特征图与注意力热图
知识点回顾:
- 不同CNN层的特征图:不同通道的特征图
- 通道注意力后的特征图和热力图
特征图本质就是不同的卷积核的输出,浅层指的是离输入图近的卷积层,浅层卷积层的特征图通常较大,而深层特征图会经过多次下采样,尺寸显著缩小,尺寸差异过大时,小尺寸特征图在视觉上会显得模糊或丢失细节。步骤逻辑如下:
1. 初始化设置:
- 将模型设为评估模式,准备类别名称列表
2.数据加载与处理:
- 从测试数据加载器中获取图像和标签
- 限制处理量以避免冗余,仅处理前 `num_images` 张图像(如2张)
3. 注册钩子捕获特征图:
- 为指定层(如 `conv1`, `conv2`, `conv3`)注册前向钩子
- 钩子函数将这些层的输出(特征图)保存到字典中(以层名为键,特征图(Tensor)为值)
4. 前向传播与特征提取:
- 模型处理图像,触发钩子函数,获取并保存特征图
- 移除钩子,避免后续干扰
5. 可视化特征图:对每张图像
- 恢复原始像素值并显示(反标准化)
- 为每个目标层创建子图,展示前 `num_channels` 个通道的特征图(每个通道的特征图是单通道灰度图,需独立显示)
- 每个通道的特征图以网格形式排列,显示通道编号
def visualize_feature_maps(model, test_loader, device, layer_names, num_images=3, num_channels=9):"""可视化指定层的特征图(修复循环冗余问题)参数:model: 模型test_loader: 测试数据加载器layer_names: 要可视化的层名称(如['conv1', 'conv2', 'conv3'])num_images: 可视化的图像总数num_channels: 每个图像显示的通道数(取前num_channels个通道)"""model.eval() # 设置为评估模式class_names = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']# 从测试集加载器中提取指定数量的图像(避免嵌套循环)images_list, labels_list = [], []for images, labels in test_loader:images_list.append(images)labels_list.append(labels)if