目录
引言
1.栈的概念和结构
栈的核心概念
栈的结构
2.栈的实现
2.1栈的实现方式
2.2栈的功能
2.3栈的声明
1.顺序栈
2。链式栈
2.4栈的功能实现
1.栈的初始化
2.判断栈是否为空
3.返回栈顶元素
4.返回栈的大小
5.元素入栈
6.元素出栈
7.打印栈的元素
8.销毁栈
3.顺序栈和链式栈的对比
适用场景
总结
4.完整代码
1.顺序表
2.链式表
结束语
引言
在学习完链表之后,我们接下来学习数据结构——栈。
学习目标:
- 1.栈的概念和结构
- 2.栈的实现
- 3.顺序栈和链式栈的对比
1.栈的概念和结构
栈(Stack)是一种线性数据结构,其核心特点是 “后进先出”(Last In, First Out,LIFO)—— 即最后入栈的元素会最先被弹出。这种特性类似于日常生活中的 “叠盘子”:最后叠上去的盘子,会被最先拿走。
栈的核心概念
- 入栈(Push):向栈顶添加元素。
- 出栈(Pop):从栈顶移除并返回元素(栈为空时无法出栈)。
- 栈顶(Top):栈中最上方的元素(最后入栈的元素)。
- 栈底(Bottom):栈中最下方的元素(最先入栈的元素)。
- 栈空(Empty):栈中没有任何元素的状态。
- 栈的大小(Size):栈中元素的数量。
栈的结构
栈的结构可以抽象为一个 “容器”,元素只能从一端(栈顶)进行插入和删除操作,另一端(栈底)是固定的。
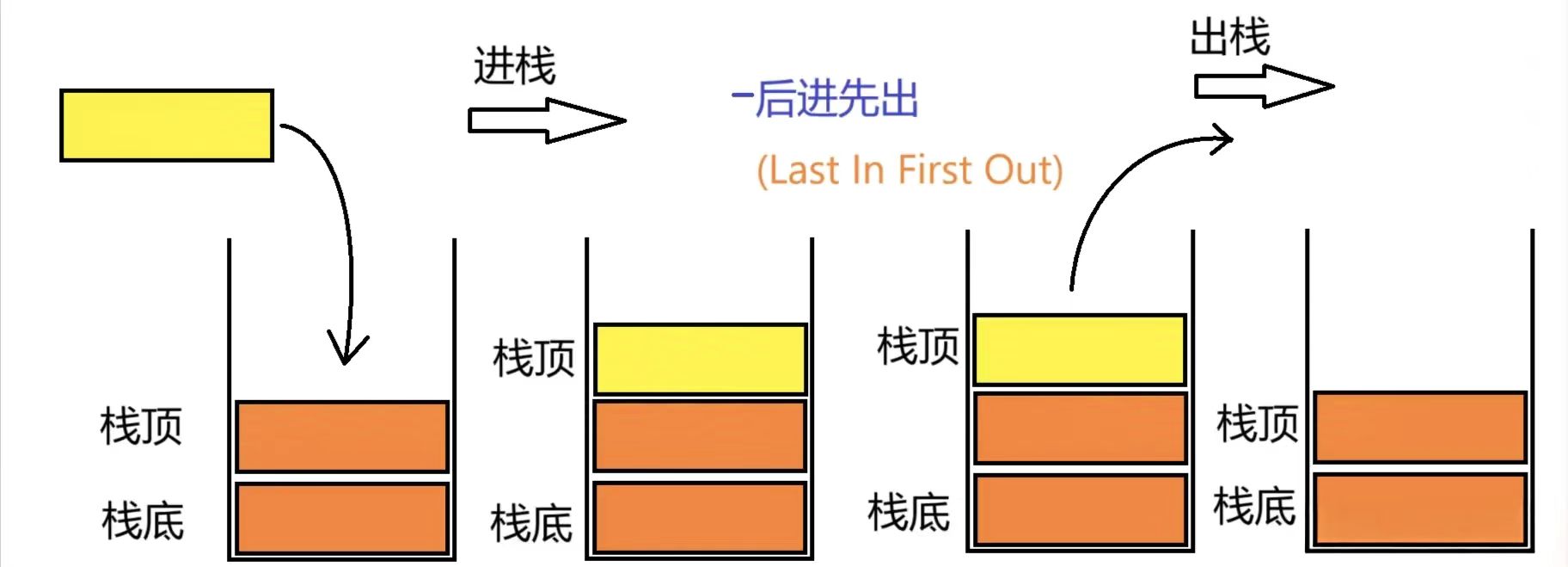
“后进先出”(Last In, First Out,LIFO):
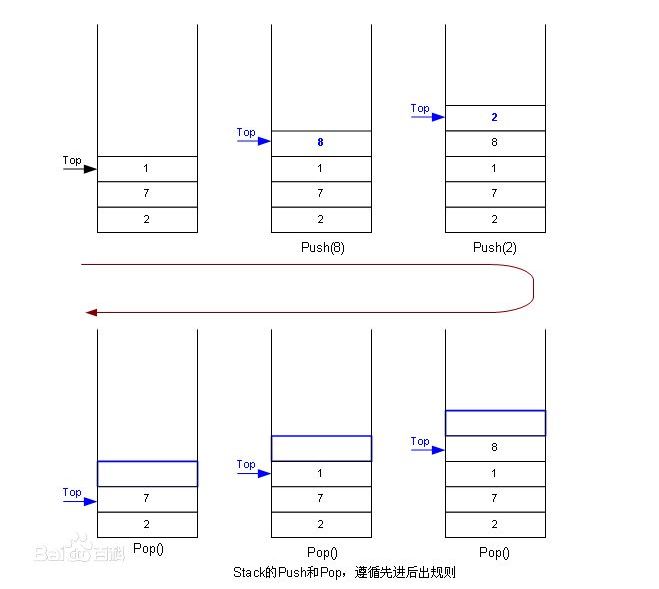
栈顶(Top):栈顶是栈中最后添加(push)元素的位置,也是最先被移除(pop)或查看(peek/top)的元素所在的位置。在栈的所有操作中,无论是添加、删除还是查看元素,都是针对栈顶进行的。因此,栈顶是栈中最活跃、最频繁被访问的位置。
栈底(Bottom):栈底是栈中最早被添加进去的元素所在的位置,也是栈中唯一一个固定不变的位置(除非整个栈被清空)。在栈的常规操作中,栈底元素不会被直接访问,除非是将整个栈的内容倒序输出或者栈被完全清空。因此,栈底在栈的操作中扮演的是一个相对静态的角色。
压栈:栈的插入操作叫做进栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈,出数据也在栈顶。
-
在计算机领域,栈有着广泛应用。例如,在编程语言中,函数调用时会使用栈来管理局部变量和返回地址。当一个函数被调用时,其相关的信息(如参数、局部变量等)会被压入栈中,函数执行完毕后,这些信息会从栈中弹出。此外,表达式求值、括号匹配等问题也常借助栈来解决。
2.栈的实现
2.1栈的实现方式
