一、大模型微调
1.1、解释
微调(Fine-tuning)是在预训练大模型基础上,针对特定领域数据进行二次训练的技术过程。这一过程使大型语言模型(如GPT、BERT等)能够更好地适应具体应用场景,显著提升在专业领域的表现。
1.2、微调的基本流程
-
模型选择:根据任务类型选择合适的预训练模型(如GPT用于生成任务,BERT用于分类任务)
-
数据准备:收集整理与目标领域相关的高质量训练数据
-
参数调整:优化学习率、训练轮次、批次大小等关键参数
-
模型训练:在保持原有知识的基础上融入领域专业知识
-
验证优化:通过测试集评估效果,进行必要的参数调整和迭代
1.3、微调的核心价值
性能提升
显著提高模型在特定领域的表现精度
使模型掌握专业术语和领域知识(如法律、医疗等)
资源效率
相比从头训练可节省90%以上的计算资源
大幅缩短模型开发周期和部署时间
功能增强
保持通用能力的同时获得专业领域优势
提升对领域细微差异的识别和处理能力
商业价值
支持企业级个性化定制(如品牌语调和风格适配)
实现生产环境中的高效精准服务(如金融客服场景)
持续进化
快速适应语言变化和新词汇
跨文化语境保持优异表现
微调技术使大模型在保留强大通用能力的同时,能够深度适配垂直领域需求,是AI应用落地的关键环节。通过精细化的微调过程,企业可以以较低成本获得高度专业化的智能解决方案。
二、参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)
参数高效微调(PEFT) 是一种针对大规模预训练模型(如 GPT、Qwen、DeepSeek等)的优 化策略。其核心思想是通过仅调整少量参数或引入额外的轻量级模块,来实现对新任务的快速 适配,而无需对整个模型进行重新训练。这种方法在资源受限的场景中表现出色,显著降低了 计算成本和存储需求,同时避免了传统微调方法可能导致的过拟合问题。
面临挑战:
高计算成本:需要更新数十亿甚至上百亿、上千亿个参数,消耗大量 GPU/TPU/NPU 资 源。
高存储需求:每个任务都需要保存一份完整的模型副本,占用大量存储空间。
易过拟合:在小数据集上微调时,容易导致模型性能下降。
传统微调的局限性
资源消耗大:传统微调需要更新模型的所有参数,计算和存储开销巨大。
任务间干扰:当模型需要适配多个任务时,全参数微调可能导致不同任务之间的冲突。
难以扩展:对于大规模模型,全参数微调的可扩展性较差,尤其在多任务场景下。
PEFT 的优势
低资源需求:仅需更新少量参数或引入轻量级模块,显著降低计算和存储成本。
任务隔离性:通过冻结原始模型参数,避免任务间的干扰,提升模型的鲁棒性。
快速部署:适用于资源受限环境(如边缘设备),支持快速迭代和部署。
三、常用方法
| 方法名称 | 核心思想 | 参数更新量 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|---|
| BitFit | 仅更新模型中的偏置参数 | 极少 | 资源受限场景 | 简单高效,计算成本极低 | 表达能力有限,性能提升较小 |
| Prompt Tuning | 优化输入提示词(硬提示) | 较少 | 分类、生成任务 | 表现稳定,不修改模型结构 | 提示设计复杂,依赖人工经验 |
| Prefix Tuning | 添加可训练的前缀向量 | 中等 | 生成式任务 | 灵活性强,效果优于Prompt | 计算成本较高,需要更多显存 |
| P-Tuning | 在输入层加入可训练的"软提示" | 较少 | 小数据集任务 | 轻量化,适合资源有限场景 | 对超参数敏感,调优难度较大 |
| Adapter | 在网络层间插入小型适配器模块 | 中等 | 多任务学习、跨领域迁移 | 模块化设计,扩展性强 | 增加推理延迟,结构设计复杂 |
| LoRA | 通过低秩分解更新参数矩阵 | 极少 | 超大规模模型微调 | 高效且性能接近全参数微调 | 需要矩阵秩选择经验 |
| (IA)³ | 注入可学习的缩放激活向量 | 极少 | 多任务学习 | 参数效率极高 | 训练稳定性需要精细控制 |
| QLoRA | 量化+LoRA的混合方法 | 极少 | 超大规模模型的低资源微调 | 可在单卡上微调超大模型 | 需要量化专业知识 |
| Freeze | 冻结大部分参数仅微调顶层 | 较少 | 领域适应任务 | 简单直接,资源消耗低 | 可能丢失底层重要特征 |
| DiffPruning | 差异化剪枝+参数更新 | 中等 | 需要模型压缩的场景 | 可生成稀疏化模型 | 实现复杂度高 |
四、BitFit
BitFit 是一种稀疏微调方法,其核心思想是仅更新模型中的偏置(bias)参数,而保持权重 (weight)参数不变。
优点:参数更新量极小,适合资源极度受限的场景。
缺点:可能无法充分捕捉复杂任务的特征。
论文地址:[2106.10199] BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
使用AutoModelForCausalLM加载因果语言模型
from transformers import AutoModelForCausalLMmodel_name = "/home/AI_big_model/models/Qwen/Qwen2.5-7B-Instruct"model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto")
冻结其它参数,只保留bias可训练
for name, param in model.named_parameters():if "bias" not in name:param.requires_grad = False # 冻结参数设置随机数种子
torch.manual_seed(42)
if torch.cuda.is_available():torch.cuda.manual_seed(42)设置分词器
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)处理和加载训练数据