len(images_list) * test_loader.batch_size >= num_images:break# 拼接并截取到目标数量images = torch.cat(images_list, dim=0)[:num_images].to(device) # torch.cat拼接多个batch的数据labels = torch.cat(labels_list, dim=0)[:num_images].to(device)with torch.no_grad():# 存储各层特征图feature_maps = {}# 保存钩子句柄hooks = []# 定义钩子函数,捕获指定层的输出def hook(module, input, output, name):feature_maps[name] = output.cpu() # 保存特征图到字典,保存到CPU,避免GPU内存占用# 为每个目标层注册钩子,并保存钩子句柄for name in layer_names:module = getattr(model, name) # 根据层名获取模块hook_handle = module.register_forward_hook(lambda m, i, o, n=name: hook(m, i, o, n)) # 绑定层名到钩子hooks.append(hook_handle)# 前向传播触发钩子_ = model(images)# 正确移除钩子for hook_handle in hooks:hook_handle.remove()# 可视化每个图像的各层特征图(仅一层循环)for img_idx in range(num_images):img = images[img_idx].cpu().permute(1, 2, 0).numpy() # [C,H,W]→[H,W,C]# 反标准化处理(恢复原始像素值)img = img * np.array([0.2023, 0.1994, 0.2010]).reshape(1, 1, 3) + np.array([0.4914, 0.4822, 0.4465]).reshape(1, 1, 3)img = np.clip(img, 0, 1) # 确保像素值在[0,1]范围内# 