目录
- 一、概念简单回顾
- 二、Python的线程开发
- 2.1 Thread类
- 2.1.1 线程启动
- 2.1.2 线程退出
- 2.1.3 线程的传参
- 2.1.4 threading的属性和方法
- 2.1.5 Thread实例的属性和方法
- 2.1.6 start和run方法
- 2.2 多线程
- 2.3 线程安全
- 2.4 daemon线程
- 2.5 threading.local类
- 2.6 __slots__拓展
- 三、线程同步
- 3.1 Event
- 3.2 线程锁Lock
- 3.3 递归锁RLock
- 3.4 同步协作Condition
- 3.5 Queue的线程安全
在网络开发中,一台服务器在同一时间内往往需要服务成千上万个客户端,因此并发编程应运而生,并发是大数据运算和网络编程必须考虑的问题。实现并发的方式有多种,如多进程、多线程、协程等,Python 支持多进程、多线程、协程技术,能够实现在同一时间内运行多个任务。本文将介绍 Python 线程的工作机制和基本应用。
【学习重点】
- 了解什么是进程和线程
- 掌握正确创建线程的方法
- 使用线程锁
- 熟悉线程之间的通信方式
一、概念简单回顾
在 《100天精通Python——基础篇 2025 第19天:并发编程启蒙——理解CPU、线程与进程的那些事》一文中我们详细讲解了一些基础概念,包括操作系统、CPU、进程、线程等,由本文开始正式进入编程阶段,故先对其中的一些概念进行一下简单的复习。
并发和并行区别:
- 并行,Parallelism: 同时做某些事,可以互不干扰的同一个时刻做几件事
- 并发,Concurrency: 也是同时做某些事,但是强调,一个时段内有事情要处理。
- 举例: 高速公路的车道,双向4车道,所有车辆(数据)可以互不干扰的在自己的车道上奔跑(传输)。在同一个时刻,每条车道上可能同时有车辆在跑,是同时发生的概念,这是并行。在一段时间内,有这么多车要通过,这是并发。并行不过是使用水平扩展方式解决并发的一种手段而已。
进程和线程:
- 进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是操作系统进行资源分配和调度的基本单位,是操作系统结构的基础。
- 进程和程序的关系:程序是源代码编译后的文件,而这些文件存放在磁盘上。当程序被操作系统加载到内存中,就是进程,进程中存放着指令和数据(资源)。一个程序的执行实例就是一个进程。它也是线程的容器。Linux 进程有父进程、子进程,Windows 的进程是平等关系。
- 在实现了线程的操作系统中,线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。线程,有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元。一个标准的线程由线程 ID,当前指令指针(PC)、寄存器集合和堆、栈组成(前面也提到过)。在许多系统中,创建一个线程比创建一个进程快
10-100倍。 - 进程、线程的理解: 现代操作系统提出进程的概念,每一个进程都认为自己独占所有的计算机硬件资源。进程就是独立的王国,进程间不可以随便的共享数据。线程就是省份,同一个进程内的线程可以共享进程的资源,每一个线程拥有自己独立的堆栈。
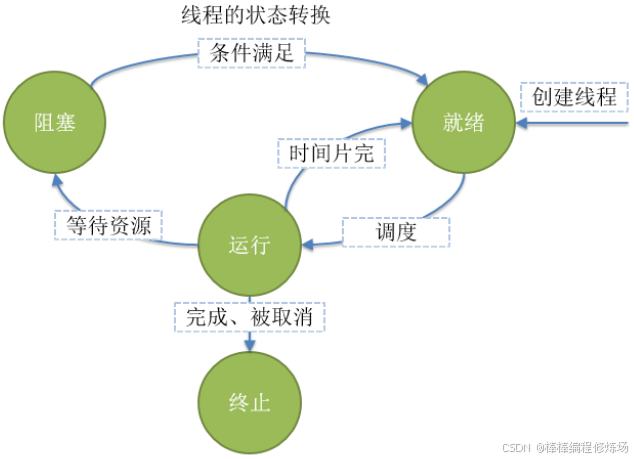
线程的状态:
-
就绪(Ready): 线程能够运行,但在等待被调度。可能线程刚刚创建启动,或刚刚从阻塞中恢复,或者被其他线程抢占
-
运行(Running): 线程正在运行
-
阻塞(Blocked): 线程等待外部事件发生而无法运行,如 I/O 操作
-
终止(Terminated): 线程完成,或退出,或被取消
Python 中的进程和线程: 运行程序会启动一个解释器进程,线程共享一个解释器进程。
二、Python的线程开发
Python 的线程开发使用标准库 threading。 进程靠线程执行代码,至少有一个主线程,其它线程是工作线程。主线程是第一个启动的线程。父线程: 如果线程A中启动了一个线程B,A就是B的父线程。子线程: B就是A的子线程。
2.1 Thread类
Python 中的线程是通过 threading 模块来实现的。其核心是 Thread 类,用于创建并管理线程。
import threading
Thread 类参数详解:
In [2]: threading.Thread?
Init signature:
threading.Thread(group=None,target=None,name=None,args=(),kwargs=None,*,daemon=None,
)
# 参数说明:
# 1.group: 保留参数,一般设置为None
# 2.target: 线程启动后要执行的任务,即函数(写函数名)
# 3.name: 线程名,后续可以使用线程对象.name属性查看
# 4.args与kwargs: 传递给函数的参数,与正常函数传参是一样的,args传给target的位置参数,kwargs传给target的关键字参数
# 5.daemon: daemon是否为daemon(守护)线程,为True: 主线程结束时,子线程也会自动退出(daemon线程--守护线程),
# False: 主线程会等待子线程执行完毕,与缺省参数None效果是一样的,后续会专门有一小节详细讲解daemon线程与non-daemon线程Docstring:
A class that represents a thread of control.This class can be safely subclassed in a limited fashion. There are two ways
to specify the activity: by passing a callable object to the constructor, or
by overriding the run() method in a subclass.
Init docstring:
This constructor should always be called with keyword arguments. Arguments are:*group* should be None; reserved for future extension when a ThreadGroup
class is implemented.*target* is the callable object to be invoked by the run()
method. Defaults to None, meaning nothing is called.*name* is the thread name. By default, a unique name is constructed of
the form "Thread-N" where N is a small decimal number.*args* is a list or tuple of arguments for the target invocation. Defaults to ().
2.1.1 线程启动
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 10:54
# @Author : AmoXiang
# @File : 1.线程的启动.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading# 最简单的线程程序
def worker():print('I"m working')print('Finished')t = threading.Thread(target=worker, name='worker') # 线程对象
t.start() # 启动
通过 threading.Thread 创建一个线程对象,target 是目标函数,可以使用 name 为线程指定名称。但是线程没有启动,需要调用 start 方法。线程之所以执行函数,是因为线程中就是要执行代码的,而最简单的代码封装就是函数,所以还是函数调用。函数执行完,线程也就退出了。那么,如果不让线程退出,或者让线程一直工作怎么办呢?
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 10:54
# @Author : AmoXiang
# @File : 1.线程的启动.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
import time# 最简单的线程程序
def worker():# 使用while True 可以让线程一直工作下去while True: # for i in range(10):time.sleep(0.5)print('I"m working')print('Finished')t = threading.Thread(target=worker, name='worker') # 线程对象
t.start() # 启动
print('~' * 30) # 注意观察这行~是什么时候打印的?