栈可以通过两种常见的数据结构实现:
-
数组实现(顺序栈)
- 用数组存储元素,栈顶对应数组的最后一个索引。
- 入栈:在数组尾部添加元素(时间复杂度 O (1))。
- 出栈:删除数组尾部元素(时间复杂度 O (1))。
- 缺点:数组大小固定,可能出现溢出(需动态扩容)。
-
链表实现(链式栈)
- 用链表的头节点作为栈顶,每次操作头节点。
- 入栈:在链表头部插入新节点(时间复杂度 O (1))。
- 出栈:删除链表头部节点(时间复杂度 O (1))。
- 优点:大小灵活,无需考虑扩容。
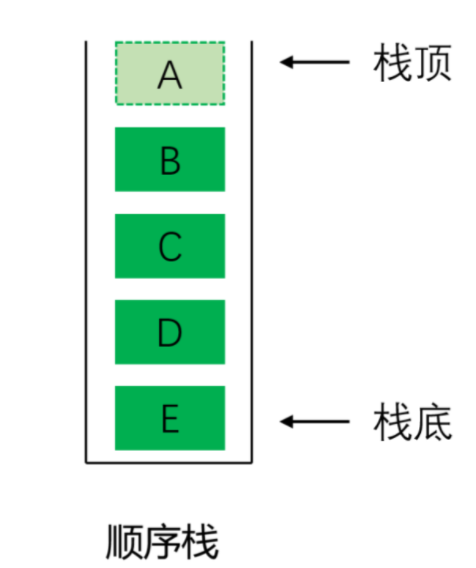
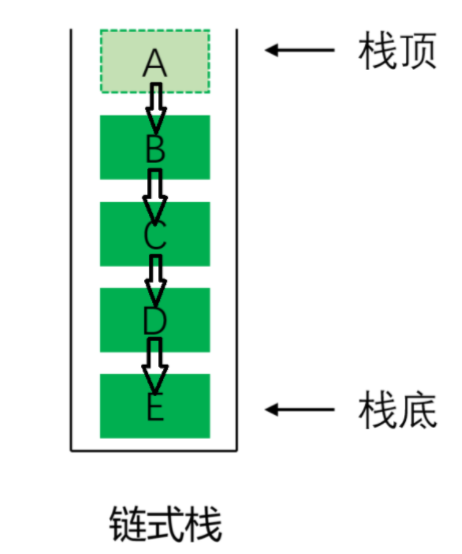
相对而言数组的结构实现更优,因为数组在尾上插入数据的代价比较小。
2.2栈的功能
栈的数据结构要实现如下功能:
1.栈的初始化。
2.判断栈是否为空。
3.返回队头元素。
4.返回栈的大小。
5.元素入栈。6.元素出栈。
7.打印栈的元素。
8.销毁栈。
2.3栈的声明
1.顺序栈
顺序栈的声明需要一个指向一块空间的指针a,指向栈顶元素的top,以及标志栈空间大小的capacity。
typedef int STDataType;typedef struct STDataType
{STDataType* a;int top;int capacity;
}ST;2.链式栈
链式栈的声明只需要一个top指针,以及栈的容量capacity。
当然这里需要链表的声明。
typedef int STDataType;typedef struct SListNode
{STDataType data;struct SListNode* next;
}SLTNode;typedef struct Stack
{// 指向栈顶节点的指针SLTNode* top;int size;
}ST;2.4栈的功能实现
1.栈的初始化
顺序栈和链式栈都可以先初始为NULL。
(1)顺序栈
顺序栈可以将top设置为-1,capacity设置为0。
代码如下:
//栈的初始化
void STInit(ST* st)
{assert(st);st->a = NULL;st->top = -1;st->capacity = 0;
}(2)链式栈
链式栈将size设置为0,top设置为NULL。
//栈的初始化
void STInit(ST* st)
{assert(st);st->size = 0;st->top = NULL;
}2.判断栈是否为空
判断栈是否为空只需要判断top的指向。
(1)顺序栈
当top=-1则为空。
代码如下:
//判空
bool STEmpty(ST* st)
{assert(st);return st->top == -1;
