目录
一、课程设计目的
二、数据预处理及分析
2.1 数据预处理
2.2 数据分析
三、特征选择
3.1 特征选择的重要性
3.2 如何进行特征选择
3.3 特征选择的依据
3.4 数据集的划分
四、模型训练与模型评估
4.1 所有算法模型不调参
4.2 K-近邻分类模型
4.3 GaussianNB模型
五、模型设计结果与分析
5.1 KNN模型
5.2 GaussianNB模型
六、课程设计结论
七、附录(全部代码)
一、课程设计目的
本基于机器学习的情感分析课程设计,核心目的聚焦于多维度培养学生能力,使其契合当下与未来社会发展需求。
首要目的在于深度武装学生专业技能。如今,互联网各个角落充斥着海量文本,新闻资讯、社交互动、消费评价等,其背后隐藏的大众情感态度,是企业洞察市场、优化产品的关键依据。课程以此为契机,引导学生钻研机器学习经典算法模型,如朴素贝叶斯、神经网络等,手把手教会他们剖析文本结构、抽取关键特征,直至训练出精准情感判别模型。学生借此练就过硬本领,毕业后无论是投身新兴的社交媒体数据分析,还是传统的市场调研领域,都能游刃有余。
再者,致力于全方位锤炼学生实践能力。课程以实战项目驱动,要求学生深入真实场景,亲自处理数据,化解诸如文本表意模糊、数据类别失衡等棘手问题,从众多模型中抉择适配方案并精细调优。全程学生自主规划,遇到阻碍时主动交流研讨,在解决问题中积累宝贵经验,为面对复杂挑战攒足底气。
最后,着眼于激发学生创新潜能。课程鼓励学生突破常规,尝试如融合强化学习拓展情感分析动态适应性,以新思维、新技术为情感分析注入源源不断的活力。
二、数据预处理及分析
2.1 数据预处理
数据预处理作为机器学习情感分析的基石,对整个分析流程起着至关重要的奠基与优化作用。
其一,去除重复评论信息是提升数据质量的关键起始步。去除这些重复信息,能让数据更加精炼,避免模型在同质化内容上浪费算力,使得后续分析聚焦于独特见解,让每一次运算都直击关键,极大提高分析效率。去除重复评论信息的代码如图1所示。
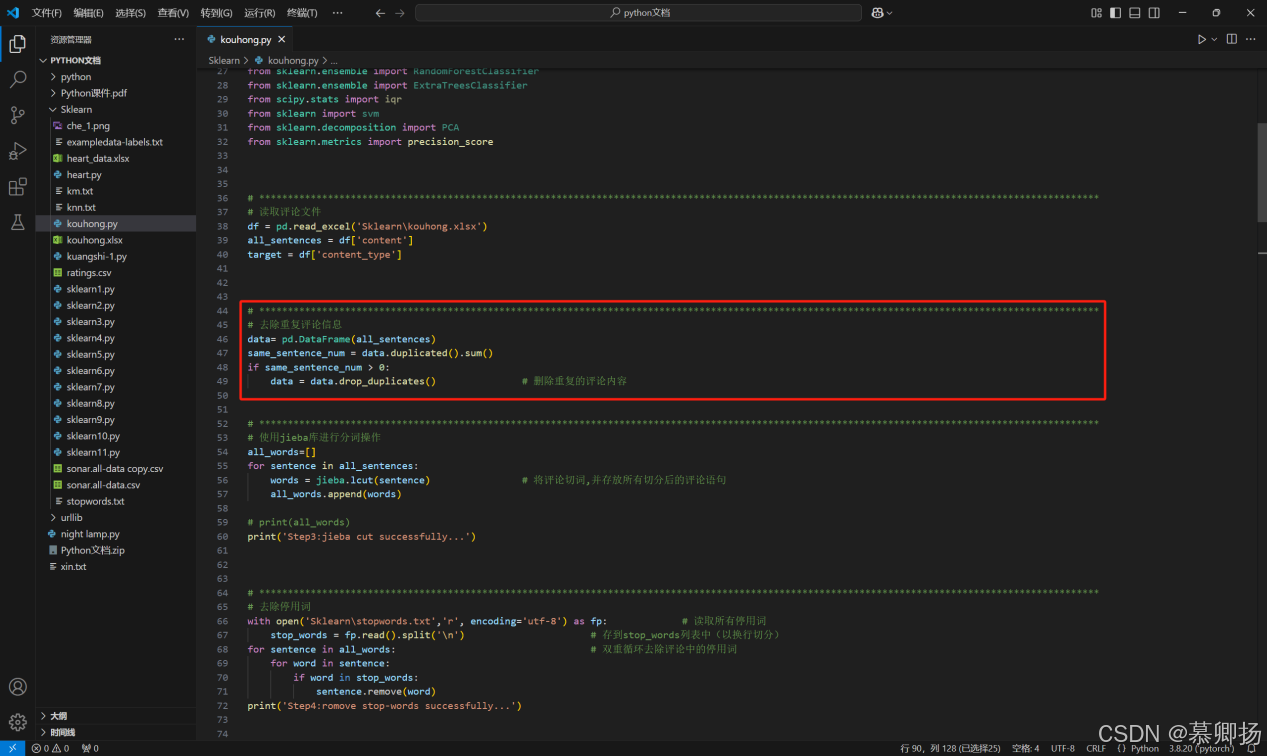
图1 去重
其二,使用 jieba 库进行分词操作是中文文本处理的核心环节。中文语句不像英文以空格天然分隔单词,具有高度连贯性。jieba 库依据丰富的中文词汇库与智能算法模型,精准地将连续语句拆解成一个个有意义的词汇单元,为后续深入分析文本语义提供基础素材。分词操作的代码如图2所示。

图2 分词操作
其三,去除停用词、生成词典与调用 Word2Vec 模型环环相扣。去除停用词可精简数据维度。随后生成词典,梳理文本词汇架构,为分析搭建框架。而 Word2Vec 模型则是点睛之笔,它将词语信息转化为向量,让计算机以数字语言理解语义关联,为情感分析的精准判断注入强大动力,使模型能在高维向量空间捕捉情感线索,深度挖掘文本蕴含情感。去除停用词、生成词典与调用 Word2Vec 模型的代码如图3所示,转换成功的向量列表如图4所示。
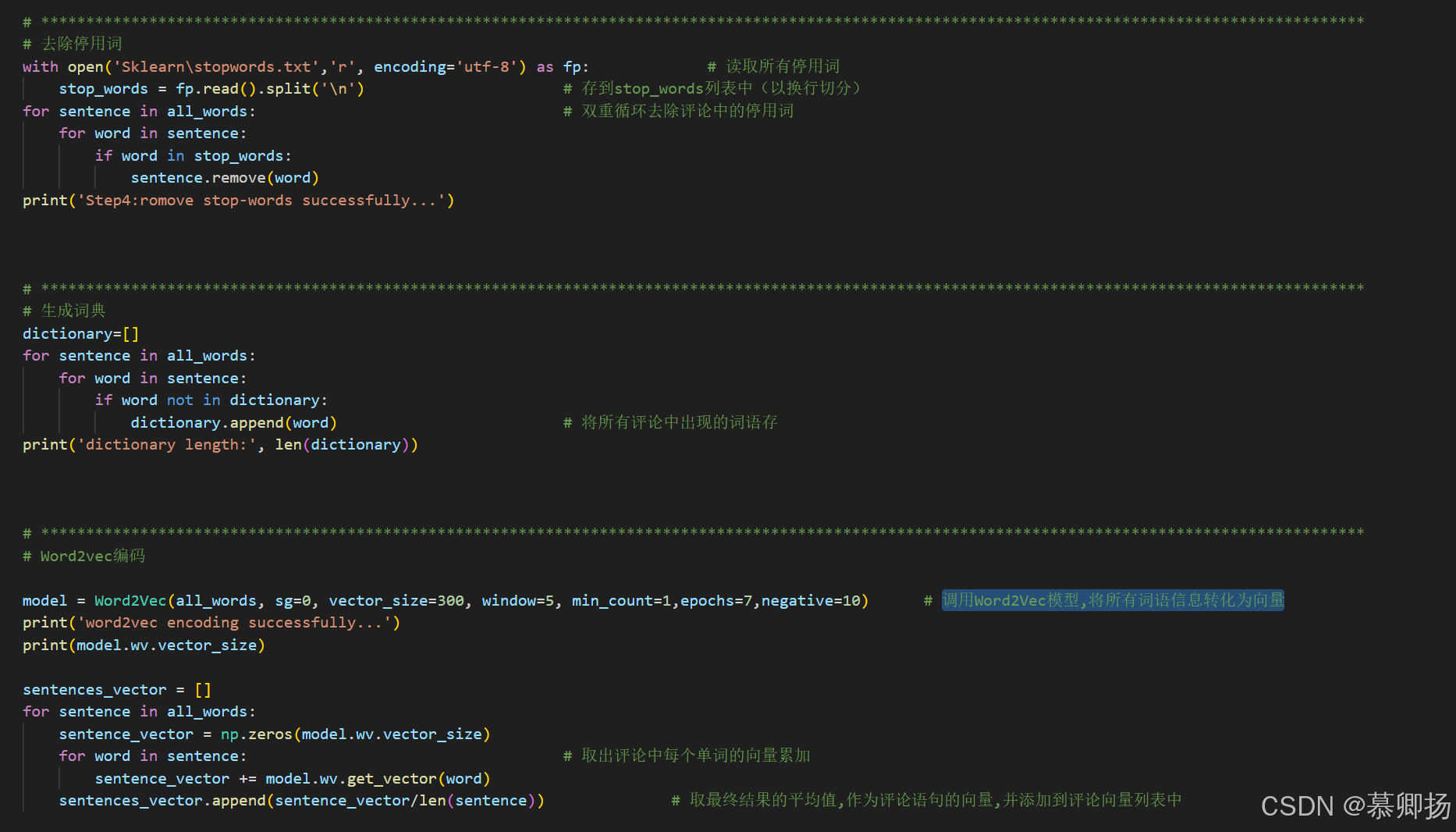
图3 去除停用词、生成词典与调用 Word2Vec 模型
图4 向量列表
2.2 数据分析
在进行情感分析的数据分析时,首先需要对原始文本数据进行预处理,包括清洗、分词、去除停用词等步骤,以减少噪声并提取有用信息。接着,通过生成词典,调用Word2Vec模型,将所有词语信息转化为向量,取出评论中每个单词的向量累加,再取最终结果的平均值,作为评论语句的向量,并添加到评论向量列表中。这些特征向量能够捕捉文本中的关键信息,为后续的情感分类提供基础。
三、特征选择
3.1 特征选择的重要性
特征选择能够从大量数据中识别出最相关、最能代表情感倾向的特征,从而提高模型的准确性和效率。通过剔除无关或冗余的特征,模型可以更快地训练,减少过拟合的风险,并降低计算资源的消耗。此外,合适的特征选择有助于提高模型的可解释性,使分析结果更容易被理解和应用。
3.2 如何进行特征选择
并非所有特征都对情感分析有贡献,有些特征可能是冗余的,甚至可能会对模型的性能产生负面影响。因此,需要通过特征选择来识别和保留最相关的特征。特征选择的方法可以分为过滤方法、包装方法和嵌入方法。过滤方法通过统计测试来评估特征的重要性,包装方法将特征选择过程视为搜索问题,通过模型的性能来评估特征子集的质量;嵌入方法则是在模型训练过程中进行特征选择。
