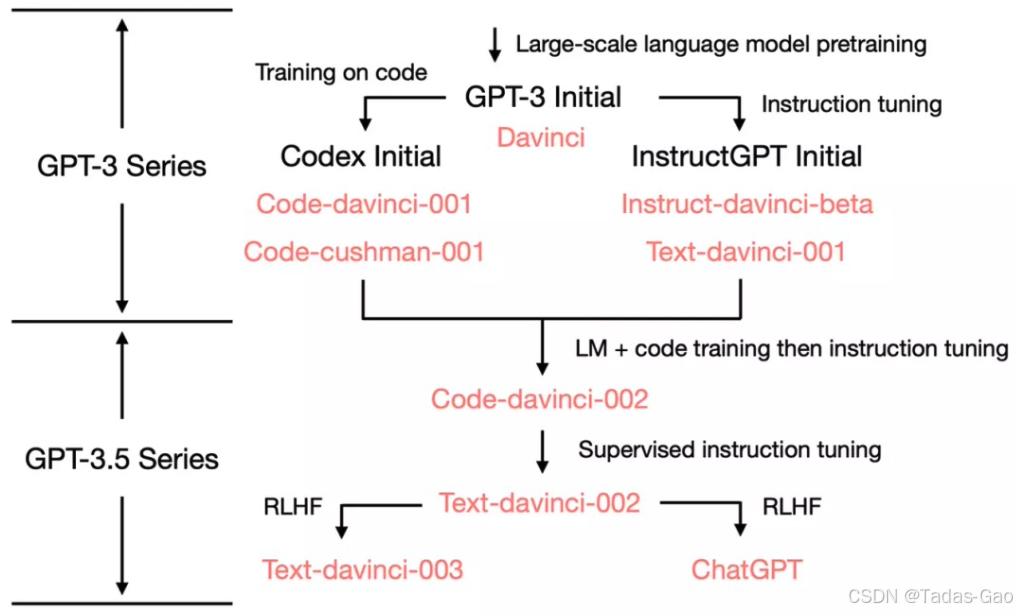
1. GPT-3 Initial(起点)
-
这是最初的 GPT-3 基础模型,发布于 2020 年。
-
从这一起点分出两条主要路径:
-
Codex 分支(面向代码生成)
-
InstructGPT 分支(面向指令微调)
-
2. 第一条分支:Codex Initial
-
目标:专注于代码生成和补全任务。
-
衍生模型:
-
Code-davinci-001:早期代码生成模型,能力较强。
-
Code-cushman-001:轻量级代码模型,响应速度更快。
-
3. 第二条分支:InstructGPT Initial
-
目标:优化对指令的理解和响应,更适合交互式任务。
-
衍生模型:
-
Instruct-davinci-beta:早期指令调优的实验性模型。
-
Text-davinci-001:初步融合代码和指令能力的模型。
-
4. 分支合并:Code-davinci-002 进入 GPT-3.5 系列
-
关键节点:Code-davinci-002 的能力被整合到 GPT-3.5 系列中。
-
产出模型:
-
Text-davinci-002:作为 GPT-3.5 系列的起点,兼具代码和文本能力。
-
5. GPT-3.5 系列的进一步分化
从 Text-davinci-002 开始,分出两条新的路径:
-
Text-davinci-003
-
迭代优化的通用文本模型,改进了指令微调和生成质量。
-
主要用于 API 和文本生成任务。
-
-
ChatGPT
-
专注于对话交互的模型,基于人类反馈强化学习(RLHF)优化。
-
发布于 2022 年 11 月,成为面向大众的对话式 AI。
-
关键点
-
Codex 和 InstructGPT 是平行发展的两条技术路线,分别侧重代码和指令理解。
-
GPT-3.5 系列是技术整合的产物,尤其是 Code-davinci-001 的代码能力被融入。
-
ChatGPT 是 GPT-3.5 的对话专用分支,通过 RLHF 大幅优化交互体验。
这一路径反映了 OpenAI 从通用模型(GPT-3)到垂直优化(代码、指令),再通过技术整合推出更强的通用模型(GPT-3.5)的战略。
遇见都是天意,记得点赞收藏哦!
,用于解决无人机三维路径规划问题,Matlab代码实现)

![MCP:让AI工具协作变得像聊天一样简单 [特殊字符]](http://pic.xiahunao.cn/MCP:让AI工具协作变得像聊天一样简单 [特殊字符])








![洛谷P12610 ——[CCC 2025 Junior] Donut Shop](http://pic.xiahunao.cn/洛谷P12610 ——[CCC 2025 Junior] Donut Shop)

Java/python/JavaScript/C++/C语言/GO六种最佳实现)



)