}(2)链式栈
判断top是否指向NULL。
//判空
bool STEmpty(ST* st)
{return (st->top == NULL);
}3.返回栈顶元素
(1)顺序栈
//取出栈顶数据
STDataType STTop(ST* st)
{assert(st);// 断言确保栈不为空(即栈顶索引不小于0)assert(st->top >= 0);return st->a[st->top];
}(2)链式栈
//取出栈顶数据
STDataType STTop(ST* st)
{assert(st);assert(!STEmpty(st));return st->top->data;
}4.返回栈的大小
(1)顺序栈
由于在一开始将top设置为-1,需要top+1才能符合需要。
代码如下:
//获取数据个数
STDataType STSize(ST* st)
{assert(st);return st->top + 1;
}(2)链式栈
//获取数据个数
STDataType STSize(ST* st)
{return st->size;
}5.元素入栈
注意:入栈需要检查空间是否足够。
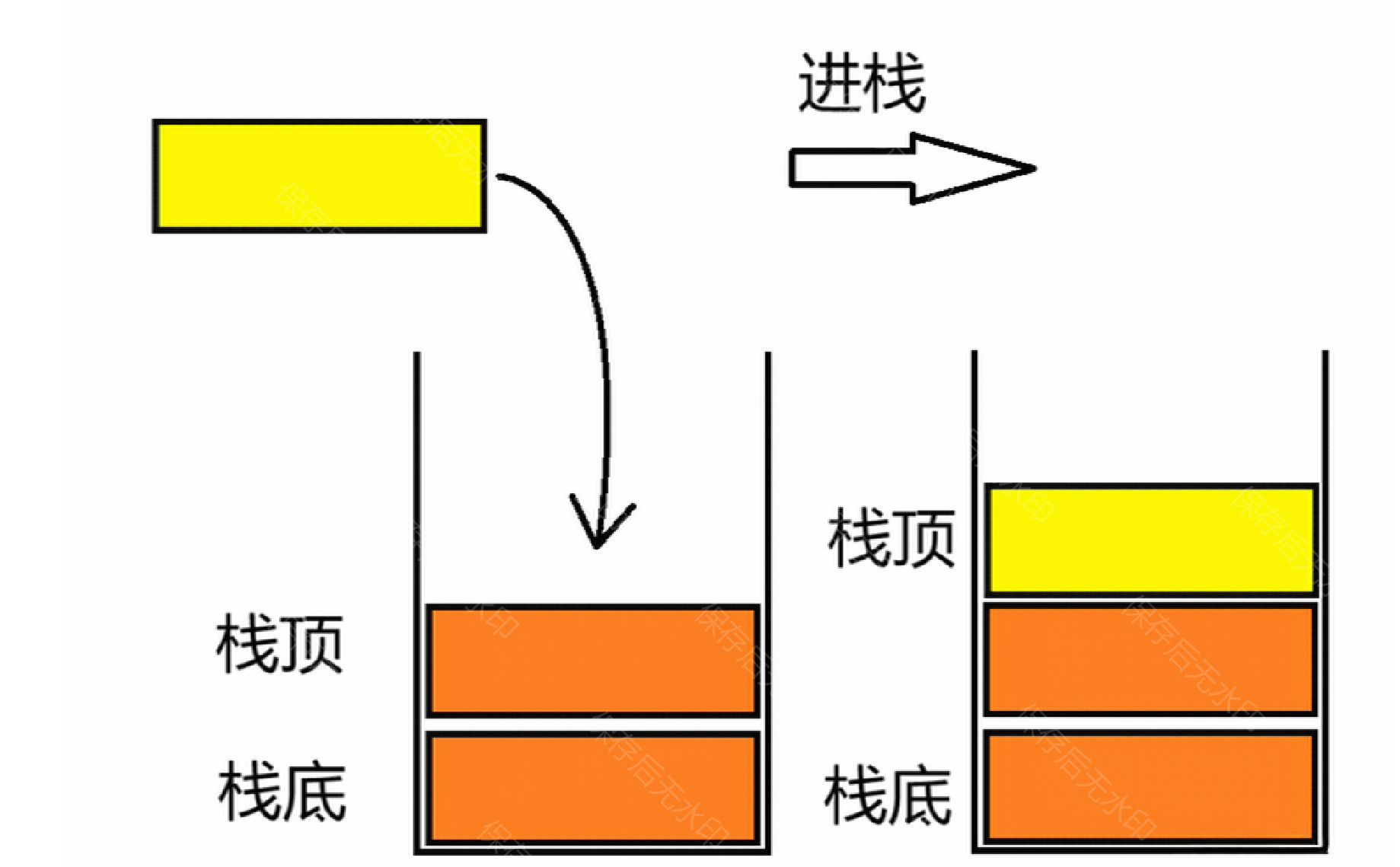
(1)顺序栈
由于top设置的是-1,因此需要先腾出空间然后再将新元素x放在栈顶。
代码如下:
//入栈
void STPush(ST* st, STDataType x)
{assert(st);// 注意:由于top初始化为-1,所以满的条件是top == capacity - 1if (st->top == st->capacity - 1){// 如果栈已满,则扩展栈的容量int newcapacity = st->capacity == 0 ? 4 : st->capacity * 2;STDataType* tmp = (STDataType*)realloc(st->a, newcapacity * sizeof(STDataType));if (tmp == NULL){perror("realloc fail:");return;}st->a = tmp;st->capacity = newcapacity;}// 增加栈顶索引,为新元素腾出空间st->top++;// 将新元素x存储在栈顶位置st->a[st->top] = x;
}(2)链式栈
//入栈
void STPush(ST* st, STDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror("malloc fail:");return;}// 新节点的next指向原来的栈顶newnode->next = st->top;// 设置新节点的数据newnode->data = x;// 更新栈顶为新节点st->top = newnode;st->size++;
