本地大语言模型实践:Ollama 部署与 Python 接口调用全攻略
一、引言
过去我们使用大语言模型(LLM),更多依赖于 OpenAI API、Claude API 等云端服务。它们虽然强大,但存在两大问题:
- 隐私与数据安全:敏感数据传输到云端,可能不符合公司或项目合规要求。
- 成本问题:频繁调用 API 成本高昂,尤其在企业场景。
因此,本地化部署 LLM 成为越来越多开发者的选择。本文将详细介绍 Ollama —— 一款快速部署本地 LLM 的工具,并演示如何通过 Python 接口调用模型完成推理。
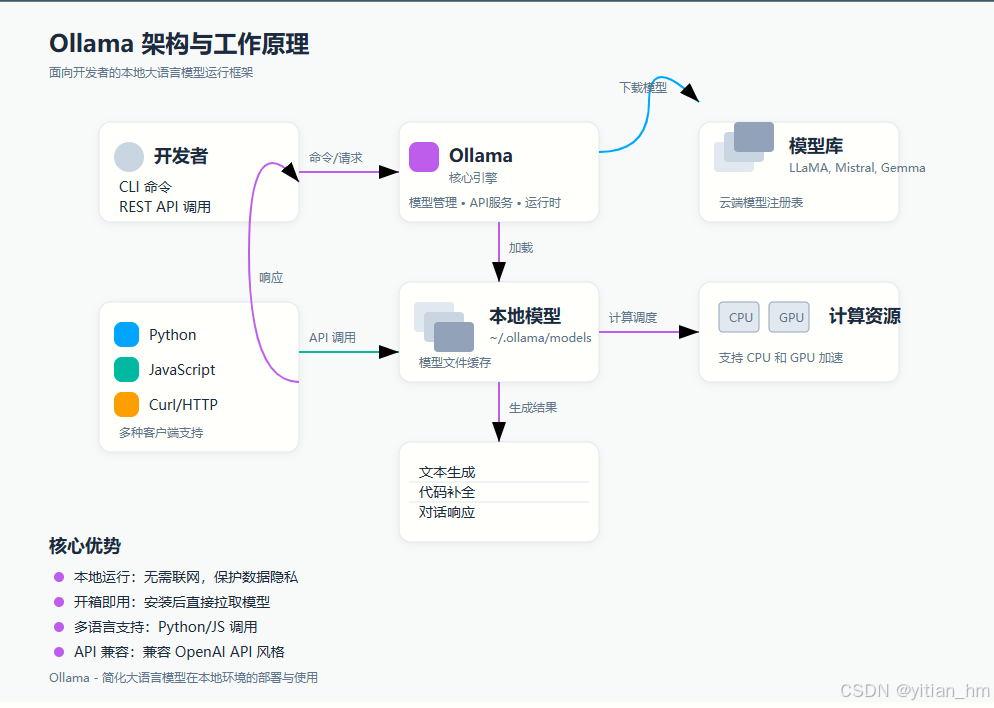
二、Ollama 是什么?
Ollama 是一个面向开发者的 本地大语言模型运行框架,支持一键运行 LLaMA、Mistral、Gemma 等开源模型。
其优势包括:
- 本地运行:无需联网,保护数据隐私。
- 开箱即用:无需复杂配置,安装后直接拉取模型。
- 支持 Python/JS 调用:便于集成到业务系统。
- 兼容 OpenAI API 风格:迁移成本低。
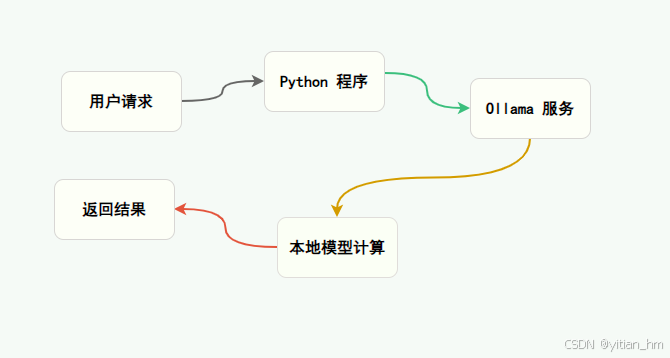
用户请求 → Python 程序 → Ollama 服务 → 本地模型计算 → 返回结果
三、Ollama 本地部署
1. 安装 Ollama
在 Linux / macOS 系统中,只需一行命令即可安装:
curl -fsSL https://ollama.com/install.sh | sh
安装完成后,运行服务:
ollama serve
2. 拉取模型
比如拉取 LLaMA-3 模型:
ollama pull llama3
此时会下载并缓存模型文件,第一次可能较慢。
3. 本地运行模型
在终端直接对话:
ollama run llama3
输出示例:
>>> Hello, what is Ollama?
Ollama is a local LLM runtime that lets you run models such as LLaMA, Mistral, and others locally on your computer...
📌 本地部署流程**
- Step1:安装 Ollama → Step2:下载模型 → Step3:本地启动 → Step4:交互推理
四、Python 接口调用 Ollama
Ollama 提供了 HTTP API,可以很容易在 Python 中调用。默认监听地址为 http://localhost:11434/api/generate。
1. 简单调用示例
import requests
import jsonurl = "http://localhost:11434/api/generate"
data = {"model": "llama3","prompt": "用简单的语言解释什么是量子计算"
}response = requests.post(url, json=data, stream=True)for line in response.iter_lines():if line:content = json.loads(line.decode("utf-8"))print(content.get("response", ""), end="", flush=True)