控制台会先打印 '~',你可以这样理解,线程启动的一瞬间,我通知你了,你要去干 worker 的活,那通知到位之后,你怎么去处理我是不管的,我继续执行我后续的任务,所以在这里你可能会先看到 '~',当然,如果在 worker 函数中,while True 下我们如果没有设置延时操作,即 time.sleep(0.5),那么该函数中的 print('I"m working') 可能会与 print('~' * 30) 争抢控制台,所以你能先看到 I"m working 的结果也不一定。
2.1.2 线程退出
Python 没有提供线程退出的方法,线程一般在下面情况时退出:
- 线程函数内语句执行完毕
- 线程函数中抛出未处理的异常
示例代码:
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 11:09
# @Author : AmoXiang
# @File : 2.线程的退出.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
import timedef worker():for i in range(10):time.sleep(0.5)if i > 5:# break # 终止循环# return # 函数返回 finished 这个在打印的时候就看不到了# raise 1 / 0 # 抛异常raise RuntimeError # 抛异常print('I am working')print('finished')t = threading.Thread(target=worker, name='worker')
t.start()
print('~' * 30)
Python 的线程没有优先级、没有线程组的概念,也不能被销毁、停止、挂起,那也就没有恢复、中断了。
2.1.3 线程的传参
线程传参和函数传参没什么区别,本质上就是函数传参。示例:
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 11:14
# @Author : AmoXiang
# @File : 3.线程的传参.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading, timedef add(x, y):print(f'{x} + {y} = {x + y}')t1 = threading.Thread(target=add, args=(1, 2))
t1.start()
time.sleep(0.5)t2 = threading.Thread(target=add, kwargs={'x': 3, 'y': 4})
t2.start()
time.sleep(0.5)# 传参会报错哦: TypeError: add() got multiple values for argument 'x'
# 前面的知识点,这里不再赘述
# t3 = threading.Thread(target=add, args=(6,), kwargs={'x': 5})
# t3 = threading.Thread(target=add, kwargs={'x': 5}, args=(6,))
# 正确写法
t3 = threading.Thread(target=add, args=(6,), kwargs={'y': 5})
t3.start()
time.sleep(0.5)
2.1.4 threading的属性和方法
下面是 Python threading 模块中常用的一些 函数 的详细说明:
| 函数名 | 说明 |
|---|---|
threading.active_count() | 返回当前活动线程的数量(包括主线程) |
threading.current_thread() | 返回当前调用者的控制线程的 Thread 对象 |
threading.enumerate() | 以列表形式返回当前所有存活的 Thread 对象 |
threading.get_ident() | 返回当前线程的 "线程标识符"(为一个非0整数,唯一) |
threading.get_native_id() | 返回操作系统分配的原生线程 ID(Python 3.8+) |
threading.main_thread() | 返回主 Thread 对象。一般情况下,主线程是 Python 解释器开始时创建的线程。 |
threading.settrace(func) | 为所有 threading 模块开始的线程设置追踪函数。在每个线程的 run() 方法被调用前,func 会被传递给 sys.settrace()。-----用的较少 |
threading.setprofile(func) | 为所有 threading 模块开始的线程设置性能测试函数。在每个线程的 run() 方法被调用前,func 会被传递给 sys.setprofile()。-----用的较少 |
threading.stack_size([size]) | 返回创建线程时用的堆栈大小。 |
示例1:
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 11:43
# @Author : AmoXiang
# @File : 4.threading的属性和方法.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
import timedef show_thread_info():print('current thread = {}\nmain thread = {}\nactive count = {}'.format(threading.current_thread(),threading.main_thread(),threading.active_count()))def worker():show_thread_info()for i in range(5):time.sleep(1)print('i am working')print('finished')t = threading.Thread(target=worker, name='worker') # 线程对象
show_thread_info()
time.sleep(1)
t.start() # 启动
print('===end===')
示例2:
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 11:49
# @Author : AmoXiang
# @File : 4.threading的属性和方法2.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threadingdef main():print(threading.active_count()) # 活动线程数print(threading.enumerate()) # 存活的线程对象列表print(threading.get_ident()) # 返回当前线程的"线程标识符"print(threading.get_native_id())print(threading.current_thread()) # 返回当前调用的线程对象print(threading.main_thread()) # 主线程print(threading.stack_size()) # 线程的堆栈大小"""1[<_MainThread(MainThread, started 19868)>]1986819868<_MainThread(MainThread, started 19868)><_MainThread(MainThread, started 19868)>0"""if __name__ == "__main__":main()
2.1.5 Thread实例的属性和方法
Thread 对象也包含多个实例方法,简单说明如下:
| 属性/方法 | 类型 | 说明 |
|---|---|---|
start() | 方法 | 启动线程,调用后线程开始执行 |
run() | 方法 | 线程执行的具体逻辑(通常不手动调用) |
join([timeout]) | 方法 | 等待至线程中止或者指定的时间,时间由参数指定,单位为秒 |
is_alive() | 方法 | 返回线程是否处于活动的状态 |
name | 属性 | 线程名称,可读写 |
ident | 属性 | Python 层的线程 ID,创建后才有 |
native_id | 属性 | 操作系统线程 ID(Python 3.8+) |
daemon | 属性 | 是否为守护线程,必须在 start() 前设置 |
isDaemon() / setDaemon() | 方法 | 获取/设置守护线程(已被 daemon 属性取代) |
示例:
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 11:56
# @Author : AmoXiang
# @File : 5.Thread实例的属性和方法.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
import timedef worker():for i in range(5):time.sleep(1)print('i am working')print('finished')t = threading.Thread(target=worker, name='worker') # 线程对象
# 返回结果: # worker None None 说明此刻线程还未真正的被创建
print(t.name, t.ident, t.native_id)
time.sleep(1)
t.start()
print('=====end=====')
while True:time.sleep(1)# 控制台输出会争抢 你会看到错乱显示,这里可以使用logging模块替代print()函数print('{} {} {}'.format(t.name, t.ident, 'alive' if t.is_alive() else 'dead'))if not t.is_alive():print('{} restart'.format(t.name))# RuntimeError: threads can only be started oncet.start() # 线程重启??此处会报错,后续会详细讲解Thread实例的start()方法与run()方法
2.1.6 start和run方法
threading.Thread 类,Thread 是 Python 提供的线程封装类。可以通过创建 Thread 对象并传入 target=函数 启动线程;也可以通过继承 Thread 并重写 run() 方法 来定义线程行为。
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 14:28
# @Author : AmoXiang
# @File : 6.自定义线程类写法.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
import timeclass SubThread(threading.Thread):def run(self):for i in range(3):time.sleep(1)msg = "子线程" + self.name + '执行,i=' + str(i) # name属性中保存的是当前线程的名字print(msg)if __name__ == '__main__':print('-----主线程开始-----')t1 = SubThread() # 创建子线程t1t2 = SubThread() # 创建子线程t2t1.start() # 启动子线程t1t2.start() # 启动子线程t2'''-----主线程开始----------主线程结束-----子线程Thread-1执行,i=0子线程Thread-2执行,i=0子线程Thread-2执行,i=1子线程Thread-1执行,i=1子线程Thread-1执行,i=2子线程Thread-2执行,i=2'''print('-----主线程结束-----')
start()方法 与 run() 方法的本质区别:
| 方法 | 作用 | 调用方式 | 是否创建新线程 |
|---|---|---|---|
start() | 真正启动线程 | 系统自动调用 run() | ✅ 是(创建新线程) |
run() | 定义线程任务逻辑 | 手动调用不会新建线程 | ❌ 否(在主线程中运行) |
示例代码:
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 13:28