}6.元素出栈
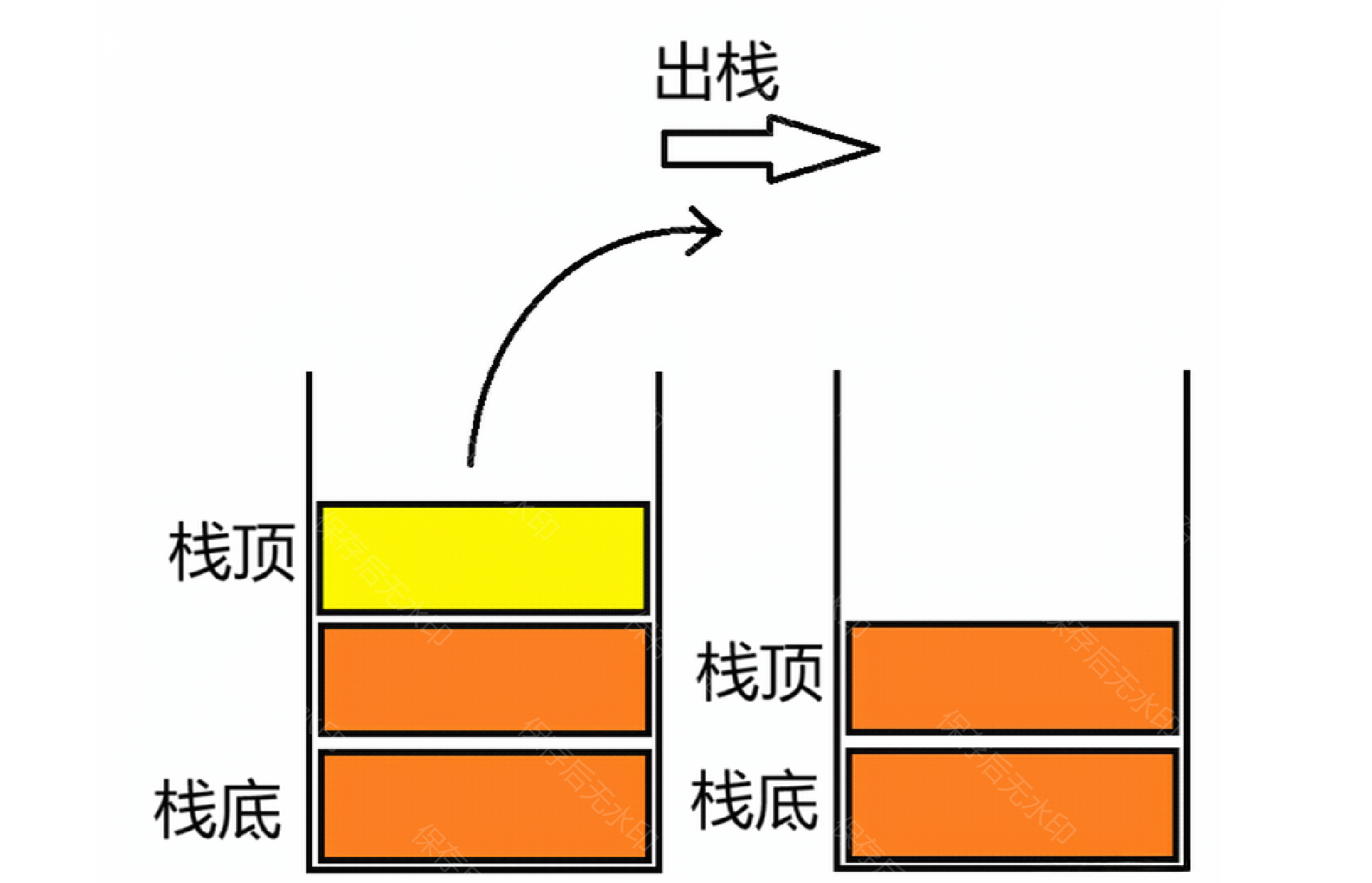
(1)顺序栈
//出栈
void STPop(ST* st)
{assert(st);assert(st->top >= 0);st->top--;
}(2)链式栈
//出栈
void STPop(ST* st)
{assert(st);assert(!STEmpty(st));// 获取栈顶节点的下一个节点SLTNode* next = st->top->next;free(st->top);// 更新栈顶指针,使其指向新的栈顶节点st->top = next;st->size--;
}7.打印栈的元素
(1)顺序栈
//栈的打印
void STPrint(ST* st)
{assert(st);assert(!STEmpty(st));// 从栈顶开始打印,直到栈底(但不包括索引-1)for (int i = st->top; i >= 0; i--){printf("%d ", st->a[i]);}
}(2)链式栈
//栈的打印
void STPrint(ST* st)
{assert(st);assert(!STEmpty(st));for (SLTNode* top = st->top; top != NULL; top = top->next){printf("%d ", top->data);}
}8.销毁栈
(1)顺序栈
//栈的销毁
void STDestory(ST* st)
{assert(st);free(st->a);st->a = NULL;st->capacity = 0;st->top = -1;
}(2)链式栈
//栈的销毁
void STDestory(ST* st)
{assert(st);SLTNode* top = st->top;while (top != NULL){SLTNode* next = top->next;free(top);top = next;}st->size = 0;
}3.顺序栈和链式栈的对比
| 顺序栈 | 链式栈 | |
| 数据结构 | 使用动态数组实现,元素在物理内存中连续存储 | 使用链表实现,元素通过节点和指针连接,内存空间不连续 |
| 内存管理 | 栈空间不足时可动态扩容,释放整个栈时一次性释放内存 | 节点内存单独分配和释放,需要遍历链表以释放所有节点内存 |
| 时间效率 | 可以通过数组下标直接访问栈内任意位置的元素,但是这不符合栈的定义 | 由于每次都需要扩容操作,所以效率略比顺序栈低 |