class CustomDataset(Dataset):def __init__(self, file_path, tokenizer, max_length=128):"""filr_path: 数据集路径tokenizer: 分词器max_length: 每个样本的最大长度,超过部分会被截断,不足的被填充"""self.file_path = file_pathself.tokenizer = tokenizerself.max_length = max_lengthself.data = [] # 存放数据集的所有样本with open(self.file_path, "r", encoding="utf-8") as f:data_list = json.load(f) # 读取json文件for item in data_list:self.data.append(item)def __len__(self):return len(self.data)def __getitem__(self, idx):# 获取对应索引的样本数据example = self.data[idx]# 使用分词器处理指令部分的文本,不需要添加特殊标记。# 整理的格式是和qwen要保持统一的。instruction = self.tokenizer(f"<|im_start|>system\n<|im_end|>\n<|im_start|>user\n{example['instruction']}<|im_end|>\n<|im_start|>assistant\n",add_special_tokens=False,)# 使用分词器处理输出部分的文本,不需要添加特殊标记。response = self.tokenizer(f"{example['output']}",add_special_tokens=False,)# 将指令和输出的token id拼接在一起input_ids = instruction["input_ids"] + response["input_ids"]# 合并attention_maskattention_mask = (instruction["attention_mask"] + response["attention_mask"])# 创建标签 labels# instruction部分的标签是-100,表示不参与训练,计算损失时会忽略这些位置# 因为模型只需要学习生成目标部分,也就是assistant的回复内容labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]if len(input_ids) > self.max_length: # 如果序列长度超过128,那么截断input_ids = input_ids[:self.max_length]attention_mask = attention_mask[:self.max_length]labels = labels[:self.max_length]else: # 如果不足128,需要填充padding_len = self.max_length - len(input_ids)input_ids = input_ids + [self.tokenizer.pad_token_id] * padding_lenattention_mask = attention_mask + [0] * padding_lenlabels = labels + [self.tokenizer.pad_token_id] * padding_len# 返回构建好的张量return {"input_ids": torch.tensor(input_ids),"attention_mask": torch.tensor(attention_mask),"labels": torch.tensor(labels),}transformers trainer训练
from transformers import Trainer, TrainingArguments, DataCollatorForSeq2Seq
args = TrainingArguments(output_dir="./chatbot/",per_device_train_batch_size=4, # bs=4gradient_accumulation_steps=8, # 梯度累计后,相当于bs=32logging_steps=10, # 每10步打印一次日志max_steps=1000, # 最大训练步数learning_rate=6e-4, # 学习率lr_scheduler_type="cosine", # 学习率调度器warmup_ratio=0.1, # warmup比例bf16=True, # 是否使用bf16save_steps=100, # 保存模型的步数
)# 实例化Trainer
trainer = Trainer(model=model, # 模型args=args, # 训练参数train_dataset=dataset, # 训练数据集data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True) # 数据收集器
)trainer.train()五、提示微调(Prompt Tuning)
Prompt Tuning(提示调优)是一种通过优化输入的"提示"来调整模型行为的方法,它通过引入可训练的"软提示"(Soft Prompts)来实现对预训练模型的引导,而不需要修改模型本身的参数。
| 特性 | 软提示 (Soft Prompt) | 硬提示 (Hard Prompt) |
|---|---|---|
| 形式 | 可训练的嵌入向量 | 自然语言文本 |
| 可读性 | 非人类可读的连续向量 | 人类可读的离散文本 |
| 参数 | 需要优化提示向量 | 固定不变 |
| 灵活性 | 可通过训练自动优化 | 需要人工设计 |
| 存储 | 通常需要额外存储少量提示参数 | 无需额外存储 |
技术特点
参数高效:仅需优化少量提示参数(通常占模型总参数的0.1%-1%)
模型冻结:保持原始预训练模型参数不变
任务适配:通过提示向量引导模型适应特定任务
计算高效:相比全参数微调,训练成本显著降低
软提示的实现步骤
(1) 初始化软提示
嵌入向量的形状:假设我们希望插入n个软提示向量,每个向量的维度为d(与模型的词 嵌入维度一致)。那么软提示的形状为(n,d) 。
随机初始化:这些嵌入向量通常使用标准正态分布或其他初始化方法(如均匀分布)进行随 机初始化。
(2) 将软提示插入输入序列