# @Author : AmoXiang
# @File : 6.start和run方法.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
import timedef worker():for i in range(5):time.sleep(1)print('i am working')print('finished')class SubThread(threading.Thread):def start(self):# 线程对象调用start()方法,会走这里逻辑,我们不知道怎么去系统调用创建一个真正的线程# 所以如果什么都不做的话,那么真正的线程不会被创建,你可以自己进行测试# 想要创建真正的线程,我们就去调用父类的start()方法,让它去系统调用创建真正的线程print('start ~~~')super(SubThread, self).start()def run(self):# run() 方法是线程真正要做的任务逻辑,可以通过传函数(target)或者继承重写# 同理,如果你光打印,什么都不做,最后虽然你能看到多个线程,可是你看不到该线程干的啥活# 最简单的方式直接调用父类的run()方法,让它处理print('run ~~~')super().run()def main():# 测试print('-----主线程开始-----')t = SubThread(target=worker, name='worker') # 线程对象print('before t.start,active_count==> {}'.format(threading.active_count()))# TODO 测试1.正确方式: 启动线程,会自动在新线程中调用 run()# t.start() # 启动# TODO 测试2.错误/不推荐: 手动调用 run()t.run() # 这不会开启新线程,而是当前线程同步执行# TODO 测试3.第2次启动线程# t.start() # RuntimeError: threads can only be started once# TODO 测试4.两次手动调用run()方法或者先启动线程,即调用start()方法后再次调用run,也会报错t.run() # AttributeError: 'SubThread' object has no attribute '_target'print('after t.start,active_count==> {}'.format(threading.active_count()))print('-----主线程结束-----')if __name__ == '__main__':main()
去源码中看看 t.start() 只能调用一次的原因,跟进到父类的 start() 方法,如下:
def start(self):"""Start the thread's activity.It must be called at most once per thread object. It arranges for theobject's run() method to be invoked in a separate thread of control.This method will raise a RuntimeError if called more than once on thesame thread object."""if not self._initialized:raise RuntimeError("thread.__init__() not called")# 根据 RuntimeError: threads can only be started once 错误提示,我们可以推断到此处# 如果self._started.is_set()为False,正常执行,self._started.is_set()返回True,则抛出异常。if self._started.is_set():raise RuntimeError("threads can only be started once")with _active_limbo_lock:_limbo[self] = selftry:_start_new_thread(self._bootstrap, ())except Exception:with _active_limbo_lock:del _limbo[self]raiseself._started.wait()
我们来看看 self._started.is_set() 这玩意是啥:
# 在 Thread 类 __init__ 初始化方法中有这样的定义
self._started = Event()
# 定位 Event,发现是一个类,类初始化方法中有下面这样的定义
self._flag = False# 并且发现 is_set 是 Event 类中的一个方法
def is_set(self):"""Return true if and only if the internal flag is true."""return self._flag
走到这里我们可以得出,第一次进入到 start() 方法中的时候,self._started.is_set() 调用返回的是 Event 类初始化时候的值,即 False,所以不会进入到 if 语句中,就不会抛出异常,那这里我们就可以猜想,在后续的操作中,是不是有哪个地方更改了这个 _flag 值,对 self._started 要留点心思,我们接着往 start() 方法下面的逻辑往后看:
# 这个函数看名字太明显了 开启一个新的线程
_start_new_thread(self._bootstrap, ())# _bootstrap是一个函数,里面实际又调用的是 _bootstrap_inner
def _bootstrap(self):try:self._bootstrap_inner()except:if self._daemonic and _sys is None:returnraise# 看看: _bootstrap_inner
def _bootstrap_inner(self):try:self._set_ident()self._set_tstate_lock()if _HAVE_THREAD_NATIVE_ID:self._set_native_id()# 这里我们看到再次使用了 self._started 这个 Event 实例对象# 调用了它的set()方法,我们定位到set()方法,看它里面做了些啥self._started.set()with _active_limbo_lock:_active[self._ident] = selfdel _limbo[self]if _trace_hook:_sys.settrace(_trace_hook)if _profile_hook:_sys.setprofile(_profile_hook)try:self.run()except:self._invoke_excepthook(self)finally:self._delete()def set(self):with self._cond:# 破案了,太明显了,这个操作,也就是说我们调用了一次start方法之后,Thread对象的属性_started 指向的Event实例对象,# 会将其属性_flag 置为True,再次调用start方法时,又根据这个值判断,是否抛出异常# 那么前面我们已经讲解到,为True时,抛出异常,故多次调用start()方法会抛异常就是这么来的self._flag = Trueself._cond.notify_all()
多次调用 start() 方法报错,我们分析完毕了,接下来我们去看看多次调用 run() 方法为何报错?这个相对来说就比较简单了:
# 在函数_bootstrap_inner中,我们可以看到run()方法被调用
try:self.run()
except:self._invoke_excepthook(self)# run()方法定义
def run(self):try:# 实例化Thread对象时,传入的target参数,即函数名称# self._target ⇒ self._target = targetif self._target is not None:self._target(*self._args, **self._kwargs)finally:del self._target, self._args, self._kwargs
run() 方法的逻辑很明显,使用 try...finally 结构,finally 块中的代码是一定会执行的,其逻辑是使用 del 关键字删除对象身上的 _target 属性,即我们第一次调用 run() 方法时,对象身上的 _target 属性被删除,当再次调用 run() 方法时,对象身上已经没有了 _target 属性,而在 if 判断语句中去取对象的 _target 属性,故会报 AttributeError 属性错误。
2.2 多线程
顾名思义,多个线程,一个进程中如果有多个线程运行,就是多线程,实现一种并发。其实在之前我们的演练过程中,就已经出现多线程,一个主线程与其他工作的线程,示例代码:
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 15:11
# @Author : AmoXiang
# @File : 7.多线程.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
import time
import sysdef worker(f=sys.stdout):t = threading.current_thread()for i in range(5):time.sleep(1)print('i am working', t.name, t.ident, file=f)print('finished', file=f)t1 = threading.Thread(target=worker, name='worker1')
t2 = threading.Thread(target=worker, name='worker2', args=(sys.stderr,))
t1.start()
t2.start()
可以看到 worker1 和 worker2 交替执行。当使用 start 方法启动线程后,进程内有多个活动的线程并行的工作,就是多线程。一个进程中至少有一个线程,并作为程序的入口,这个线程就是主线程。一个进程至少有一个主线程,其他线程称为工作线程。
2.3 线程安全
多线程执行一段代码,不会产生不确定的结果,那这段代码就是线程安全的。多线程在运行过程中,由于共享同一进程中的数据,多线程并发使用同一个数据,那么数据就有可能被相互修改,从而导致某些时刻无法确定这个数据的值,最终随着多线程运行,运行结果不可预期,这就是线程不安全。------在文章后面部分会进行详细地讲解
2.4 daemon线程
daemon 线程,有人翻译成后台线程,也有人翻译成守护线程。Python 中,构造线程的时候,可以设置 daemon 属性,这个属性必须在 start() 方法前设置好。源码 Thread 类的 __init__() 方法中:
if daemon is not None:if daemon and not _daemon_threads_allowed():raise RuntimeError('daemon threads are disabled in this (sub)interpreter')self._daemonic = daemon
else:self._daemonic = current_thread().daemon
线程 daemon 属性,如果设定就是用户的设置,否则就取当前线程的 daemon 值。主线程是 non-daemon 线程,即 daemon = False。
class _MainThread(Thread):def __init__(self):Thread.__init__(self, name="MainThread", daemon=False)self._set_tstate_lock()self._started.set()self._set_ident()if _HAVE_THREAD_NATIVE_ID:self._set_native_id()with _active_limbo_lock:_active[self._ident] = self
示例代码:
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 16:47
# @Author : AmoXiang
# @File : 7.daemon线程.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import time
import threadingdef foo():time.sleep(5)for i in range(5):print(i)# 主线程是non-daemon线程
t1 = threading.Thread(target=foo, daemon=False)
t1.start()
'''
RuntimeError: cannot set daemon status of active thread
daemon属性: 表示线程是否是daemon线程,这个值必须在start()之前设置,否则引发RuntimeError异常==> t1.daemon = True
isDaemon(): 是否是daemon线程
setDaemon(): 设置为daemon线程,必须在start方法之前设置 已经被daemon属性替代了
'''
print('Main Thread Exits')
发现线程 t1 依然执行,主线程已经执行完,但是一直等着线程 t1。修改为 t1 = threading.Thread(target=foo, daemon=True) 试一试,结果程序立即结束了,进程根本没有等 daemon 线程 t1。看一个例子,看看主线程何时结束 daemon 线程:
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 16:58