运行结果:
量子计算是一种利用量子力学原理进行运算的方法,它可以同时处理多个状态...
2. 类似 ChatGPT 的对话接口
如果你习惯 OpenAI 的 chat/completions API,Ollama 也支持对话模式。
import requestsurl = "http://localhost:11434/api/chat"
data = {"model": "llama3","messages": [{"role": "system", "content": "你是一个Python专家"},{"role": "user", "content": "帮我写一个快速排序的Python实现"}]
}res = requests.post(url, json=data)
print(res.json()["message"]["content"])
返回结果将是一段完整的 Python 快排代码。
📌 Python 调用流程**
用户 → Python requests → Ollama API → 本地模型 → 输出结果
五、常见使用场景
- 企业内网助手:在公司内网跑 Ollama,做一个类似 ChatGPT 的知识助手。
- 代码生成与测试:调用本地模型生成/补全代码,不依赖云端 API。
- 隐私数据问答:在本地喂入敏感文档,避免外泄。
- 边缘设备 AI 应用:在 GPU/高性能 PC 上部署,减少云端开销。
六、局限性与优化
虽然 Ollama 强大,但仍有一些局限:
- 模型大小受硬件限制:消费级电脑运行 70B 参数模型几乎不可能。
- 推理速度较慢:本地 CPU/GPU 性能有限时,响应会比云端慢。
- 缺少微调:相比企业级服务,定制化训练门槛更高。
优化方法
- 使用 量化模型(如
q4_K_M格式),内存占用大幅降低。 - 在 GPU 上运行,速度提升数倍。
- 与向量数据库(Milvus/Faiss)结合,构建本地 RAG 系统。
七、与其他大语言模型的对比
| 模型/框架 | 部署方式 | 优点 | 缺点 |
|---|---|---|---|
| OpenAI GPT-4 | 云端API | 最强大,生态完善 | 成本高,数据外泄风险 |
| Claude 3 | 云端API | 长上下文强 | 不可本地部署 |
| LLaMA / Mistral (Ollama) | 本地部署 | 数据安全,免费 | 需硬件支持 |
| ChatGLM / Qwen | 本地可部署 | 中文优化好 | 英文生态稍弱 |
📌 模型对比图**
- 云端模型(GPT/Claude):高性能,但受制于 API
- 本地模型(Ollama):灵活、安全,但依赖硬件
八、总结
ollama本地部署:
- Ollama 的基本原理与优势
- 如何本地部署并运行 LLaMA 模型
- 如何用 Python 调用 Ollama API 进行推理
- 使用场景、局限性及优化方向
- 与其他大语言模型的对比
Ollama 让本地运行大模型变得前所未有的简单,对开发者来说,它既是一个学习 LLM 的工具,也是构建企业级私有 AI 应用的重要基础。
未来,可以结合 RAG、微调 等技术,把 Ollama 打造成一个真正的 本地智能助手。


之如何在linux上正常使用R)



)




- MT7682+VLC出图)




)