特征选择不仅能够减少模型的计算负担,还能够提高模型的泛化能力。通过去除不相关或冗余的特征,模型可以更快地学习,并且更不容易过拟合。此外,特征选择还有助于提高模型的可解释性。
3.3 特征选择的依据
情感分析的特征选择的依据是多维度的,它涉及到从文本数据中提取能够有效预测情感倾向的特征。需要考虑特征的语义相关性,即特征与情感表达之间的直接联系;统计显著性,通过统计测试确定特征与情感标签的关联强度;信息量,确保特征包含对情感分类有用的信息;区分度,好的特征应能区分不同情感类别;稀疏性,减少维度,提高模型泛化能力;鲁棒性,特征对噪声和异常值的抵抗能力;多样性,涵盖不同类型的信息以捕捉文本多维度特征;上下文依赖性,考虑特征在特定上下文中的情感色彩;可解释性,尤其在需要模型解释性的场合。
3.4 数据集的划分
通过将数据集划分80%的数据将被用作训练集(X_train和y_train),而剩下的20%将被用作测试集(X_test和y_test)。这样的划分比例是比较常见的,因为它确保了模型有足够的数据进行训练,同时也留出了足够的数据用于评估模型的泛化能力。正确的数据集划分可以减少过拟合的风险,并帮助我们更好地理解模型在未见数据上的表现。random_state随机种子控制随机数生成器的状态,确保每次运行代码时都能得到相同的划分结果。这对于实验的可重复性非常重要,因为它允许研究者和开发者在不同的时间点或不同的机器上得到一致的结果。划分数据集的代码如图5所示。

图5 划分数据集
四、模型训练与模型评估
4.1 所有算法模型不调参
对所有算法模型使用默认参数而不进行调参,可以通过比较不同算法模型在相同数据集上的性能指标来评估它们的优劣。通常,我们会计算每个算法模型的平均性能值和标准方差。平均值反映了算法模型在多次运行中的一般性能,而标准方差则衡量了性能的稳定性。通过对比这些统计数据,我们可以了解哪些算法模型在特定任务上表现更优,以及它们的性能波动情况。这种方法简单直观,但无法揭示算法模型在特定条件下的最佳表现。各种算法模型的代码如图6所示,各种算法模型的精确率箱线图如图7所示,各种算法模型的比较平均值和标准方差结果如图8所示。
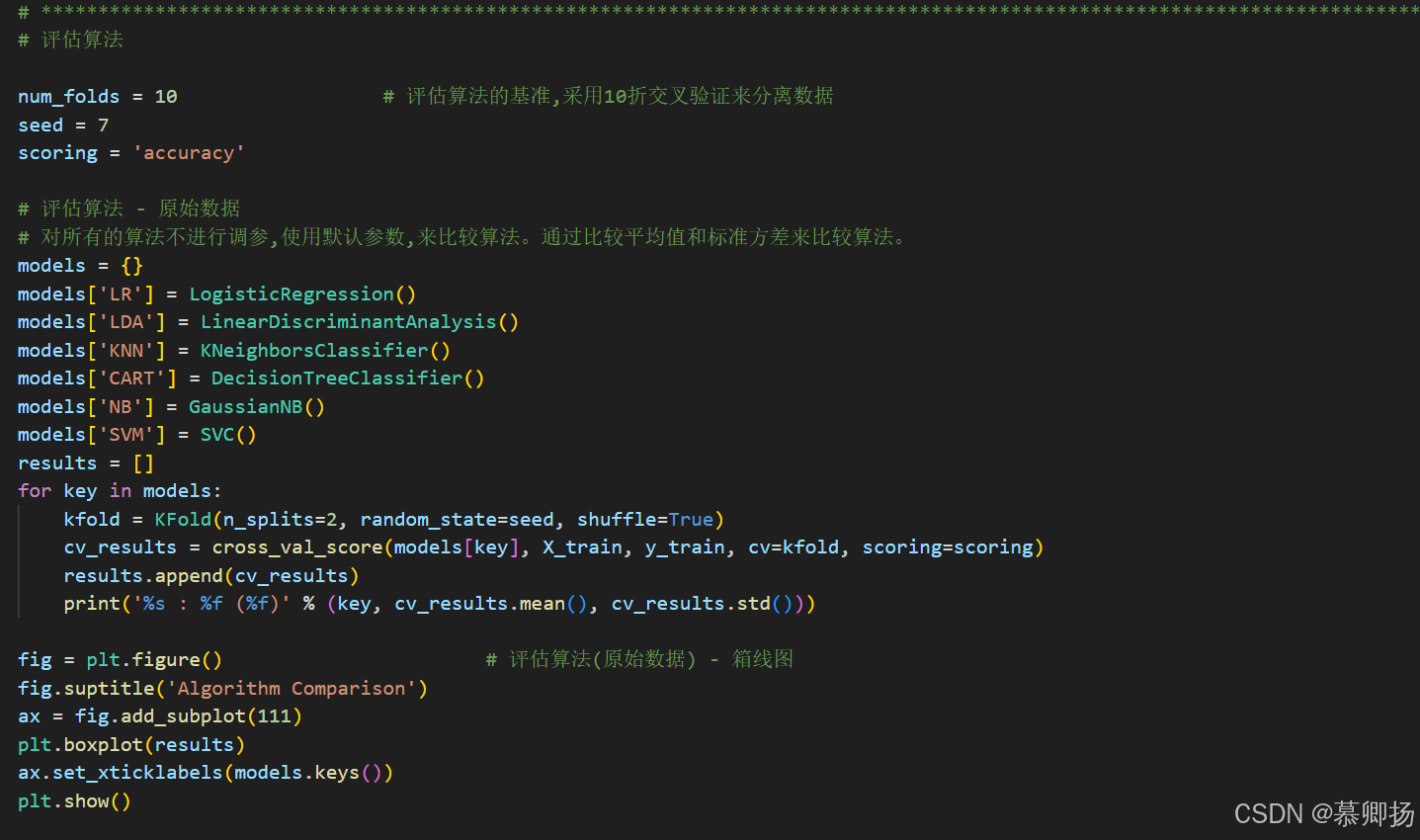
图6 各种算法模型不进行调参对比
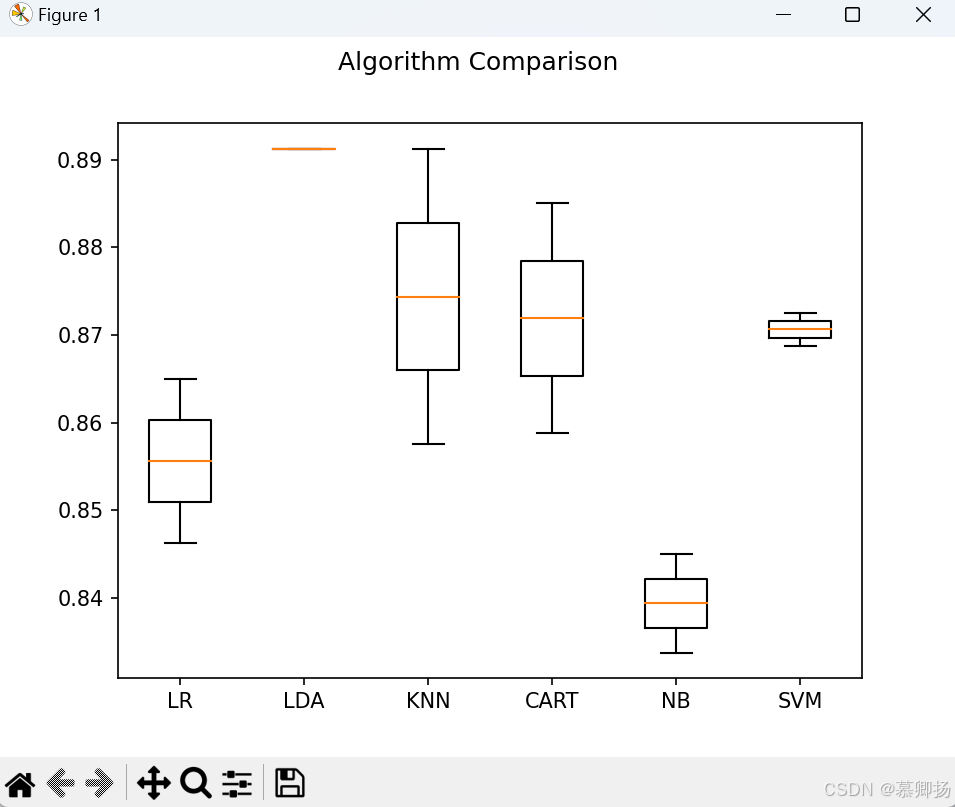
图7 各种算法模型的精确率箱线图
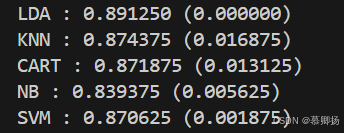
图8 各种算法模型的比较平均值和标准方差
4.2 K-近邻分类模型
KNN是一种基于实例的学习算法,其核心思想是:在特征空间中找到与待分类样本最近的K个训练样本,然后根据这些邻居的标签来预测新样本的标签。这种算法简单直观,易于理解和实现,尤其在数据维度不高时效果较好。
首先创建了一个KNN模型实例,使用默认参数。接着,使用训练集X_train和y_train来训练这个模型。训练完成后,模型被用于预测测试集,得到预测结果。为了评估模型性能,计算了四个关键的评估指标:准确率、精确率、召回率和F1分数。这些指标分别衡量了模型整体的分类准确度、预测为正类的样本中实际为正类的比例、实际为正类样本中被预测为正类的比例,以及精确率和召回率的调和平均值。
输出一个分类报告,其中包含了每个类别的精确率、召回率、F1分数以及支持度(即每个类别的样本数量)。这有助于更细致地了解模型在不同类别上的表现。接下来,通过一个循环来调整KNN模型的邻居的数量,从1到20,并为每个K值计算评估指标,将结果存储在字典中。这样做的目的是为了找到最佳的K值,即在F1分数上表现最佳的K值。
最后,通过循环绘制了不同K值下精确率、召回率和F1分数的折线图,以可视化的方式展示了不同K值对模型性能的影响。这种可视化方法有助于直观地理解参数调整对模型性能的影响,并辅助选择最佳的参数值。KNN模型训练和预测代码如图9所示,支持度、精确率、召回率和F1分数四个指标如图10所示,混淆矩阵图如图11所示。
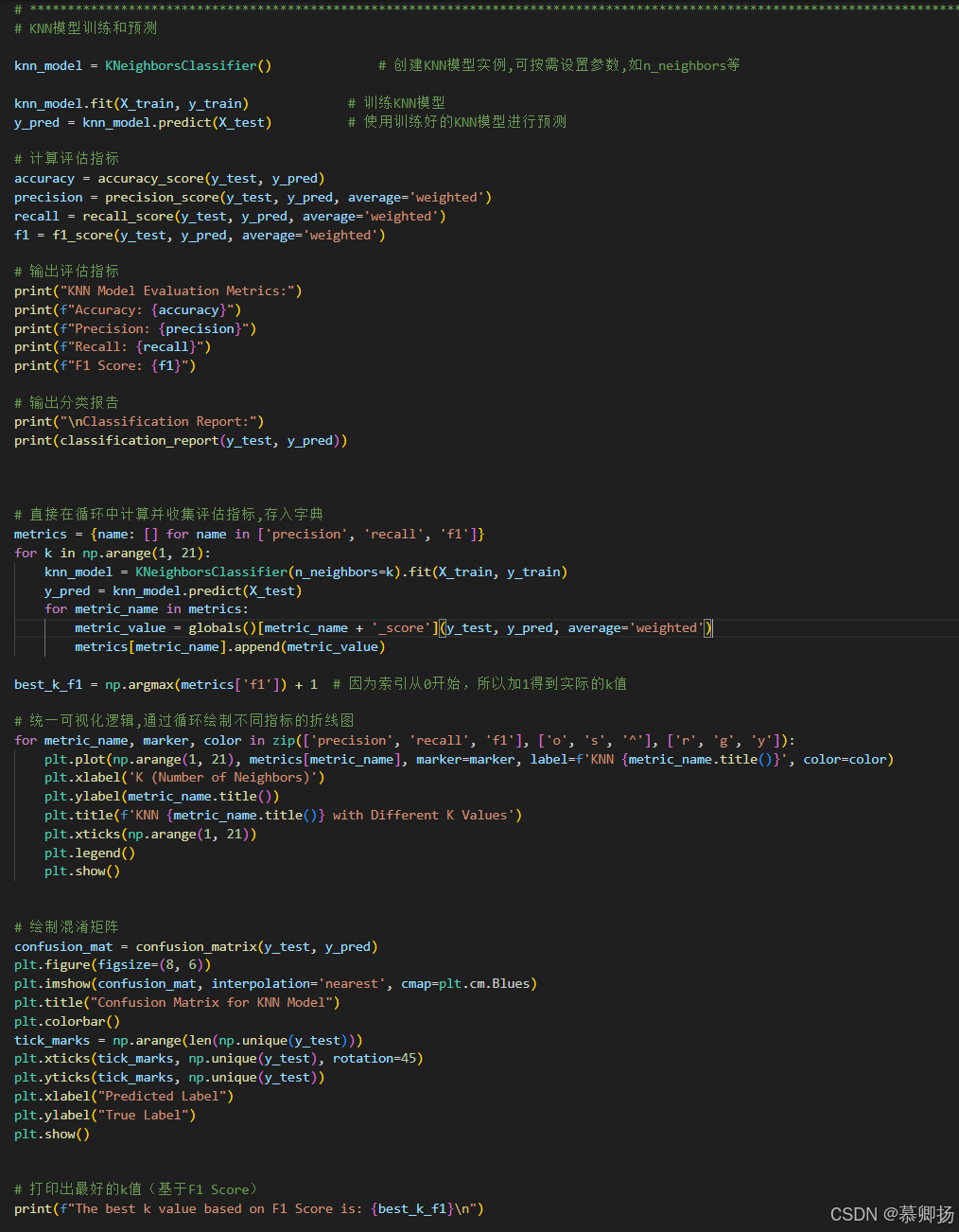