创建子图num_layers = len(layer_names)fig, axes = plt.subplots(1, num_layers + 1, figsize=(4 * (num_layers + 1), 4))# 显示原始图像axes[0].imshow(img)axes[0].set_title(f'原始图像\n类别: {class_names[labels[img_idx]]}')axes[0].axis('off')# 显示各层特征图for layer_idx, layer_name in enumerate(layer_names):fm = feature_maps[layer_name][img_idx] # 取第img_idx张图像的特征图fm = fm[:num_channels] # 仅取前num_channels个通道num_rows = int(np.sqrt(num_channels)) # 计算网格行数num_cols = num_channels // num_rows if num_rows != 0 else 1 # 计算网格列数# 创建子图网格layer_ax = axes[layer_idx + 1]layer_ax.set_title(f'{layer_name}特征图 \n')# 加个换行让文字分离上去layer_ax.axis('off') # 关闭大子图的坐标轴# 在大子图内创建小网格for ch_idx, channel in enumerate(fm):ax = layer_ax.inset_axes([ch_idx % num_cols / num_cols, (num_rows - 1 - ch_idx // num_cols) / num_rows, 1/num_cols, 1/num_rows])ax.imshow(channel.numpy(), cmap='viridis')ax.set_title(f'通道 {ch_idx + 1}')ax.axis('off')plt.tight_layout()plt.show()# 调用示例(按需修改参数)
layer_names = ['conv1', 'conv2', 'conv3']