| 空间效率 | 顺序栈的扩容较大可能会造成空间的浪费 | 内存使用相对灵活,但每个节点需要额外存储指针 |
优缺点对比
| 顺序栈 | 链式栈 | |
| 优点 | 1. 内存连续,缓存利用率高(局部性原理); 2. 实现简单,操作高效(无指针操作)。 | 1. 无需预分配空间,大小动态调整; 2. 不会出现栈溢出(除非内存耗尽)。 |
| 缺点 | 1. 初始化时需确定容量,可能溢出或浪费空间; 2. 动态扩容时有性能开销。 | 1. 每个节点需额外存储指针,空间开销略大; 2. 内存不连续,缓存利用率较低。 |
适用场景
-
顺序栈:
适用于元素数量已知或变化不大的场景,例如:- 表达式求值(元素数量有限);
- 函数调用栈(深度可控)。
-
链式栈:
适用于元素数量不确定或变化剧烈的场景,例如:- 处理动态数据(如日志记录,长度未知);
- 需频繁扩容的场景(避免顺序栈的复制开销)。
总结
- 顺序栈注重效率和空间连续性,适合场景固定、数据量可预测的情况;
- 链式栈注重灵活性,适合数据量动态变化、难以预估的情况。
4.完整代码
1.顺序表
Stack.h
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int STDataType;typedef struct STDataType
{STDataType* a;int top;int capacity;
}ST;//栈的初始化
void STInit(ST* st);//栈的销毁
void STDestory(ST* st);//入栈
void STPush(ST* st, STDataType x);
//出栈
void STPop(ST* st);//取出栈顶数据
STDataType STTop(ST* st);//判空
bool STEmpty(ST* st);//获取数据个数
STDataType STSize(ST* st);//栈的打印
void STPrint(ST* st);Stack.c
#include"Stack.h"//栈的初始化
void STInit(ST* st)
{assert(st);st->a = NULL;st->top = -1;st->capacity = 0;
}//栈的销毁
void STDestory(ST* st)
{assert(st);free(st->a);st->a = NULL;st->capacity = 0;st->top = -1;
}//入栈
void STPush(ST* st, STDataType x)