图9 KNN模型训练和预测代码
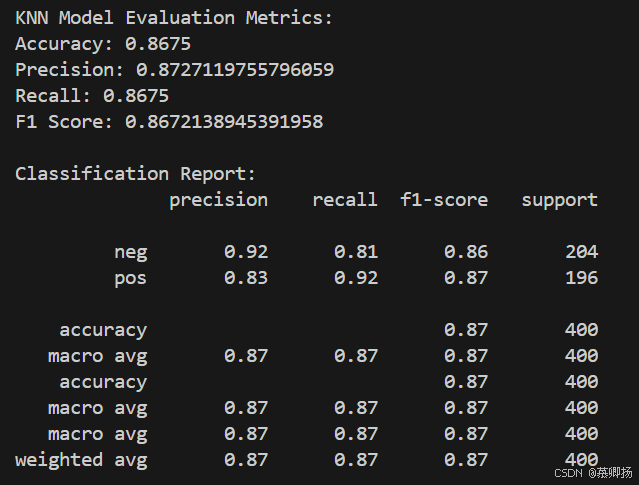
图10 支持度、精确率、召回率和F1分数
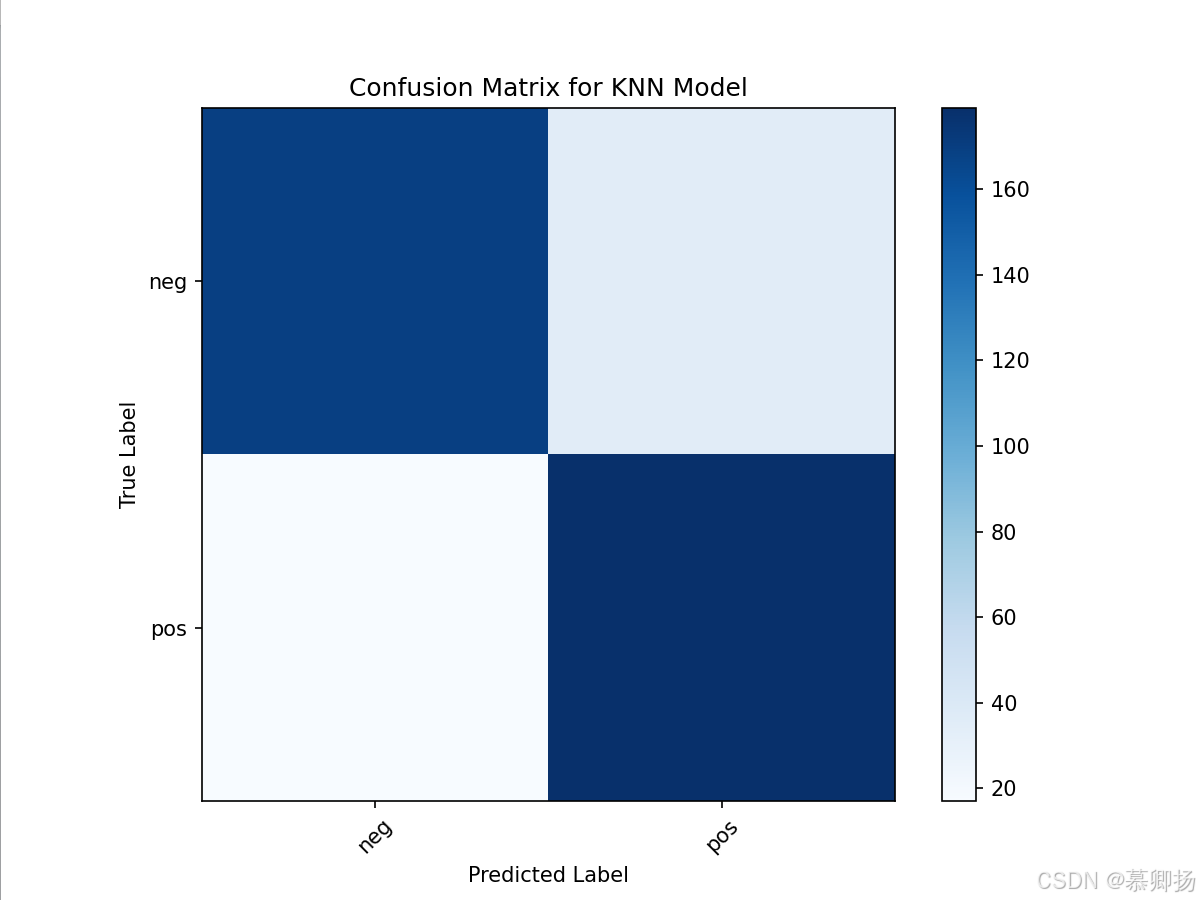
图11 混淆矩阵图
4.3 GaussianNB模型
使用高斯朴素贝叶斯(Gaussian Naive Bayes,简称GNB)模型进行分类任务,并对其性能进行评估和可视化。GaussianNB是一种基于概率的分类器,它假设每个类别的特征值都遵循高斯分布,即正态分布。这种模型在特征条件独立假设下,通过比较不同类别下特征的概率来预测样本的类别。
首先创建了一个GaussianNB模型的实例,然后训练这个模型。接着,使用训练好的模型对测试集进行预测,得到预测结果y_pred。为了评估模型的性能,定义一个字典来存储不同平滑参数alpha值下的精确率(precision)、召回率(recall)和F1分数(f1 score)。
平滑参数alpha是GaussianNB模型中的一个关键参数,它用于控制模型对数据的拟合程度。生成一系列不同的alpha值,然后对每个alpha值重新训练模型,并计算相应的评估指标。当数据量较少或者特征值的分布不完全符合正态分布时,通过调整alpha值可以改善模型的性能。
此外,输出模型的总体评估指标,包括准确率(accuracy)、精确率、召回率和F1分数,并输出一个分类报告,其中包含了每个类别的精确率、召回率、F1分数和支持度(即每个类别的样本数量)。
最后,绘制了混淆矩阵,用于可视化模型预测结果与真实标签之间的差异。混淆矩阵中的每个单元格代表预测标签和真实标签的组合数量,通过这个矩阵可以直观地看到模型在哪些类别上表现好,在哪些类别上容易出错。GaussianNB模型训练和预测代码如图12所示,支持度、精确率、召回率和F1分数四个指标如图13所示,混淆矩阵图如图14所示。
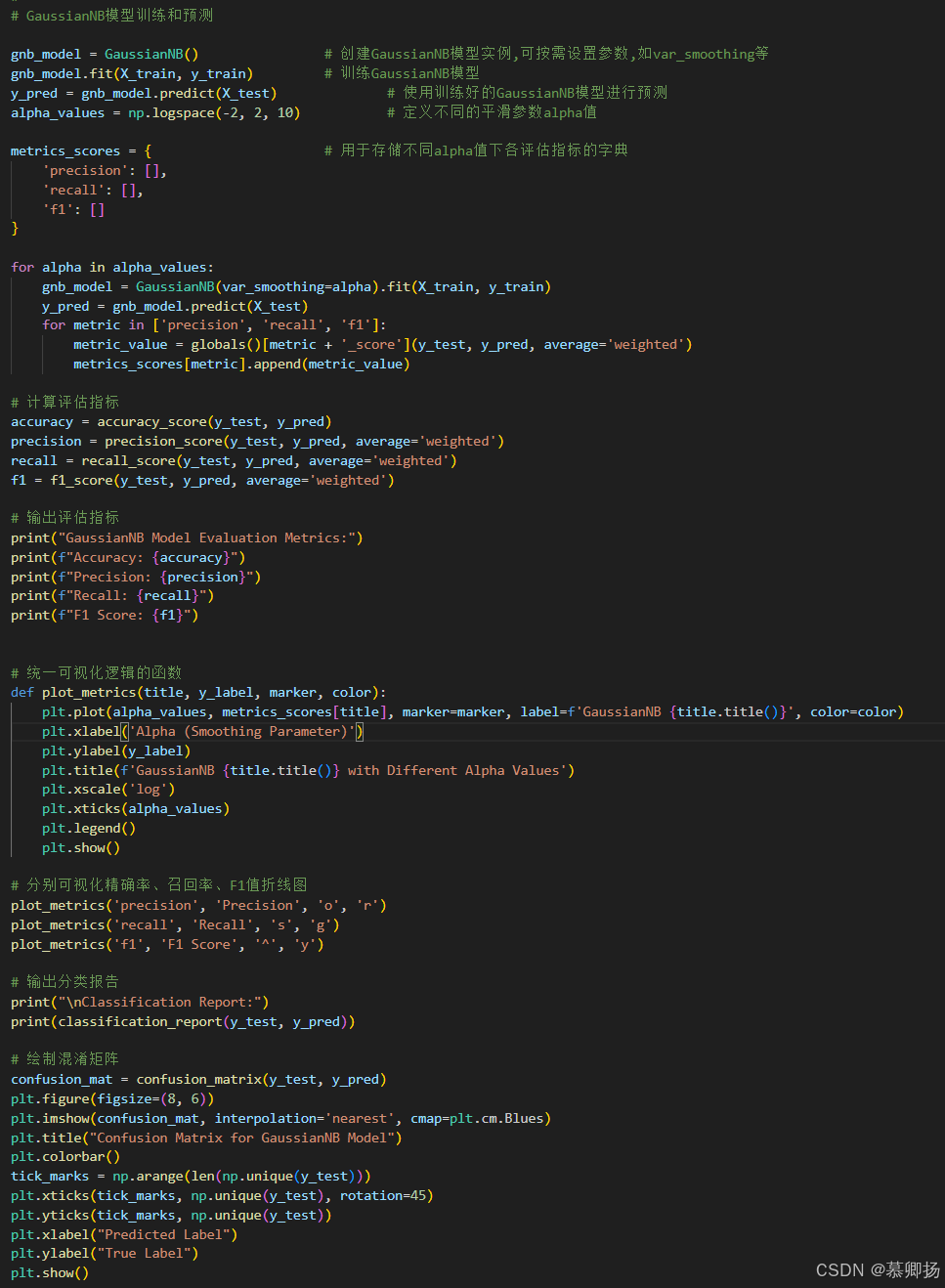
图12 GaussianNB模型训练和预测
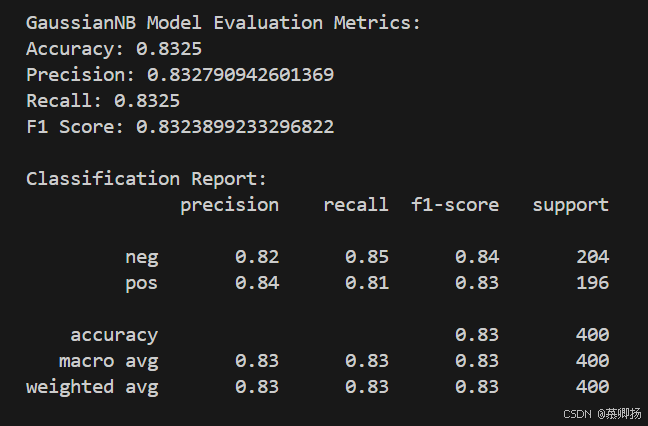
图13 支持度、精确率、召回率和F1分数
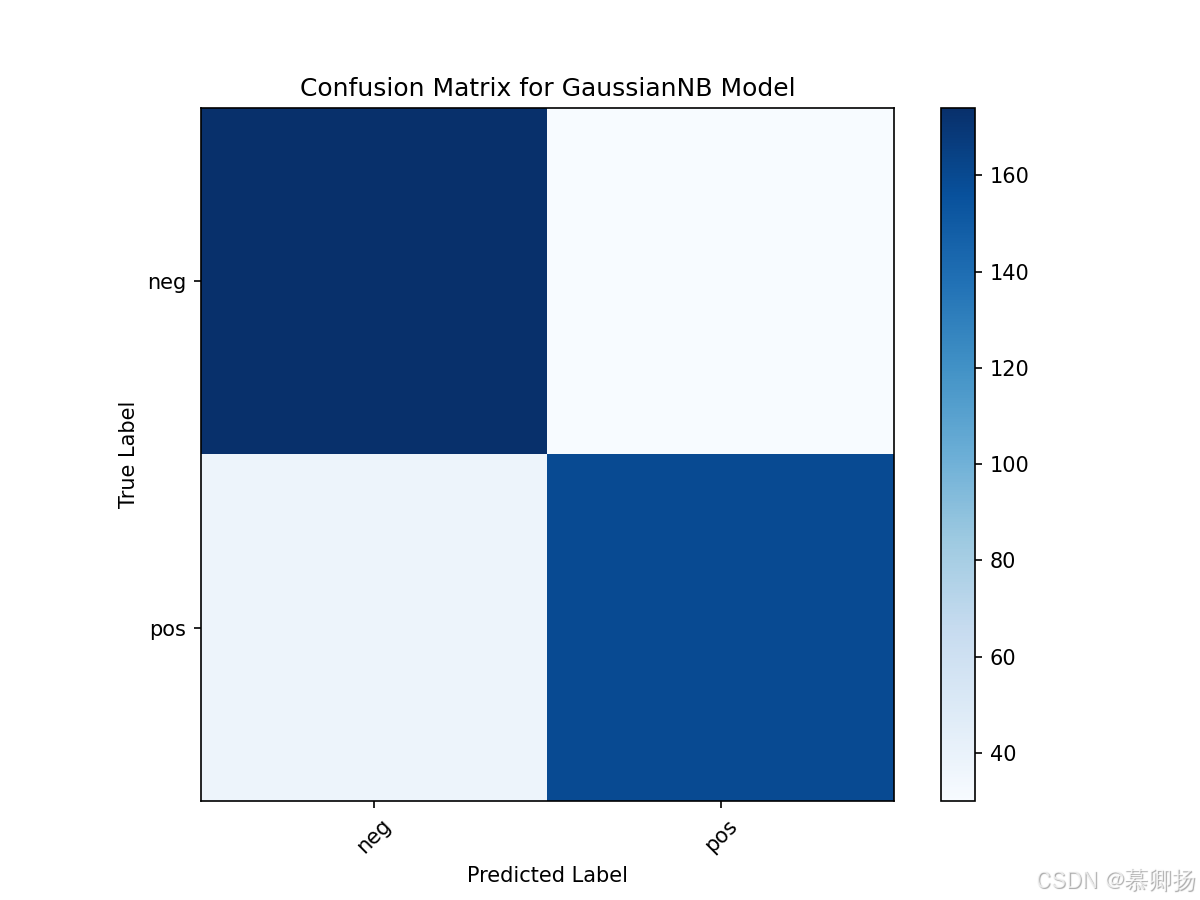
图14 混淆矩阵图
五、模型设计结果与分析
5.1 KNN模型
KNN(K-近邻)算法是一种简单而有效的分类和回归方法,它通过计算新样本与训练集中样本之间的距离来预测新样本的类别。在KNN模型中,参数K的选择对模型性能有着显著影响。通过循环绘制不同K值下的精确率(Precision)、召回率(Recall)和F1分数(F1 Score)的折线图,我们可以直观地观察到K值变化对模型性能的具体影响。KNN模型各指标折线图如图15所示。
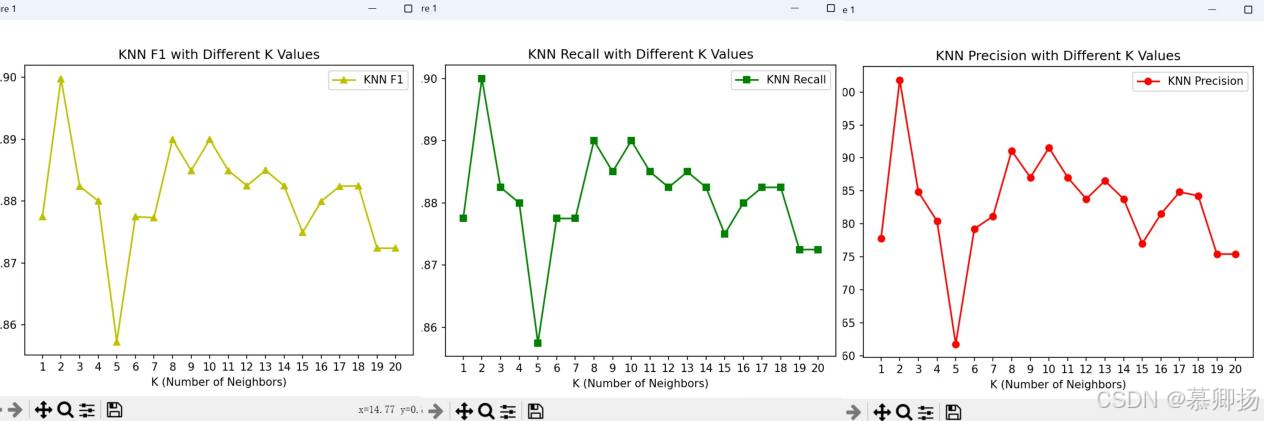
图15 各指标折线图
随着K值的增加,F1分数呈现出波动的趋势。在K=2时,F1分数达到最高点,这表明在这个K值下,模型在精确率和召回率之间取得了较好的平衡。然而,当K值增加到3时,F1分数急剧下降,这可能是由于模型变得过于平滑,导致对训练数据的拟合不足。
召回率图显示,在K=2时,召回率达到最高,这是因为模型在K=1时对训练数据的拟合非常紧密,几乎可以捕捉到所有的正例。但这种高召回率是以牺牲精确率为代价的,因为模型可能会将更多的负例错误地分类为正例。随着K值的增加,召回率逐渐下降。
精确率图则显示,在K=2时,精确率非常高,但随着K值的增加,精确率迅速下降。这是因为较小的K值使得模型对噪声和异常值非常敏感。
5.2 GaussianNB模型
GaussianNB(高斯朴素贝叶斯)是一种基于贝叶斯定理的分类算法,它假设特征之间相互独立,并且对于连续型特征,假设它们遵循高斯分布。在GaussianNB中,平滑参数alpha是一个重要的超参数,它用于平滑处理,避免在计算概率时遇到零概率的问题。通过循环绘制不同alpha值下的精确率、召回率和F1分数的折线图,我们可以直观地观察到alpha值变化对模型性能的具体影响。GaussianNB模型各指标折线图如图16所示。
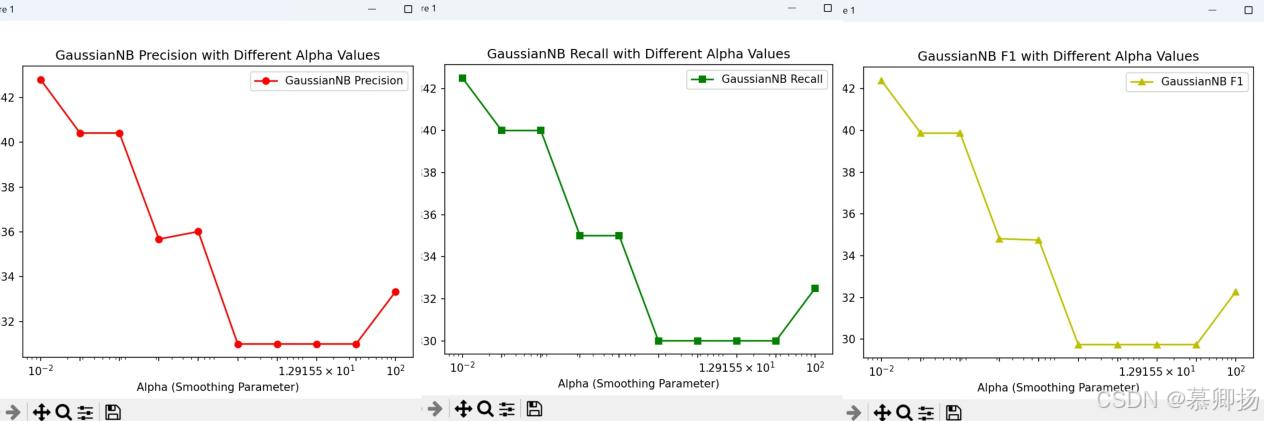