# @Author : AmoXiang
# @File : 7.daemon线程2.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import time
import threadingdef worker(name, timeout):time.sleep(timeout)print('{} working'.format(name))# 主线程 是non-daemon线程
'''
Main Thread Exits
t1 working
t2 working
'''
t1 = threading.Thread(target=worker, args=('t1', 2), daemon=True)
t1.start()
t2 = threading.Thread(target=worker, args=('t2', 3), daemon=False)
t2.start()
print('Main Thread Exits')
print('~' * 30)
# 调换2和3看看效果
'''
运行下面代码的时候记得将上面的给注释掉,调换2和3后,程序执行结果如下:
Main Thread Exits
t2 working
'''
t1 = threading.Thread(target=worker, args=('t1', 3), daemon=True)
t1.start()
t2 = threading.Thread(target=worker, args=('t2', 2), daemon=False)
t2.start()
print('Main Thread Exits')
上例说明,如果还有 non-daemon 线程在运行,进程不结束,进程也不会杀掉其它所有 daemon 线程。直到所有 non-daemon 线程全部运行结束(包括主线程),不管有没有 daemon 线程,程序退出。总结:
- 线程具有一个 daemon 属性,可以手动设置为 True 或 False,也可以不设置,则取默认值 None,如果不设置 daemon,就取当前线程的 daemon 来设置它
- 主线程是 non-daemon 线程,即 daemon = False
- 从主线程创建的所有线程的不设置 daemon 属性,则默认都是 daemon = False,也就是 non-daemon 线程
- Python 程序在没有活着的 non-daemon 线程运行时,程序退出,也就是除主线程之外剩下的只能都是 daemon 线程,主线程才能退出,否则主线程就只能等待
join() 方法,先看一个简单的例子,看看效果:
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 17:08
# @Author : AmoXiang
# @File : 8.join()方法.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import time
import threadingdef worker(name, timeout):time.sleep(timeout)print('{} working'.format(name))t1 = threading.Thread(target=worker, args=('t1', 3), daemon=True)
t1.start()
'''
t1 working
Main Thread Exits
'''
t1.join() # 设置join,取消join对比一下
# 取消join() ==> Main Thread Exits
print('Main Thread Exits')
使用了 join() 方法后,当前线程阻塞了,daemon 线程执行完了,主线程才退出了。
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 17:08
# @Author : AmoXiang
# @File : 8.join()方法.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import time
import threadingdef worker(name, timeout):time.sleep(timeout)print('{} working'.format(name))t1 = threading.Thread(target=worker, args=('t1', 10), daemon=True)
t1.start()
t1.join(2)
print('~~~~~~~~~~~')
t1.join(2)
print('~~~~~~~~~~~')
print('Main Thread Exits')
def join(self, timeout=None):
- join() 方法是线程的标准方法之一
- 一个线程中调用另一个线程的 join() 方法,调用者将被阻塞,直到被调用线程终止,或阻塞超时一个线程可以被 join 多次
- timeout 参数指定调用者等待多久,没有设置超时,就一直等到被调用线程结束
- 调用谁的 join() 方法,就是 join() 谁,就要等谁
daemon 线程应用场景,主要应用场景有:
- 后台任务。如发送心跳包、监控,这种场景最多
- 主线程工作才有用的线程。如主线程中维护这公共的资源,主线程已经清理了,准备退出,而工作线程使用这些资源工作也没有意义了,一起退出最合适
- 随时可以被终止的线程
如果主线程退出,想所有其它工作线程一起退出,就使用 daemon=True 来创建工作线程。比如,开启一个线程定时判断 WEB 服务是否正常工作,主线程退出,工作线程也没有必须存在了,应该随着主线程退出一起退出。这种 daemon 线程一旦创建,就可以忘记它了,只用关心主线程什么时候退出就行了。daemon 线程,简化了程序员手动关闭线程的工作。
2.5 threading.local类
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 18:19
# @Author : AmoXiang
# @File : 9.threading.local类.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
import time
import loggingFORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)def worker():x = 0for i in range(5):time.sleep(0.2)x += 1logging.info(x)def main():for i in range(10):threading.Thread(target=worker, name='t-{}'.format(i)).start()if __name__ == '__main__':main()
上例使用多线程,每个线程完成不同的计算任务。x 是局部变量,可以看出每一个线程的 x 是独立的,互不干扰的,为什么?因为 x 是定义在 worker() 函数内部的变量,是一个局部变量(local variable):
def worker():x = 0 # 局部变量,每个线程各有一个副本
线程启动后,每个线程都会单独执行一次 worker() 函数,每个线程都有自己独立的栈空间(stack),函数内部的变量就存在于线程的私有栈中,互不干扰。能否改造成使用全局变量完成?
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 19:20
# @Author : AmoXiang
# @File : 9.threading.local类2.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
import time
import loggingFORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)class A:def __init__(self):self.x = 0# 全局对象
global_data = A()def worker():global_data.x = 0for i in range(10):time.sleep(0.0001)global_data.x += 1logging.info(global_data.x)def main():for i in range(10):threading.Thread(target=worker, name='t-{}'.format(i)).start()if __name__ == '__main__':main()
上例虽然使用了全局对象,但是线程之间互相干扰,导致了不期望的结果,即线程不安全。能不能既使用全局对象,还能保持每个线程使用不同的数据呢?python 提供 threading.local 类,将这个类实例化得到一个全局对象,但是不同的线程使用这个对象存储的数据其他线程看不见。
# 将上面示例23行代码改为下列代码
global_data = threading.local()
执行程序,结果显示和使用局部变量的效果一样。再看 threading.local 的例子:
# -*- coding: utf-8 -*-
# @Time : 2025-05-20 19:28
# @Author : AmoXiang
# @File : 9.threading.local类3.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
import time
import loggingFORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)# 全局对象
X = 'abc'
global_data = threading.local()
global_data.x = 100
print(global_data, global_data.x)
print('~' * 30)
time.sleep(2)def worker():logging.info(X)logging.info(global_data)logging.info(global_data.x)worker() # 普通函数调用
print('=' * 30)
time.sleep(2)
threading.Thread(target=worker, name='worker').start() # 启动一个线程
从运行结果来看,另起一个线程打印 global_data.x 出错了,如下图所示:
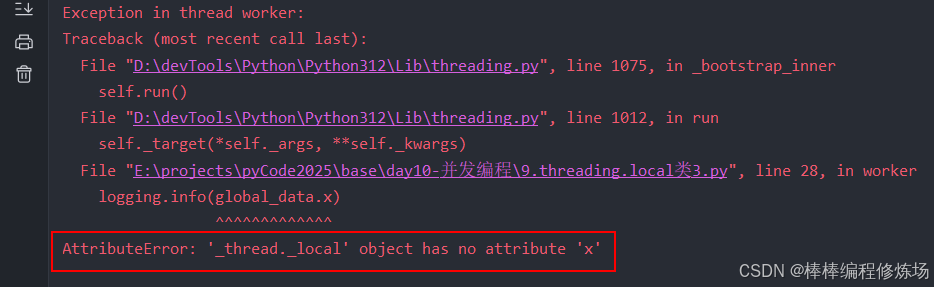
AttributeError: '_thread._local' object has no attribute 'x',但是,global_data 打印没有出错,说明看到 global_data,但是 global_data 中的 x 看不到,这个 x 不能跨线程。要想知道其中是怎么实现的,只能去看源码,那我们就去看看。整个 local 类的代码并不多,如下:
class local:# __slots__参考《2.6 __slots__拓展》小节的讲解__slots__ = '_local__impl', '__dict__'def __new__(cls, /, *args, **kw):if (args or kw) and (cls.__init__ is object.__init__):raise TypeError("Initialization arguments are not supported")self = object.__new__(cls)impl = _localimpl()impl.localargs = (args, kw)impl.locallock = RLock()object.__setattr__(self, '_local__impl', impl)# We need to create the thread dict in anticipation of# __init__ being called, to make sure we don't call it# again ourselves.impl.create_dict()return selfdef __getattribute__(self, name):with _patch(self):return object.__getattribute__(self, name)def __setattr__(self, name, value):if name == '__dict__':raise AttributeError("%r object attribute '__dict__' is read-only"% self.__class__.__name__)with _patch(self):return object.__setattr__(self, name, value)def __delattr__(self, name):if name == '__dict__':raise AttributeError("%r object attribute '__dict__' is read-only"% self.__class__.__name__)with _patch(self):return object.__delattr__(self, name)
这几个魔术方法在 《100天精通Python——基础篇 2025 第14天:深入掌握魔术方法与元类,玩转高级OOP技巧》我们就已经详细学习过,我这里简单提一下,如果有不懂的自己回去看看。在我们使用 threading.local() 时,首先会走 __new__() 方法中的逻辑,如下:
def __new__(cls, /, *args, **kw):# 判断是否传入参数,如果有且没有重写__init__()方法,就会抛出异常,因为: 默认的 object.__init__() 是不接受任何参数的if (args or kw) and (cls.__init__ is object.__init__):raise TypeError("Initialization arguments are not supported")# 调用父类的__new__()方法创建对象self = object.__new__(cls)# 跟进_localimpl,发现它是一个类,那这里相当于就是在实例化,大概扫一眼它的属性和方法impl = _localimpl()impl.localargs = (args, kw) # 给localargs属性赋值impl.locallock = RLock() # 给locallock属性赋值, RLock我后面会讲# 注意: 8-10行都是在操作impl实例# 调用object基类的__setattr__方法为local实例添加属性,添加_local__impl属性,对应值为impl,# 即上面_localimpl类实例化的实例object.__setattr__(self, '_local__impl', impl)# We need to create the thread dict in anticipation of# __init__ being called, to make sure we don't call it# again ourselves.# 调用impl实例的create_dict()方法,接下来就把实例self返回了,所以我们要重点看create_dict()方法中的逻辑impl.create_dict()return selfclass _localimpl:"""A class managing thread-local dicts"""__slots__ = 'key', 'dicts', 'localargs', 'locallock', '__weakref__'def __init__(self):# The key used in the Thread objects' attribute dicts.# We keep it a string for speed but make it unlikely to clash with# a "real" attribute.self.key = '_threading_local._localimpl.' + str(id(self))# { id(Thread) -> (ref(Thread), thread-local dict) }self.dicts = {}def get_dict(self):"""Return the dict for the current thread. Raises KeyError if nonedefined."""thread = current_thread()return self.dicts[id(thread)][1]def create_dict(self):"""Create a new dict for the current thread, and return it."""localdict = {}key = self.keythread = current_thread()idt = id(thread)def local_deleted(_, key=key):# When the localimpl is deleted, remove the thread attribute.thread = wrthread()if thread is not None:del thread.__dict__[key]def thread_deleted(_, idt=idt):# When the thread is deleted, remove the local dict.# Note that this is suboptimal if the thread object gets# caught in a reference loop. We would like to be called# as soon as the OS-level thread ends instead.local = wrlocal()if local is not None:dct = local.dicts.pop(idt)wrlocal = ref(self, local_deleted)wrthread = ref(thread, thread_deleted)thread.__dict__[key] = wrlocalself.dicts[idt] = wrthread, localdictreturn localdict
跟进 impl.create_dict(),如下:
def create_dict(self):"""Create a new dict for the current thread, and return it."""# 定义一个变量localdict,为字典类型localdict = {}# self.key = '_threading_local._localimpl.' + str(id(self))# _threading_local._localimpl.拼接上_localimpl实例的地址key = self.keythread = current_thread() # 当前线程idt = id(thread) # 当前线程地址值# 函数定义跳过def local_deleted(_, key=key):# When the localimpl is deleted, remove the thread attribute.thread = wrthread()if thread is not None:del thread.__dict__[key]# 函数定义跳过def thread_deleted(_, idt=idt):# When the thread is deleted, remove the local dict.# Note that this is suboptimal if the thread object gets# caught in a reference loop. We would like to be called# as soon as the OS-level thread ends instead.local = wrlocal()if local is not None:dct = local.dicts.pop(idt)# ref弱引用wrlocal = ref(self, local_deleted)wrthread = ref(thread, thread_deleted)# 给当前线程实例对象__dict__设置key,valuethread.__dict__[key] = wrlocal# dicts是_localimpl类初始化时所定义的一个属性# 即impl实例属性dicts中多了一对数据,以当前线程id为key,值为 wrthread, localdict# self.dicts = {'id(thread)': wrthread, localdict}self.dicts[idt] = wrthread, localdictreturn localdict # 返回了一个空字典
至此 impl.create_dict() 整个逻辑执行完毕,回到 __new__() 方法中,返回了当前 local 类的实例。知道大致逻辑之后,我们来分析一下这个报错 AttributeError: '_thread._local' object has no attribute 'x'
def worker():logging.info(X)logging.info(global_data)logging.info(global_data.x)threading.Thread(target=worker, name='worker').start()
# 启动线程,执行 worker 中的逻辑
# global_data.x 调用会走 ⇒ __getattribute__()方法逻辑
# 即 local 类的:
def __getattribute__(self, name):with _patch(self):return object.__getattribute__(self, name)# 上下文,跟进
@contextmanager
def _patch(self):# yield 后面没有东西 说明是在之前做增强# 调用local类实例的_local__impl属性,即global_data的_local__impl属性# 在之前我们的源码分析中_local__impl属性为impl,即_localimpl的实例# 前面已经说过,impl dicts属性中挂着数据对:{'id(thread)': wrthread, localdict}impl = object.__getattribute__(self, '_local__impl')try:# get_dict()方法就是: self.dicts[id(thread)][1]# 即取到localdict ==> {} 大的空字典dct = impl.get_dict()except KeyError:dct = impl.create_dict()args, kw = impl.localargsself.__init__(*args, **kw)# 锁不用管with impl.locallock:# 可以看到逻辑是调用object __setattr__()方法# self传入的是local实例,即此处给local实例的 __dict__ 设置了一个空字典object.__setattr__(self, '__dict__', dct)yielddef get_dict(self):"""Return the dict for the current thread. Raises KeyError if nonedefined."""thread = current_thread()return self.dicts[id(thread)][1]# 上下文完成之后,回到__getattribute__,执行:
return object.__getattribute__(self, name)
# local类实例 __dict__ 为 {},那么使用基类的
# object.__getattribute__怎么能取到 x 属性呢,这就是报错的原因
小结: threading.local 类通过属性 _local__impl 属性对应的值,即 _localimpl 类的实例构建了一个大字典,存放所有线程相关的字典,即:{ id(Thread) ⇒ (ref(Thread), thread-local dict) },每一线程实例的 id 为 key,元组为 value。value 中2部分别为线程对象引用,每个线程自己的字典。运行时,threading.local 实例处在不同的线程中,就从大字典中找到当前线程相关键值对中的字典,覆盖 threading.local 实例的 __dict__,这样就可以在不同的线程中,安全地使用线程独有的数据,做到了线程间数据隔离,如同本地变量一样安全。
2.6 __slots__拓展
Python 中的 __slots__ 是一个性能优化工具,常用于减少内存占用和限制类的属性动态创建。在一些对性能敏感或者需要大量创建实例的场景中,使用 __slots__ 可以带来明显好处。
什么是 __slots__?默认情况下,Python 的类实例是通过一个叫做 __dict__ 的字典来存储属性的:
class Person:def __init__(self, name):self.name = namep = Person('棒棒编程修炼场')
print(p.__dict__) # {'name': '棒棒编程修炼场'}
这样虽然灵活,但会多占用内存。__slots__ 的作用是:告诉 Python 不使用 __dict__,而是使用更紧凑的内部结构来固定属性,从而节省内存。为什么使用 __slots__?
- 节省内存:没有
__dict__,每个实例占用的内存更少。 - 防止添加不存在的属性:限制只能使用定义好的属性,提升代码健壮性。
- 访问属性更快(略微):属性访问通过更底层的数据结构,访问速度稍有提升。
典型使用场景:
- 大量创建实例(如爬虫、数据处理、图节点对象)
- 属性固定的轻量对象(如数据库模型、配置项等)
- 嵌入式或低内存环境(如微型服务器、树莓派)
- 对性能要求极高的系统
示例1:基本使用
# -*- coding: utf-8 -*-
# @Time : 2025-05-24 4:57
# @Author : bb_bcxlc
# @File : __slots__例子1.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680class Person:__slots__ = ('name', 'age') # 只允许这两个属性def __init__(self, name, age):self.name = nameself.age = agep = Person("棒棒编程修炼场", 18)
print(p.name)# 下面代码执行会报错: AttributeError: 'Person' object has no attribute 'gender'
p.gender = 'female'
