《从零构建大语言模型》学习笔记2,文本数据处理1
文章目录
- 《从零构建大语言模型》学习笔记2,文本数据处理1
- 前言
- 1、分词
- 2.将把提取出来的词元转换为数字ID
- 3.添加特殊上下文标记
- 4. 字节对编码(以及tiktoken库无法下载gpt2参数,调用get_encoding时SSL超时的解决方法)
前言
本书原项目地址:https://github.com/rasbt/LLMs-from-scratch
接下来就开始学习代码了,在训练我们的LLM模型之前,我们先要准备好学习的文本数据,所以第一步是把文本转成计算机能运算的向量,这个过程也叫做embedding,如果有自己部署过开源大模型的小伙伴,就会知道除了要下载大预言模型,在这之前还有个embedding模型,我个人理解应该就是这个过程。其实就是建立一个把所有的文字或者词句映射成方便计算机运算的一些向量库。

这里就引用原作者的图片来介绍了
当然不止是文本数据有这个过程,音视频和图片文件都有这个过程。
当然embedding 需要收集庞大的数据来构造,我们自己收集是比较麻烦的,所以我们后面会用开源的gpt2来进行映射。
有了这个向量库之后,我们需要对我们自己的语料进行转换,把普通的文字根据向量库转成数字。所有第一步要把我们的语料进行分词,把一整句完整的句子拆分为单个的单词和符号。

1、分词
这一步前面的代码还是比较好理解的,原作者用来一本小说的所有文字举例来说明如何简单的对语料进行分词。关于代码我就贴一些关键代码进行解读。
下面我就贴代码了
with open("the-verdict.txt", "r", encoding="utf-8") as f:raw_text = f.read() ##读入文件按照utf-8
print("Total number of character:", len(raw_text))##先输出总长度
print(raw_text[:99])##输出前一百个内容
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text) ##按照符号继续把原文件给分割了
preprocessed = [item.strip() for item in preprocessed if item.strip()]##去掉两端的空白字符 也是去掉了空字符串和仅包含空白字符的项
print(preprocessed[:30])
以上代码是为了把小说中的所有词语和标点符号拆分为一个列表,后续好进行处理和索引。主要用的正则表达式来进行拆分。
2.将把提取出来的词元转换为数字ID
上一步提取出来的词元列表,我们去重后编排一个数字ID列表,过程如下图:
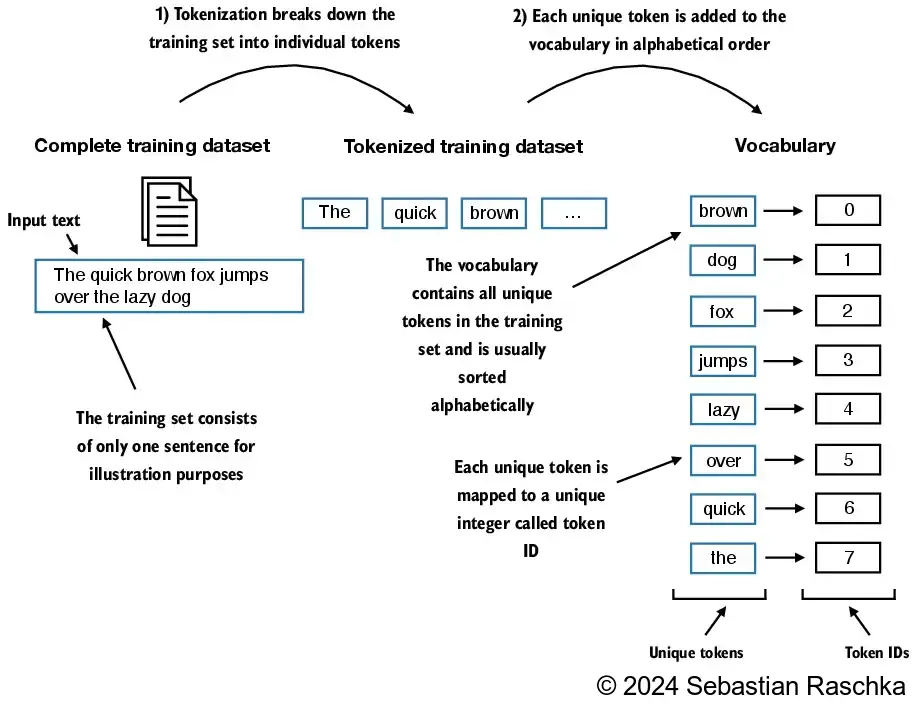
代码如下:
all_words = sorted(set(preprocessed))#从去掉重复的字符
vocab_size = len(all_words)#计总的单词书print(vocab_size)
print(all_words[:50])vocab = {token:integer for integer,token in enumerate(all_words)}##先把word进行编号,再按照单词或者标点为索引(有HashList那味道了)class SimpleTokenizerV1:#一个实例的名字创立def __init__(self, vocab): ## 初始化一个字符串self.str_to_int = vocab #单词到整数的映射self.int_to_str = {i:s for s,i in vocab.items()} #方便解码,进行整数到词汇的反向映射def encode(self, text):preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)##正则化分词标点符号preprocessed = [item.strip() for item in preprocessed if item.strip()## 去掉两端空格与全部的空句]ids = [self.str_to_int[s] for s in preprocessed]##整理完的额字符串列表对应到id,从字典出来return idsdef decode(self, ids):text = " ".join([self.int_to_str[i] for i in ids]) #映射整数id到字符串。join是用前面那个(“ ”)联结成一个完整的字符串# Replace spaces before the specified punctuationstext = re.sub(r'\s+([,.?!"()\'])', r'\1', text) #使用正则表达式,去除标点符号前的多余空格# \s+匹配一个或者多个空白 \1 替换到匹配return texttokenizer = SimpleTokenizerV1(vocab) #用vocab创造一个实例
text = """"It's the last he painted, you know," Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(text) #按照这个例子里的encode函数处理text
print(ids)
all_words 是词元去重排序后的一个字典。然后定义了一个SimpleTokenizerV1类,这个类里面定义了两个函数,一个encode函数能把任意段话转为数字ID列表,decode函数能把数字ID列表解码为对应的文字段落。
3.添加特殊上下文标记
上面的SimpleTokenizerV1类还有些缺陷,就是all_words这个字典太小了,可能会有很多没有收录的词语,这时候就要对SimpleTokenizerV1类进行改进了,通过判断来添加"<|endoftext|>", “<|unk|>” 这两个标签,一个是段落结束标志,一个是没有对应词元时的标志。