{assert(st);// 注意:由于top初始化为-1,所以满的条件是top == capacity - 1if (st->top == st->capacity - 1){// 如果栈已满,则扩展栈的容量int newcapacity = st->capacity == 0 ? 4 : st->capacity * 2;STDataType* tmp = (STDataType*)realloc(st->a, newcapacity * sizeof(STDataType));if (tmp == NULL){perror("realloc fail");return;}st->a = tmp;st->capacity = newcapacity;}// 增加栈顶索引,为新元素腾出空间st->top++;// 将新元素x存储在栈顶位置st->a[st->top] = x;
}//出栈
void STPop(ST* st)
{assert(st);assert(st->top >= 0);st->top--;
}//取出栈顶数据
STDataType STTop(ST* st)
{assert(st);assert(st->top >= 0);return st->a[st->top];
}//判空
bool STEmpty(ST* st)
{assert(st);return st->top == -1;
}//获取数据个数
STDataType STSize(ST* st)
{assert(st);return st->top + 1;
}//栈的打印
void STPrint(ST* st)
{assert(st);assert(!STEmpty(st));// 从栈顶开始打印,直到栈底(但不包括索引-1)for (int i = st->top; i >= 0; i--){printf("%d ", st->a[i]);}
}2.链式表
Stack.h
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int STDataType;typedef struct SListNode
{STDataType data;struct SListNode* next;
}SLTNode;typedef struct Stack
{// 指向栈顶节点的指针SLTNode* top;int size;
}ST;//栈的初始化
void STInit(ST* st);//栈的销毁
void STDestory(ST* st);//入栈
void STPush(ST* st, STDataType x);//出栈
void STPop(ST* st);//取出栈顶数据
STDataType STTop(ST* st);//判空
bool STEmpty(ST* st);//获取数据个数
STDataType STSize(ST* st);//栈的打印