__dict__ 声明后,Python 不会为每个实例分配 __dict__,实例只能拥有指定的属性(更节省内存)。
# AttributeError: 'Person' object has no attribute '__dict__'. Did you mean: '__dir__'?
print(p.__dict__)
示例2:内存占用对比
# -*- coding: utf-8 -*-
# @Time : 2025-05-24 5:01
# @Author : bb_bcxlc
# @File : __slots__例子2.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680class Normal:def __init__(self, x, y):self.x = xself.y = yclass Slotted:__slots__ = ('x', 'y')def __init__(self, x, y):self.x = xself.y = yfrom pympler import asizeof# 使用 pympler 包来真实统计内存占用
# 需要使用pip命令进行安装: pip install pympler
many_a = [Normal(1, 2) for _ in range(100000)]
many_b = [Slotted(1, 2) for _ in range(100000)]print("NoSlots total size:", asizeof.asizeof(many_a))
print("WithSlots total size:", asizeof.asizeof(many_b))
示例3:继承限制
class A:__slots__ = ('x',)class B(A):passb = B()
b.y = 10 # 正常,子类没有 __slots__,就会自动启用 __dict__
要想子类也限制属性,需要子类也声明 __slots__:
class B(A):__slots__ = ('y',)b = B()
b.x = 10
print(b.x) # 继承的属性是有的,动态添加属性不行
# b.z = 10 # AttributeError: 'B' object has no attribute 'z'
可以显式允许使用 __dict__(脱裤子放屁,多此一举):
class Person:__slots__ = ('name', '__dict__') # 允许动态添加属性p = Person()
p.name = '棒棒编程修炼场'
p.age = 25 # 现在可以添加
# 棒棒编程修炼场 {'age': 25} __slots__限定的属性不会出现在__dict__中
# 转而使用一个更轻量的、固定的结构来保存属性。这正是它节省内存的关键(猜想)
# 棒棒编程修炼场 {'age': 25}
print(p.name, p.__dict__)
如果你要创建大量结构固定的对象(如数据结构、节点对象),建议使用。如果你在做性能优化、节省内存,使用 __slots__ 是非常值得考虑的。
三、线程同步
概念: 线程同步是指通过某种机制,使多个线程在访问共享数据时能够有序进行,确保同一时刻只有一个线程能访问或修改特定资源,从而避免数据冲突和不一致。补充点小细节(区分两个概念):
| 概念 | 含义 |
|---|---|
| 线程同步(Synchronization) | 控制多个线程对 同一共享资源 的访问 |
| 线程协作 / 协调(Coordination) | 让多个线程 有逻辑顺序地协作完成任务,比如:线程A等待线程B的信号 |
举个例子:
共享资源 = 厨房
"线程 A 正在做饭" → 加了锁
"线程 B 想用厨房" → 只能等 A 出来(解锁)
这就是线程同步: 只有一个人能操作厨房
Python 中实现线程同步的常见技术有:
1.互斥锁: Lock = _allocate_lock
2.可重入锁: _RLockdef RLock(*args, **kwargs):"""Factory function that returns a new reentrant lock.A reentrant lock must be released by the thread that acquired it. Once athread has acquired a reentrant lock, the same thread may acquire it againwithout blocking; the thread must release it once for each time it hasacquired it."""# 看源码中这个 _PyRLock 其实指向的是 _RLock类# _PyRLock = _RLockif _CRLock is None:return _PyRLock(*args, **kwargs)return _CRLock(*args, **kwargs)3.条件变量: class Condition:
4.信号量: class Semaphore:
5.事件: class Event:
6.还有一些高级封装,如 queue.Queue 自带线程安全
接下来一一进行讲解,首先来看事件通信 Event。
3.1 Event
Event 事件,是线程间通信机制中最简单的实现,使用一个内部的标记 flag,通过 flag 的 True 或 False 的变化来进行操作。Event 实例常用方法:
| 方法名 | 作用描述 |
|---|---|
.set() | 将事件标志设为 True,所有正在等待这个事件的线程将被唤醒。当 flag 标志为 True 时,调用 wait() 方法的线程不会被阻塞 |
.clear() | 将事件标志重设为 False,之后调用 wait() 方法的线程将会被阻塞,直到调用 set() 方法将内部标志再次设置为 True |
.is_set() | 检查事件标志当前是否为 True ,当且仅当内部标志为 True 时返回 True |
.wait(timeout) | 如果事件标志为 False,阻塞线程直到它变成 True 或超时 |
简单示例:
# -*- coding: utf-8 -*-
# @Time : 2025-05-24 15:17
# @Author : bb_bcxlc
# @File : 11.event事件简单例子.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threadingevent = threading.Event()
print(event.is_set()) # False
# event.wait() # 阻塞住了event.set() # 将标志置为True,无返回值
print(event.is_set()) # True
event.wait() # 设置为True后,wait()方法不阻塞
print('end ~')
练习:老板雇佣了一个工人,让他生产杯子,老板一直盯着这个工人,直到生产完10个杯子。下面的代码是否能够完成功能?
# -*- coding: utf-8 -*-
# @Time : 2025-05-24 15:52
# @Author : bb_bcxlc
# @File : 11.event练习.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import logging
import threading
import timeFormat = '%(asctime)s - %(threadName)s - %(message)s'
logging.basicConfig(level=logging.INFO, format=Format)flag = Falsedef boss():logging.info('I"m boss,watching U.')while True:time.sleep(1)if flag:breaklogging.info('Good Job~~~')def worker(count=10):global flaglogging.info('I"m working for U.')cups = []while True:time.sleep(0.5)if len(cups) >= count:flag = Truebreakcups.append(1) # 模拟杯子logging.info('I have finished my Job. cups: {}'.format(len(cups)))w = threading.Thread(target=worker, name='worker')
b = threading.Thread(target=boss, name='boss')
b.start()
w.start()
上面代码基本能够完成,但上面代码中老板一直要不停的查询 worker 的状态变化。使用 Event 修改代码后如下:
# -*- coding: utf-8 -*-
# @Time : 2025-05-24 16:53
# @Author : bb_bcxlc
# @File : 11.event练习-改进.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import logging
import threading
import timeFormat = '%(asctime)s - %(threadName)s - %(message)s'
logging.basicConfig(level=logging.INFO, format=Format)event = threading.Event() # 1:n 一个通知多个def boss(e):logging.info('I"m boss,watching U.')e.wait() # 没有设置时间,则等到天荒地老logging.info('Good Job~~~')def worker(e, count=10):logging.info('I"m working for U.')cups = []# while True:# e.wait如果没有设置标志,返回值为False# 使用wait阻塞等待while not e.wait(0.5):# time.sleep(0.5)if len(cups) >= count:e.set()# break 为啥可以注释break呢?cups.append(1) # 模拟杯子logging.info('I have finished my Job. cups: {}'.format(len(cups)))w = threading.Thread(target=worker, name='worker', args=(event,))
b1 = threading.Thread(target=boss, name='boss1', args=(event,))
b2 = threading.Thread(target=boss, name='boss2', args=(event,))
b1.start()
b2.start()
time.sleep(5)
w.start()
总结: 需要使用同一个 Event 对象的标记 flag,谁 wait 就是等到 flag 变为 True,或等到超时返回 False,不限制等待者的个数,通知所有等待者。测试 wait() 方法:
# -*- coding: utf-8 -*-
# @Time : 2025-05-24 17:07
# @Author : bb_bcxlc
# @File : 11.event测试wait.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threadingevent = threading.Event()print(event.is_set())
print(event.wait(3))
print(event.is_set())
print('~' * 30)
threading.Timer(3, lambda: event.set()).start()
print(event.wait(5))
print(event.is_set())
补充案例:模拟红绿灯交通。其中标志位设置为 True,代表绿灯,直接通行;标志位被清空,代表红灯;wait() 等待变绿灯。