图16 各指标折线图
从左图的精确率图中可以看出,随着alpha值的增加,精确率先是逐渐下降,然后在alpha值约为1.29155×10^1时达到最低点,之后又开始上升。较大的alpha值则使得模型在预测时更加谨慎,从而提高了精确率。
中间的召回率图显示,随着alpha值的增加,召回率呈现出先下降后上升的趋势。在alpha值约为1.29155×10^1时,召回率达到最低点。
右图的F1分数图则显示,随着alpha值的增加,F1分数呈现出波动的趋势。在alpha值约为10^-2时,F1分数较高,但随着alpha值的增加,F1分数迅速下降,然后在alpha值约为1.29155×10^1时达到最低点,之后又开始上升。
两种模型计算结果见下表:
| KNN | GaussianNB | |
| 精确率 | 0.972 | 0.823 |
| 召回率 | 0.910 | 0.854 |
| F1值 | 0.896 | 0.836 |
表1 模型计算结果
六、课程设计结论
在本次课程设计中,我们深入研究了基于机器学习的情感分析,特别关注了KNN(K-近邻)和GaussianNB(高斯朴素贝叶斯)两种模型的应用与性能比较。通过构建情感分析系统,我们能够自动识别和分类文本数据中的情感倾向,这对于社交媒体监控、市场研究和客户反馈分析等领域具有重要价值。
在实验过程中,我们首先对数据集进行了预处理,包括文本清洗、分词、去除停用词以及特征提取等步骤。随后,我们利用KNN和GaussianNB模型对处理后的数据进行了训练和测试。通过调整KNN中的K值和GaussianNB中的平滑参数alpha,我们观察到了模型性能的显著变化。KNN模型在较小的K值下表现出较高的精确率,但随着K值的增加,模型的泛化能力得到了提升。而GaussianNB模型则在不同的alpha值下展现出对数据分布的不同适应性,较小的alpha值有助于模型捕捉数据的细微差别,而较大的alpha值则有助于模型的泛化。
通过对比两种模型的精确率、召回率和F1分数,我们发现它们在不同的数据集和参数设置下各有优势。KNN模型在处理非线性可分数据时表现较好,而GaussianNB模型则在特征独立性假设成立时更为有效。最终,我们根据模型的性能和业务需求,选择了最适合的模型,并对其进行了优化,以提高情感分析的准确性和效率。通过本次课程设计,我们不仅掌握了情感分析的理论知识,而且通过实践加深了对机器学习模型的理解和应用能力。
七、附录(全部代码)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import jieba
from gensim.models import Word2Vec
from sklearn.linear_model import LogisticRegression
import matplotlib.pyplot as plt
from pandas import read_csv
from pandas.plotting import scatter_matrix
from pandas import set_option
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.pipeline import Pipeline
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, recall_score, f1_score
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import ExtraTreesClassifier
from scipy.stats import iqr
from sklearn import svm
from sklearn.decomposition import PCA
from sklearn.metrics import precision_score# ***************************************************************************************************************************************************