visualize_feature_maps(model=model,test_loader=test_loader,device=device,layer_names=layer_names,num_images=5, # 可视化5张测试图像 → 输出5张大图num_channels=9 # 每张图像显示前9个通道的特征图
)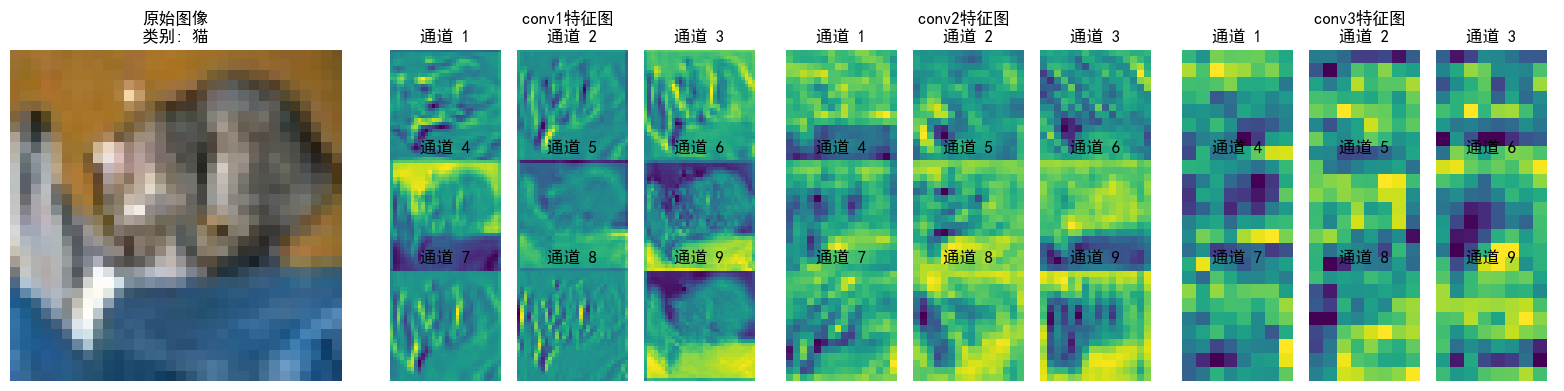
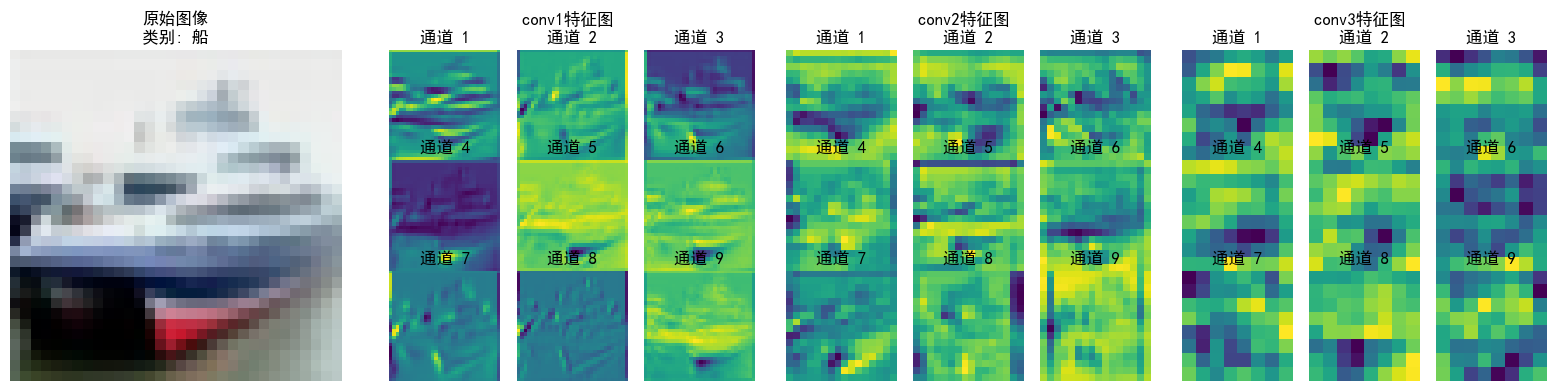
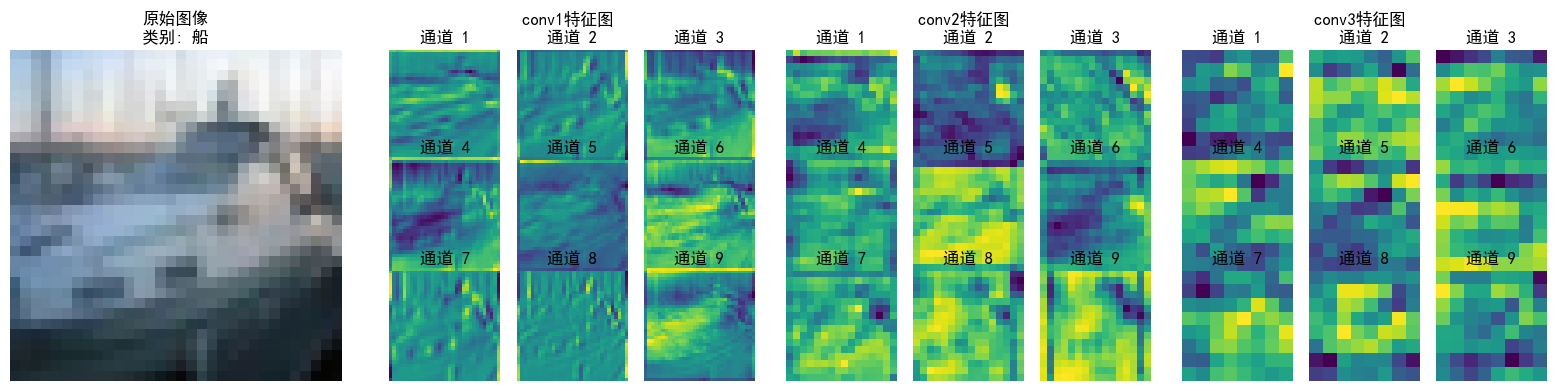
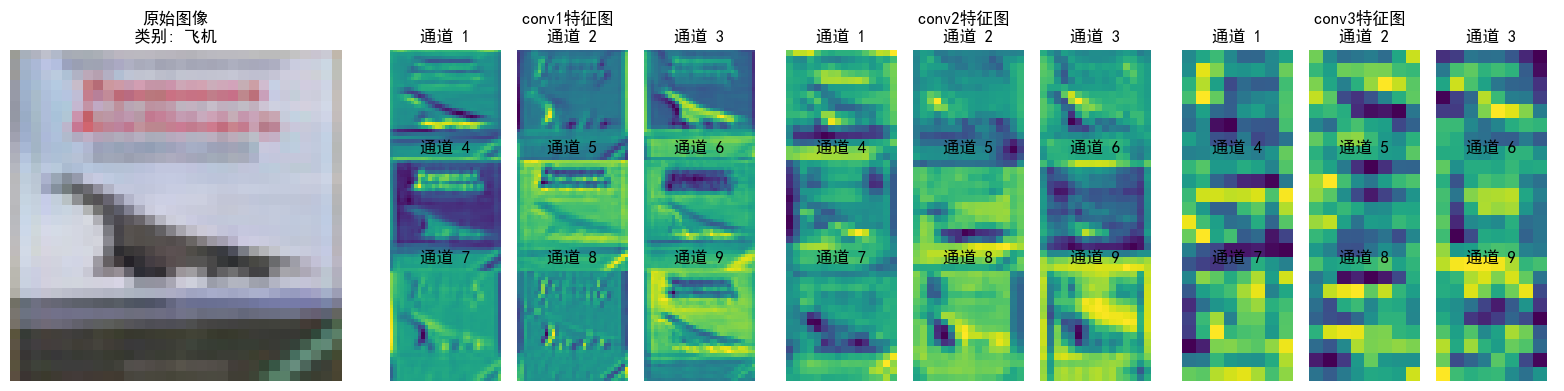
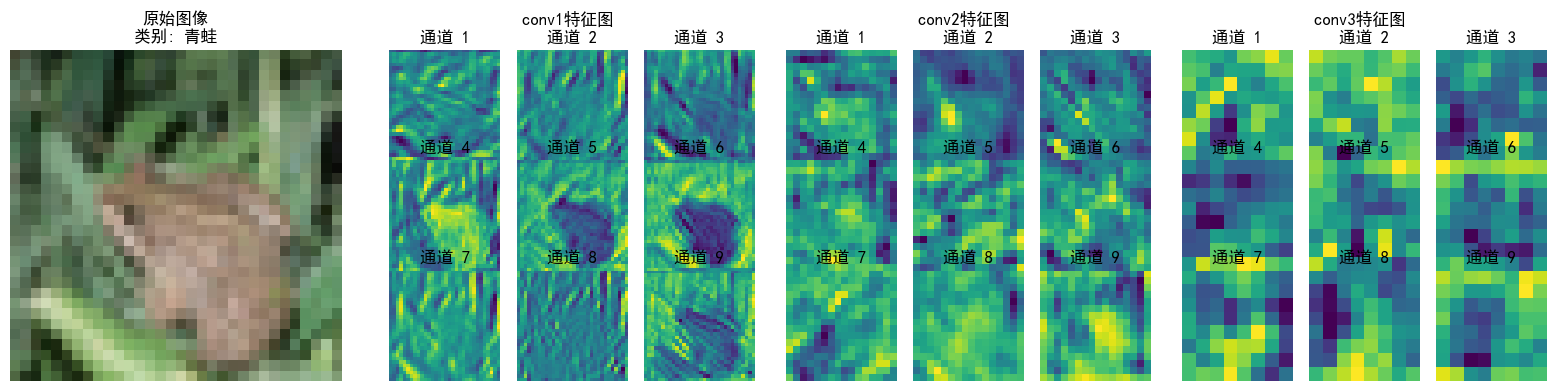
可以看到特征逐层抽象,从“看得见的细节”(conv1)→ “局部结构”(conv2)→ “类别相关的抽象模式”(conv3),模型通过这种方式实现从“看图像”到“理解语义”的跨越;并且每层各个通道也聚焦了不同特征(如通道1检测边缘轮廓,通道2检测纹理细节...),共同协作完成分类任务

分别针对不同层次的模型理解需求的三种主流的神经网络可视化方法,就差注意力热图没学了,一般用于检查注意力模块是否聚焦与任务相关的关键通道或者空间,具体来说:
-
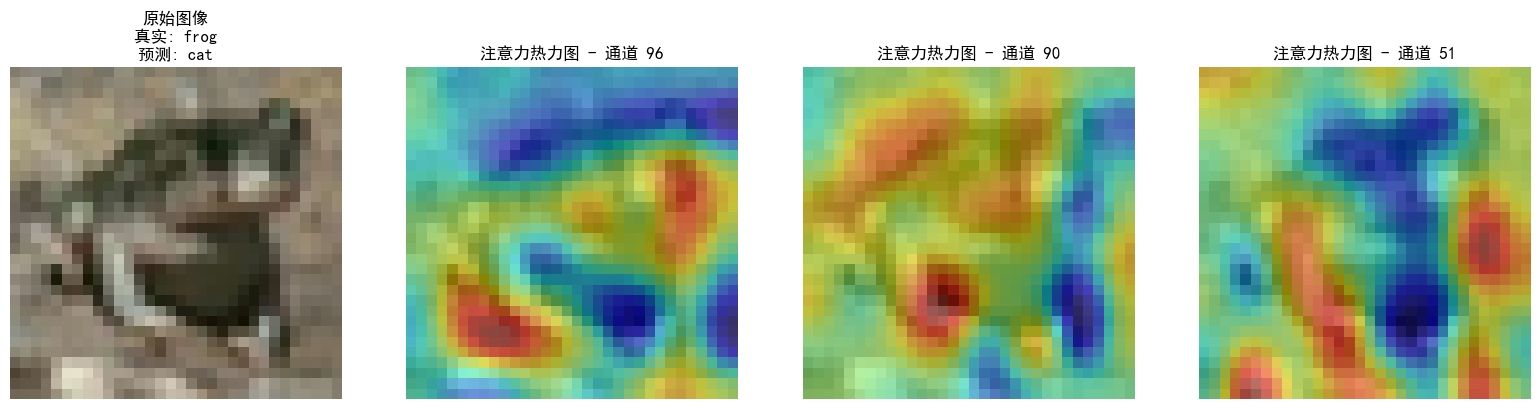
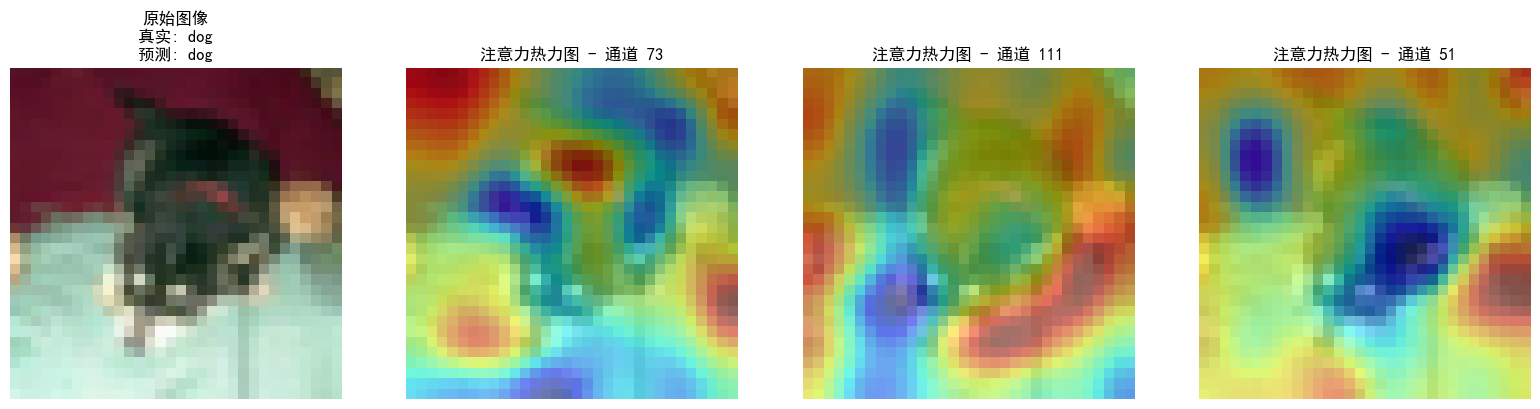
通道注意力热图:展示不同通道的权重分布,例如,在图像分类任务中,模型可能会对包含目标物体的通道赋予更高的注意力权重
-
空间注意力热图:展示输入图像中不同空间位置的权重分布,例如,在目标检测或图像分类任务中,模型可能会对目标物体所在的区域分配更高的注意力权重
注意力热图的步骤和特征图差不多,就是注意一下钩子注册位置仅在最后一个卷积层,就用昨天加入了通道注意力模块的cnn模型训练的结果来可视化
# 可视化空间注意力热力图(显示模型关注的图像区域)
def visualize_attention_map(model, test_loader, device, class_names, num_samples=3):"""可视化模型的注意力热力图,展示模型关注的图像区域"""model.eval() # 设置为评估模式with torch.no_grad():for i, (images, labels) in