代码如下:
class SimpleTokenizerV2:##版本2.0,启动!def __init__(self, vocab):self.str_to_int = vocabself.int_to_str = { i:s for s,i in vocab.items()}#s为单词,i是keydef encode(self, text):preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)#正则化按照标点分类preprocessed = [item.strip() for item in preprocessed if item.strip()]#去掉两头与所有空余句preprocessed = [item if item in self.str_to_int else "<|unk|>" for item in preprocessed#遍历 preprocessed 中的每个 item,如果 item 存在于 self.str_to_int(即词汇表)中,就保留 item#如果不存在(即该单词或符号未定义在词汇表中),就替换为特殊标记 <|unk|>。#拓展:推导式(如列表推导式)是一种紧凑的语法,专门用于生成新列表(或其他容器)#与普通 for 循环相比,它更加简洁和高效,但逻辑复杂时可能会降低可读性。]ids = [self.str_to_int[s] for s in preprocessed]#单词或标点映射为整数列表return idsdef decode(self, ids):text = " ".join([self.int_to_str[i] for i in ids])# Replace spaces before the specified punctuationstext = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)return texttokenizer = SimpleTokenizerV2(vocab)text1 = "Hello, do you like tea?"
text2 = "In the sunlit terraces of the palace."text = " <|endoftext|> ".join((text1, text2))#用句子分隔符链接两个句子print(text) #跟第一个一样,但不会报错了
tokenizer.decode(tokenizer.encode(text))
主要是编码的时候做了一次未知词元的判断
4. 字节对编码(以及tiktoken库无法下载gpt2参数,调用get_encoding时SSL超时的解决方法)
以上提到的分词方式是比较简单的,主要是方便大家理解。接下来使用一种基于字节对编码(BPE)概念的更复杂的分词方案。BPE分词器被用于训练诸如GPT-2、GPT-3以及ChatGPT最初使用的模型等大型语言模型。那具体怎么实现的我这里也不深究了,我们直接拿过来用就好,下面需要使用到tiktoken这个库。
import importlib
import tiktoken
print("tiktoken version:", importlib.metadata.version("tiktoken"))#验证下载并输出版本信息
tokenizer = tiktoken.get_encoding("gpt2")#初始化GPT2!
到这里需要注意一下,因为这里需要下载gpt2的参数,但是大部分人的网络应该下载不下来,根据错误提示可以手动下载vocab.bpe和encoder.json这两个文件,下载后在当前路径创建一个文件夹
.tiktoken,把文件放在这里面。然后还需要把缓存路径设置为该路径,同时手动修改vocab.bpe文件名为6d1cbeee0f20b3d9449abfede4726ed8212e3aee,修改encoder.json文件名为6c7ea1a7e38e3a7f062df639a5b80947f075ffe6。
vocab.bpe下载地址:https://openaipublic.blob.core.windows.net/gpt-2/encodings/main/vocab.bpe
encoder.json下载地址:https://openaipublic.blob.core.windows.net/gpt-2/encodings/main/encoder.json
修改后的代码如下:
import importlib
import tiktoken
print("tiktoken version:", importlib.metadata.version("tiktoken"))#验证下载并输出版本信息import hashlib
blobpath = "https://openaipublic.blob.core.windows.net/gpt-2/encodings/main/vocab.bpe"
vocab_key = hashlib.sha1(blobpath.encode()).hexdigest()
print(vocab_key)
blobpath = "https://openaipublic.blob.core.windows.net/gpt-2/encodings/main/encoder.json"
encoder_key = hashlib.sha1(blobpath.encode()).hexdigest()
print(encoder_key)import os
tiktoken_cache_dir = ".tiktoken"
os.environ["TIKTOKEN_CACHE_DIR"] = tiktoken_cache_dir
# validate
assert os.path.exists(os.path.join(tiktoken_cache_dir, vocab_key))
assert os.path.exists(os.path.join(tiktoken_cache_dir, encoder_key))tokenizer = tiktoken.get_encoding("gpt2")#初始化GPT2!
完整的解决思路可以参考下面两个链接:
how to use tiktoken in offline mode computer
SSLError: HTTPSConnectionPool(host=‘openaipublic.blob.core.windows.net’, port=443)
后面的代码就是使用gpt2的参数对本地语料进行加解码了。









)