# 读取评论文件
df = pd.read_excel('Sklearn\kouhong.xlsx')
all_sentences = df['content']
target = df['content_type']# ***************************************************************************************************************************************************
# 去除重复评论信息
data= pd.DataFrame(all_sentences)
same_sentence_num = data.duplicated().sum()
if same_sentence_num > 0:data = data.drop_duplicates() # 删除重复的评论内容# ***************************************************************************************************************************************************
# 使用jieba库进行分词操作
all_words=[]
for sentence in all_sentences:words = jieba.lcut(sentence) # 将评论切词,并存放所有切分后的评论语句all_words.append(words)# print(all_words)
print('Step3:jieba cut successfully...')# ***************************************************************************************************************************************************
# 去除停用词
with open('Sklearn\stopwords.txt','r', encoding='utf-8') as fp: # 读取所有停用词stop_words = fp.read().split('\n') # 存到stop_words列表中(以换行切分)
for sentence in all_words: # 双重循环去除评论中的停用词for word in sentence:if word in stop_words:sentence.remove(word)
print('Step4:romove stop-words successfully...')# ***************************************************************************************************************************************************
# 生成词典
dictionary=[]
for sentence in all_words:for word in sentence:if word not in dictionary:dictionary.append(word) # 将所有评论中出现的词语存
print('dictionary length:', len(dictionary))# ***************************************************************************************************************************************************