enumerate(test_loader):if i >= num_samples: # 只可视化前几个样本breakimages, labels = images.to(device), labels.to(device)# 创建一个钩子,捕获中间特征图activation_maps = []def hook(module, input, output):activation_maps.append(output.cpu())# 为最后一个卷积层注册钩子(获取特征图)hook_handle = model.conv3.register_forward_hook(hook)# 前向传播,触发钩子outputs = model(images)# 移除钩子hook_handle.remove()# 获取预测结果_, predicted = torch.max(outputs, 1)# 获取原始图像img = images[0].cpu().permute(1, 2, 0).numpy()# 反标准化处理img = img * np.array([0.2023, 0.1994, 0.2010]).reshape(1, 1, 3) + np.array([0.4914, 0.4822, 0.4465]).reshape(1, 1, 3)img = np.clip(img, 0, 1)# 获取激活图(最后一个卷积层的输出)feature_map = activation_maps[0][0].cpu() # 取第一个样本# 计算通道注意力权重(使用SE模块的全局平均池化)channel_weights = torch.mean(feature_map, dim=(1, 2)) # [C]# 按权重对通道排序sorted_indices = torch.argsort(channel_weights, descending=True)# 创建子图fig, axes = plt.subplots(1, 4, figsize=(16, 4))# 显示原始图像axes[0].imshow(img)axes[0].set_title(f'原始图像\n真实: {class_names[labels[0]]}\n预测: {class_names[predicted[0]]}')axes[0].axis('off')# 