原始输入:预训练模型的输入通常是经过分词器(Tokenizer)处理后的标记序列(Token Sequence),其形状为[B,L,D] ,其中:
B是批量大小(Batch Size)。
L是序列长度(Sequence Length)。
D是词嵌入维度(Embedding Dimension)。
插入位置:软提示通常被插入到输入序列的开头(或特定位置)。例如,将其拼接到原始输 入序列的前面。
(3) 输入到模型
将拼接后的嵌入向量作为模型的输入,传递给预训练模型进行前向传播。
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name = "/home/AI_big_model/models/Qwen/Qwen2.5-7B-Instruct"torch.manual_seed(42)
if torch.cuda.is_available():torch.cuda.manual_seed(42)# 移动模型到 GPU (如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载预训练的因果语言模型
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="bfloat16").to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name)# # 打印模型结构,查看原始模型的架构和参数
# print("原始模型结构:")
# print(model)"""------------------------------------------------------------------------------------------------"""# PromptTuningConfig是用于配置提示微调(Prompt Tuning)参数的类
# 它可以帮助定义微调过程中所需的各项配置,如学习率、批次大小等
# TaskType是一个枚举类,用于指定模型处理的任务类型,例如序列分类、命名实体识别等
# get_peft_model是一个用于根据配置获取具体微调模型的函数
# 通过这个函数,用户可以根据自己的需求获取到适合任务的微调模型实例
from peft import PromptTuningConfig, get_peft_model, TaskType# 定义一个提示文本(prompt),用于引导模型的行为
# 这段文本将作为虚拟 token 的初始化内容,告诉模型如何扮演特定角色# 可以使用:
# config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM, num_virtual_tokens=10)# 但是为了追求快速实现和语义引导,建议使用 prompt_encoder。
prompt = "请使用以上角色回答用户问题。"# 配置 Prompt Tuning 参数
config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM, # 指定任务类型为因果语言建模(Causal Language Modeling)num_virtual_tokens=len(tokenizer(prompt)["input_ids"]), # 设置虚拟 token 的数量# 虚拟 token 的数量由提示文本的 token 数量决定prompt_tuning_init_text=prompt, # 使用提示文本初始化虚拟 token 的嵌入tokenizer_name_or_path=model_name,
)
print(config)
# import sys;sys.exit(0)
# 创建 PEFT 模型
# 将原始模型与 Prompt Tuning 配置结合,生成一个新的支持 Prompt Tuning 的模型
model = get_peft_model(model, config)
# print("PEFT模型结构:")
# print(model)
# import sys;sys.exit(0)
# print(sum(p.numel() for p in model.parameters() if p.requires_grad))六、P-tuning
P-Tuning 是一种基于“软提示”的微调方法,其核心思想是通过引入一组可学习的“软提示”(Soft Prompt)嵌入向量来调整预训练语言模型的行为。与传统的硬提示(Hard Prompt,即直接在 输入文本中添加自然语言提示)不同,P-Tuning 的软提示是以连续的嵌入向量形式存在,并且 这些嵌入向量是通过训练优化得到的。
与 Prompt Tuning 的区别:
提示生成方式:Prompt Tuning 直接使用随机初始化的嵌入向量作为软提示,而 P Tuning 使用一个小型的神经网络(称为“提示生成器”)动态生成软提示,从而增强软提 示的表现力。
复杂度:Prompt Tuning 的实现较为简单,仅限于输入层;而 P-Tuning 的实现更加复 杂,可能涉及多层优化或动态调整机制。
适用场景:Prompt Tuning 更适合简单任务(如分类),而 P-Tuning 更适合复杂任务 (如生成式任务)。
P-Tuning 实现步骤
(1) 初始化软提示
软提示的形状:假设我们希望插入 个软提示向量,每个向量的维度为 (与模型的词嵌 入维度一致)。那么软提示的形状为 。
随机初始化:这些嵌入向量通常使用标准正态分布或其他初始化方法(如均匀分布)进行随 机初始化。
提示生成器:P-Tuning 的软提示通常由一个小型神经网络(提示生成器)动态生成,而不 是直接随机初始化。
(2) 将软提示插入输入序列
原始输入:预训练模型的输入通常是经过分词器(Tokenizer)处理后的标记序列(Token Sequence),其形状为(B,L,D) ,
其中: B是批量大小(Batch Size)。
L是序列长度(Sequence Length)。
D是词嵌入维度(Embedding Dimension)。
插入位置:软提示通常被插入到输入序列的开头(或特定位置)。例如,将其拼接到原始输 入序列的前面。
(3) 输入到模型
将拼接后的嵌入向量作为模型的输入,传递给预训练模型(如 BERT、GPT 等)进行前向传播。