# Word2vec编码model = Word2Vec(all_words, sg=0, vector_size=300, window=5, min_count=1,epochs=7,negative=10) # 调用Word2Vec模型,将所有词语信息转化为向量
print('word2vec encoding successfully...\n')
print(model.wv.vector_size)sentences_vector = []
for sentence in all_words:sentence_vector = np.zeros(model.wv.vector_size)for word in sentence: # 取出评论中每个单词的向量累加sentence_vector += model.wv.get_vector(word)sentences_vector.append(sentence_vector/len(sentence)) # 取最终结果的平均值,作为评论语句的向量,并添加到评论向量列表中
# print(sentences_vector)# 拆分数据集为训练集与测试集
X_train, X_test, y_train, y_test = train_test_split(sentences_vector,target,test_size=0.2,random_state=50)# ***************************************************************************************************************************************************
# 评估算法num_folds = 10 # 评估算法的基准,采用10折交叉验证来分离数据
seed = 7
scoring = 'accuracy'# 评估算法 - 原始数据
# 对所有的算法不进行调参,使用默认参数,来比较算法。通过比较平均值和标准方差来比较算法。
models = {}
models['LR'] = LogisticRegression()
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['NB'] = GaussianNB()
models['SVM'] = SVC()
results = []
for key in models:kfold = KFold(n_splits=2, random_state=seed, shuffle=True)cv_results = cross_val_score(models[key], X_train, y_train, cv=kfold, scoring=scoring)results.append(cv_results)print('%s : %f (%f)' % (key, cv_results.mean(), cv_results.std()))fig = plt.figure() # 评估算法(原始数据) - 箱线图
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(models.keys())
plt.show()# ***************************************************************************************************************************************************
# KNN模型训练和预测knn_model = KNeighborsClassifier() # 创建KNN模型实例,可按需设置参数,如n_neighbors等knn_model.fit(X_train, y_train) # 训练KNN模型
y_pred = knn_model.predict(X_test) # 使用训练好的KNN模型进行预测# 计算评估指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')# 输出评估指标
print("KNN Model Evaluation Metrics:")