void STPrint(ST* st);Stack.c
#include"Stack.h"//栈的初始化
void STInit(ST* st)
{assert(st);st->size = 0;st->top = NULL;
}//栈的销毁
void STDestory(ST* st)
{assert(st);SLTNode* top = st->top;while (top != NULL){SLTNode* next = top->next;free(top);top = next;}st->size = 0;
}//入栈
void STPush(ST* st, STDataType x)
{SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));if (newnode == NULL){perror("malloc fail:");return;}// 新节点的next指向原来的栈顶newnode->next = st->top;// 设置新节点的数据newnode->data = x;// 更新栈顶为新节点st->top = newnode;st->size++;
}//出栈
void STPop(ST* st)
{assert(st);assert(!STEmpty(st));// 获取栈顶节点的下一个节点SLTNode* next = st->top->next;free(st->top);// 更新栈顶指针,使其指向新的栈顶节点st->top = next;st->size--;
}//取出栈顶数据
STDataType STTop(ST* st)
{assert(st);assert(!STEmpty(st));return st->top->data;
}//判空
bool STEmpty(ST* st)
{return (st->top == NULL);
}//获取数据个数
STDataType STSize(ST* st)
{return st->size;
}//栈的打印
void STPrint(ST* st)
{assert(st);assert(!STEmpty(st));for (SLTNode* top = st->top; top != NULL; top = top->next){printf("%d ", top->data);}
}结束语
本篇我们主要介绍了一下栈,接下来我们将接着学习与栈类似的另一个数据结构——队列。
感谢您的三连支持!!!


)





:沪深A股《最新分时交易》数据获取大全:附Python、Java等多语言实战教程与接口文档说明)

)



- 裸机开发)
|漏洞前置感知、精准修复、合规清晰,筑牢软件供应链安全防线!)



)
)