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name = "./models/Qwen/Qwen2___5-0___5B-Instruct"torch.manual_seed(42)
if torch.cuda.is_available():torch.cuda.manual_seed(42)# 移动模型到 GPU (如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")from peft import PromptEncoderConfig, TaskType, get_peft_model, PromptEncoderReparameterizationType
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)print("原始模型结构:")
print(model)# 初始化PromptEncoderConfig配置对象
# 该配置用于定义提示编码器的参数,以适应特定的任务类型
# 参数:
# task_type: 任务类型,这里设置为因果语言模型(CAUSAL_LM)
# num_virtual_tokens: 虚拟令牌的数量,这里设置为10
# encoder_reparameterization_type: 编码器重新参数化类型,这里使用LSTM
config = PromptEncoderConfig(task_type=TaskType.CAUSAL_LM,num_virtual_tokens=10,encoder_reparameterization_type=PromptEncoderReparameterizationType.LSTM,)# 创建 peft model
model = get_peft_model(model, config)
print("PEFT模型结构:")
print(model)
# import sys;sys.exit(0)
# print(sum(p.numel() for p in model.parameters() if p.requires_grad))
total_params = 0
for name, param in model.named_parameters():if param.requires_grad:print(f"{name}: {param.shape} -> {param.numel()}")total_params += param.numel()
print(f"Total trainable parameters: {total_params}")总结
Prompt Tuning 是一种简单高效的微调方法,适合资源受限场景和简单任务。它的实现方 式直接且易于理解,但表现力相对有限。
P-Tuning 则通过引入提示生成器等机制增强了软提示的表现力,适合复杂任务(如生成式 任务)和对性能要求较高的场景。虽然其实现复杂度和计算成本略高,但在生成式任务中表 现出色。
推荐使用 Prompt Tuning 的场景
资源受限环境:边缘设备、移动端部署
简单判别任务:文本分类、情感分析、实体识别
快速原型开发:需要快速验证模型适配性的场景
少样本学习:训练数据少于1,000条时效果显著
推荐使用 P-Tuning 的场景
复杂生成任务:对话生成、文本摘要、创意写作
多步推理任务:数学解题、逻辑推理、复杂问答
领域自适应:需要深度调整模型行为的情况
数据充足时:训练数据超过10,000条时优势明显
| 特性 | Prompt Tuning | P-Tuning |
|---|---|---|
| 核心思想 | 直接优化连续提示嵌入 | 通过提示生成器产生动态提示 |
| 参数更新量 | 仅提示参数(0.1%-1%模型参数) | 提示生成器参数(1%-5%模型参数) |
| 模型改动 | 无结构改动 | 需添加提示生成器模块 |
| 训练效率 | 极高(仅反向传播提示参数) | 较高(需训练小型神经网络) |
| 任务表现力 | 适用于简单分类/回归任务 | 擅长复杂生成/推理任务 |
| 实现复杂度 | ★★☆ | ★★★☆ |
| 硬件需求 | 单卡GPU即可运行 | 可能需要更大显存 |
| 任务类型 | Prompt Tuning (准确率) | P-Tuning (准确率) |
|---|---|---|
| 文本分类 | 92.3% | 93.1% |
| 实体识别 | 88.7% | 89.5% |
| 文本生成(ROUGE) | 0.65 | 0.72 |
| 数学推理 | 54.2% | 68.9% |
七、Prefix-tuning
Prefix Tuning 核心思想是在模型的输入中添加一组可训练的前缀向量(Prefix Vectors),这 些向量作为任务特定的上下文信息,帮助模型适应新任务。与 Prompt Tuning 不同的是, Prefix Tuning 的前缀向量通常被插入到 Transformer 模型的每一层,而不仅仅是输入层。
特点:
前缀向量可以看作是模型输入的一部分,影响模型的输出。
相较于 Prompt Tuning 更灵活,适用于生成式任务(如对话、翻译)。
优势:在生成任务中表现优异,同时保留了原始模型的通用性。
实现步骤
(1) 初始化前缀向量
前缀向量的形状:假设我们希望为每个 Transformer 层插入n个前缀向量,每个向量的维 度为 d(与模型的隐藏层维度一致)。那么前缀向量的形状为[L,n,d] ,
其中: L是 Transformer 层数。
n是每层前缀向量的数量。
d是隐藏层维度。
随机初始化:这些前缀向量通常使用标准正态分布或其他初始化方法进行随机初始化。
(2) 将前缀向量插入 Transformer 层
Transformer 的结构:Transformer 模型的每一层包含两个主要部分:
自注意力机制(Self-Attention):计算输入序列的注意力权重。
前馈网络(Feed-Forward Network, FFN):对注意力输出进行非线性变换。
插入位置:前缀向量被插入到每一层的自注意力机制中,作为额外的上下文信息。
(3) 输入到模型
将修改后的键值对传递给 Transformer 模型的每一层,完成前向传播。
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name = "./models/Qwen/Qwen2___5-0___5B-Instruct"# 构建数据集