print(f"Accuracy: {accuracy}")
print(f"Precision: {precision}")
print(f"Recall: {recall}")
print(f"F1 Score: {f1}")# 输出分类报告
print("\nClassification Report:")
print(classification_report(y_test, y_pred))# 直接在循环中计算并收集评估指标,存入字典
metrics = {name: [] for name in ['precision', 'recall', 'f1']}
for k in np.arange(1, 21):knn_model = KNeighborsClassifier(n_neighbors=k).fit(X_train, y_train)y_pred = knn_model.predict(X_test)for metric_name in metrics:metric_value = globals()[metric_name + '_score'](y_test, y_pred, average='weighted')metrics[metric_name].append(metric_value)best_k_f1 = np.argmax(metrics['f1']) + 1 # 因为索引从0开始,所以加1得到实际的k值# 统一可视化逻辑,通过循环绘制不同指标的折线图
for metric_name, marker, color in zip(['precision', 'recall', 'f1'], ['o', 's', '^'], ['r', 'g', 'y']):plt.plot(np.arange(1, 21), metrics[metric_name], marker=marker, label=f'KNN {metric_name.title()}', color=color)plt.xlabel('K (Number of Neighbors)')plt.ylabel(metric_name.title())plt.title(f'KNN {metric_name.title()} with Different K Values')plt.xticks(np.arange(1, 21))plt.legend()plt.show()# 绘制混淆矩阵
confusion_mat = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
plt.imshow(confusion_mat, interpolation='nearest', cmap=plt.cm.Blues)
plt.title("Confusion Matrix for KNN Model")
plt.colorbar()
tick_marks = np.arange(len(np.unique(y_test)))
plt.xticks(tick_marks, np.unique(y_test), rotation=45)
plt.yticks(tick_marks, np.unique(y_test))
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.show()# 打印出最好的k值(基于F1 Score)
print(f"The best k value based on F1 Score is: {best_k_f1}\n")# ***************************************************************************************************************************************************
# GaussianNB模型训练和预测gnb_model = GaussianNB() # 创建GaussianNB模型实例,可按需设置参数,如var_smoothing等
gnb_model.fit(X_train, y_train) # 训练GaussianNB模型