显示前3个最活跃通道的热力图for j in range(3):channel_idx = sorted_indices[j]# 获取对应通道的特征图channel_map = feature_map[channel_idx].numpy()# 归一化到[0,1]channel_map = (channel_map - channel_map.min()) / (channel_map.max() - channel_map.min() + 1e-8)# 调整热力图大小以匹配原始图像from scipy.ndimage import zoomheatmap = zoom(channel_map, (32/feature_map.shape[1], 32/feature_map.shape[2]))# 显示热力图axes[j+1].imshow(img)axes[j+1].imshow(heatmap, alpha=0.5, cmap='jet')axes[j+1].set_title(f'注意力热力图 - 通道 {channel_idx}')axes[j+1].axis('off')plt.tight_layout()plt.show()# 调用可视化函数
visualize_attention_map(model, test_loader, device, class_names, num_samples=3)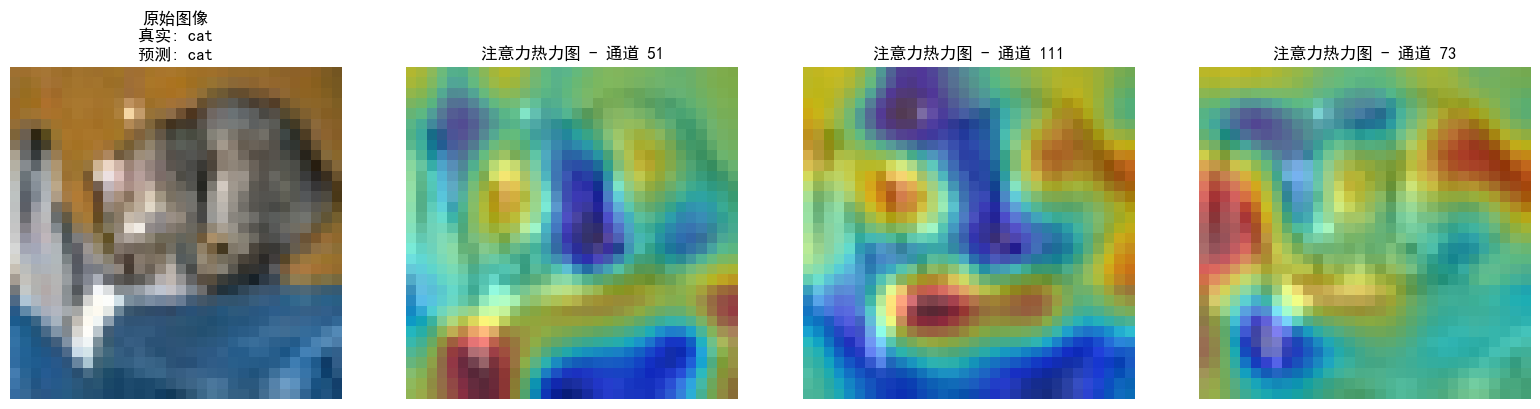
关于全局平均池化 torch.mean vs nn.AdaptiveAvgPool2d 两种方法其实功能上完全等价,只不过前者是直接操作张量的函数,更适合后处理;后者适合神经网络。再明确一点,假设输入特征图[C, H, W]:
torch.mean(dim=(1, 2))→ 输出[C](每个通道的标量均值)nn.AdaptiveAvgPool2d(1)→ 输出[C, 1, 1](可通过squeeze()转为[C],所以这里直接注册钩子捕获这一层输出得到通道权重也行)
当前代码的热力图是单通道特征图的归一化激活强度,再叠加到原图上,并不是严格意义上的注意力热图,严谨一点的话应该用sigmoid后的通道权重来画直方图
@浙大疏锦行



)






)






)

Step-Back 回答回退策略扩大检索范围)