import jsontorch.manual_seed(42)
if torch.cuda.is_available():torch.cuda.manual_seed(42)# 移动模型到 GPU (如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# PromptTuningConfig是用于配置提示微调(Prompt Tuning)参数的类
# 它可以帮助定义微调过程中所需的各项配置,如学习率、批次大小等
# TaskType是一个枚举类,用于指定模型处理的任务类型,例如序列分类、命名实体识别等
# get_peft_model是一个用于根据配置获取具体微调模型的函数
# 通过这个函数,用户可以根据自己的需求获取到适合任务的微调模型实例
from peft import PrefixTuningConfig, get_peft_model, TaskTypemodel = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="bfloat16").to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name)# print("原始模型结构:")
# print(model)# 创建一个PrefixTuningConfig对象,用于配置前缀调优的参数
# 参数task_type指定任务类型为因果语言模型(CAUSAL_LM)
# 参数num_virtual_tokens指定虚拟令牌的数量为15,这些虚拟令牌作为前缀使用
# 设置prefix_projection为True,意味着在前缀和模型主体之间会有一个投影层
config = PrefixTuningConfig(task_type=TaskType.CAUSAL_LM,num_virtual_tokens=15,prefix_projection=True,)# 创建 peft model
model = get_peft_model(model, config)
# print("PEFT模型结构:")
# print(model)
# import sys;sys.exit(0)
print(sum(p.numel() for p in model.parameters() if p.requires_grad))八、LORA
低秩适配(LoRA) 是一种基于低秩分解的参数高效微调(PEFT)方法。其核心思想是将需要 调整的权重矩阵分解为两个低秩矩阵,并仅训练这些低秩矩阵,而原始模型的权重保持冻结。 这种方法通过低秩近似显著减少了需要训练的参数量,同时保持了较高的任务性能。
| 对比项 | LoRA(Low-Rank Adaptation) | QLoRA(Quantized LoRA) |
|---|---|---|
| 核心思想 | 在模型的权重矩阵上添加低秩适配层(Low-Rank Adapters),并仅训练这部分参数 | 先将模型量化到更低的精度(如 4-bit),再应用 LoRA 进行训练 |
| 是否量化 | ❌ 否,保持原始模型权重精度 | ✅ 是,使用 4-bit 量化(NF4 量化格式) |
| 计算效率 | 需要全精度(FP16 或 BF16)存储模型 | 量化后大幅降低显存占用 |
| 显存占用 | 高(需要存储 LoRA 适配层和全模型) | 低(4-bit 量化后显存需求减少 3-4 倍) |
| 训练速度 | 需要更高的显存,但仍比全量微调快 | 由于量化,计算更高效,适合更大模型 |
| 适用场景 | 适用于 中等规模 LLM(如 7B、13B) | 适用于 超大规模 LLM(如 30B、65B) |
| 存储需求 | 需要存储 FP16/BF16 权重 + LoRA 适配层 | 仅存储 4-bit 量化权重 + LoRA 适配层 |
| 推理性能 | 需要全精度计算,但开销比全量微调小 | 量化后推理更快,适用于低资源部署 |
import os
import torch
from transformers import AutoTokenizer, AutoModelForCausalLMmodel_name = "./models/Qwen/Qwen2___5-0___5B-Instruct"# 构建数据集
import jsontorch.manual_seed(42)
if torch.cuda.is_available():torch.cuda.manual_seed(42)# 移动模型到 GPU (如果可用)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载预训练的因果语言模型
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="bfloat16").to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name)# 打印模型结构,查看原始模型的架构和参数
print("原始模型结构:")
print(model)# target_modules = None 时Qwen2默认对q和v进行处理
from peft import PeftModel, PeftConfig, get_peft_model, LoraConfig, TaskType# 配置LoRA(Low-Rank Adaptation)参数以微调语言模型
config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 设置任务类型为因果语言模型(Causal Language Model)r=4, # 设置低秩矩阵的秩(rank)为4,影响模型的微调参数量和计算复杂度lora_alpha=32, # 设置LoRA的alpha参数为32,用于缩放注意力权重,影响模型性能lora_dropout=0.01, # 设置LoRA层的dropout概率为0.01,用于正则化防止过拟合# target_modules = ['query'] # (此行注释掉,未使用)可指定需要应用LoRA的模块,例如'query'注意力模块
)# 创建 peft model