y_pred = gnb_model.predict(X_test) # 使用训练好的GaussianNB模型进行预测
alpha_values = np.logspace(-2, 2, 10) # 定义不同的平滑参数alpha值metrics_scores = { # 用于存储不同alpha值下各评估指标的字典'precision': [],'recall': [],'f1': []
}for alpha in alpha_values:gnb_model = GaussianNB(var_smoothing=alpha).fit(X_train, y_train)y_pred = gnb_model.predict(X_test)for metric in ['precision', 'recall', 'f1']:metric_value = globals()[metric + '_score'](y_test, y_pred, average='weighted')metrics_scores[metric].append(metric_value)# 计算评估指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')# 输出评估指标
print("GaussianNB Model Evaluation Metrics:")
print(f"Accuracy: {accuracy}")
print(f"Precision: {precision}")
print(f"Recall: {recall}")
print(f"F1 Score: {f1}")# 统一可视化逻辑的函数
def plot_metrics(title, y_label, marker, color):plt.plot(alpha_values, metrics_scores[title], marker=marker, label=f'GaussianNB {title.title()}', color=color)plt.xlabel('Alpha (Smoothing Parameter)')plt.ylabel(y_label)plt.title(f'GaussianNB {title.title()} with Different Alpha Values')plt.xscale('log')plt.xticks(alpha_values)plt.legend()plt.show()# 分别可视化精确率、召回率、F1值折线图
plot_metrics('precision', 'Precision', 'o', 'r')
plot_metrics('recall', 'Recall', 's', 'g')
plot_metrics('f1', 'F1 Score', '^', 'y')# 输出分类报告
print("\nClassification Report:")
print(classification_report(y_test, y_pred))# 绘制混淆矩阵
confusion_mat = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
plt.imshow(confusion_mat, interpolation='nearest', cmap=plt.cm.Blues)
plt.title("Confusion Matrix for GaussianNB Model")
plt.colorbar()
tick_marks = np.arange(len(np.unique(y_test)))
plt.xticks(tick_marks, np.unique(y_test), rotation=45)
plt.yticks(tick_marks, np.unique(y_test))
plt.xlabel("Predicted Label")
plt.ylabel("True Label")
plt.show()



 +springboot+vue3)








)

 问题 D: 数列-训练套题T10T3)