# -*- coding: utf-8 -*-
# @Time : 2025-05-24 17:15
# @Author : bb_bcxlc
# @File : 11.event红绿灯.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading, time # 导入threading和time模块event = threading.Event() # 创建Event对象def lighter(): # 红绿灯处理线程函数'''0<count<2为绿灯,2<count<5为红灯,count>5重置标志'''event.set() # 设置标志位为Truecount = 0 # 递增变量,初始为0while True:if count > 2 and count < 5:event.clear() # 将标志设置为Falseprint("\033[1;41m 现在是红灯 \033[0m")elif count > 5:event.set() # 设置标志位为Truecount = 0 # 恢复初始值else:print("\033[1;42m 现在是绿灯 \033[0m")time.sleep(1)count += 1 # 递增变量def car(name): # 小车处理线程函数'''红灯停,绿灯行'''while True:if event.is_set(): # 当标志位为True时print(f"[{name}] 正在开车...")time.sleep(0.25)else: # 当标志位为False时print(f"[{name}] 看见了红灯,需要等几秒")event.wait()print(f"\033[1;34;40m 绿灯亮了,[{name}]继续开车 \033[0m")# 开启红绿灯
light = threading.Thread(target=lighter, )
light.start()
# 开始行驶
car = threading.Thread(target=car, args=("张三",))
car.start()
3.2 线程锁Lock
定义一个全局变量 g_num,分别创建2个子线程对 g_num 执行不同的操作,并输出操作后的结果。代码如下:
from threading import Thread # 导入线程
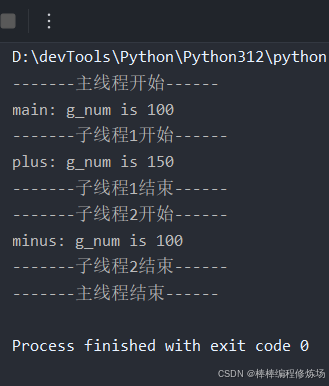
import timeg_num = 100 # 定义一个全局变量def plus(): # 第一个线程函数print('-------子线程1开始------')global g_num # 定义全局变量g_num += 50 # 全局变量值加50print('plus: g_num is %d' % g_num)print('-------子线程1结束------')def minus(): # 第二个线程函数time.sleep(3)print('-------子线程2开始------')global g_num # 定义全局变量g_num -= 50 # 全局变量值减50print('minus: g_num is %d' % g_num)print('-------子线程2结束------')if __name__ == '__main__':print('-------主线程开始------')print('main: g_num is %d' % g_num)t1 = Thread(target=plus) # 实例化线程t1t2 = Thread(target=minus) # 实例化线程t2t1.start() # 开启线程t1t2.start() # 开启线程t2t1.join() # 等待t1线程结束t2.join() # 等待t2线程结束print('-------主线程结束------')
上述代码中,定义一个全局变量 g_num,赋值为 100,然后创建2个线程。一个线程将 g_num 增加 50,一个线程将 g_num 减少 50。如果 g_num 的最终结果为 100,则说明线程之间可以共享数据。运行结果如下图所示:
从上面的例子可以得出,在一个进程内的所有线程共享全局变量,能够在不使用其他方式的前提下完成多线程之间的数据共享。由于线程可以对全局变量随意修改,这就可能造成多线程之间对全局变量的混乱操作。举个例子,订单要求生产1000个杯子,组织10个工人生产。请忽略老板,关注工人生成杯子:
# -*- coding: utf-8 -*-
# @Time : 2025-05-24 18:22
# @Author : bb_bcxlc
# @File : 12.锁的引入.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
from threading import Thread
import time
import loggingFORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)cups = []def worker(count=1000):logging.info("I'm working")while True:if len(cups) >= count:breaktime.sleep(0.0001) # 为了看出线程切换效果,模拟杯子制作时间cups.append(1)logging.info('I finished my job. cups = {}'.format(len(cups)))for i in range(1, 11):t = Thread(target=worker, name="w{}".format(i), args=(1000,))t.start()
从上例的运行结果看出,多线程调度,导致了判断失效,多生产了杯子,即造成了全局变量 cups 最后的结果混乱,不准确。再以生活中的房子为例,当房子内只有一个居住者时(单线程),他可以任意时刻使用任意一个房间,如厨房、卧室和卫生间等。但是,当这个房子有多个居住者时(多线程),他就不能在任意时刻使用某些房间,如卫生间,否则就会造成混乱。如何解决这个问题呢?一个防止他人进入的简单方法,就是门上加一把锁。先到的人锁上门,后到的人就在门口排队,等锁打开再进去。如下图所示:

这就是互斥锁(Mutual exclusion,缩写 Mutex),防止多个线程同时读写某一块内存区域。互斥锁为资源引入一个状态:锁定和非锁定。某个线程要更改共享数据时,先将其锁定,此时资源的状态为 "锁定",其他线程不能更改;直到该线程释放资源,将资源的状态变成 "非锁定" 时,其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。Python 中的 Lock 类是 mutex 互斥锁。一旦一个线程获得锁,其它试图获取锁的线程将被阻塞,直到拥有锁的线程释放锁。凡是存在共享资源争抢的地方都可以使用锁,从而保证只有一个使用者可以完全使用这个资源。
在 threading 模块中使用 Lock 类可以方便地处理锁定。Lock 类有2个方法:acquire() 锁定和 release() 释放锁。示例用法如下:
import threadingmutex = threading.Lock() # 创建锁# 获取锁定,如果有必要,需要阻塞到锁定释放为止
# 1.默认阻塞,阻塞可以设置超时时间。非阻塞时,timeout禁止设置
# 2.如果提供blocking参数并将它设置为False,当无法获取锁定时将立即返回False;如果成功获取锁定则返回True
mutex.acquire(blocking=True, timeout=-1) # 锁定# 简单讲: 释放锁。可以从任何线程调用释放,已上锁的锁,会被重置为unlocked,未上锁的锁上调用,抛 RuntimeError 异常
mutex.release() # 释放锁
锁的基本使用:
# -*- coding: utf-8 -*-
# @Time : 2025-05-24 17:58
# @Author : bb_bcxlc
# @File : 12.锁的基本使用.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
import timelock = threading.Lock() # 互斥mutex
lock.acquire()
print('-' * 30)def worker(l):print('worker start', threading.current_thread())l.acquire()print('worker done', threading.current_thread())for i in range(10):threading.Thread(target=worker, name="w{}".format(i), args=(lock,), daemon=True).start()print('-' * 30)
while True:cmd = input(">>>")if cmd == 'r': # 按r后枚举所有线程看看lock.release()print('released one locker')elif cmd == 'quit':lock.release()breakelse:print(threading.enumerate())print(lock.locked())
上例可以看出不管在哪一个线程中,只要对一个已经上锁的锁发起阻塞地请求,该线程就会阻塞。加锁,修改生产杯子的需求:
# -*- coding: utf-8 -*-
# @Time : 2025-05-24 19:03
# @Author : bb_bcxlc
# @File : 12.生产杯子-加锁.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
import time
import loggingFORMAT = "%(asctime)s %(threadName)s %(thread)d %(message)s"
logging.basicConfig(format=FORMAT, level=logging.INFO)cups = []
mutex = threading.Lock()def worker(lock, count=1000):logging.info("I'm working")while True:lock.acquire() # 获取锁if len(cups) >= count:# lock.release() # 锁位置1break# lock.release() # 锁位置2time.sleep(0.0001) # 为了看出线程切换效果,模拟杯子制作时间cups.append(1)# lock.release() # 锁位置3logging.info('I finished my job. cups = {}'.format(len(cups)))for i in range(1, 11):threading.Thread(target=worker, name="w{}".format(i), args=(mutex, 1000)).start()
锁分析:
- 锁位置2: 假设某一个瞬间,有一个工作线程A获取了锁,len(cups) 正好有 999 个,然后就释放了锁,可以继续执行下面的语句,生产一个杯子,这地方不阻塞,但是正好杯子也没有生产完。锁释放后,其他线程就可以获得锁,线程B获得了锁,发现 len(cups) 也是 999 个,然后释放锁,然后也可以去生产一个杯子。锁释放后,其他的线程也可能获得锁。就说A和B线程都认为是 999 个,都会生产一个杯子,那么实际上最后一定会超出 1000 个。假设某个瞬间一个线程获得锁,然后发现杯子到了 1000 个,没有释放锁就直接 break 了,由于其他线程还在阻塞等待锁释放,这就成了死锁了。在多任务系统下,当一个或多个线程等待系统资源,而资源又被线程本身或其他线程占用时,就形成了死锁,如下图所示:

- 锁位置3分析: 获得锁的线程发现是 999,有资格生产杯子,生产一个,释放锁,看似很完美。问题在于,获取锁的线程发现杯子有 1000 个,直接 break,没释放锁离开了,死锁了。
- 锁位置1分析: 如果线程获得锁,发现是1000,break 前释放锁,没问题。问题在于,A线程获得锁后,发现小于1000,继续执行,其他线程获得锁全部阻塞。A线程再次执行循环后,自己也阻塞了。死锁了。
问题:究竟怎样加锁才正确呢?要在锁位置1和锁位置3同时加 release()。锁是典型必须释放的,Python 提供了上下文支持。查看 Lock 类的上下文方法,__enter__() 方法返回 bool 表示是否获得锁,__exit__() 方法中释放锁。由此上例可以修改为:
def worker(lock, count=1000):logging.info("I'm working")while True:with lock:if len(cups) >= count:breaktime.sleep(0.0001) # 为了看出线程切换效果,模拟杯子制作时间cups.append(1)logging.info('I finished my job. cups = {}'.format(len(cups)))
锁的应用场景: 锁适用于访问和修改同一个共享资源的时候,即读写同一个资源的时候。如果全部都是读取同一个共享资源需要锁吗?不需要。因为这时可以认为共享资源是不可变的,每一次读取它都是一样的值,所以不用加锁。使用锁的注意事项:
- 少用锁,必要时用锁。使用了锁,多线程访问被锁的资源时,就成了串行,要么排队执行,要么争抢执行。举例,高速公路上车并行跑,可是到了只开放了一个收费口,过了这个口,车辆依然可以在多车道上一起跑。过收费口的时候,如果排队一辆辆过,加不加锁一样效率相当,但是一旦出现争抢,就必须加锁一辆辆过。注意,不管加不加锁,只要是一辆辆过,效率就下降了。
- 加锁时间越短越好,不需要就立即释放锁。一定要避免死锁
不使用锁,有了效率,但是结果是错的。使用了锁,效率低下,但是结果是对的。所以,我们是为了效率要错误结果呢?还是为了对的结果,让计算机去计算吧。
3.3 递归锁RLock
在 threading 模块中,可以定义两种类型的锁:threading.Lock 和 threading.RLock。它们的区别是:Lock 不允许重复调用 acquire() 方法来获取锁,否则容易出现死锁;而 RLock 允许在同一线程中多次调用 acquire(),不会阻塞程序,这种锁也称为递归锁。在一个线程中,acquire 和 release 必须成对出现,即调用了n次 acquire() 方法,就必须调用n次的 release() 方法,这样才能真正释放所占用的锁。
示例:
# -*- coding: utf-8 -*-
# @Time : 2025-05-24 19:47
# @Author : bb_bcxlc
# @File : 12.RLock.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading # 导入threading模块deposit = 0 # 定义变量,初始为存款余额
rlock = threading.RLock() # 创建递归锁def run_thread(n): # 线程处理函数global deposit # 声明为全局变量for i in range(1000000): # 无数次重复操作,对变量执行先存后取相同的值rlock.acquire() # 获取锁rlock.acquire() # 在同一线程内,程序不会堵塞。try: # 执行修改deposit = deposit + ndeposit = deposit - nfinally:rlock.release() # 释放锁rlock.release() # 释放锁# 创建2个线程,并分别传入不同的值
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
# 开始执行线程
t1.start()
t2.start()
# 阻塞线程
t1.join()
t2.join()
print(f'存款余额为:{deposit}')
3.4 同步协作Condition
Condition 是 threading 模块的一个子类,用于维护多个线程之间的同步协作。一个 Condition 对象允许一个或多个线程在被其他线程通知之前进行等待。其内部使用的也是 Lock 或者 RLock,同时增加了等待池功能。Condition 对象包含以下方法:
# 1.acquire(): 请求底层锁
# 2.release(): 释放底层锁
# 3.wait(self, timeout=None): 等待直到被通知发生超时
# 等待,直到条件计算为真。参数 predicate 为一个可调用对象,而且它的返回值可被解释为一个布尔值
# 4.wait_for(self, predicate, timeout=None):
# 默认唤醒一个等待这个条件的线程。这个方法唤醒最多n个正在等待这个条件变量的线程
# 5.notify(self, n=1):
# 6.notify_all(self): # 唤醒所有正在等待这个条件的线程
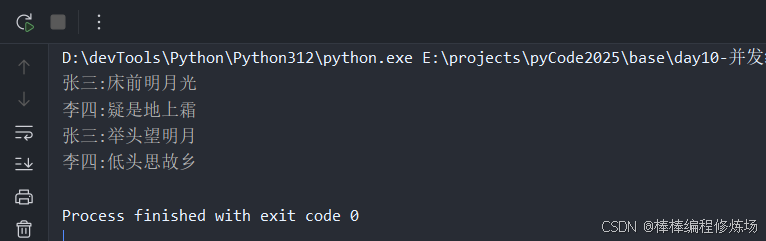
【示例】使用 Condition 来协调两个线程之间的工作,实现两个线程的交替说话。对话模拟效果如下:
张三: 床前明月光
李四: 疑是地上霜
张三: 举头望明月
李四: 低头思故乡
如果只有两句,可以使用锁机制,让某个线程先执行,本示例有多句话交替出现,适合使用 Condition。示例完整代码如下:
# -*- coding: utf-8 -*-
# @Time : 2025-05-24 19:51
# @Author : bb_bcxlc
# @File : 13.Condition.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading # 导入threading模块class ZSThead(threading.Thread): # 张三线程类def __init__(self, name, cond): # 初始化函数,接收说话人的姓名和Condition对象super(ZSThead, self).__init__()self.name = nameself.cond = conddef run(self):# 必须先调用with self.cond,才能使用wait()、notify()方法with self.cond:# 讲话print("{}:床前明月光".format(self.name))# 等待李四的回应self.cond.notify() # 通知self.cond.wait() # 等待状态# 讲话print("{}:举头望明月".format(self.name))# 等待李四的回应self.cond.notify() # 通知self.cond.wait() # 等待状态class LSThread(threading.Thread): # 李四线程类def __init__(self, name, cond):super(LSThread, self).__init__()self.name = nameself.cond = conddef run(self):with self.cond:# wait()方法不仅能获得一把锁,并且能够释放cond的大锁,# 这样张三才能进入with self.cond中self.cond.wait()print(f"{self.name}:疑是地上霜")# notify()释放wait()生成的锁self.cond.notify() # 通知self.cond.wait() # 等待状态print(f"{self.name}:低头思故乡")self.cond.notify() # 通知c = threading.Condition() # 创建条件对象
zs = ZSThead("张三", c) # 实例化张三线程
ls = LSThread("李四", c) # 实例化李四线程
ls.start() # 李四开始说话
zs.start() # 张三接着说话
ls.start() 和 zs.start() 的启动顺序很重要,必须先启动李四,让他在那里等待,因为先启动张三时,他说了话就发出了通知,但是当时李四的线程还没有启动,并且 Condition 外面的大锁也没有释放,李四也没法获取 self.cond 这把大锁。Condition 有两层锁,一把底层锁在线程调用了 wait() 方法时就会释放,每次调用 wait() 方法后,都会创建一把锁放进 Condition 的双向队列中,等待 notify() 方法的唤醒。程序运行结果如下所示:
3.5 Queue的线程安全
queue 是一个线程安全的 FIFO/LIFO/Priority 队列模块,可以在多个线程之间安全地传递数据,内部实现已经自带了锁机制,不需要我们再手动加锁。模块提供的三种队列类型:
| 队列类 | 描述 |
|---|---|
Queue.Queue(即 queue.Queue) | 先进先出队列(FIFO)✅ 最常用 |
queue.LifoQueue | 后进先出队列(LIFO,类似栈) |
queue.PriorityQueue | 优先级队列,元素必须是 (priority, item) 的形式 |
常用 API 一览:
| 方法 | 描述 |
|---|---|
put(item) | 放入一个元素,若队列满则阻塞(可配超时) |
get() | 获取一个元素,若队列空则阻塞(可配超时) |
qsize() | 当前队列元素数量(非精确,慎用) |
empty() | 判断队列是否为空(不保证绝对准确) |
full() | 判断队列是否满(同样不保证绝对准确) |
put_nowait(item) | 非阻塞放入 |
get_nowait() | 非阻塞获取 |
示例代码:
# -*- coding: utf-8 -*-
# @Time : 2025-05-24 21:18
# @Author : bb_bcxlc
# @File : 14.queue.py
# @Software: PyCharm
# @Blog: https://blog.csdn.net/xw1680import threading
import queue
import time
import randomq = queue.Queue(maxsize=5)# 生产者线程函数
def producer(name):for i in range(10):item = f"item-{i}"q.put(item) # 会阻塞直到队列有空位print(f"{name} 生产了 {item}")time.sleep(random.random())# 消费者线程函数
def consumer(name):while True:item = q.get() # 会阻塞直到队列非空print(f"{name} 消费了 {item}")time.sleep(random.random())q.task_done()# 启动线程
t1 = threading.Thread(target=producer, args=("生产者1",))
t2 = threading.Thread(target=consumer, args=("消费者1",), daemon=True)t1.start()
t2.start()t1.join()
q.join() # 等待队列任务完成
print("所有任务处理完毕")
特别注意下面的代码在多线程中使用:
import queueq = queue.Queue(8)
if q.qsize() == 7:q.put() # 上下两句可能被打断if q.qsize() == 1:q.get() # 未必会成功
如果不加锁,是不可能获得准确的大小的,因为你刚读取到了一个大小,还没有取走数据,就有可能被其他线程改了。Queue 类的 size 虽然加了锁,但是,依然不能保证立即 get、put 就能成功,因为读取大小和 get、put 方法是分开的。小结:
# 优点:
# 1.线程安全: 内部自带锁机制,避免竞态
# 2.简单高效: 使用简洁,支持阻塞/非阻塞操作
# 3.多种模式: FIFO、LIFO、优先级队列满足不同需求
# 4.可用于生产者-消费者模型: 线程间数据交互的首选方式# 使用注意事项
# 1.empty() 和 full() 不可靠,只是近似值(文档明确说明)
# 2.task_done() 必须匹配 get(),否则 join() 会一直阻塞
# 3.队列满/空时不建议使用非阻塞操作直接判断,应通过 try-except 或 timeout 控制# Queue 适合使用的场景
# 1.多线程中线程安全的数据通信
# 2.实现 生产者-消费者模式
# 3.控制任务并发量
# 4.异步任务调度(搭配 ThreadPoolExecutor 等)
至此今天的学习就到此结束了,笔者在这里声明,笔者写文章只是为了学习交流,以及让更多学习Python语言的读者少走一些弯路,节省时间,并不用做其他用途,如有侵权,联系博主删除即可。感谢您阅读本篇博文,希望本文能成为您编程路上的领航者。祝您阅读愉快!

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请点赞、评论、收藏一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
编码不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!

)



)













)