model = get_peft_model(model, config)
print("PEFT模型结构:")
print(model)
# import sys;sys.exit(0)
# print(sum(p.numel() for p in model.parameters() if p.requires_grad))九、集合微调验证
微调
import json
import torch
from torch.utils.data import Dataset
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments, DataCollatorForSeq2Seq
from peft import (PromptTuningConfig,TaskType,get_peft_model,PromptEncoderConfig,PromptEncoderReparameterizationType,PrefixTuningConfig,LoraConfig,
)
import torch.nn as nnclass CustomDataset(Dataset):"""自定义数据集类,用于加载和预处理训练数据。"""def __init__(self, file_path, tokenizer, max_length=128):"""初始化数据集。Args:file_path: 数据集文件路径。tokenizer: 用于文本分词的tokenizer。max_length: 每个样本的最大长度,超出部分将被截断,不足部分将被填充。"""self.file_path = file_pathself.tokenizer = tokenizerself.max_length = max_lengthself.data = [] # 存放数据集的所有样本with open(self.file_path, "r", encoding="utf-8") as f:data_list = json.load(f) # 读取json文件for item in data_list:self.data.append(item)def __len__(self):"""返回数据集中的样本数量。"""return len(self.data)def __getitem__(self, idx):"""根据索引获取单个样本并进行处理。Args:idx: 样本的索引。Returns:一个字典,包含input_ids, attention_mask, 和 labels。"""# 获取对应索引的样本数据example = self.data[idx]# 使用分词器处理指令部分的文本,不需要添加特殊标记。# 整理的格式是和qwen要保持统一的。# <|im_start|> 和 <|im_end|> 是Qwen模型特有的对话标记。# system: 系统角色,user: 用户角色,assistant: 助手角色。instruction = self.tokenizer(f"<|im_start|>system\n<|im_end|>\n<|im_start|>user\n{example['instruction']}<|im_end|>\n<|im_start|>assistant\n",add_special_tokens=False, # 不添加tokenizer的默认特殊标记)# 使用分词器处理输出部分的文本,不需要添加特殊标记。response = self.tokenizer(f"{example['output']}",add_special_tokens=False, # 不添加tokenizer的默认特殊标记)# 将指令和输出的token id拼接在一起,形成完整的输入序列。input_ids = instruction["input_ids"] + response["input_ids"]# 合并attention_mask。attention_mask用于指示哪些token是实际内容(1)哪些是填充(0)。attention_mask = instruction["attention_mask"] + response["attention_mask"]# 创建标签 labels。# instruction部分的标签是-100,表示这些token在计算损失时会被忽略。# 这是因为在因果语言建模中,模型只需要学习生成assistant的回复内容。labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]if len(input_ids) > self.max_length: # 如果序列长度超过最大长度,则进行截断。input_ids = input_ids[: self.max_length]attention_mask = attention_mask[: self.max_length]labels = labels[: self.max_length]else: # 如果序列长度不足最大长度,则进行填充。padding_len = self.max_length - len(input_ids)input_ids = input_ids + [self.tokenizer.pad_token_id] * padding_len # 使用pad_token_id填充input_idsattention_mask = attention_mask + [0] * padding_len # attention_mask填充0labels = labels + [self.tokenizer.pad_token_id] * padding_len # labels也使用pad_token_id填充# 返回构建好的张量,转换为PyTorch tensor类型。return {"input_ids": torch.tensor(input_ids),"attention_mask": torch.tensor(attention_mask),"labels": torch.tensor(labels),}def change_model(model_name, selcet="Bitfit", file_path="./dataset/data.json"):"""根据选择的微调方法加载模型、tokenizer和数据集,并对模型进行相应的设置。Args:model_name: 预训练模型的名称或路径。selcet: 选择的微调方法("Bitfit", "Prompt-tuning", "P-tuning", "Prefix-tuning", "LORA")。file_path: 数据集文件路径。Returns:model: 配置好的模型。tokenizer: 对应的tokenizer。dataset: 处理好的数据集。"""# 从预训练模型加载因果语言模型model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto")# 从预训练模型加载分词器tokenizer = AutoTokenizer.from_pretrained(model_name)# 创建自定义数据集实例dataset = CustomDataset(file_path, tokenizer)if selcet == "Bitfit":# BitFit方法:只训练模型的偏置(bias)参数,冻结其他参数。for name, param in model.named_parameters():if "bias" not in name:param.requires_grad = False # 冻结非偏置参数elif selcet == "Prompt-tuning":# Prompt-tuning方法:通过添加可学习的虚拟token来调整模型的行为。prompt = "请使用以上角色回答用户问题。" # 定义一个提示文本config = PromptTuningConfig(task_type=TaskType.CAUSAL_LM, # 指定任务类型为因果语言建模num_virtual_tokens=len(tokenizer(prompt)["input_ids"]), # 虚拟token的数量由提示文本的token数量决定prompt_tuning_init_text=prompt, # 使用提示文本初始化虚拟token的嵌入tokenizer_name_or_path=model_name,)model = get_peft_model(model, config) # 获取PEFT模型elif selcet == "P-tuning":# P-tuning方法:使用一个编码器(如LSTM)来生成提示的嵌入。config = PromptEncoderConfig(task_type=TaskType.CAUSAL_LM, # 指定任务类型为因果语言建模num_virtual_tokens=10, # 虚拟token的数量encoder_reparameterization_type=PromptEncoderReparameterizationType.LSTM, # 编码器类型为LSTM)model = get_peft_model(model, config) # 获取PEFT模型elif selcet == "Prefix-tuning":# Prefix-tuning方法:在每个Transformer层前添加可学习的前缀。config = PrefixTuningConfig(task_type=TaskType.CAUSAL_LM, # 指定任务类型为因果语言建模num_virtual_tokens=15, # 虚拟token的数量作为前缀prefix_projection=True, # 在前缀和模型主体之间添加一个投影层)model = get_peft_model(model, config) # 获取PEFT模型elif selcet == "LORA":# LORA(Low-Rank Adaptation)方法:通过低秩矩阵分解来高效微调大模型。config = LoraConfig(task_type=TaskType.CAUSAL_LM, # 设置任务类型为因果语言模型r=4, # 设置低秩矩阵的秩,影响微调参数量lora_alpha=32, # LoRA的alpha参数,用于缩放注意力权重lora_dropout=0.01, # LoRA层的dropout概率# target_modules = ['query'] # 可以指定需要应用LoRA的模块,例如'query'注意力模块)model = get_peft_model(model, config) # 获取PEFT模型return model, tokenizer, datasetif __name__ == "__main__":# 配置训练参数args = TrainingArguments(output_dir="./chatbot/", # 模型输出目录per_device_train_batch_size=4, # 每个设备的训练批量大小gradient_accumulation_steps=8, # 梯度累积步数,相当于有效批量大小为 4 * 8 = 32logging_steps=10, # 每10步打印一次日志max_steps=1000, # 最大训练步数learning_rate=6e-4, # 学习率lr_scheduler_type="cosine", # 学习率调度器类型为cosinewarmup_ratio=0.1, # warmup比例,在前10%的步数内逐渐增加学习率bf16=True, # 是否使用bf16(bfloat16)混合精度训练save_steps=100, # 每100步保存一次模型)# 指定预训练模型路径model_name = "/home/AI_big_model/models/Qwen/Qwen2.5-0.5B-Instruct"# 调用change_model函数,根据选择的微调方法获取模型、tokenizer和数据集model, tokenizer, dataset = change_model(model_name,selcet="LORA", # 选择LORA微调方法file_path="/home/model_change/identity.json", # 数据集文件路径)# 实例化Trainertrainer = Trainer(model=model, # 待训练的模型args=args, # 训练参数train_dataset=dataset, # 训练数据集# 数据收集器,用于将样本批量化并进行填充data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),)# 开始训练模型trainer.train()| 模块包 | 主要功能 | 代码中主要用途 | 备注 |
json | 处理 JSON (JavaScript Object Notation) 数据格式。 | 从 .json 文件中加载训练数据集。 | Python 内置模块,用于数据序列化和反序列化。 |
torch | PyTorch 深度学习框架的核心库,提供张量计算能力。 | 将 Python 数据(如列表)转换为 PyTorch 张量 (Tensor),用于模型输入和计算。 | 支持 GPU 加速计算。 |
torch.utils.data.Dataset | PyTorch 中用于创建自定义数据集的抽象基类。 | 继承此类以实现 CustomDataset,定义如何加载和处理单个数据样本。 | 通常与 DataLoader 配合使用,实现数据的批量加载。 |
transformers | Hugging Face 提供的预训练模型和分词器库。 | 提供各种大模型(如 Qwen)及其配套工具。 | |
AutoModelForCausalLM | 自动加载因果语言模型,用于文本生成任务。 | 根据模型名称加载 Qwen 预训练模型。 | Auto 前缀表示自动识别模型架构。 |
AutoTokenizer | 自动加载与模型对应的分词器。 | 将文本转换为模型可理解的数字 ID 序列,并处理注意力掩码。 | 负责文本的预处理。 |
Trainer | Hugging Face 提供的高级训练 API。 | 封装了训练循环,简化模型训练、评估、日志记录和保存等流程。 | 大幅减少训练代码量。 |
TrainingArguments | 定义训练过程中的各种超参数和配置。 | 设置学习率、批量大小、训练步数、日志步数等。 | 用于配置 Trainer。 |
DataCollatorForSeq2Seq | 数据收集器,用于将单个样本组合成批次并进行填充。 | 对批次内的序列进行动态填充,以确保长度一致,方便模型并行处理。 | 对于变长序列尤其重要。 |
peft | Hugging Face 提供的参数高效微调 (PEFT) 库。 | 允许在只训练少量参数的情况下微调大型预训练模型,节省资源。 | |
PromptTuningConfig | 配置 Prompt Tuning (提示微调) 方法的参数。 | 定义虚拟 token 数量和初始化提示文本,通过可学习的提示向量调整模型行为。 | |
TaskType | 枚举类,用于指定 PEFT 任务类型。 | 在 PEFT 配置中指定任务为因果语言建模 (CAUSAL_LM)。 | 帮助 PEFT 库内部正确配置微调策略。 |
get_peft_model | 根据 PEFT 配置修改原始模型,使其成为 PEFT 模型。 | 将加载的预训练模型转换为只训练少量参数的 PEFT 模型实例。 | PEFT 库的核心函数。 |
PromptEncoderConfig | 配置 P-tuning 方法的参数。 | 定义虚拟 token 数量和提示编码器类型(如 LSTM)。 | P-tuning 使用编码器生成提示嵌入。 |
PromptEncoderReparameterizationType | 指定 P-tuning 中提示编码器的重新参数化类型。 | 指定编码器使用 LSTM。 | |
PrefixTuningConfig | 配置 Prefix-tuning (前缀微调) 方法的参数。 | 定义虚拟 token 数量和是否使用投影层,在 Transformer 层前添加可学习前缀。 | |
LoraConfig | 配置 LoRA (Low-Rank Adaptation) 方法的参数。 | 定义秩 r、lora_alpha 和 lora_dropout,通过低秩矩阵分解高效微调。 | 广泛应用于大型语言模型微调。 |
torch.nn | PyTorch 中用于构建神经网络的模块。 | 提供各种神经网络层、激活函数、损失函数等,此处代码中虽导入但未直接使用。 | 通常在定义自定义模型结构时用到。 |
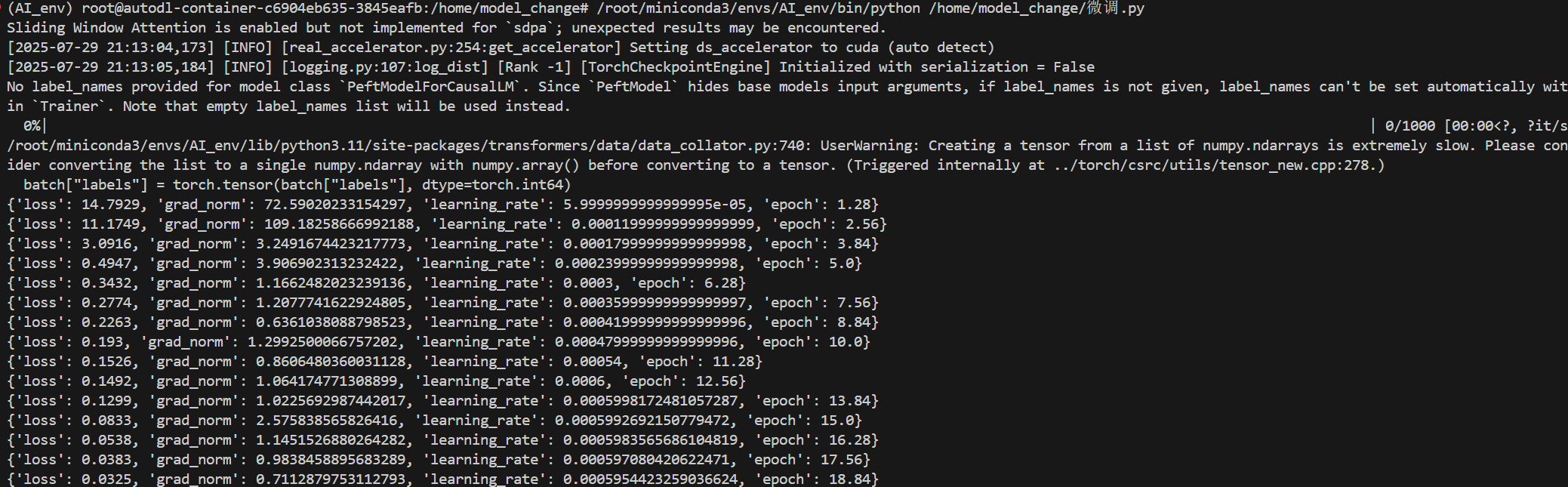
验证模型
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import AutoPeftModelForCausalLM
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name = "/home/model_change/chatbot/checkpoint-100"# Bitfit
# model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto").to(device)
# Prompt-tuning, P-tuning, Prefix-tuning, LORA
model = AutoPeftModelForCausalLM.from_pretrained(model_name).to(device)tokenizer = AutoTokenizer.from_pretrained(model_name)prompt = "你是谁"message = [{"role": "system", "content": ""},{"role": "user", "content": prompt},
]text = tokenizer.apply_chat_template(message, tokenize=False, add_generation_prompt=True)model_ids = tokenizer([text], return_tensors="pt").to(device)generated_ids = model.generate(**model_ids, max_new_tokens=512)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_ids.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)print(response)



)
)

 - 加法器)



)
传输层(上)运输层协议概述)


vllm在线启动集成openweb-ui)
)



